1.什么是ChatGLM-6B
ChatGLM-6B 是的一种自然语言处理模型,属于大型生成语言模型系列的一部分。"6B"在这里指的是模型大约拥有60亿个参数,这些参数帮助模型理解和生成语言。ChatGLM-6B 特别设计用于对话任务,能够理解和生成自然、流畅的对话文本。 这个模型通过大量的文本数据进行训练,学习如何预测和生成语言中的下一个词,从而能够参与到各种对话场景中。它可以用于多种应用,比如聊天机器人、自动回复系统和其他需要语言理解的技术中,ChatGLM-6B 的能力取决于它的训练数据和具体的实现方式,通常能够处理复杂的语言任务,提供有用和合理的回复。
😝有需要的小伙伴,可以V扫描下方二维码免费领取🆓
 ##### 2.开源仓库
##### 2.开源仓库
-
ChatGLM的github地址如下
- https://github.com/THUDM/ChatGLM-6B
- 有非常详细的文档介绍
在这里插入图片描述
2.1硬件要求

在这里插入图片描述
3.模型运行环境搭建
-
python环境
- 建议使用Anaconda方便对管理相关的库进行python环境的隔离
- 版本要求:为了避免一些千奇百怪的兼容错误,版本要求大于3.10
-
conda创建虚拟环境
conda create -n chatglm-6b python==3.10.4conda activate chatglm-6b

