王者荣耀图鉴皮肤怎么来的
最近一个王者荣耀图鉴开源很火

这个项目里面有很多的图片和音效资源,最简单的方法就是利用爬虫技术爬取这些图片资源。
第一步环境准备
- Pyhton3.12
- macos系统
第二步查看王者荣耀官网
这些图片资源最简单的来源就是王者荣耀官网网站了
王者荣耀
打开控制台,刷新页面我们会发现一个herolist.json的请求,这就是王者荣耀英雄数据
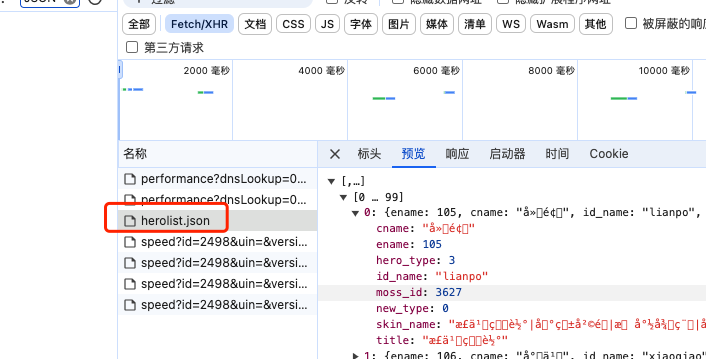
这里发现接口的字符串编码有问题,暂时忽略不考虑,后面通过代码修正
进入英雄资料页面,发现页面url与herolist.json存在一定的关系
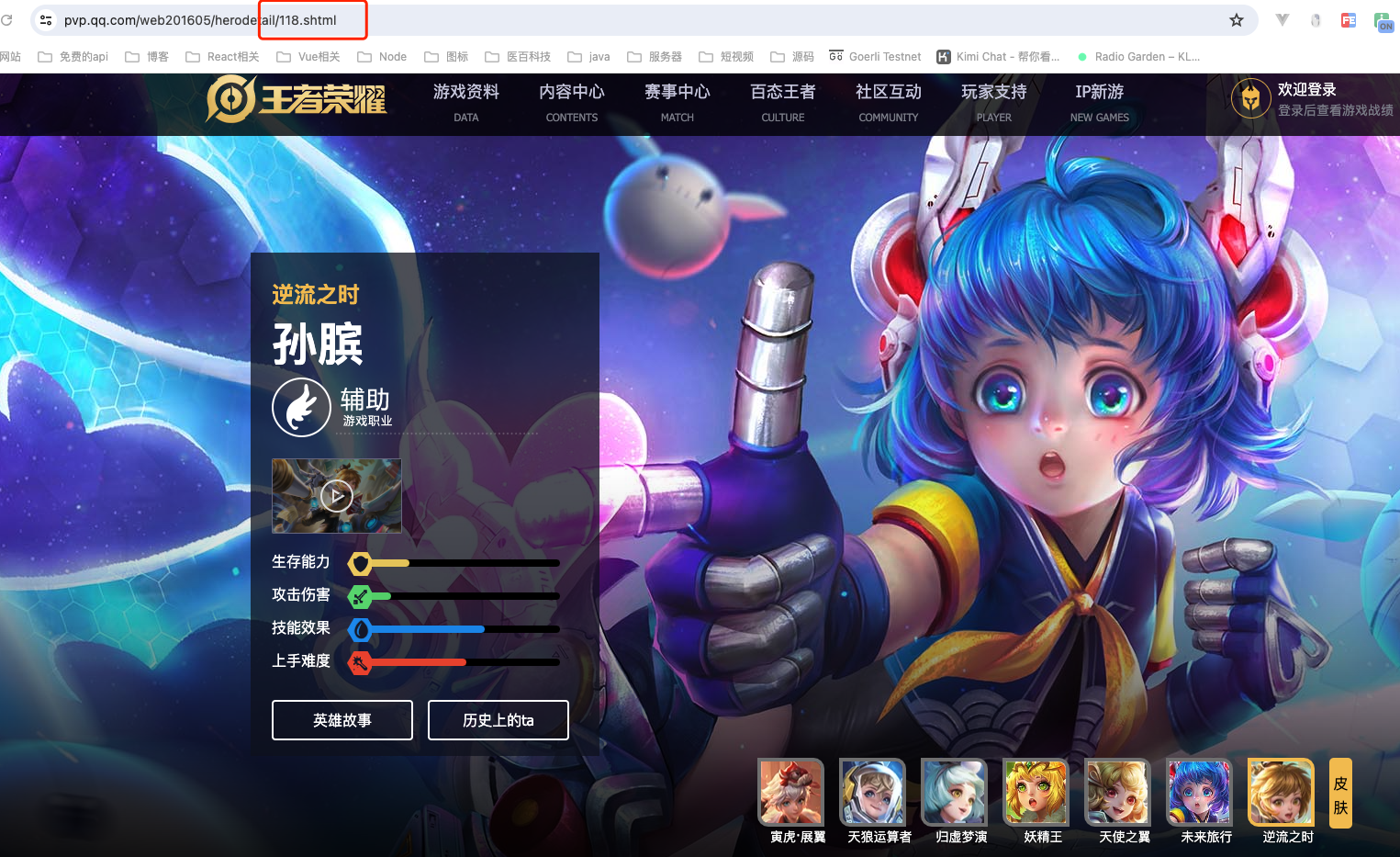
这里的数字和json中的ename一一对应
第三步代码实现
- 获取herolist.json的数据
- 循环hreolist.json数据抓取每一个ename对应的shtml页面
- 获取shtml英雄皮肤图片src
- 下载图片图片写入本地文件夹,或者上传cos服务
#!/usr/bin/env python
# -*- coding: utf-8 -*-
import requests
from bs4 import BeautifulSoup
from urllib import parse
from urllib3.util.retry import Retry
from requests.adapters import HTTPAdapter
import os
session = requests.Session()
retry = Retry(total=5, backoff_factor=0.1, status_forcelist=[500, 502, 503, 504], raise_on_status=False)
adapter = HTTPAdapter(max_retries=retry)
session.mount('http://', adapter)
session.mount('https://', adapter)
class Skin(object):
def __init__(self):
# 英雄的json数据
self.hero_url = 'https://pvp.qq.com/web201605/js/herolist.json'
# 英雄详细页的通用url前缀信息
self.base_url = 'https://pvp.qq.com/web201605/herodetail/'
# 英雄详细页url后缀信息
self.detail_url = ''
# 图片存储文件夹
self.img_folder = 'skin'
# 图片url的通用前缀
self.skin_url = 'https://game.gtimg.cn/images/yxzj/img201606/skin/hero-info/'
# 图片url的后缀信息
self.skin_detail_url = ''
def get_hero(self):
"""获取英雄的json数据"""
request = requests.get(self.hero_url)
hero_list = request.json()
return hero_list
def get_hero_skin(self, hero_name, hero_no):
"""获取详细页英雄皮肤展示的信息,并爬图"""
url = parse.urljoin(self.base_url, self.detail_url)
