一、SpringBatch简介
1、Spring Batch是一个轻量级,全面的批处理框架,旨在开发对企业系统日常运营至关重要的强大批处理应用程序。Spring Batch构建了人们期望的Spring Framework特性(生产力,基于POJO的开发方法和一般易用性),同时使开发人员可以在必要时轻松访问和利用更高级的企业服务。
2、中文社区
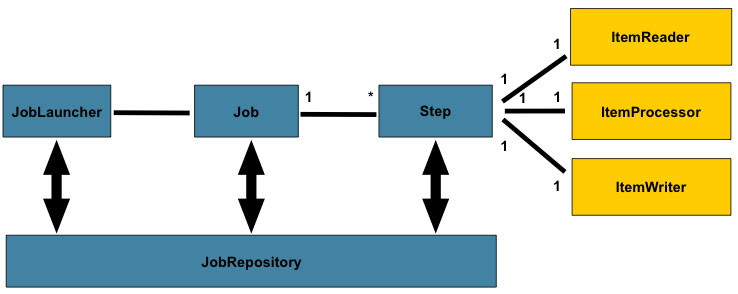
二、SpringBatch核心概念
1、 任务Job相关:
是封装整个批处理过程的单位,跑一个批处理任务,就是跑一个Job所定义的内容
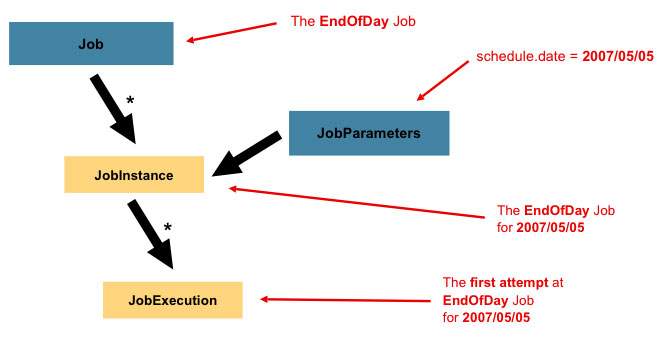
①、Job:封装处理实体,定义过程逻辑。
②、JobInstance:Job的运行实例,不同的实例,参数不同,所以定义好一个Job后可以通过不同参数运行多次。
③、JobParameters:与JobInstance相关联的参数。
④、JobExecution:代表Job的一次实际执行,可能成功、可能失败。
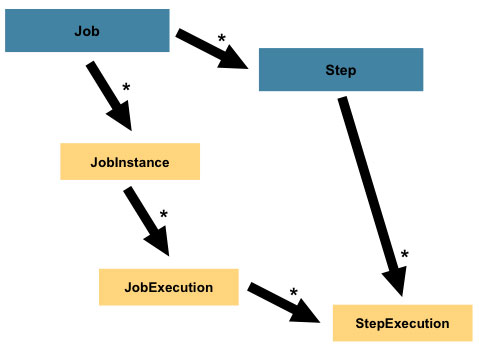
2、Step:
Step是对Job某个过程的封装,一个Job可以包含一个或多个Step,一步步的Step按特定逻辑执行,才代表Job执行完成 。
定义一个Job关键是定义好一个或多个Step,然后把它们组装好即可。而定义Step有多种方法,但有一种常用的模型就是输入——处理——输出,即Item Reader、Item Processor和Item Writer。比如通过Item Reader从文件输入数据,然后通过Item Processor进行业务处理和数据转换,最后通过Item Writer写到数据库中去。
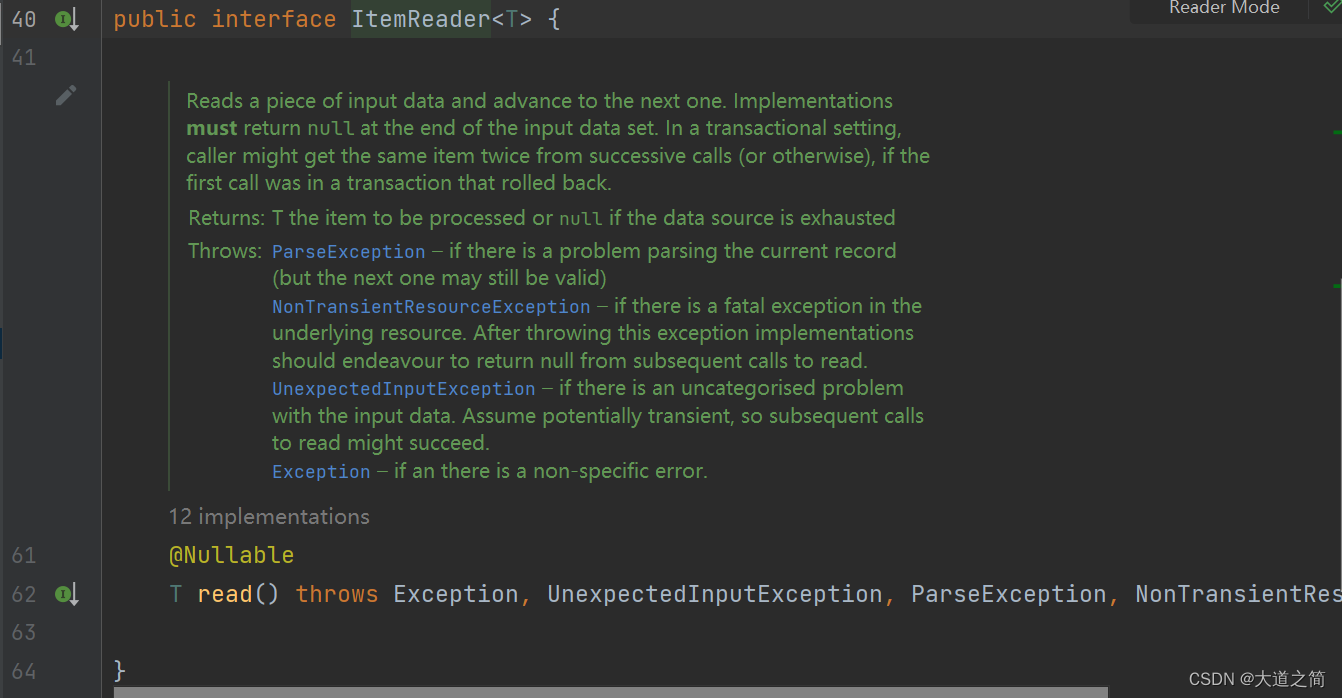
ItemReader
ItemProcessor
 ItemWriter
ItemWriter
Job任务图
3、JobRepository
对整个批处理的新增、更新、执行进行记录。
package org.springframework.batch.core.repository;
import org.springframework.batch.core.Job;
import org.springframework.batch.core.JobExecution;
import org.springframework.batch.core.JobInstance;
import org.springframework.batch.core.JobParameters;
import org.springframework.batch.core.Step;
import org.springframework.batch.core.StepExecution;
import org.springframework.batch.core.repository.dao.JobExecutionDao;
import org.springframework.batch.core.repository.dao.JobInstanceDao;
import org.springframework.batch.item.ExecutionContext;
import org.springframework.lang.Nullable;
import org.springframework.transaction.annotation.Isolation;
import java.util.Collection;
/**
* <p>
* Repository responsible for persistence of batch meta-data entities.
