使用 Solr 9 中的数据导入处理程序(DIH)
DIH(Data Import Handler)提供了一种可配置的方式向 Solr 中导入数据。
从 Solr 9 开始,数据导入处理程序(DIH)已经不再直接包含在 Solr 中,而是作为一个独立的项目存在。
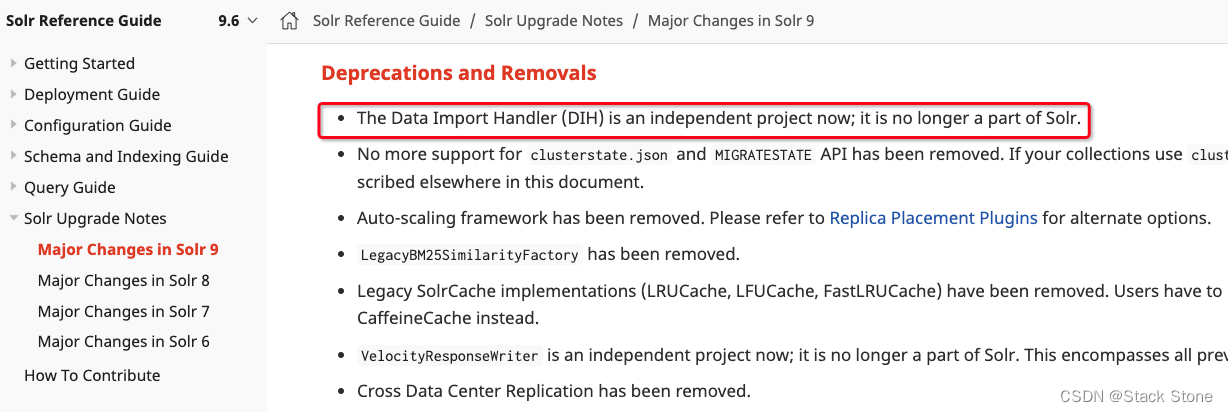
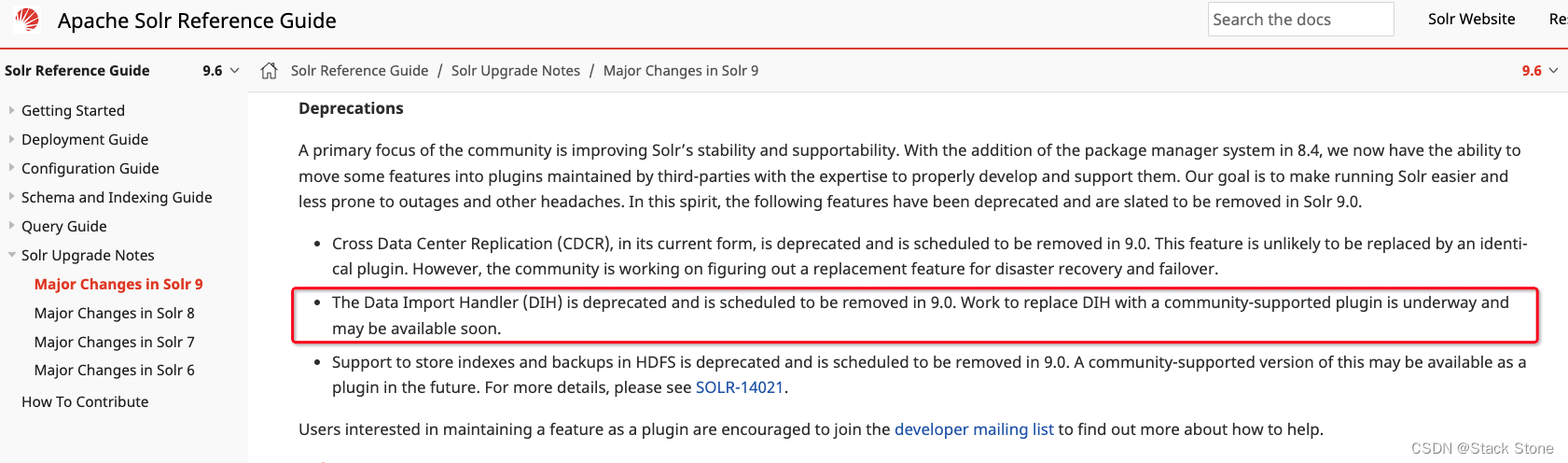
本文将详细介绍如何在 Solr 9 中配置和使用 DIH,包括如何设置 Solr 环境和导入数据的具体步骤。
关于独立出来的 DIH 源码可以从:https://github.com/SearchScale/dataimporthandler?tab=readme-ov-file 中获取。
本示例将展示如何从源码启动 Solr 项目并配置 DIH。
安装和启动 Solr 服务
你可以自己在本地下载好 Solr 服务部署,截止到本博客的编写时间,Solr 的最新版是 9.6.1,我这里直接从 github 上 clone Solr 的源码,并将分支切到 releases/solr/9.6.1 版本标签,对应命令如下:
git checkout releases/solr/9.6.1
由于 Solr9 项目构建已从原来的 ant 方式更改为了 gradle 方式,我们将项目导入到 IDEA 中后,IDEA 会自动识别 gradle 项目。
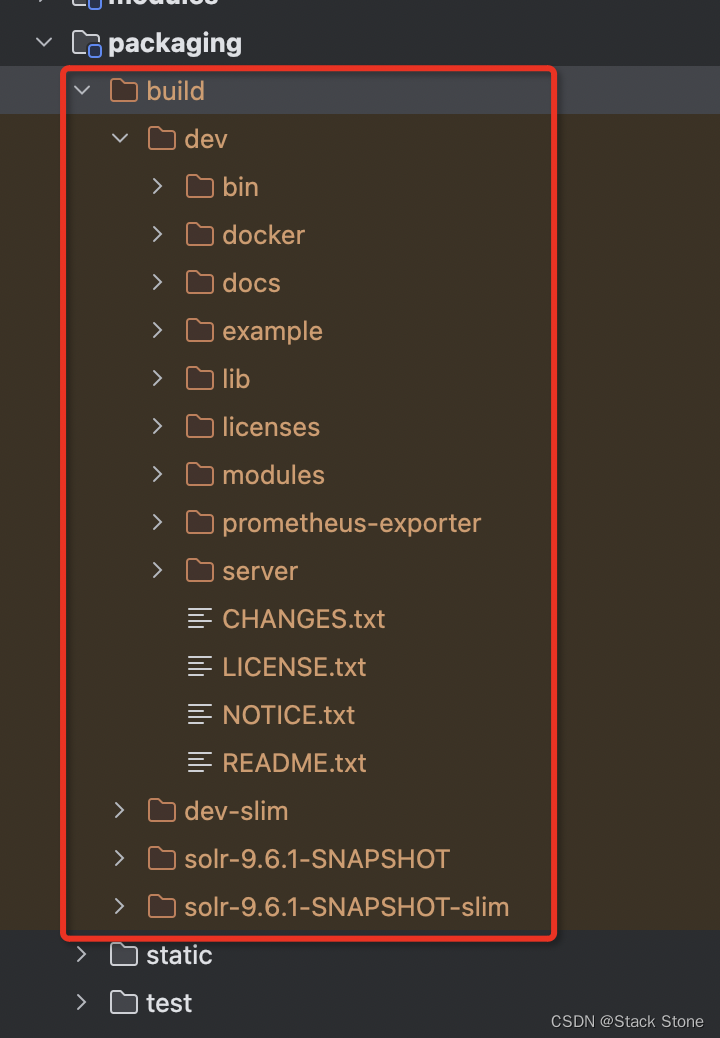
在项目的根目录下我们可以执行 ./gradlew dev 命令,此命令执行后再项目的 solr/packaging/build 目录下会生成编译打包后的项目结构。
如下所示:
定义 SolrHome 目录并源码启动 Solr 服务
首先我们需要在本地电脑上选择一个目录作为我们的 SolrHome 目录,这里我选择 /Workspace/SolrHome/Solr9/test_demo 作为我的 SolrHome 目录,我们现在创建/Workspace/SolrHome/Solr9/test_demo 空目录,如下所示:
之后在项目的 solr/server/solr 目录下找到 solr.xml 将其拷贝到 /Workspace/SolrHome/Solr9/test_demo 目录下,如下所示:
IDEA 双击 Shift 键,查找 StartSolrJetty java 类,如下所示:
我们需要修改这个测试启动类,在代码中设置 SolrHome 和 webapp 的地址,修改后的内容如下:
public class StartSolrJetty {
private static final Logger log = LoggerFactory.getLogger(MethodHandles.lookup().lookupClass());
public static void main(String[] args) {
//System.setProperty("solr.solr.home", "../../../example/solr");
// 此处设置 SolrHome 地址
System.setProperty("solr.solr.home", "/Workspace/SolrHome/Solr9/test_demo");
Server server = new Server();
ServerConnector connector = new ServerConnector(server, new HttpConnectionFactory());
// Set some timeout options to make debugging easier.