request = requests.get(url)
request.encoding = 'gbk'
html = request.text
# 获取皮肤信息的节点
soup = BeautifulSoup(html, 'lxml')
skip_list = soup.select('.pic-pf-list3')
for skin_info in skip_list:
# 获取皮肤名称
img_names = skin_info.attrs['data-imgname']
name_list = img_names.split('|')
skin_no = 1
# 循环下载皮肤图片
for skin_name in name_list:
self.skin_detail_url = '%s/%s-bigskin-%s.jpg' % (hero_no, hero_no, skin_no)
skin_no += 1
img_name = hero_name + '-' + skin_name + '.jpg'
self.download_skin(img_name)
def download_skin(self, img_name):
try:
"""下载皮肤图片"""
img_url = parse.urljoin(self.skin_url, self.skin_detail_url)
print(img_url)
response = session.get(img_url, timeout=(10,27), stream=True)
response.raise_for_status()
if response.status_code == 200:
print('download-%s' % img_name)
img_path = os.path.join(self.img_folder, img_name)
with open(img_path, 'wb') as img:
for chunk in response.iter_content(chunk_size=8192):
if chunk:
img.write(chunk)
else:
print('img error!')
except requests.exceptions.ChunkedEncodingError:
self.download_skin(img_name)
except requests.exceptions.RequestException:
print('img error!')
def make_folder(self):
"""创建图片存储文件夹"""
if not os.path.exists(self.img_folder):
os.mkdir(self.img_folder)
def run(self):
"""脚本执行入口"""
self.make_folder()
hero_list = self.get_hero()
for hero in hero_list:
hero_no = str(hero['ename'])
self.detail_url = hero_no + '.shtml'
hero_name = hero['cname']
self.get_hero_skin(hero_name, hero_no)
# 程序执行入口
if __name__ == '__main__':
skin = Skin()
skin.run()

该demo仅用于学习交流,请勿用于商业用途,否则后果自负。
如果实在搞不定就联系博主吧