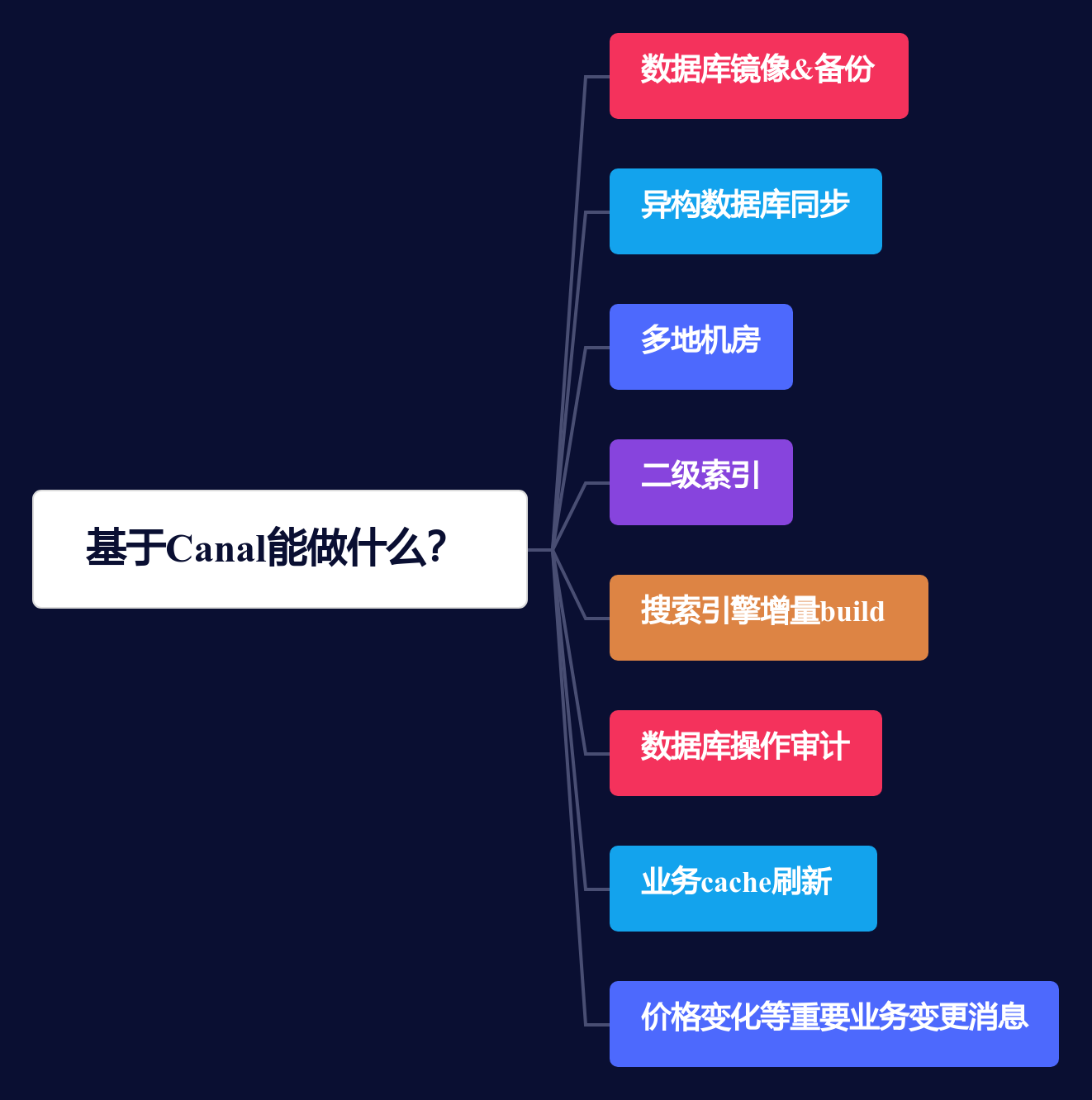
分析探索Canal开源技术原理和架构
- 背景说明
- Canal基本介绍
- Canal作用方向
- MySQL同步原理
- Binlog Dump交互
- Binlog的协议模型
- Canal的模拟slave角色
- Canal的消费订阅
- Canal Server模块
- Canal Instance模块
- 参考资料
- 类似开源项目
背景说明
在早期阶段,阿里巴巴B2B公司由于其在杭州和美国两地均设有数据中心,因此面临了跨机房数据同步的迫切需求。为了满足这一业务需求,公司早期主要依赖于基于触发器的机制来获取和同步数据的增量变更。
 然而,自2010年起,随着技术的发展和业务需求的升级,阿里系公司开始探索新的同步策略。他们逐步转向基于数据库日志解析的技术,以更高效、更准确地捕获数据的增量变更,并基于此构建了增量数据的订阅与消费服务。这一转变不仅优化了数据同步的效率,也为公司后续的业务发展奠定了坚实的基础,标志着阿里巴巴在数据处理和同步领域迈入了新的纪元。
然而,自2010年起,随着技术的发展和业务需求的升级,阿里系公司开始探索新的同步策略。他们逐步转向基于数据库日志解析的技术,以更高效、更准确地捕获数据的增量变更,并基于此构建了增量数据的订阅与消费服务。这一转变不仅优化了数据同步的效率,也为公司后续的业务发展奠定了坚实的基础,标志着阿里巴巴在数据处理和同步领域迈入了新的纪元。
Canal基本介绍