* </p>
*
* @see JobInstance
* @see JobExecution
* @see StepExecution
*
* @author Lucas Ward
* @author Dave Syer
* @author Robert Kasanicky
* @author David Turanski
* @author Michael Minella
* @author Mahmoud Ben Hassine
*/
public interface JobRepository {
/**
* Check if an instance of this job already exists with the parameters
* provided.
*
* @param jobName the name of the job
* @param jobParameters the parameters to match
* @return true if a {@link JobInstance} already exists for this job name
* and job parameters
*/
boolean isJobInstanceExists(String jobName, JobParameters jobParameters);
/**
* Create a new {@link JobInstance} with the name and job parameters provided.
*
* @param jobName logical name of the job
* @param jobParameters parameters used to execute the job
* @return the new {@link JobInstance}
*/
JobInstance createJobInstance(String jobName, JobParameters jobParameters);
/**
* Create a new {@link JobExecution} based upon the {@link JobInstance} it's associated
* with, the {@link JobParameters} used to execute it with and the location of the configuration
* file that defines the job.
*
* @param jobInstance {@link JobInstance} instance to initialize the new JobExecution.
* @param jobParameters {@link JobParameters} instance to initialize the new JobExecution.
* @param jobConfigurationLocation {@link String} instance to initialize the new JobExecution.
* @return the new {@link JobExecution}.
*/
JobExecution createJobExecution(JobInstance jobInstance, JobParameters jobParameters, String jobConfigurationLocation);
/**
* <p>
* Create a {@link JobExecution} for a given {@link Job} and
* {@link JobParameters}. If matching {@link JobInstance} already exists,
* the job must be restartable and it's last JobExecution must *not* be
* completed. If matching {@link JobInstance} does not exist yet it will be
* created.
* </p>
*
* <p>
* If this method is run in a transaction (as it normally would be) with
* isolation level at {@link Isolation#REPEATABLE_READ} or better, then this
* method should block if another transaction is already executing it (for
* the same {@link JobParameters} and job name). The first transaction to
* complete in this scenario obtains a valid {@link JobExecution}, and
* others throw {@link JobExecutionAlreadyRunningException} (or timeout).
* There are no such guarantees if the {@link JobInstanceDao} and
* {@link JobExecutionDao} do not respect the transaction isolation levels
* (e.g. if using a non-relational data-store, or if the platform does not
* support the higher isolation levels).
* </p>
*
* @param jobName the name of the job that is to be executed
*
* @param jobParameters the runtime parameters for the job
*
* @return a valid {@link JobExecution} for the arguments provided
*
* @throws JobExecutionAlreadyRunningException if there is a
* {@link JobExecution} already running for the job instance with the
* provided job and parameters.
* @throws JobRestartException if one or more existing {@link JobInstance}s
* is found with the same parameters and {@link Job#isRestartable()} is
* false.
* @throws JobInstanceAlreadyCompleteException if a {@link JobInstance} is
* found and was already completed successfully.
*
*/
JobExecution createJobExecution(String jobName, JobParameters jobParameters)
throws JobExecutionAlreadyRunningException, JobRestartException, JobInstanceAlreadyCompleteException;
/**
* Update the {@link JobExecution} (but not its {@link ExecutionContext}).
*
* Preconditions: {@link JobExecution} must contain a valid
* {@link JobInstance} and be saved (have an id assigned).
*
* @param jobExecution {@link JobExecution} instance to be updated in the repo.
*/
void update(JobExecution jobExecution);
/**
* Save the {@link StepExecution} and its {@link ExecutionContext}. ID will
* be assigned - it is not permitted that an ID be assigned before calling
* this method. Instead, it should be left blank, to be assigned by a
* {@link JobRepository}.
*
* Preconditions: {@link StepExecution} must have a valid {@link Step}.
*
* @param stepExecution {@link StepExecution} instance to be added to the repo.
*/
void add(StepExecution stepExecution);
/**
* Save a collection of {@link StepExecution}s and each {@link ExecutionContext}. The
* StepExecution ID will be assigned - it is not permitted that an ID be assigned before calling
* this method. Instead, it should be left blank, to be assigned by {@link JobRepository}.
*
* Preconditions: {@link StepExecution} must have a valid {@link Step}.
*
* @param stepExecutions collection of {@link StepExecution} instances to be added to the repo.
*/
void addAll(Collection<StepExecution> stepExecutions);
/**
* Update the {@link StepExecution} (but not its {@link ExecutionContext}).
*
* Preconditions: {@link StepExecution} must be saved (have an id assigned).
*
* @param stepExecution {@link StepExecution} instance to be updated in the repo.
*/
void update(StepExecution stepExecution);
/**
* Persist the updated {@link ExecutionContext}s of the given
* {@link StepExecution}.
*
* @param stepExecution {@link StepExecution} instance to be used to update the context.
*/
void updateExecutionContext(StepExecution stepExecution);
/**
* Persist the updated {@link ExecutionContext} of the given
* {@link JobExecution}.
* @param jobExecution {@link JobExecution} instance to be used to update the context.
*/
void updateExecutionContext(JobExecution jobExecution);
/**
* @param jobInstance {@link JobInstance} instance containing the step executions.
* @param stepName the name of the step execution that might have run.
* @return the last execution of step for the given job instance.
*/
@Nullable
StepExecution getLastStepExecution(JobInstance jobInstance, String stepName);
/**
* @param jobInstance {@link JobInstance} instance containing the step executions.
* @param stepName the name of the step execution that might have run.
* @return the execution count of the step within the given job instance.