connector.setIdleTimeout(1000 * 60 * 60);
connector.setPort(8983);
server.setConnectors(new Connector[] {connector});
WebAppContext bb = new WebAppContext();
bb.setServer(server);
bb.setContextPath("/solr");
//bb.setWar("webapp/web");
// 此处设置项目目录下的 solr/webapp/web 的绝对路径地址
bb.setWar("/Workspace/source-code/solr/solr/webapp/web");
// // START JMX SERVER
// if( true ) {
// MBeanServer mBeanServer = ManagementFactory.getPlatformMBeanServer();
// MBeanContainer mBeanContainer = new MBeanContainer(mBeanServer);
// server.getContainer().addEventListener(mBeanContainer);
// mBeanContainer.start();
// }
server.setHandler(bb);
try {
System.out.println(">>> STARTING EMBEDDED JETTY SERVER, PRESS ANY KEY TO STOP");
server.start();
while (System.in.available() == 0) {
Thread.sleep(5000);
}
server.stop();
server.join();
} catch (Exception e) {
log.error("failed to start", e);
System.exit(100);
}
}
}
修改好后,我们启动这个测试类的 main 方法,之后浏览器可以访问 http://localhost:8983/solr/#/,页面内容如下:
创建 SolrCore 目录并定义 Schema
在创建的 SolrHome 目录下,我们新建一个 movie_core_1 的子目录,如下所示:
之后复制Solr项目中 solr/configsets/_default/conf 目录下的配置文件到上面创建的 movie_core_1 目录下,如下图所示:
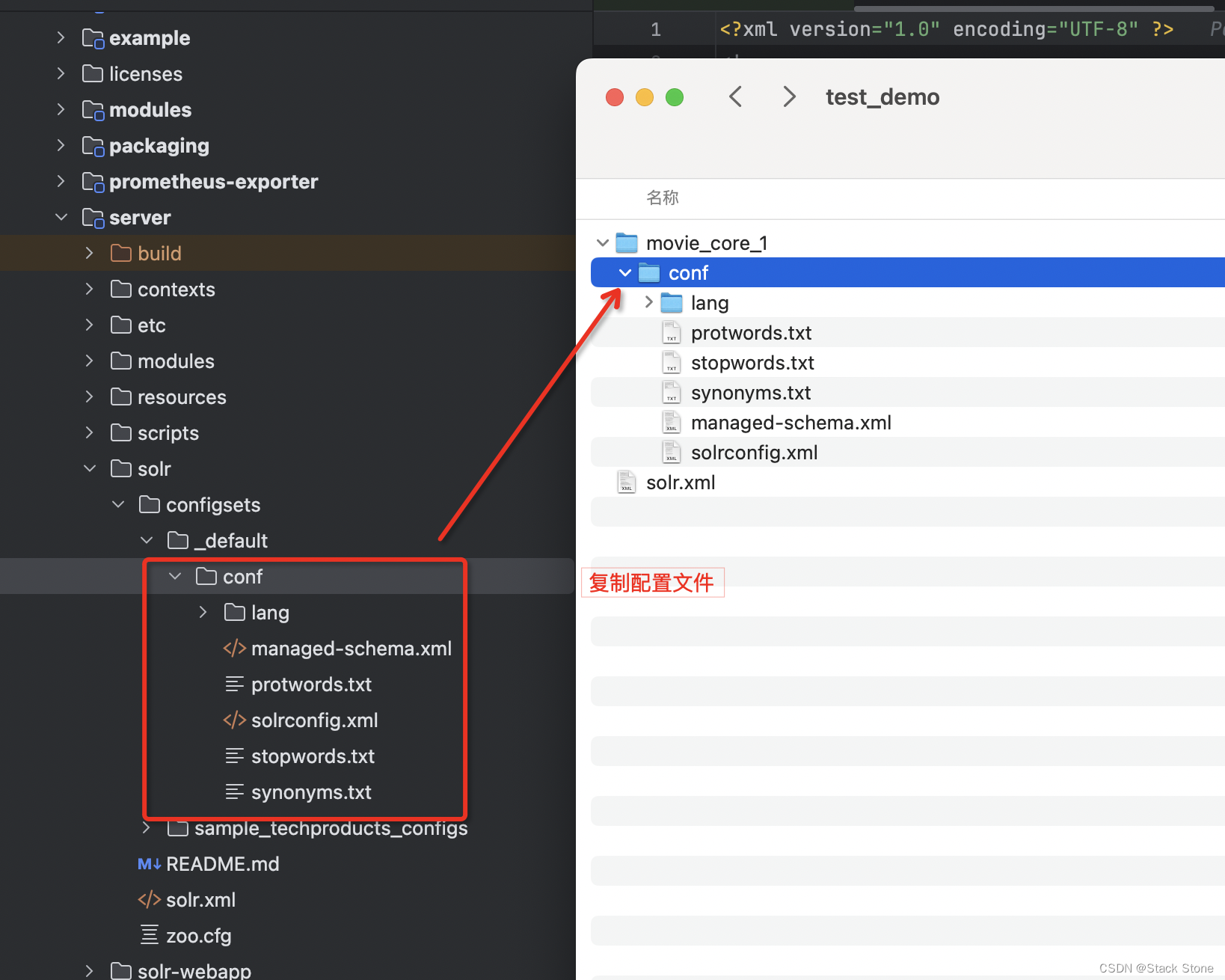
编辑 managed-schema.xml 文件,这里我删除了这个文件所有多余的配置,内容如下:
<?xml version="1.0" encoding="UTF-8" ?>
<schema name="movie_config_demo" version="1.6">