Canal [kə’næl],该名称直译为“水道”或“管道”,形象地描绘了Canal在数据传输中的核心作用,如同水流在渠道中自然流淌,数据也在Canal的引导下顺畅传输。采用纯Java开发,这一选择确保了其跨平台性和广泛的兼容性,使开发者能够轻松集成到各种Java生态系统中。
Canal作用方向
Canal专注于数据库增量日志的准实时解析,为开发者提供了一种高效、可靠的数据订阅与消费机制。目前,其开源版本主要支持MySQL数据库,但未来有望扩展至更多数据库类型。
通过Canal,开发者可以实时捕获数据库的变化,并基于这些变化进行相应的业务处理,从而实现数据的实时同步、分析或触发其他业务逻辑。Canal的这一特性在大数据、实时计算、分布式系统等领域具有广泛的应用前景。
MySQL同步原理
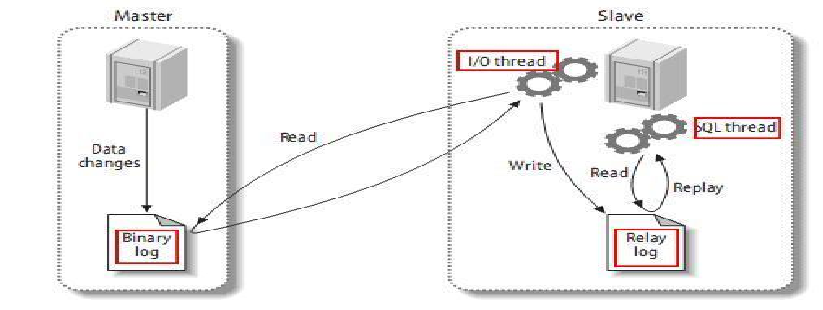
MySQL的主从复制(Master-Slave Replication)机制是实现数据同步的关键技术,其中Slave节点的同步原理可以概括为以下两个核心步骤:
-
I/O Thread读取并存储Binlog:
- Slave节点的I/O线程连接到Master节点,并请求发送二进制日志(Binary Log,简称Binlog)中的事件。
- Master节点接收到请求后,开始发送Binlog中尚未被Slave节点同步的事件数据。
- Slave节点的I/O线程接收这些事件数据,并写入到本地的中继日志(Relay Log)中,以备后续处理。
-
SQL Thread应用变更到数据库:
- Slave节点的SQL线程从中继日志中读取事件。
- 对于每个事件,SQL线程将其转化为在Slave上执行相应的SQL语句或变更。
- SQL线程按顺序执行这些语句,从而在Slave数据库上应用与Master数据库相同的变更,保持数据的一致性。
Binlog Dump交互

Binlog的协议模型
Binlog,即MySQL的二进制日志,记录了数据库的所有更改,使得MySQL可以支持数据复制和恢复操作。在Binlog中,每一个变更都被封装为一个或多个Event。以下是对Binlog Event结构的详细分析:
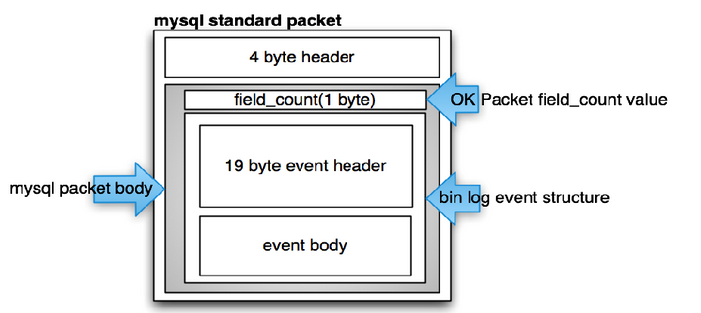
Binlog文件以4个字节的魔数(Magic Number)开始,其值为0xfe 0x62 0x69 0x6e,对应ASCII码的"þbin"。随后是各种Event的序列,每个Event都具有相同的通用结构,由Event Header和Event Data两部分组成。
Canal的模拟slave角色
为了捕获数据库中的实时增量数据,一种常用的技术方法是模拟MySQL主从复制中的Slave端的行为。具体而言,这涉及到一个精心的设计,即通过实现MySQL主从复制协议中的关键部分,使应用程序能够伪装成MySQL的Slave节点(类似于I/O线程的角色),从而实时接收并处理主节点(Master)上的数据变更。