*/
int getStepExecutionCount(JobInstance jobInstance, String stepName);
/**
* @param jobName the name of the job that might have run
* @param jobParameters parameters identifying the {@link JobInstance}
* @return the last execution of job if exists, null otherwise
*/
@Nullable
JobExecution getLastJobExecution(String jobName, JobParameters jobParameters);
}
4、JobLauncher
负责启动任Job
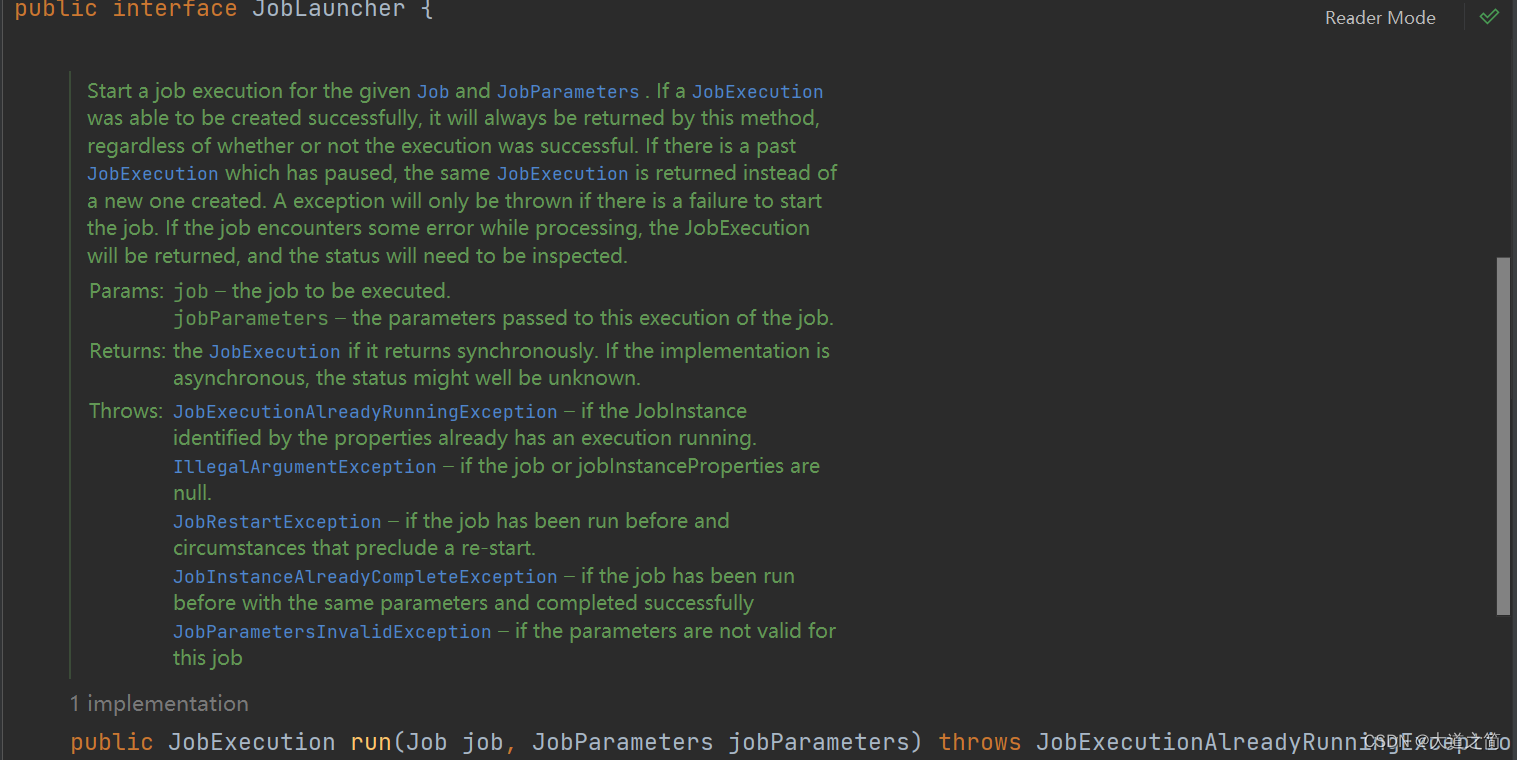
三、使用案例
1、引入依赖
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-batch</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-jpa</artifactId>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>5.1.47</version>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<version>1.18.12</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-jdbc</artifactId>
</dependency>
2、引入官方建表SQL
-- Autogenerated: do not edit this file
CREATE TABLE BATCH_JOB_INSTANCE (
JOB_INSTANCE_ID BIGINT NOT NULL PRIMARY KEY ,
VERSION BIGINT ,
JOB_NAME VARCHAR(100) NOT NULL,
JOB_KEY VARCHAR(32) NOT NULL,
constraint JOB_INST_UN unique (JOB_NAME, JOB_KEY)
) ENGINE=InnoDB;
CREATE TABLE BATCH_JOB_EXECUTION (
JOB_EXECUTION_ID BIGINT NOT NULL PRIMARY KEY ,
VERSION BIGINT ,
JOB_INSTANCE_ID BIGINT NOT NULL,
CREATE_TIME DATETIME(6) NOT NULL,
START_TIME DATETIME(6) DEFAULT NULL ,
END_TIME DATETIME(6) DEFAULT NULL ,
STATUS VARCHAR(10) ,
EXIT_CODE VARCHAR(2500) ,
EXIT_MESSAGE VARCHAR(2500) ,
LAST_UPDATED DATETIME(6),
JOB_CONFIGURATION_LOCATION VARCHAR(2500) NULL,
constraint JOB_INST_EXEC_FK foreign key (JOB_INSTANCE_ID)
references BATCH_JOB_INSTANCE(JOB_INSTANCE_ID)
) ENGINE=InnoDB;
CREATE TABLE BATCH_JOB_EXECUTION_PARAMS (
JOB_EXECUTION_ID BIGINT NOT NULL ,
TYPE_CD VARCHAR(6) NOT NULL ,
KEY_NAME VARCHAR(100) NOT NULL ,
STRING_VAL VARCHAR(250) ,
DATE_VAL DATETIME(6) DEFAULT NULL ,
LONG_VAL BIGINT ,
DOUBLE_VAL DOUBLE PRECISION ,
IDENTIFYING CHAR(1) NOT NULL ,
constraint JOB_EXEC_PARAMS_FK foreign key (JOB_EXECUTION_ID)
references BATCH_JOB_EXECUTION(JOB_EXECUTION_ID)
) ENGINE=InnoDB;
CREATE TABLE BATCH_STEP_EXECUTION (
STEP_EXECUTION_ID BIGINT NOT NULL PRIMARY KEY ,
VERSION BIGINT NOT NULL,
STEP_NAME VARCHAR(100) NOT NULL,
JOB_EXECUTION_ID BIGINT NOT NULL,
START_TIME DATETIME(6) NOT NULL ,
END_TIME DATETIME(6) DEFAULT NULL ,
STATUS VARCHAR(10) ,
COMMIT_COUNT BIGINT ,
READ_COUNT BIGINT ,
FILTER_COUNT BIGINT ,
WRITE_COUNT BIGINT ,
READ_SKIP_COUNT BIGINT ,
WRITE_SKIP_COUNT BIGINT ,
PROCESS_SKIP_COUNT BIGINT ,
ROLLBACK_COUNT BIGINT ,
EXIT_CODE VARCHAR(2500) ,
EXIT_MESSAGE VARCHAR(2500) ,
LAST_UPDATED DATETIME(6),
constraint JOB_EXEC_STEP_FK foreign key (JOB_EXECUTION_ID)
references BATCH_JOB_EXECUTION(JOB_EXECUTION_ID)
) ENGINE=InnoDB;
CREATE TABLE BATCH_STEP_EXECUTION_CONTEXT (
STEP_EXECUTION_ID BIGINT NOT NULL PRIMARY KEY,
SHORT_CONTEXT VARCHAR(2500) NOT NULL,
SERIALIZED_CONTEXT TEXT ,
constraint STEP_EXEC_CTX_FK foreign key (STEP_EXECUTION_ID)
references BATCH_STEP_EXECUTION(STEP_EXECUTION_ID)
) ENGINE=InnoDB;
CREATE TABLE BATCH_JOB_EXECUTION_CONTEXT (
JOB_EXECUTION_ID BIGINT NOT NULL PRIMARY KEY,
SHORT_CONTEXT VARCHAR(2500) NOT NULL,