<!-- 定义字段类型 -->
<types>
<!-- 字符串类型,适用于文本,支持排序和docValues -->
<fieldType name="string" class="solr.StrField" sortMissingLast="true" docValues="true" />
<!-- 整数点类型,适用于整数,支持docValues -->
<fieldType name="pint" class="solr.IntPointField" docValues="true"/>
<!-- 长整数点类型,适用于长整数,支持docValues -->
<fieldType name="plong" class="solr.LongPointField" docValues="true"/>
<!-- 双精度浮点数点类型,适用于浮点数,支持docValues -->
<fieldType name="pdouble" class="solr.DoublePointField" docValues="true"/>
<!-- 日期点类型,适用于日期,支持docValues -->
<fieldType name="pdate" class="solr.DatePointField" docValues="true"/>
<!-- 文本字段类型,用于需要分词的文本 -->
<fieldType name="text" class="solr.TextField" omitNorms="true">
<!-- 索引时的分析器配置 -->
<analyzer type="index">
<tokenizer class="solr.StandardTokenizerFactory"/>
<filter class="solr.StopFilterFactory" ignoreCase="true" words="stopwords.txt" />
<filter class="solr.LowerCaseFilterFactory"/>
</analyzer>
<!-- 查询时的分析器配置 -->
<analyzer type="query">
<tokenizer class="solr.StandardTokenizerFactory"/>
<filter class="solr.StopFilterFactory" ignoreCase="true" words="stopwords.txt" />
<filter class="solr.SynonymGraphFilterFactory" synonyms="synonyms.txt" ignoreCase="true" expand="true"/>
<filter class="solr.LowerCaseFilterFactory"/>
</analyzer>
</fieldType>
</types>
<!-- 定义字段 -->
<fields>
<!-- 特殊的系统字段,用于乐观并发控制 -->