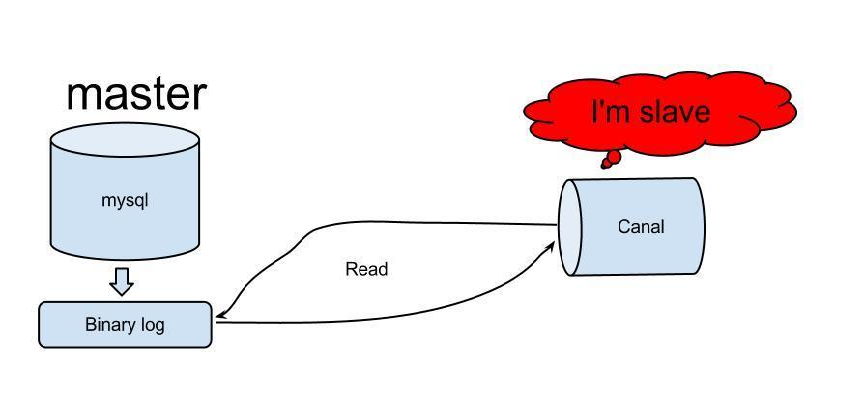 在这种方法中,应用程序会模拟Slave节点与Master节点之间的通信协议,包括建立连接、请求Binlog日志、接收并解析Binlog事件等步骤。通过这种方式,应用程序能够实时地获取到主节点上发生的所有数据变更,如插入、更新、删除等操作,并基于这些变更进行后续的数据处理或同步操作。
在这种方法中,应用程序会模拟Slave节点与Master节点之间的通信协议,包括建立连接、请求Binlog日志、接收并解析Binlog事件等步骤。通过这种方式,应用程序能够实时地获取到主节点上发生的所有数据变更,如插入、更新、删除等操作,并基于这些变更进行后续的数据处理或同步操作。
Canal的消费订阅
在数据处理的生态系统中,数据消费扮演着至关重要的角色。它基于特定的网络协议,为不同的业务需求提供了灵活且高效的数据订阅与消费机制。这一原理的实现,借鉴了数据库主从复制中的SQL Thread模式,但更进一步地融入了业务自定义的灵活性。
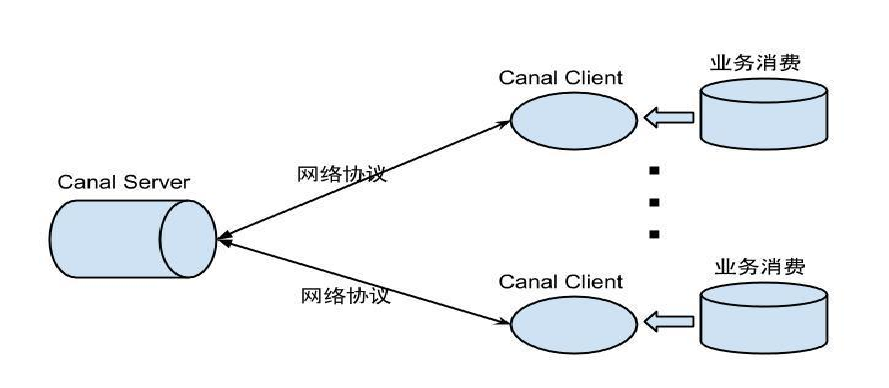
在数据消费阶段,系统采用了类似于SQL Thread的处理机制。但与SQL Thread不同的是,这里的数据处理不再局限于简单的数据库操作,而是可以根据业务需求进行高度自定义。通过定义灵活的数据处理规则和逻辑,系统可以实现对数据流的精细化加工和处理,从而满足不同业务场景下的复杂需求。
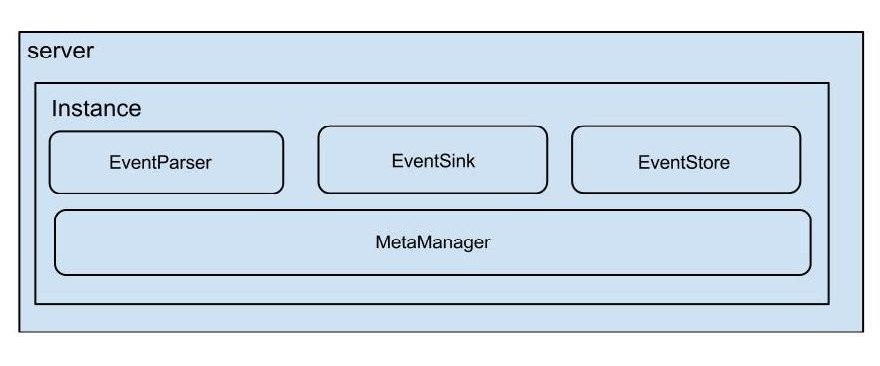
Canal Server模块