SERIALIZED_CONTEXT TEXT ,
constraint JOB_EXEC_CTX_FK foreign key (JOB_EXECUTION_ID)
references BATCH_JOB_EXECUTION(JOB_EXECUTION_ID)
) ENGINE=InnoDB;
CREATE TABLE BATCH_STEP_EXECUTION_SEQ (
ID BIGINT NOT NULL,
UNIQUE_KEY CHAR(1) NOT NULL,
constraint UNIQUE_KEY_UN unique (UNIQUE_KEY)
) ENGINE=InnoDB;
INSERT INTO BATCH_STEP_EXECUTION_SEQ (ID, UNIQUE_KEY) select * from (select 0 as ID, '0' as UNIQUE_KEY) as tmp where not exists(select * from BATCH_STEP_EXECUTION_SEQ);
CREATE TABLE BATCH_JOB_EXECUTION_SEQ (
ID BIGINT NOT NULL,
UNIQUE_KEY CHAR(1) NOT NULL,
constraint UNIQUE_KEY_UN unique (UNIQUE_KEY)
) ENGINE=InnoDB;
INSERT INTO BATCH_JOB_EXECUTION_SEQ (ID, UNIQUE_KEY) select * from (select 0 as ID, '0' as UNIQUE_KEY) as tmp where not exists(select * from BATCH_JOB_EXECUTION_SEQ);
CREATE TABLE BATCH_JOB_SEQ (
ID BIGINT NOT NULL,
UNIQUE_KEY CHAR(1) NOT NULL,
constraint UNIQUE_KEY_UN unique (UNIQUE_KEY)
) ENGINE=InnoDB;
INSERT INTO BATCH_JOB_SEQ (ID, UNIQUE_KEY) select * from (select 0 as ID, '0' as UNIQUE_KEY) as tmp where not exists(select * from BATCH_JOB_SEQ);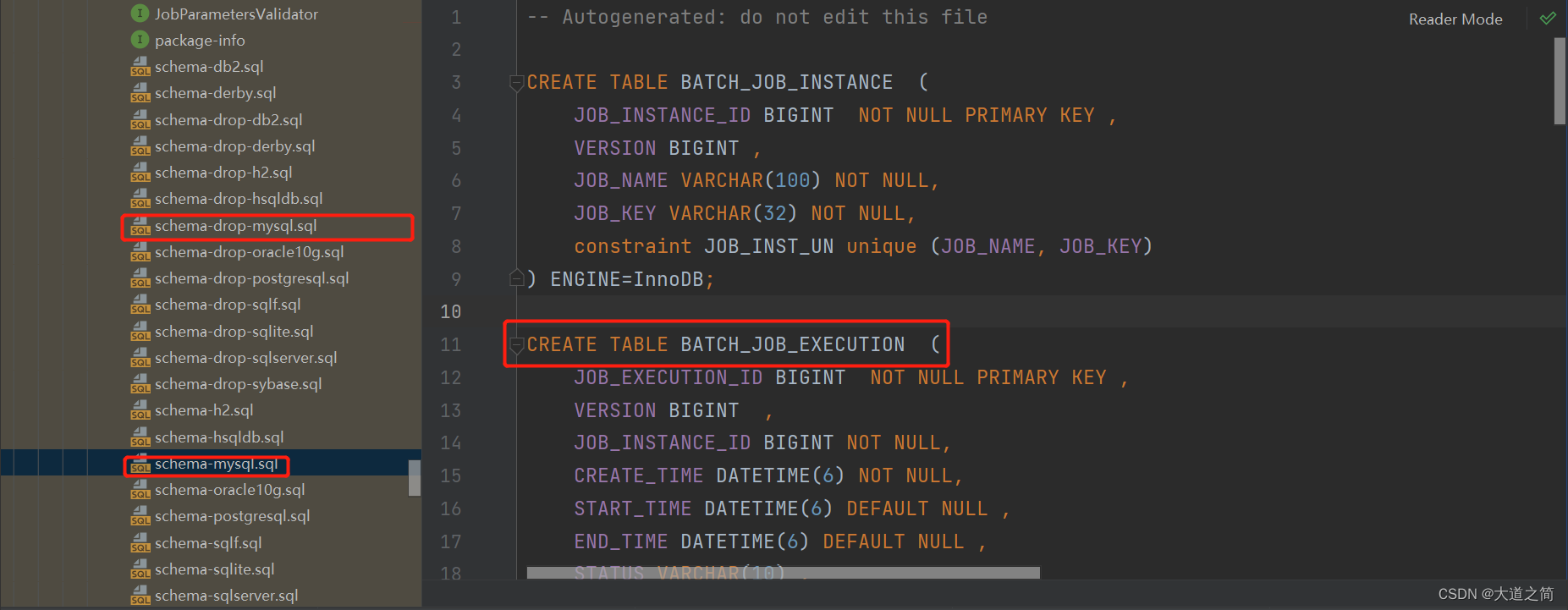
业务数据SQL
CREATE TABLE `student` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`name` varchar(20) NOT NULL,
`age` int(11) NOT NULL,
`sex` varchar(20) NOT NULL,
`address` varchar(100) NOT NULL,
`cid` int(11) NOT NULL,
PRIMARY KEY (`id`) USING BTREE
) ENGINE=InnoDB AUTO_INCREMENT=19 DEFAULT CHARSET=utf8;
INSERT INTO `student`(NAME,age,sex,address,cid) VALUE('Tom',23,'男','湖南',23);
INSERT INTO `student`(NAME,age,sex,address,cid) VALUE('Luck',24,'男','湖北',24);
INSERT INTO `student`(NAME,age,sex,address,cid) VALUE('Jack',25,'男','武汉',25);
INSERT INTO `student`(NAME,age,sex,address,cid) VALUE('User',26,'男','陕西',26);3、业务代码
①、DataBatchJob:读取数据任务
package com.boot.skywalk.job;
import com.boot.skywalk.entity.Student;
import com.boot.skywalk.listener.JobListener;
import lombok.extern.slf4j.Slf4j;
import org.springframework.batch.core.Job;
import org.springframework.batch.core.Step;
import org.springframework.batch.core.configuration.annotation.JobBuilderFactory;
import org.springframework.batch.core.configuration.annotation.StepBuilderFactory;
import org.springframework.batch.core.launch.support.RunIdIncrementer;
import org.springframework.batch.item.ItemProcessor;
import org.springframework.batch.item.ItemReader;
import org.springframework.batch.item.ItemWriter;
import org.springframework.batch.item.database.JpaPagingItemReader;
import org.springframework.batch.item.database.orm.JpaNativeQueryProvider;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Component;
import javax.persistence.EntityManagerFactory;
@Slf4j
@Component
public class DataBatchJob {
/**
* Job构建工厂,用于构建Job
*/
private final JobBuilderFactory jobBuilderFactory;
/**
* Step构建工厂,用于构建Step
*/
private final StepBuilderFactory stepBuilderFactory;
/**
* 实体类管理工工厂,用于访问表格数据
*/
private final EntityManagerFactory emf;
/**
* 自定义的简单Job监听器
*/
private final JobListener jobListener;
/**
* 构造器注入
* @param jobBuilderFactory
* @param stepBuilderFactory
* @param emf
