scene graph generation benchmark关于visual genome的数据划分(train,test,val)
- 前言
前言
很多做scene graph generation,准备测试的同学,发现visual genome并没有提供官方的训练train,测试test,验证val数据集划分。
不过我们可以参考scene graph generation benchmark的相关代码,然后找到这个代码里对VG150数据的划分,并参考这个领域对VG150的数据的划分,来划分VG150并进行验证。
我们进入scene graph generation benchmark的代码,在这个文件里打上断点。
Scene-Graph-Benchmark.pytorch/maskrcnn_benchmark/data/build.py
def build_dataset(cfg, dataset_list, transforms, dataset_catalog, is_train=True):
"""
Arguments:
dataset_list (list[str]): Contains the names of the datasets, i.e.,
coco_2014_trian, coco_2014_val, etc
transforms (callable): transforms to apply to each (image, target) sample
dataset_catalog (DatasetCatalog): contains the information on how to
construct a dataset.
is_train (bool): whether to setup the dataset for training or testing
"""
if not isinstance(dataset_list, (list, tuple)):
raise RuntimeError(
"dataset_list should be a list of strings, got {}".format(dataset_list)
)
datasets = []
for dataset_name in dataset_list:
data = dataset_catalog.get(dataset_name, cfg)
factory = getattr(D, data["factory"])
args = data["args"]
# for COCODataset, we want to remove images without annotations
# during training
if data["factory"] == "COCODataset":
args["remove_images_without_annotations"] = is_train
if data["factory"] == "PascalVOCDataset":
args["use_difficult"] = not is_train
args["transforms"] = transforms
#Remove it because not part of the original repo (factory cant deal with additional parameters...).
if "capgraphs_file" in args.keys():
del args["capgraphs_file"]
# make dataset from factory
dataset = factory(**args)
datasets.append(dataset)
# for testing, return a list of datasets
if not is_train:
return datasets
# for training, concatenate all datasets into a single one
dataset = datasets[0]
if len(datasets) > 1:
dataset = D.ConcatDataset(datasets)
return [dataset]
这部分代码的大致意思是说:如果当前的dataset_name 是train(或test,或val),就通过项目中已包装好的参数,来读取相应的文件,处理成数据dataset,也就是我们主要在下面这两行代码上打断点。
dataset = factory(**args)
datasets.append(dataset)
然后我们根据dataset_name把三个相关的dataset用pickle头文件下载下来:(也就是添加这样一些代码:)
if dataset_name == 'VG_stanford_filtered_with_attribute_train':
with open('data_train.pkl', 'wb') as f:
pickle.dump(dataset, f)
if dataset_name == 'VG_stanford_filtered_with_attribute_test':
with open('data_test.pkl', 'wb') as f:
pickle.dump(dataset, f)
if dataset_name == 'VG_stanford_filtered_with_attribute_val':
with open('data_val.pkl', 'wb') as f:
pickle.dump(dataset, f)
通过不同的模式的运行,得到三个文件pkl:

但是这三个文件,因为数据格式跟maskrcnn设置有关,只有在scene graph generation benchamrak的项目里才能打开,所以我对这三个数据pkl文件做了如下处理
import os
import bisect
import copy
import logging
from collections import Counter, defaultdict
import matplotlib.pyplot as plt
import random
import numpy as np
import pickle
import json
from maskrcnn_benchmark.utils.comm import get_world_size
from maskrcnn_benchmark.utils.imports import import_file
from maskrcnn_benchmark.utils.miscellaneous import save_labels
import pickle
file_paths = {
'train': '/Scene-Graph-Benchmark.pytorch/data_train.pkl',
'test': '/Scene-Graph-Benchmark.pytorch/data_test.pkl',
'val': '/Scene-Graph-Benchmark.pytorch/data_val.pkl'
}
# 读取pkl文件并转换为字典格式
def read_pkl_file(file_path):
with open(file_path, 'rb') as f:
data = pickle.load(f)
# 将数据转换为字典格式
data_dict = {
'categories': data.categories,
'filenames': data.filenames,
'gt_boxes': [box.tolist() for box in data.gt_boxes], # 将numpy数组转换为列表
'gt_classes': [cls.tolist() for cls in data.gt_classes], # 将numpy数组转换为列表
'img_info': data.img_info,
'ind_to_attributes': data.ind_to_attributes,
'ind_to_classes': data.ind_to_classes,
'ind_to_predicates': data.ind_to_predicates,
'relationships': [rel.tolist() for rel in data.relationships], # 将numpy数组转换为列表
'split': data.split
}
return data_dict
# 保存数据到json文件
def save_to_json(data_dict, output_path):
with open(output_path, 'w') as json_file:
json.dump(data_dict, json_file, indent=4)
# 处理每个文件并保存为json
for split, file_path in file_paths.items():
data_dict = read_pkl_file(file_path)
output_path = f'/Scene-Graph-Benchmark.pytorch/data_{split}.json'
save_to_json(data_dict, output_path)
print(f'Saved {split} data to {output_path}')
最终得到如下三个json文件(本地就可以运行):

运行起来是这样的:
import json
import os
import sys
file1_path = './data_train.json'
file2_path = './data_test.json'
file3_path = './data_val.json'
with open(file1_path, 'r', encoding='utf-8') as file:
data1 = json.load(file)
with open(file2_path, 'r', encoding='utf-8') as file:
data2 = json.load(file)
with open(file3_path, 'r', encoding='utf-8') as file:
data3 = json.load(file)
print(data1)
print(data2)
print(data3)
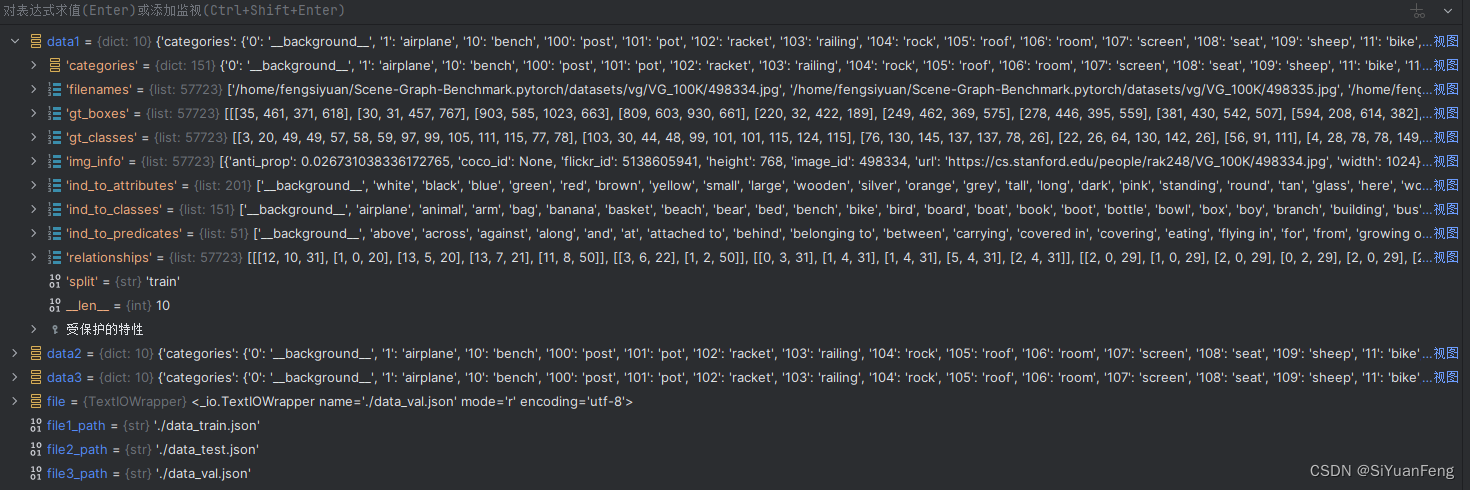
其他的变量都很好理解,注意gt_classes是gt_boxes每一个物体的类别编号。
ind_to_classes是背景1+150个名词类别
ind_to_predicates是背景1+50个谓词类别
正好对应了vg150的150个名词和50个谓词
接下来大家愉快的使用这个SGG划分的VG150数据集吧。
链接:https://pan.baidu.com/s/1QGaNxPoWi9BIckYafoQrvg
提取码:yw1y
–来自百度网盘超级会员V8的分享