开放域闲聊场景
Prompted LLMs as Chatbot Modules for Long Open-domain Conversation
-
发布日期:2023-05-01
-
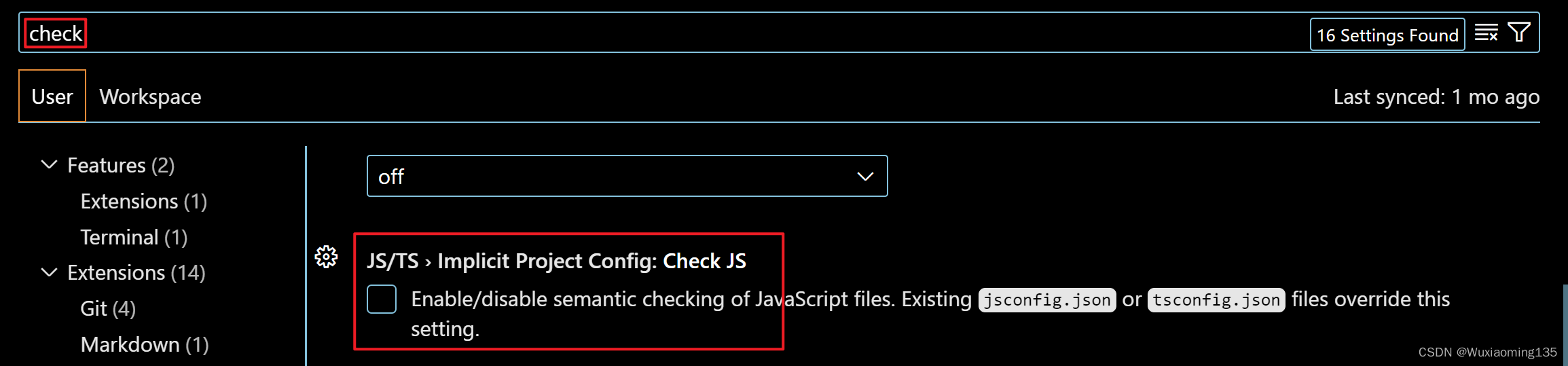
简要介绍:作者提出了 MPC(模块化提示聊天机器人),这是一种无需微调即可创建高质量对话代理的新方法,可以成为长期开放域聊天机器人的有效解决方案。该方法利用预训练好的大型语言模型(LLM)作为单独的模块,通过使用 few-shot、思维链(CoT)和外部记忆等技术来实现长期一致性和灵活性。
MPC 本质上是一种 RAG 或者说 Agent,在输入和输出的中间添加了更多思考和记忆的环节,将 LLM 从“人”的角色进一步拆分为“大脑”和“嘴巴”。这种明确的分工的确能够提升最终的效果,但同样会遇到 RAG、Agent 成本较高的问题,以及引入更多中间环节造成的误差累积。为什么成本较高?为了确保中间环节结果的正确性,往往也会接一个 LLM 去做判断,或者训练专门的小模型,这些都需要资源,并且对整个推理过程的时延造成一定的影响。在业务上是否真得要这么做,还需要进一步衡量效果和成本的 tradeoff。
RoleLLM: Benchmarking, Eliciting, and Enhancing Role-Playing Abilities of Large Language Models
-
发布日期:2023-10
-
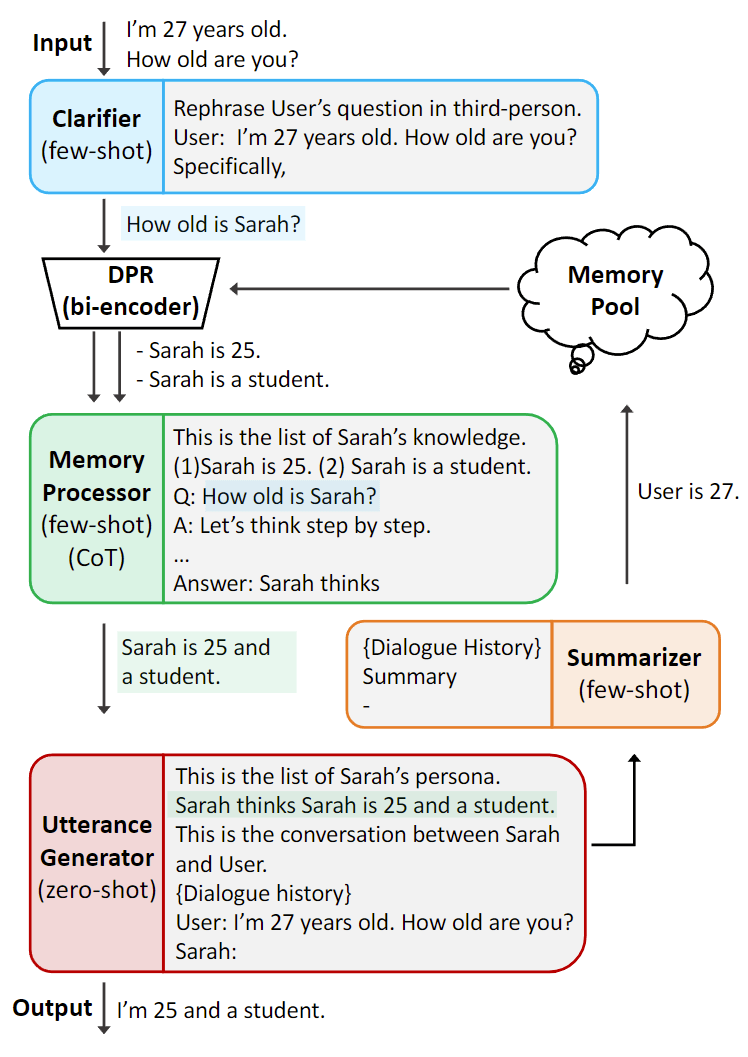
简要介绍:介绍 RoleLLM,一个用于对 LLM 的角色扮演能力进行基准测试、诱导和增强的框架,包括四个阶段:(1) 100 个角色的角色档案构建;(2) 基于上下文的指令生成(Context-Instruct),用于角色特定知识的提取;(3) 使用 GPT 的角色提示(RoleGPT),用于说话风格的模仿;(4) 角色条件指令调整(Role-Conditioned Instruction Tuning,RoCIT),用于微调开源模型和角色定制。通过 Context-Instruct 和 RoleGPT,作者创建了 RoleBench,这是第一个系统化、精细化的角色扮演基准数据集。
Blending Is All You Need: Cheaper, Better Alternative to Trillion-Parameters LLM
-