* @param jobListener
*/
@Autowired
public DataBatchJob(JobBuilderFactory jobBuilderFactory, StepBuilderFactory stepBuilderFactory,
EntityManagerFactory emf, JobListener jobListener) {
this.jobBuilderFactory = jobBuilderFactory;
this.stepBuilderFactory = stepBuilderFactory;
this.emf = emf;
this.jobListener = jobListener;
}
/**
* 一个最基础的Job通常由一个或者多个Step组成
*/
public Job dataHandleJob() {
return jobBuilderFactory.get("dataHandleJob").
incrementer(new RunIdIncrementer()).
// start是JOB执行的第一个step
start(handleDataStep()).
// 可以调用next方法设置其他的step,例如:
// next(xxxStep()).
// next(xxxStep()).
// ...
// 设置我们自定义的JobListener
listener(jobListener).
build();
}
/**
* 一个简单基础的Step主要分为三个部分
* ItemReader : 用于读取数据
* ItemProcessor : 用于处理数据
* ItemWriter : 用于写数据
*/
private Step handleDataStep() {
return stepBuilderFactory.get("getData").
// <输入对象, 输出对象> chunk通俗的讲类似于SQL的commit; 这里表示处理(processor)100条后写入(writer)一次
<Student, Student>chunk(100).
// 捕捉到异常就重试,重试100次还是异常,JOB就停止并标志失败
faultTolerant().retryLimit(3).retry(Exception.class).skipLimit(100).skip(Exception.class).
// 指定ItemReader对象
reader(getDataReader()).
// 指定ItemProcessor对象
processor(getDataProcessor()).
// 指定ItemWriter对象
writer(getDataWriter()).
build();
}
/**
* 读取数据
*
* @return ItemReader Object
*/
private ItemReader<? extends Student> getDataReader() {
// 读取数据,这里可以用JPA,JDBC,JMS 等方式读取数据
JpaPagingItemReader<Student> reader = new JpaPagingItemReader<>();
try {
// 这里选择JPA方式读取数据
JpaNativeQueryProvider<Student> queryProvider = new JpaNativeQueryProvider<>();
// 一个简单的 native SQL
queryProvider.setSqlQuery("SELECT * FROM student");
// 设置实体类
queryProvider.setEntityClass(Student.class);
queryProvider.afterPropertiesSet();
reader.setEntityManagerFactory(emf);
// 设置每页读取的记录数
reader.setPageSize(3);
// 设置数据提供者
reader.setQueryProvider(queryProvider);
reader.afterPropertiesSet();
// 所有ItemReader和ItemWriter实现都会在ExecutionContext提交之前将其当前状态存储在其中,
// 如果不希望这样做,可以设置setSaveState(false)
reader.setSaveState(true);
} catch (Exception e) {
log.error("read data error",e);
}
return reader;
}
/**
* 处理数据
*
* @return ItemProcessor Object
*/
private ItemProcessor<Student, Student> getDataProcessor() {
return student -> {
// 模拟处理数据,这里处理就是打印一下
log.info("processor data : " + student.toString());
return student;
};
}
/**
* 写入数据
*
* @return ItemWriter Object
*/
private ItemWriter<Student> getDataWriter() {
return list -> {
for (Student student : list) {
// 模拟写数据,为了演示的简单就不写入数据库了
log.info("write data : " + student);
}
};
}
}线程池配置
②、ExecutorConfiguration
package com.boot.skywalk.config;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.scheduling.concurrent.ThreadPoolTaskExecutor;
@Configuration
public class ExecutorConfiguration {
@Bean
public ThreadPoolTaskExecutor threadPoolTaskExecutor() {
ThreadPoolTaskExecutor threadPoolTaskExecutor = new ThreadPoolTaskExecutor();
threadPoolTaskExecutor.setCorePoolSize(10);
threadPoolTaskExecutor.setMaxPoolSize(20);
threadPoolTaskExecutor.setQueueCapacity(500);
threadPoolTaskExecutor.setThreadNamePrefix("Data-Job");
return threadPoolTaskExecutor;
}
}③、监听器:任务执行前后做相关统计.