<field name="_version_" type="plong" indexed="false" stored="false"/>
<!-- 电影ID,唯一标识符 -->
<field name="MOVIE_ID" type="string" indexed="true" stored="true" required="true" multiValued="false"/>
<!-- 电影名称 -->
<field name="NAME" type="text" indexed="true" stored="true" required="true" multiValued="false"/>
<!-- 电影别名 -->
<field name="ALIAS" type="text" indexed="true" stored="true" multiValued="false"/>
<!-- 电影封面图片 -->
<field name="COVER" type="string" indexed="false" stored="true" multiValued="false"/>
<!-- 导演名单 -->
<field name="DIRECTORS" type="string" indexed="true" stored="true" multiValued="false"/>
<!-- 豆瓣评分 -->
<field name="DOUBAN_SCORE" type="pdouble" indexed="true" stored="true" multiValued="false"/>
<!-- 豆瓣投票数 -->
<field name="DOUBAN_VOTES" type="pint" indexed="true" stored="true" multiValued="false"/>
<!-- 电影类型 -->
<field name="GENRES" type="string" indexed="true" stored="true" multiValued="false"/>
<!-- 电影语言 -->
<field name="LANGUAGES" type="string" indexed="true" stored="true" multiValued="false"/>
<!-- 电影时长 -->
<field name="MINS" type="pdouble" indexed="true" stored="true" multiValued="false"/>
<!-- 官方网站 -->
<field name="OFFICIAL_SITE" type="string" indexed="false" stored="true" multiValued="false"/>
<!-- 制作地区 -->
<field name="REGIONS" type="string" indexed="true" stored="true" multiValued="false"/>