在这里插入图片描述
- ChatGLM-6B代码下载
- 使用git命令进行代码拉取
git clone https://github.com/THUDM/ChatGLM-6B.git- 进入到下载好的文件目录,下载相关依赖
pip install -r requirements.txt -i https://pypi.tuna.tsinghua.edu.cn/simplepip install -i https://pypi.tuna.tsinghua.edu.cn/simple streamlitpip install -i https://pypi.tuna.tsinghua.edu.cn/simple streamlit-chat- 环境隔离之后,这里的版本不影响其他项目的依赖版本,这里需要注意,每一个版本严格按照要求下载,否则容易出错
4. 模型下载
- 代码由 transformers 自动下载模型实现和参数。完整的模型实现可以在 Hugging Face Hub。如果你的网络环境较差,下载模型参数可能会花费较长时间甚至失败。此时可以先将模型下载到本地,然后从本地加载。
- 从 Hugging Face Hub 下载模型需要先安装Git LFS ,然后运行
代码语言:javascript
复制
git clone https://huggingface.co/THUDM/chatglm-6b
- Git LFS安装 -> https://docs.github.com/zh/repositories/working-with-files/managing-large-files/installing-git-large-file-storage
- 将模型下载到本地之后,上代码中的 THUDM/chatglm-6b 替换为你本地的 chatglm-6b 文件夹的路径,即可从本地加载模型。
在这里插入图片描述
5.模型调用
5.1 代码调用
代码语言:javascript
复制
from transformers import AutoTokenizer, AutoModel
tokenizer = AutoTokenizer.from_pretrained("THUDM/chatglm-6b", trust_remote_code=True)
#model = AutoModel.from_pretrained("THUDM/chatglm-6b", trust_remote_code=True).half().cuda()
#macbook需要调用mps后端
model = AutoModel.from_pretrained("THUDM/chatglm-6b", trust_remote_code=True).half().to('mps')
model = model.eval()
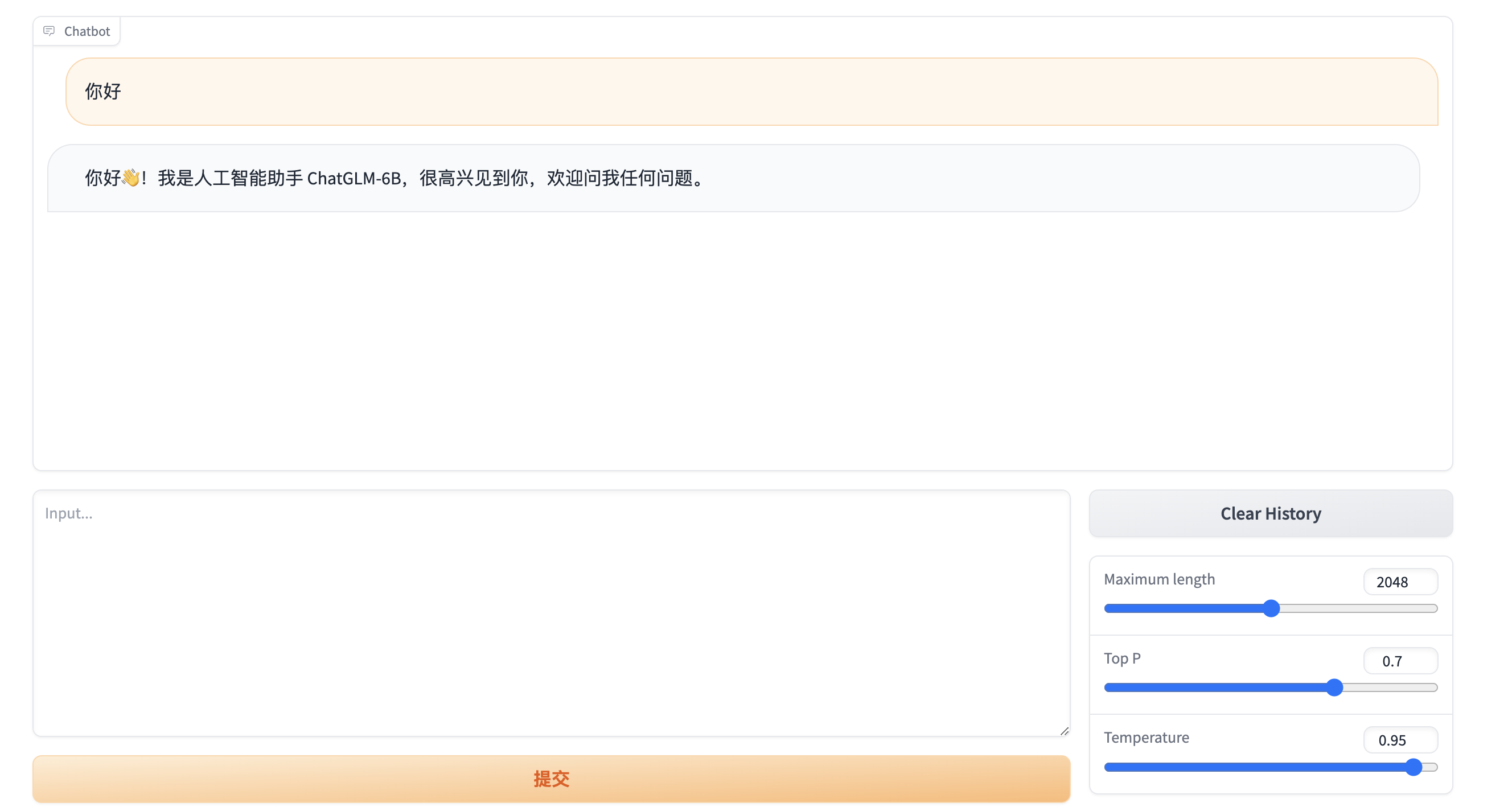
response, history = model.chat(tokenizer, "你好", history=[])
print(response)
你好👋!我是人工智能助手 ChatGLM-6B,很高兴见到你,欢迎问我任何问题。
如果你没有 GPU 硬件的话,也可以在 CPU 上进行推理,但是推理速度会更慢。使用方法如下(需要大概 32GB 内存)
model = AutoModel.from_pretrained("THUDM/chatglm-6b", trust_remote_code=True).float()
#代码解释
AutoTokenizer.from_pretrained():