package com.boot.skywalk.listener;
import lombok.extern.slf4j.Slf4j;
import org.springframework.batch.core.BatchStatus;
import org.springframework.batch.core.JobExecution;
import org.springframework.batch.core.JobExecutionListener;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.scheduling.concurrent.ThreadPoolTaskExecutor;
import org.springframework.stereotype.Component;
@Slf4j
@Component
public class JobListener implements JobExecutionListener {
private final ThreadPoolTaskExecutor threadPoolTaskExecutor;
private long startTime;
@Autowired
public JobListener(ThreadPoolTaskExecutor threadPoolTaskExecutor){
this.threadPoolTaskExecutor=threadPoolTaskExecutor;
}
/**
* 该方法会在job开始前执行
*/
@Override
public void beforeJob(JobExecution jobExecution) {
startTime = System.currentTimeMillis();
log.info("job before " + jobExecution.getJobParameters());
}
/**
* 该方法会在job结束后执行
*/
@Override
public void afterJob(JobExecution jobExecution) {
log.info("JOB STATUS : {}", jobExecution.getStatus());
if (jobExecution.getStatus() == BatchStatus.COMPLETED) {
log.info("JOB FINISHED");
threadPoolTaskExecutor.destroy();
} else if (jobExecution.getStatus() == BatchStatus.FAILED) {
log.info("JOB FAILED");
}
log.info("Job Cost Time : {}/ms", (System.currentTimeMillis() - startTime));
}