发布日期:2024-01-05
-
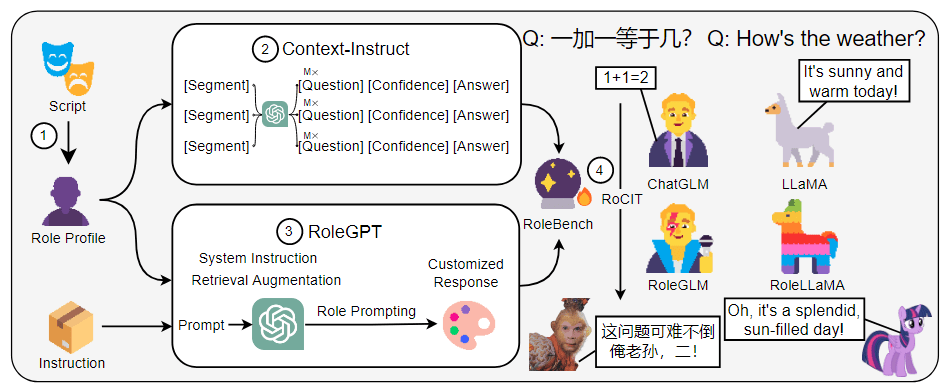
简要介绍:介绍了“混合”(Blended),这是一种通过随机选择不同系统(模型)的回复来组合多个聊天人工智能的简单方法。经验证据表明,当特定的较小模型被协同混合时,它们的性能有可能超过或赶上更大的同类模型,同时还能保持较小系统的推理成本。

在对话过程中,Blended 每次都会随机(均匀)选择产生当前响应的聊天模型(例如,有 A、B 和 C 三个聊天模型,随机从中挑选一个模型来生成响应)。论文中也提到“特定聊天模型生成的回复是以之前选择的聊天模型生成的所有回复为条件的。这意味着不同的聊天模型会对当前回复的输出产生隐性影响。因此,当前的回复融合了各个聊天人工智能的优势,它们相互协作,创造出了更吸引人的整体对话”。由于这篇论文是 chai,并且在他们自家的产品上得到了验证,因此我们也尝试了该方案。但在使用过程中,如果 A、B 和 C 这三个模型的差距较大时,用户所看到的回答风格差距也较大,就好像角色是“精神分裂”的。
如果成本足够的话,可以考虑异步同时调用这三个模型,然后在后处理环节中调用一致性方法或者 reward model 去评估各响应的结果,挑选出最适合的响应。或者根据对话轮数来选择聊天模型,例如前 10 轮调用 A 模型;10 轮到 50 轮调用 B 模型;50 轮以后调用 C 模型。
LLM-Blender:Ensembling Large Language Models with Pairwise Ranking and Generative Fusion
-
发布日期:2023-06-05
-
简要介绍:提出了一个名为 LLM-BLENDER 的集合框架,该框架由两个模块组成:Pair-Ranker 模块和 Gen-Fuser 模块。Pair-Ranker 采用一种专门的成对比较方法来区分候选输出之间的细微差别。Gen-Fuser 的目标是合并排名靠前的候选输出,通过利用它们的优势和减少它们的劣势来生成改进的输出。
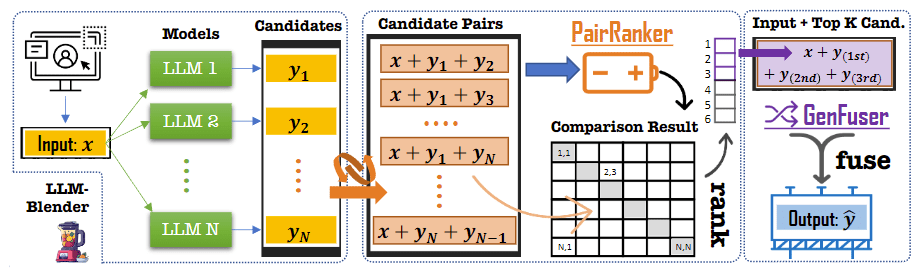
这篇工作比 chai 那篇论文要早,从方法上来说(我个人理解)也更加靠谱一些,但 Gen-Fuser 要怎么做是个比较棘手的问题。并且整体的流程过长(即便是异步调用的方式,整体的时长取决于最后一个输出的耗时,并且不同模型的输出有长有短),在实际的使用过程中要不可避免地要增加时延以及降低服务的总体吞吐。