AutoTokenizer.from_pretrained() 方法用于加载一个预训练的tokenizer,这个tokenizer负责将文本输入转化为模型可以理解的数值形式(即tokens)。它从指定的本地路径加载tokenizer配置和数据。
参数"THUDM/chatglm-6b" 指的是tokenizer存储的目录。
trust_remote_code=True 是一个安全选项,当你信任你正在加载的代码时可以设置为True,它允许执行加载过程中可能会运行的远程或自定义代码。
AutoModel.from_pretrained():
AutoModel.from_pretrained() 方法用于加载预训练的模型。这个模型能够根据输入的tokens进行处理并输出结果。
同样地,模型是从指定的本地路径加载的。
trust_remote_code=True 允许加载自定义代码。
.half():
.half() 方法用于将模型的数据类型转换为半精度浮点数(Float16)。这通常用于减少模型在显存中占用的空间,从而可以加快计算速度,尤其是在支持半精度计算的GPU上。
.to('mps'):
.to('mps') 方法是将模型移动到一个特定的设备上运行,这里是指Apple的Metal Performance Shaders (MPS)。MPS是Apple为MacOS设备上的机器学习和深度学习提供支持的后端,可以利用Apple硬件的优势提高性能
- 如果你没有 GPU 硬件的话,也可以在 CPU 上进行推理,但是推理速度会更慢。使用方法如下(需要大概 32GB 内存)
代码语言:javascript
复制
model = AutoModel.from_pretrained("THUDM/chatglm-6b", trust_remote_code=True).float()
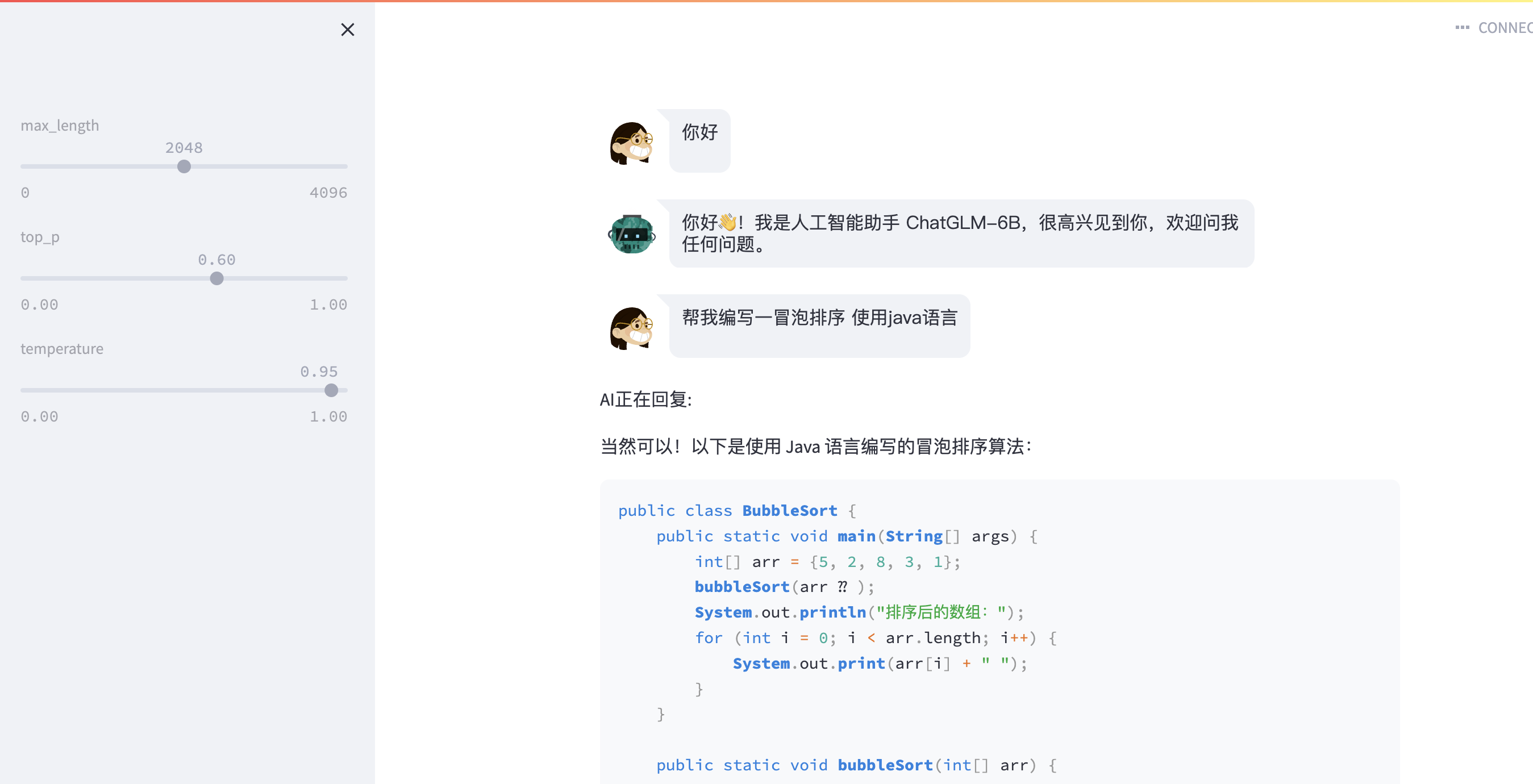
5.2 web页面调用
-
运行 streamlit run web_demo2.py 可直接进行web页面的对话
-
或者直接运行web_demo.py文件 使用 gradio
在这里插入图片描述
那么,我们该如何学习大模型?
作为一名热心肠的互联网老兵,我决定把宝贵的AI知识分享给大家。 至于能学习到多少就看你的学习毅力和能力了 。我已将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。
一、大模型全套的学习路线
学习大型人工智能模型,如GPT-3、BERT或任何其他先进的神经网络模型,需要系统的方法和持续的努力。既然要系统的学习大模型,那么学习路线是必不可少的,下面的这份路线能帮助你快速梳理知识,形成自己的体系。
L1级别:AI大模型时代的华丽登场

L2级别:AI大模型API应用开发工程

L3级别:大模型应用架构进阶实践

L4级别:大模型微调与私有化部署

一般掌握到第四个级别,市场上大多数岗位都是可以胜任,但要还不是天花板,天花板级别要求更加严格,对于算法和实战是非常苛刻的。建议普通人掌握到L4级别即可。
以上的AI大模型学习路线,不知道为什么发出来就有点糊,高清版可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

二、640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

三、大模型经典PDF籍
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。

四、AI大模型商业化落地方案

作为普通人,入局大模型时代需要持续学习和实践,不断提高自己的技能和认知水平,同时也需要有责任感和伦理意识,为人工智能的健康发展贡献力量。