}定时任务执行job,可以使用XXL-JOB、Quartz来执行,这里使用Spring Task. ④、BatchTask
package com.boot.skywalk.task;
import com.boot.skywalk.job.DataBatchJob;
import lombok.extern.slf4j.Slf4j;
import org.springframework.batch.core.Job;
import org.springframework.batch.core.JobExecution;
import org.springframework.batch.core.JobParameters;
import org.springframework.batch.core.JobParametersBuilder;
import org.springframework.batch.core.JobParametersInvalidException;
import org.springframework.batch.core.launch.JobLauncher;
import org.springframework.batch.core.repository.JobExecutionAlreadyRunningException;
import org.springframework.batch.core.repository.JobInstanceAlreadyCompleteException;
import org.springframework.batch.core.repository.JobRestartException;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.scheduling.annotation.Scheduled;
import org.springframework.stereotype.Component;
@Slf4j
@Component
public class BatchTask {
@Autowired
private JobLauncher jobLauncher;
@Autowired
private DataBatchJob dataBatchJob;
@Scheduled(cron = "0 */1 * * * ?")
public void runBatch() throws JobParametersInvalidException, JobExecutionAlreadyRunningException,
JobRestartException, JobInstanceAlreadyCompleteException {
log.info("定时任务执行了...");
// 在运行一个job的时候需要添加至少一个参数,这个参数最后会被写到batch_job_execution_params表中,