<!-- 上映日期 -->
<field name="RELEASE_DATE" type="pdate" indexed="true" stored="true" multiValued="false"/>
<!-- 剧情简介 -->
<field name="STORYLINE" type="text" indexed="true" stored="true" multiValued="false"/>
<!-- 标签 -->
<field name="TAGS" type="string" indexed="true" stored="true" multiValued="false"/>
<!-- 上映年份 -->
<field name="YEAR" type="pint" indexed="true" stored="true" multiValued="false"/>
<!-- 演员ID列表 -->
<field name="ACTOR_IDS" type="string" indexed="true" stored="true" multiValued="false"/>
<!-- 导演ID列表 -->
<field name="DIRECTOR_IDS" type="string" indexed="true" stored="true" multiValued="false"/>
</fields>
<!-- 定义主键 -->
<uniqueKey>MOVIE_ID</uniqueKey>
</schema>
由于上面的 schema 配置没有定义 text_general 字段,所以我们还需要修改 solrconfig.xml 配置文件,注释掉下面的代码内容:
<!--
<updateProcessor class="solr.AddSchemaFieldsUpdateProcessorFactory" name="add-schema-fields">
<lst name="typeMapping">
<str name="valueClass">java.lang.String</str>
<str name="fieldType">text_general</str>
<lst name="copyField">
<str name="dest">*_str</str>
<int name="maxChars">256</int>
</lst>
Use as default mapping instead of defaultFieldType
<bool name="default">true</bool>
</lst>
<lst name="typeMapping">
<str name="valueClass">java.lang.Boolean</str>
<str name="fieldType">booleans</str>
</lst>