在Canal的架构中,server 代表着一个独立运行的Canal服务器实例,它依托于Java虚拟机(JVM)环境执行。每个server实例都承载着Canal的核心功能和数据处理逻辑。
 基于netty网络处理 + protobuf数据传输格式
基于netty网络处理 + protobuf数据传输格式
Canal Instance模块
Canal的instance概念对应于一个特定的数据队列或数据流。这种设计使得一个server实例能够同时处理和管理零个到多个(0…n)instance。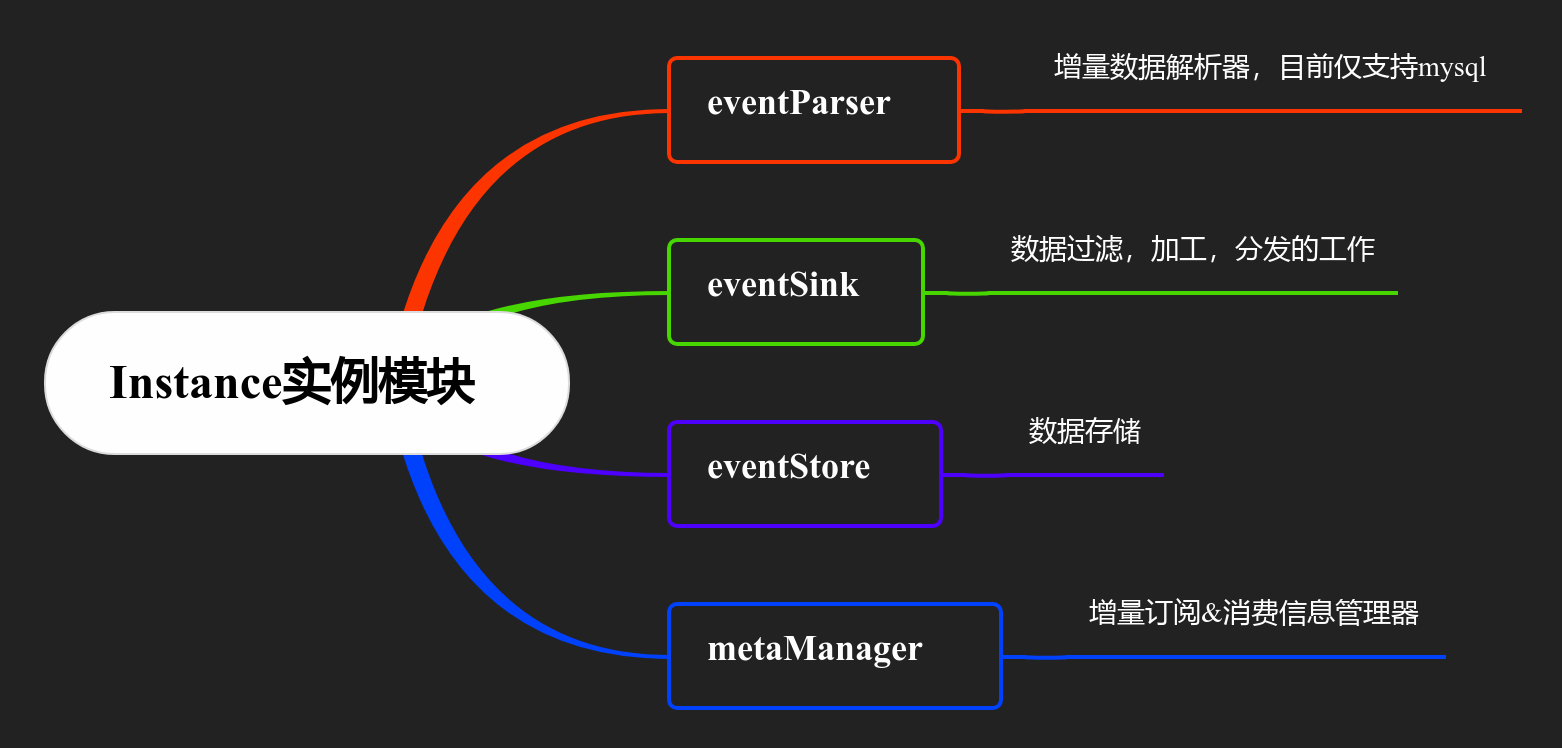 每个
每个instance负责监控、捕获并传递特定数据源(如MySQL数据库)的变更数据到相应的消费者或处理逻辑中。
参考资料
- http://dev.mysql.com/doc/internals/en/binary-log.html
- https://github.com/alibaba/canal/wiki
- http://dev.mysql.com/doc/internals/en/binary-log.html
- http://dev.mysql.com/doc/internals/en/replication-protocol.html
类似开源项目
- https://github.com/linkedin/databus
- http://code.google.com/p/tungsten-replicator/
- http://code.google.com/p/open-replicator/