// 不添加这个参数的话,job不会运行,并且这个参数在表中中不能重复,若设置的参数已存在表中,则会抛出异常,
// 所以这里才使用时间戳作为参数
JobParameters jobParameters = new JobParametersBuilder()
.addLong("timestamp", System.currentTimeMillis())
.toJobParameters();
// 获取job并运行
Job job = dataBatchJob.dataHandleJob();
JobExecution execution = jobLauncher.run(job, jobParameters);
log.info("定时任务结束. Exit Status : {}", execution.getStatus());
}
}⑤、application中添加如下配置.
spring:
datasource:
# SpringBoot2.x默认是Hikari,无需加下面一行
type: com.zaxxer.hikari.HikariDataSource
username: root
password: XXXXXXXX
url: jdbc:mysql://localhost:3306/test?useUnicode=true&characterEncoding=utf-8&useSSL=false
driver-class-name: com.mysql.jdbc.Driver
# jpa模式
jpa:
open-in-view: true
show-sql: true
hibernate:
ddl-auto: update
database: mysql
# batch
# 禁止项目启动时运行job
batch:
job:
enabled: false⑥、启动类开启Spring Batch、Spring Task
@EnableScheduling
@EnableBatchProcessing
运行项目如下:
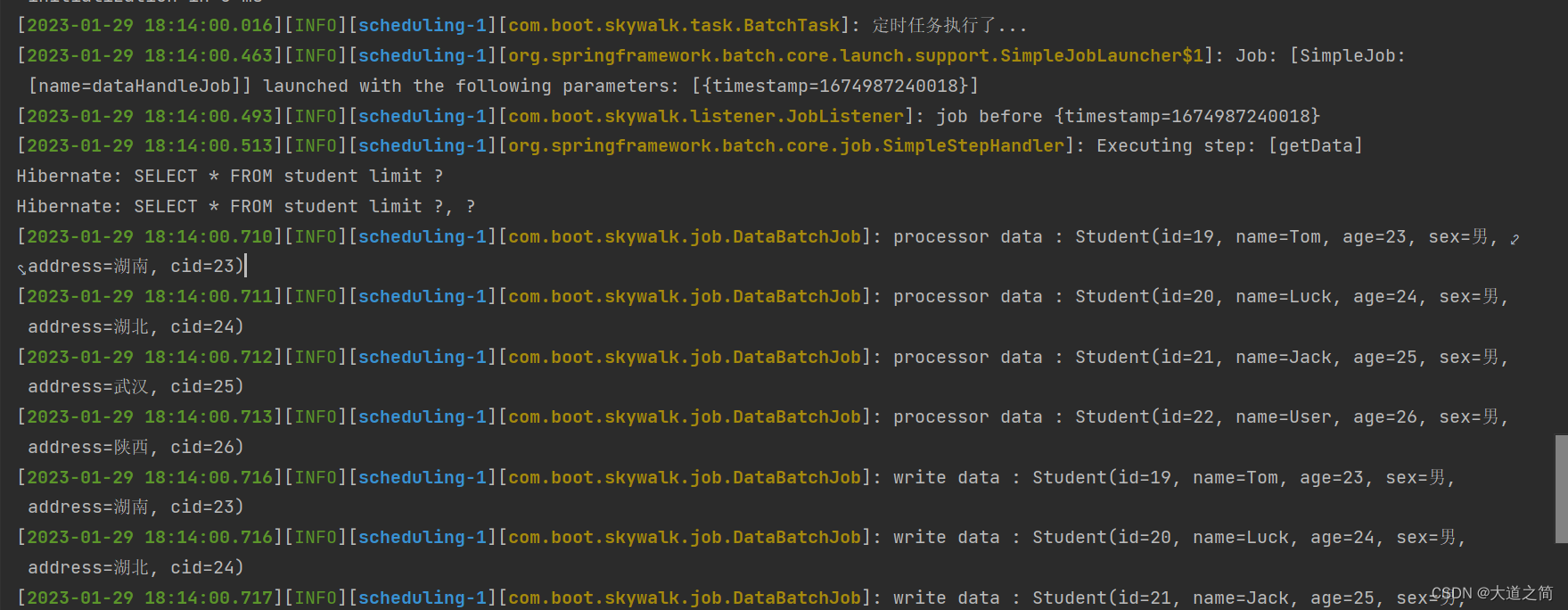
 执行结果表记录
执行结果表记录
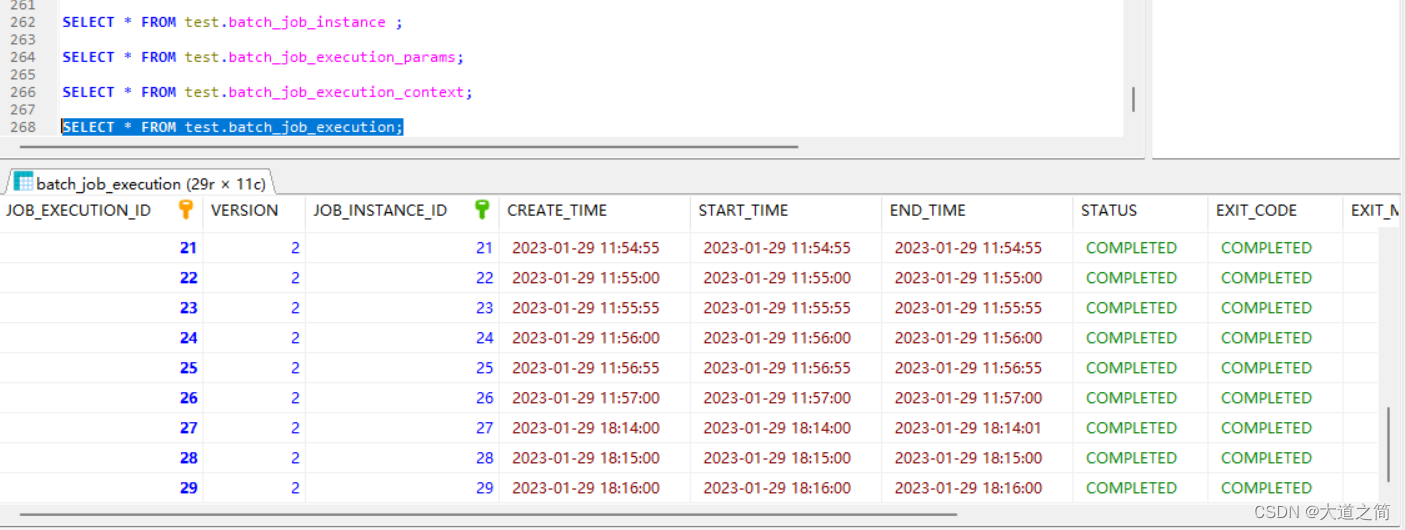
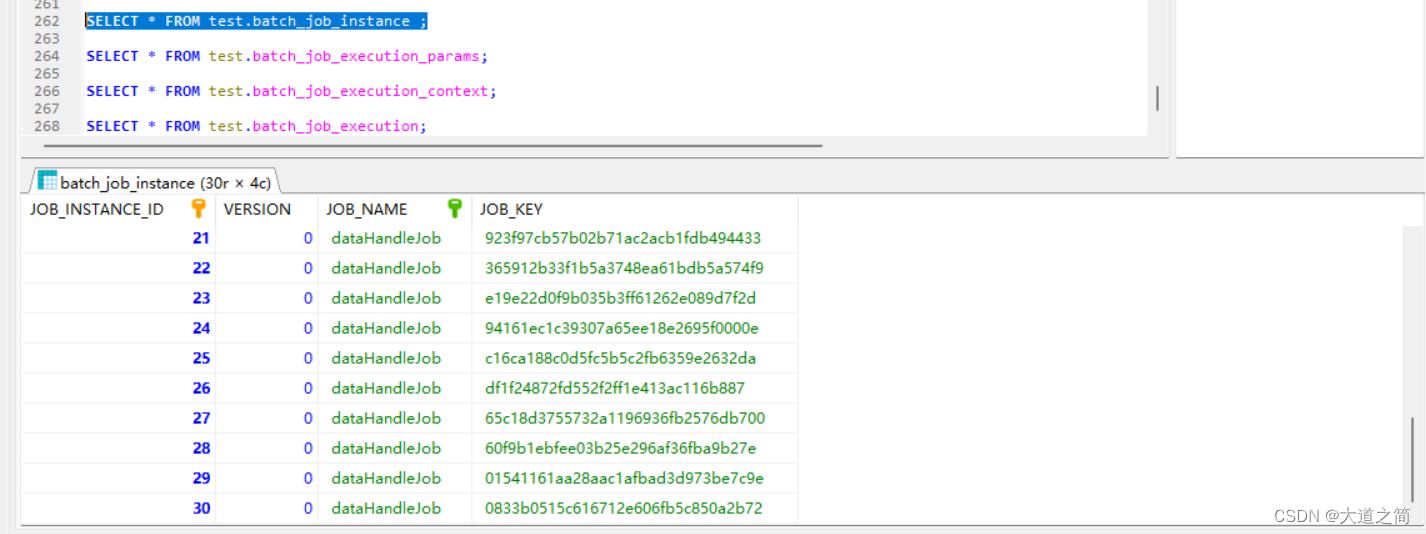
四、扩展,监听读取数据、处理数据、写入数据
1、ItemReaderListener

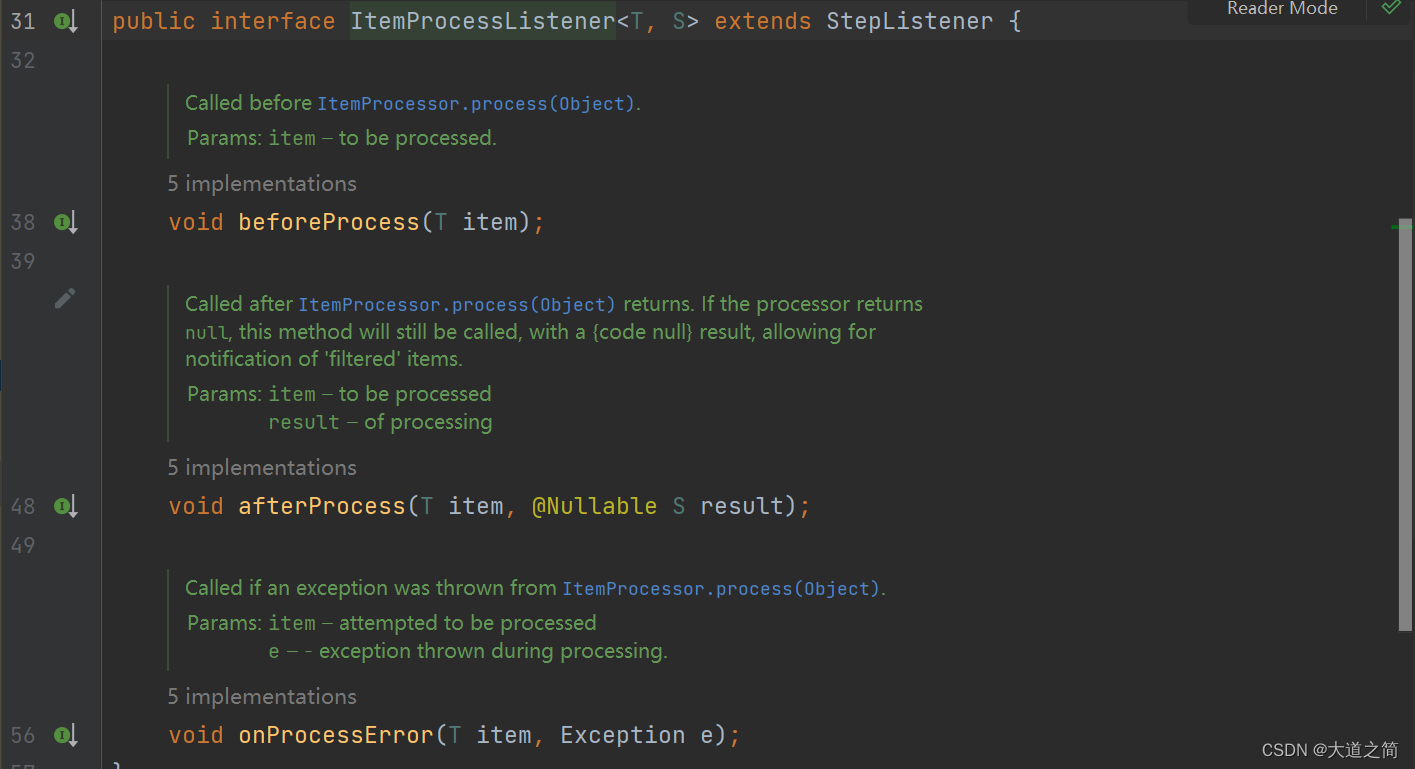
2、ItemProcesserListener
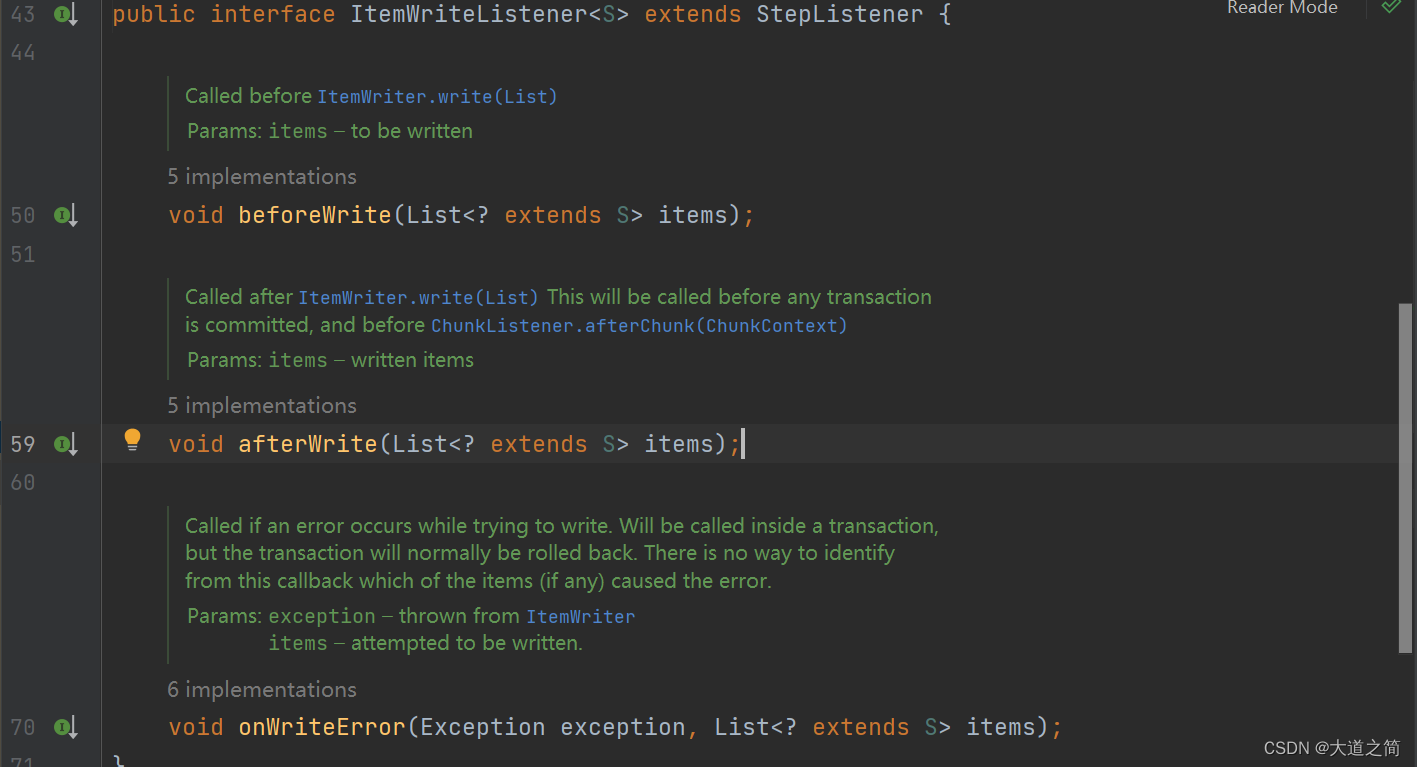
 3、ItemWriteListener
3、ItemWriteListener
Spring Batch为我们提供了许多开箱即用的Reader和Writer,满足众多业务开发场景。