<lst name="typeMapping">
<str name="valueClass">java.util.Date</str>
<str name="fieldType">pdates</str>
</lst>
<lst name="typeMapping">
<str name="valueClass">java.lang.Long</str>
<str name="valueClass">java.lang.Integer</str>
<str name="fieldType">plongs</str>
</lst>
<lst name="typeMapping">
<str name="valueClass">java.lang.Number</str>
<str name="fieldType">pdoubles</str>
</lst>
</updateProcessor>
-->
<!--
<updateRequestProcessorChain name="add-unknown-fields-to-the-schema" default="${update.autoCreateFields:true}"
processor="uuid,remove-blank,field-name-mutating,parse-boolean,parse-long,parse-double,parse-date,add-schema-fields">
<processor class="solr.LogUpdateProcessorFactory"/>
<processor class="solr.DistributedUpdateProcessorFactory"/>
<processor class="solr.RunUpdateProcessorFactory"/>
</updateRequestProcessorChain>
-->
之后我们在 Solr Admin 页面创建这个 core,如下所示:
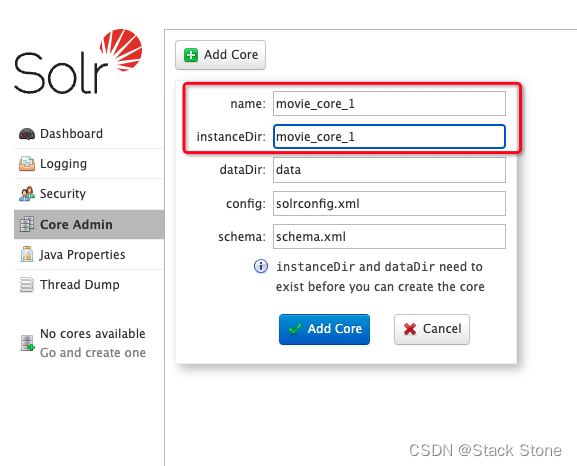
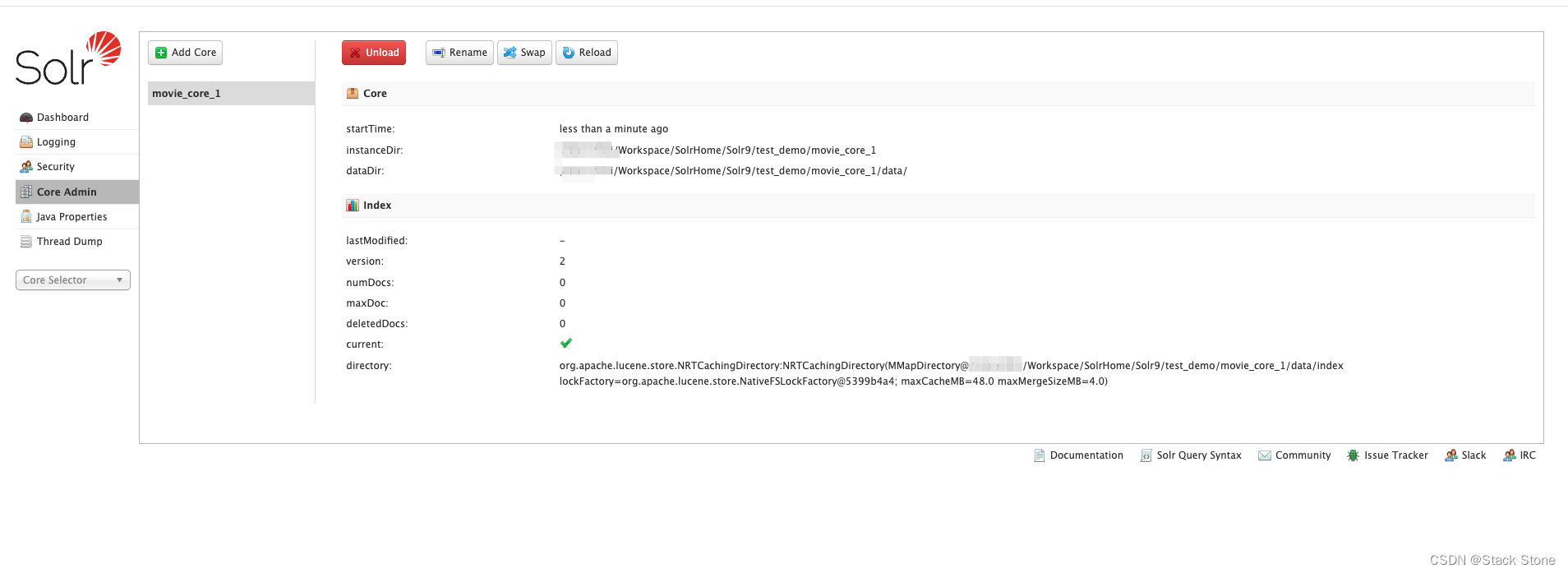
点击 Add Core ,创建好后如下所示:
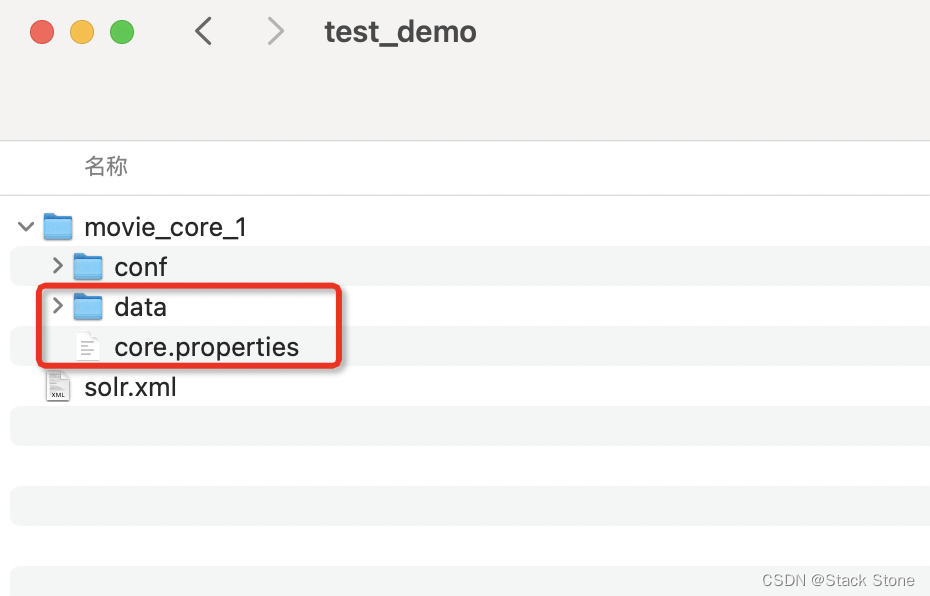
当然此时会在 movie_core_1目录下生成 data 索引目录以及 core.properties 属性文件,如下所示:
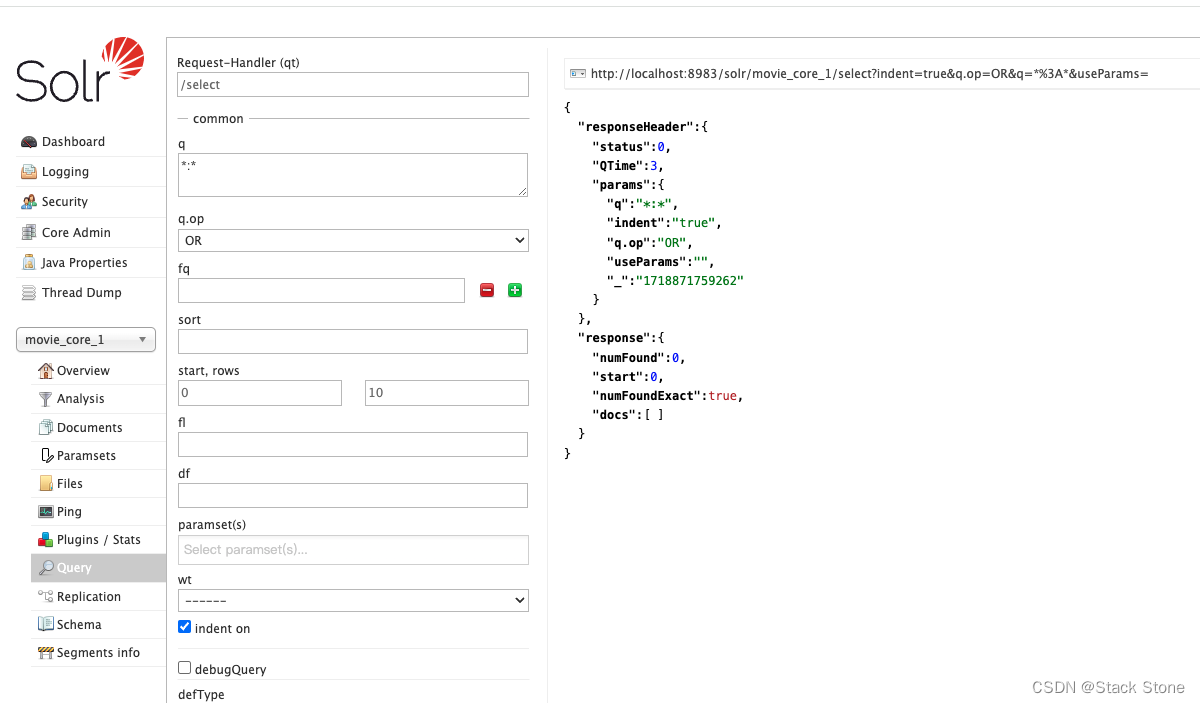
查询测试:
配置 DIH
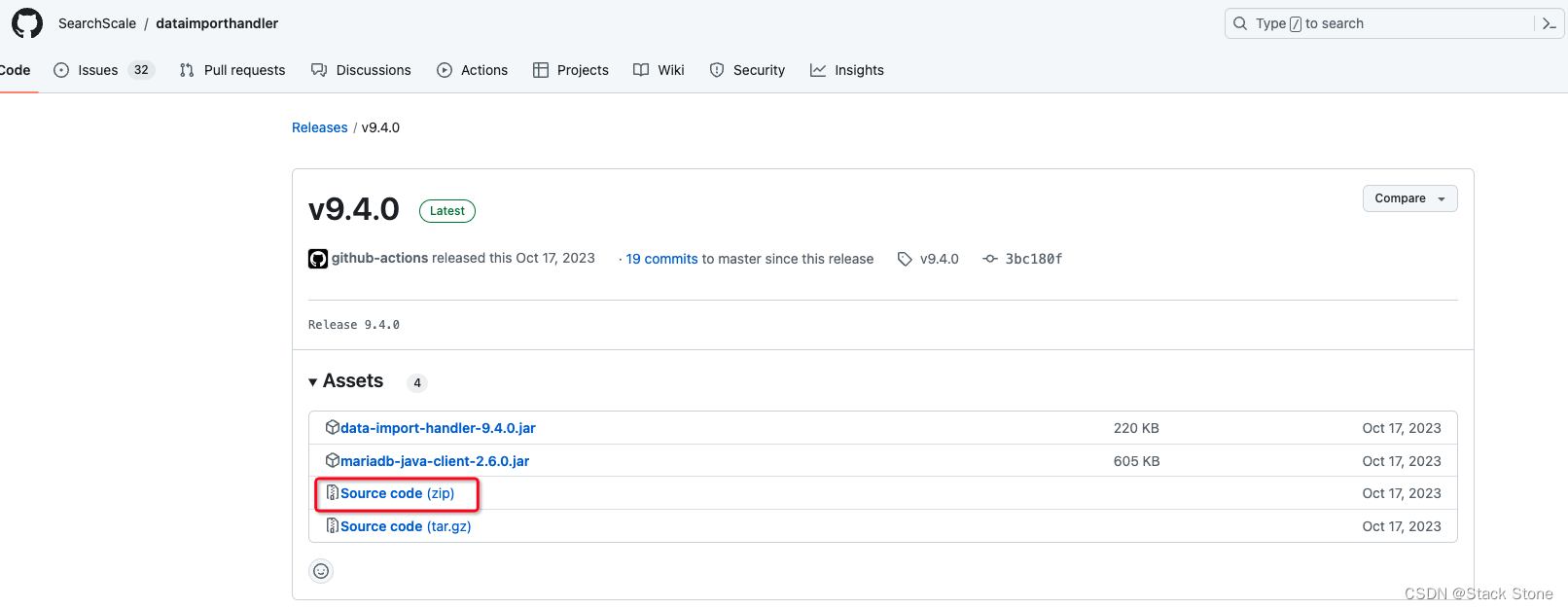
访问 https://github.com/SearchScale/dataimporthandler?tab=readme-ov-file 下载我们需要的 DIH jar 包,这里我直接下载的是源码:
打开下载好的源码:
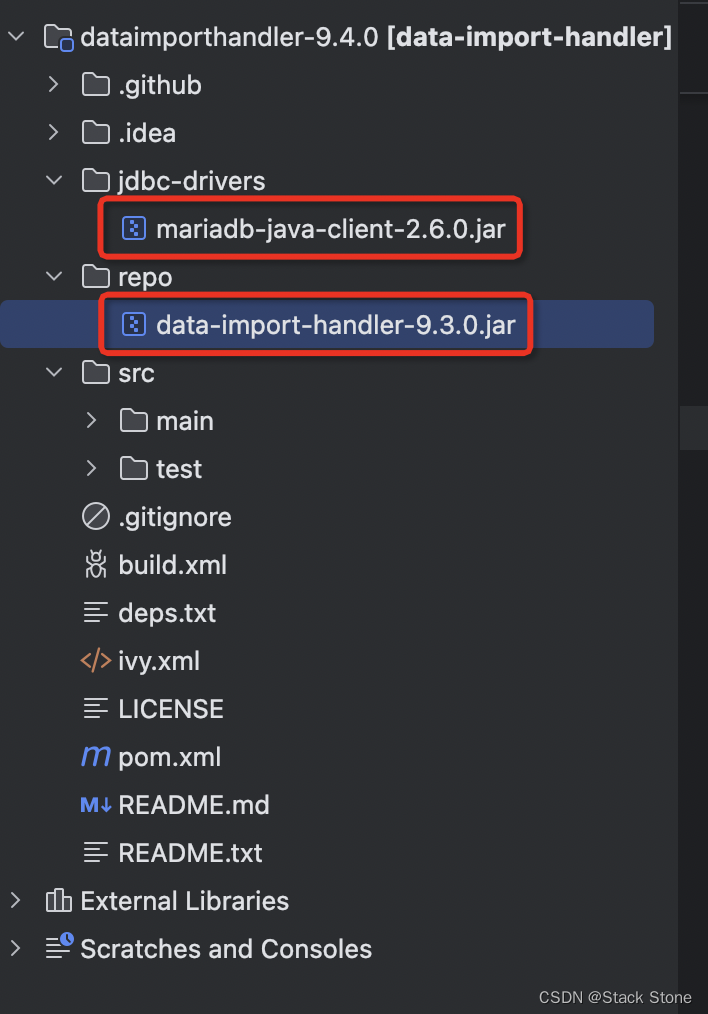
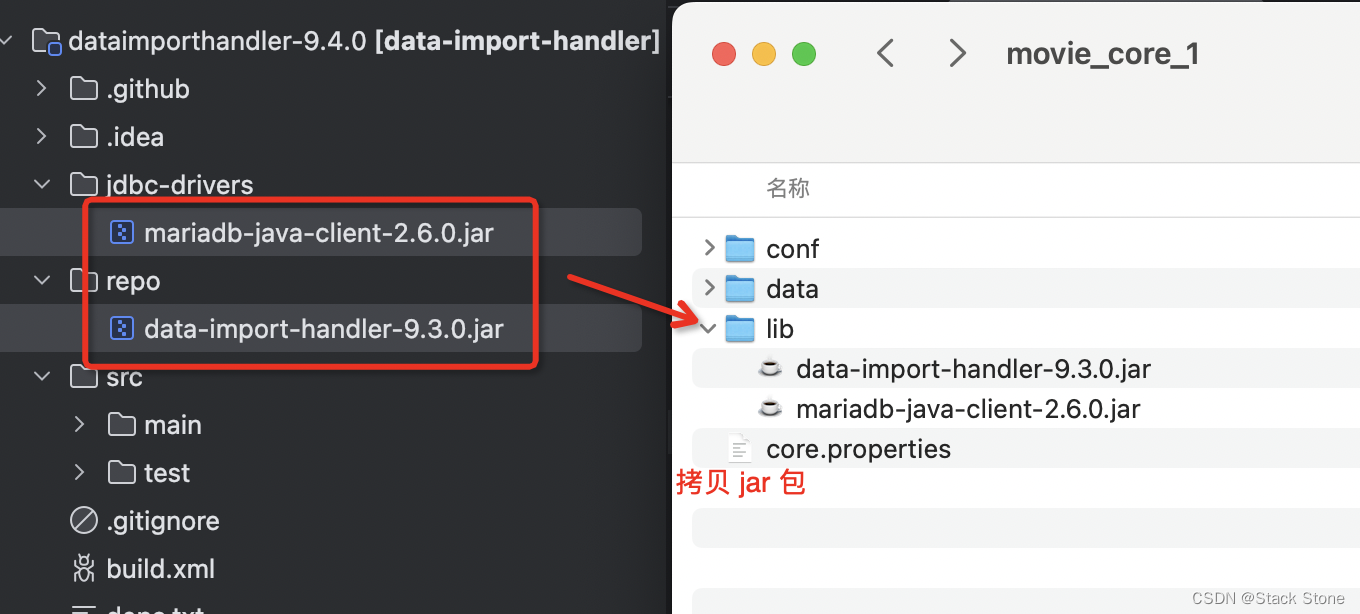
可以看到项目中有 mariadb-java-client-2.6.0.jar 和 data-import-handler-9.3.0.jar 两个 jar 包文件,我们需要将这两个 jar 包拷贝至 movie_core_1/lib 目录下,如下所示:
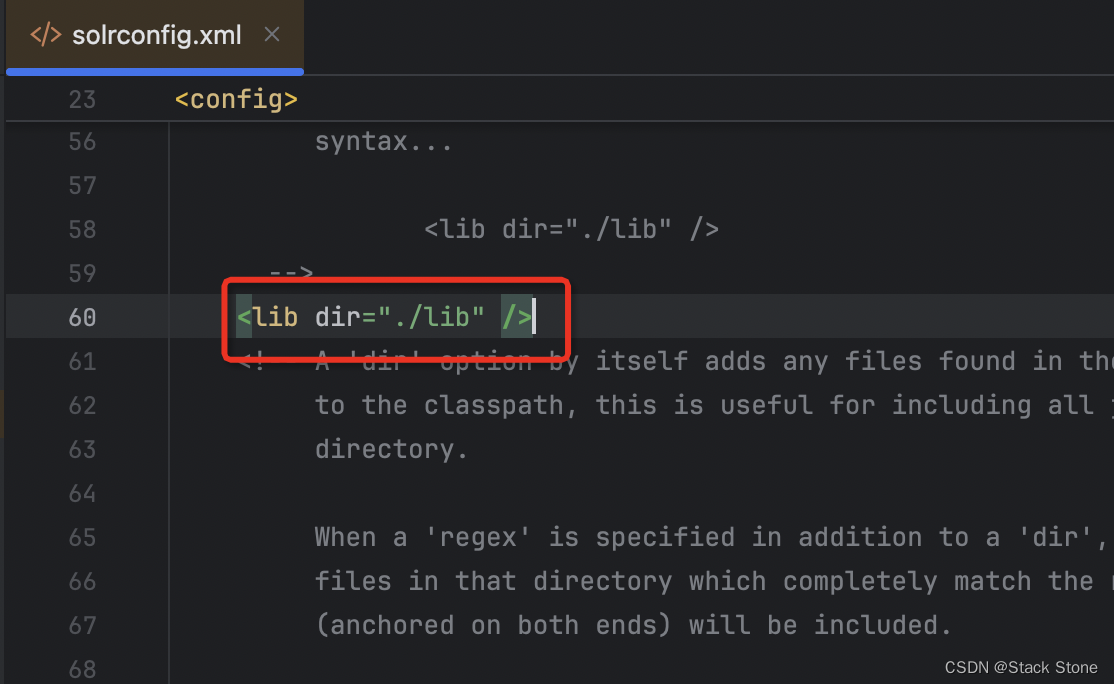
编写 solrconfig.xml 文件,新增如下配置:
<lib dir="./lib" />
如图:
<requestHandler name="/dataimport" class="org.apache.solr.handler.dataimport.DataImportHandler">
<lst name="defaults">
<str name="config">data-config.xml</str>
</lst>
</requestHandler>
如图:
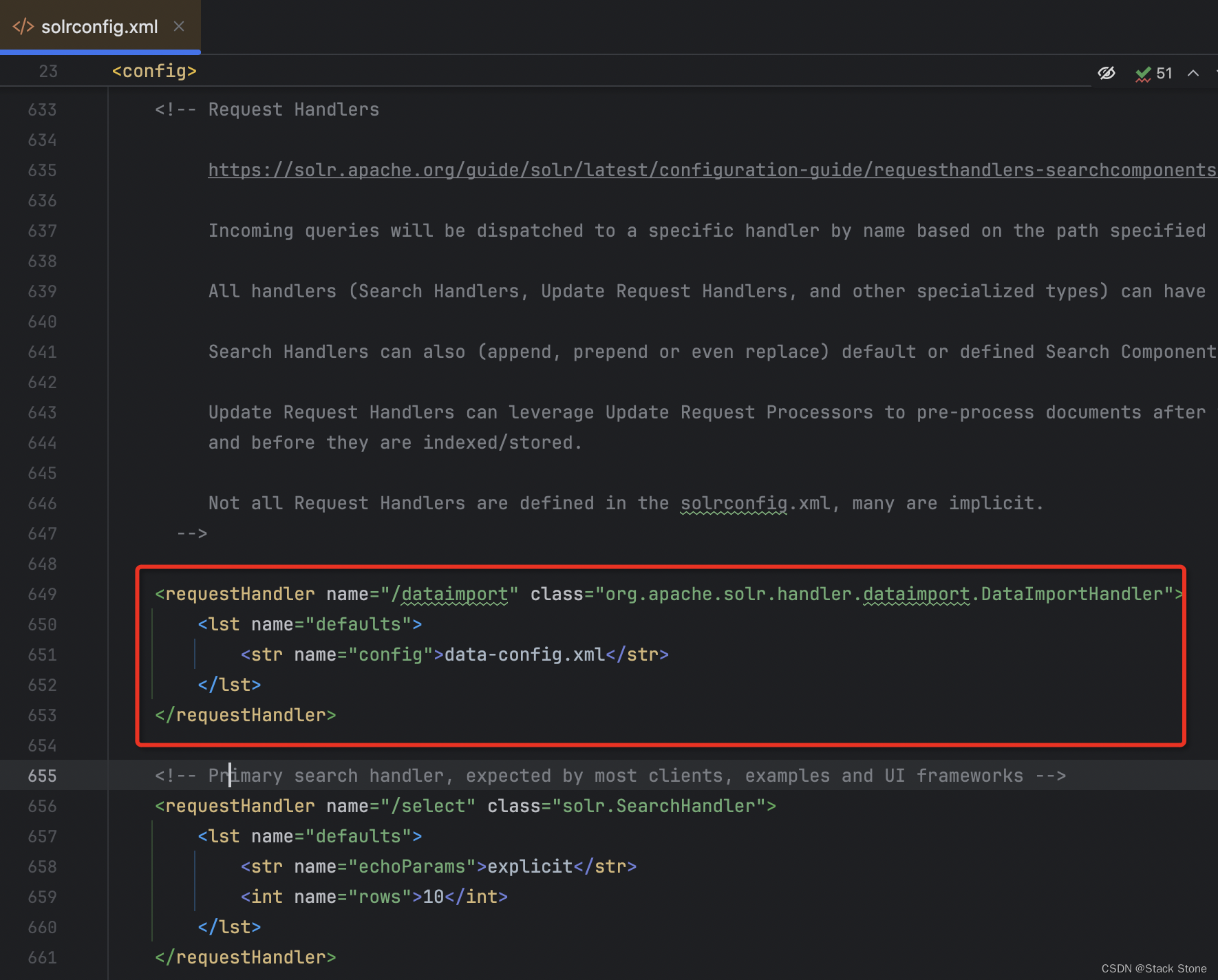
之后再新增一个 data-config.xml 文件到 movie_core_1/conf 目录下,data-config.xml 内容如下:
<dataConfig>
<dataSource type="JdbcDataSource" driver="com.mysql.cj.jdbc.Driver"
url="jdbc:mysql://localhost:3306/movies" user="root" password="12345678" />
<document>
<entity name="movie"
query="SELECT movie_id, name, alias, cover, directors, douban_score, douban_votes, genres,
languages, mins, official_site, regions, release_date, storyline, tags,
CAST(year AS CHAR) AS year, actor_ids, director_ids FROM movie">
<field column="movie_id" name="movie_id" />
<field column="name" name="name" />
<field column="alias" name="alias" />
<field column="cover" name="cover" />
<field column="directors" name="directors" />
<field column="douban_score" name="douban_score" />
<field column="douban_votes" name="douban_votes" />
<field column="genres" name="genres" />
<field column="languages" name="languages" />
<field column="mins" name="mins" />
<field column="official_site" name="official_site" />
<field column="regions" name="regions" />
<field column="release_date" name="release_date" dateTimeFormat="yyyy-MM-dd" />
<field column="storyline" name="storyline" />
<field column="tags" name="tags" />
<field column="year" name="year" />
<field column="actor_ids" name="actor_ids" />
<field column="director_ids" name="director_ids" />
</entity>
</document>
</dataConfig>
注意: 这里我是从 mysql 中查询表数据进行索引,所以需要 MySQL 的驱动包,需要从 https://mvnrepository.com/ 中下载 MySQL 的驱动 jar 包,将其拷贝至 movie_core_1/lib 目录下: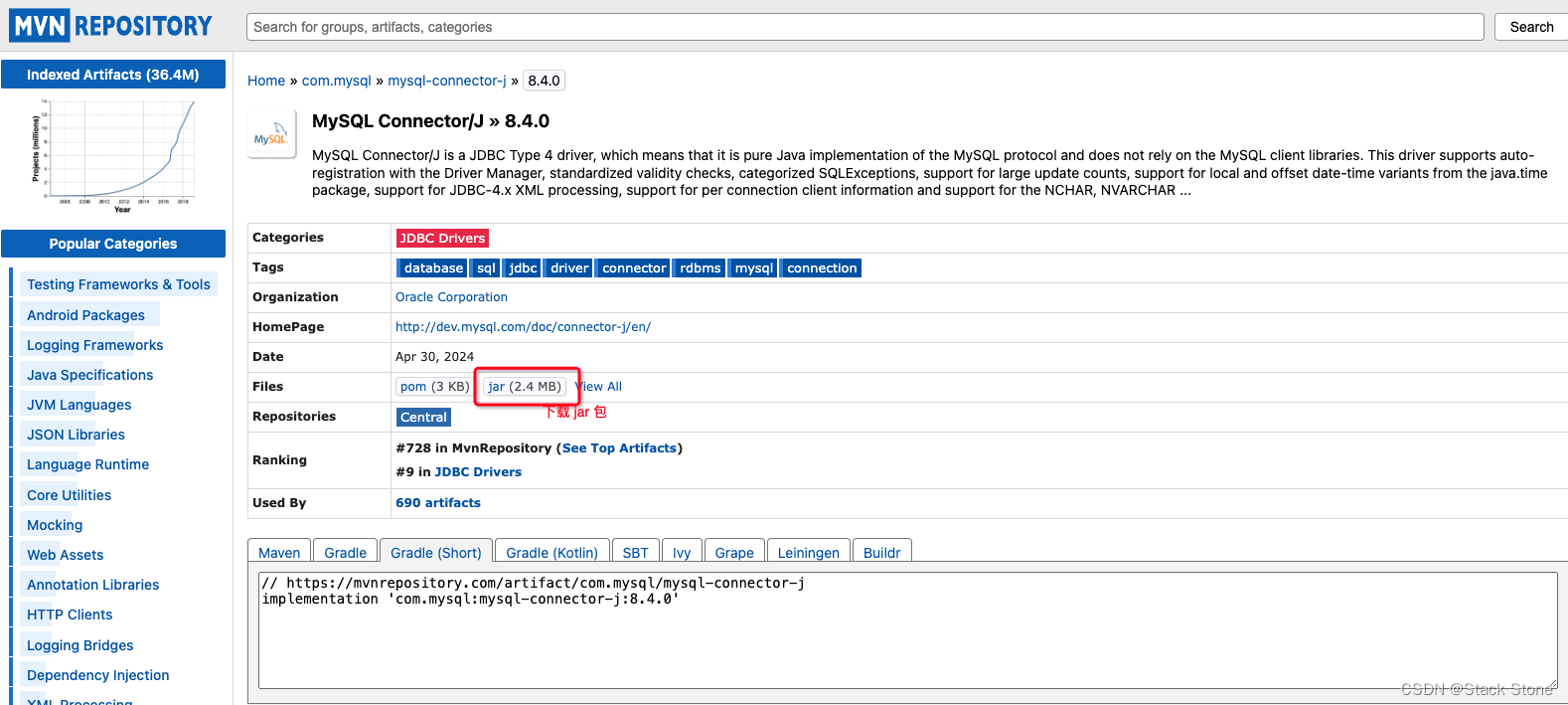
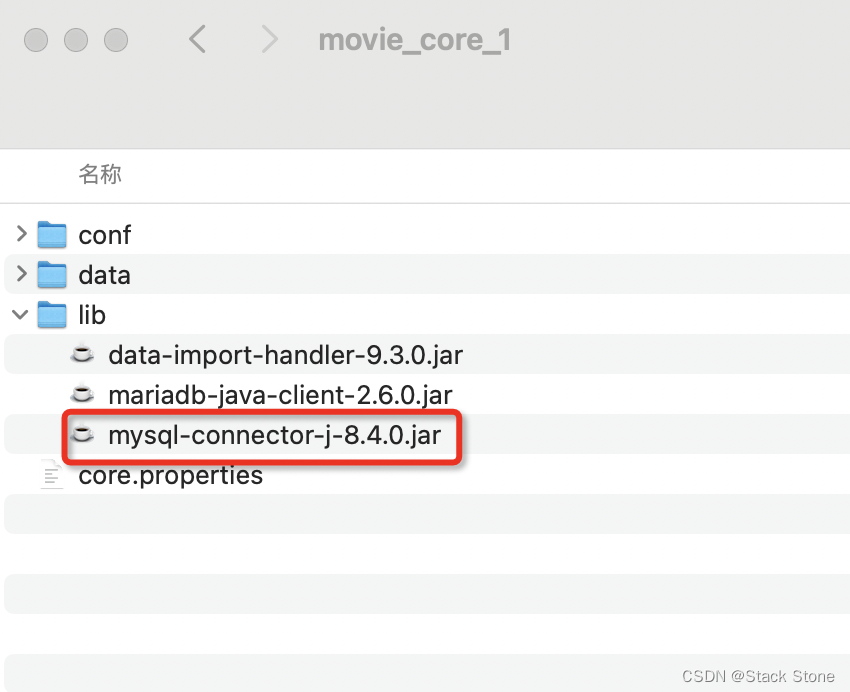
我的 MYSQL 表结构如下:
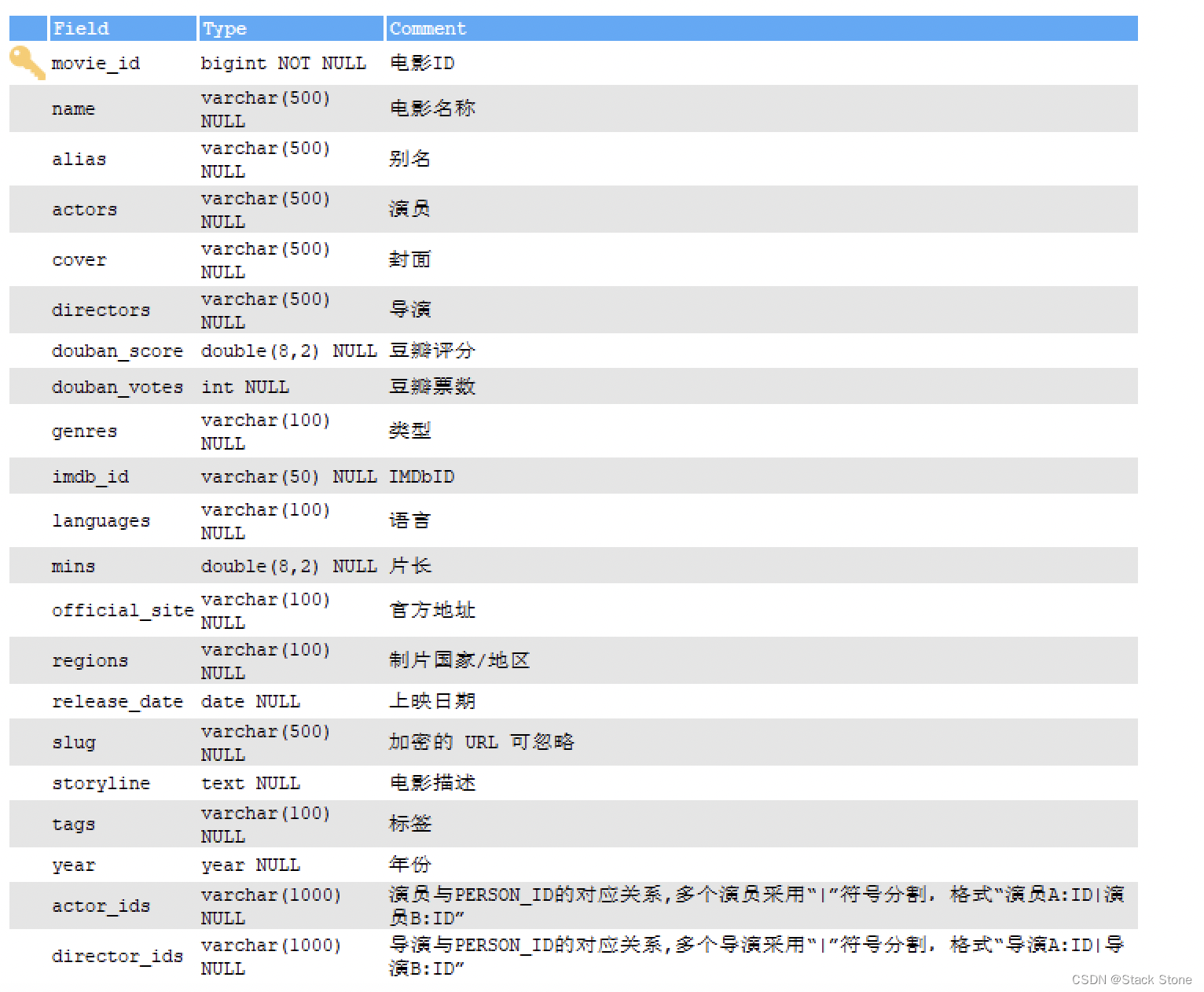
表数据:https://github.com/lt5227/example_code/blob/main/spring_solr_example/sql/movies.sql
之后在 CoreAdmin 页面中选择 Relod,重新加载配置。
在浏览器中请求 http://localhost:8983/solr/movie_core_1/dataimport?command=full-import 接口,程序就会读取查询数据库进行全量索引了,请求后页面返回如下:

控制台日志如下:
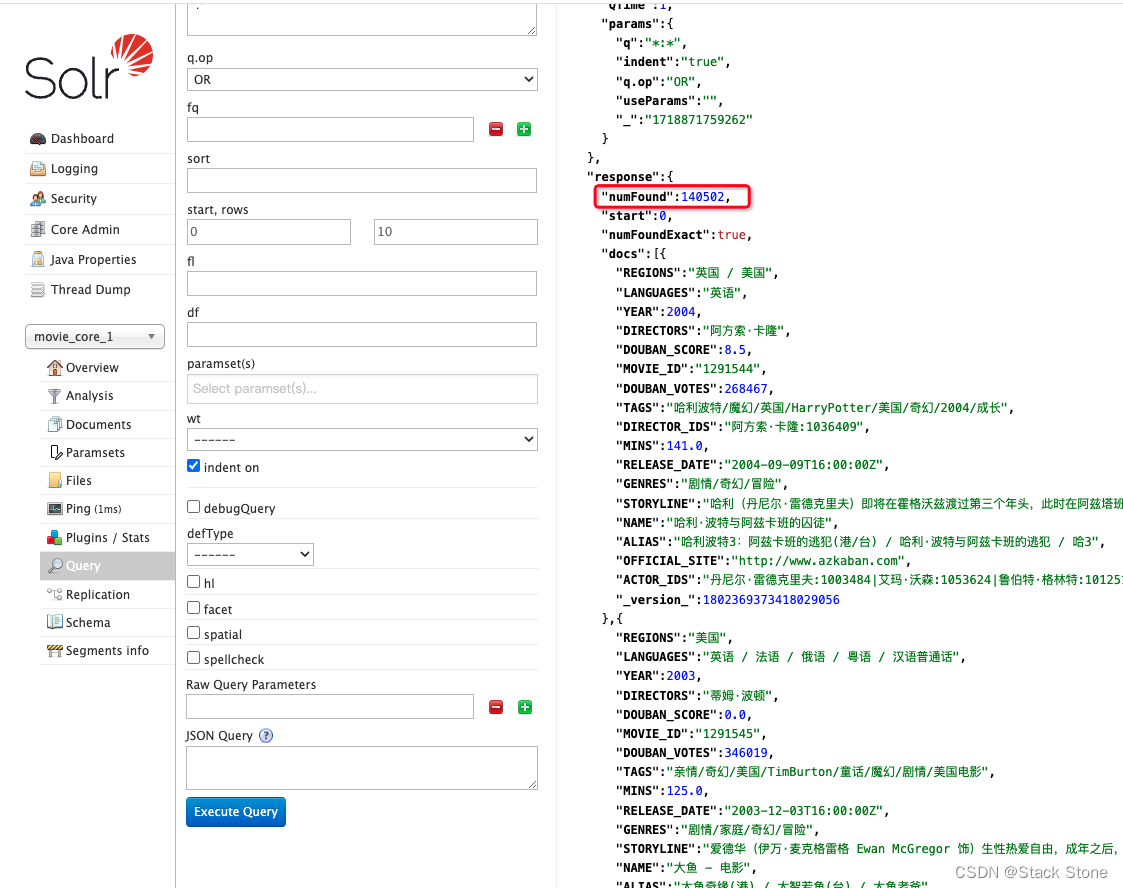
测试查询:
官方文档:
https://solr.apache.org/guide/8_6/uploading-data-with-index-handlers.html
https://solr.apache.org/guide/solr/latest/upgrade-notes/major-changes-in-solr-9.html#deprecations-and-removals