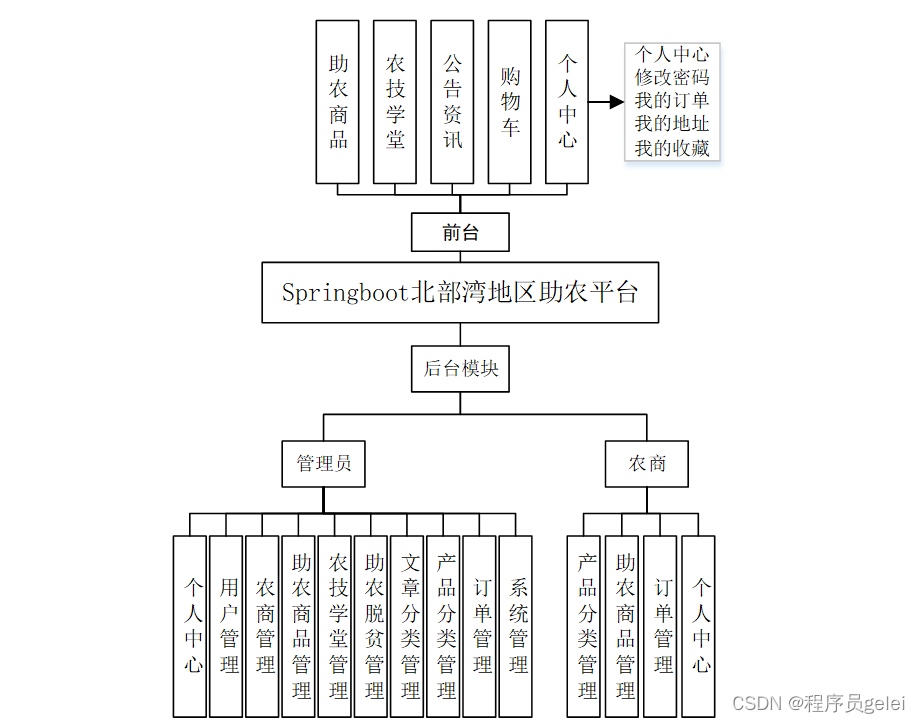
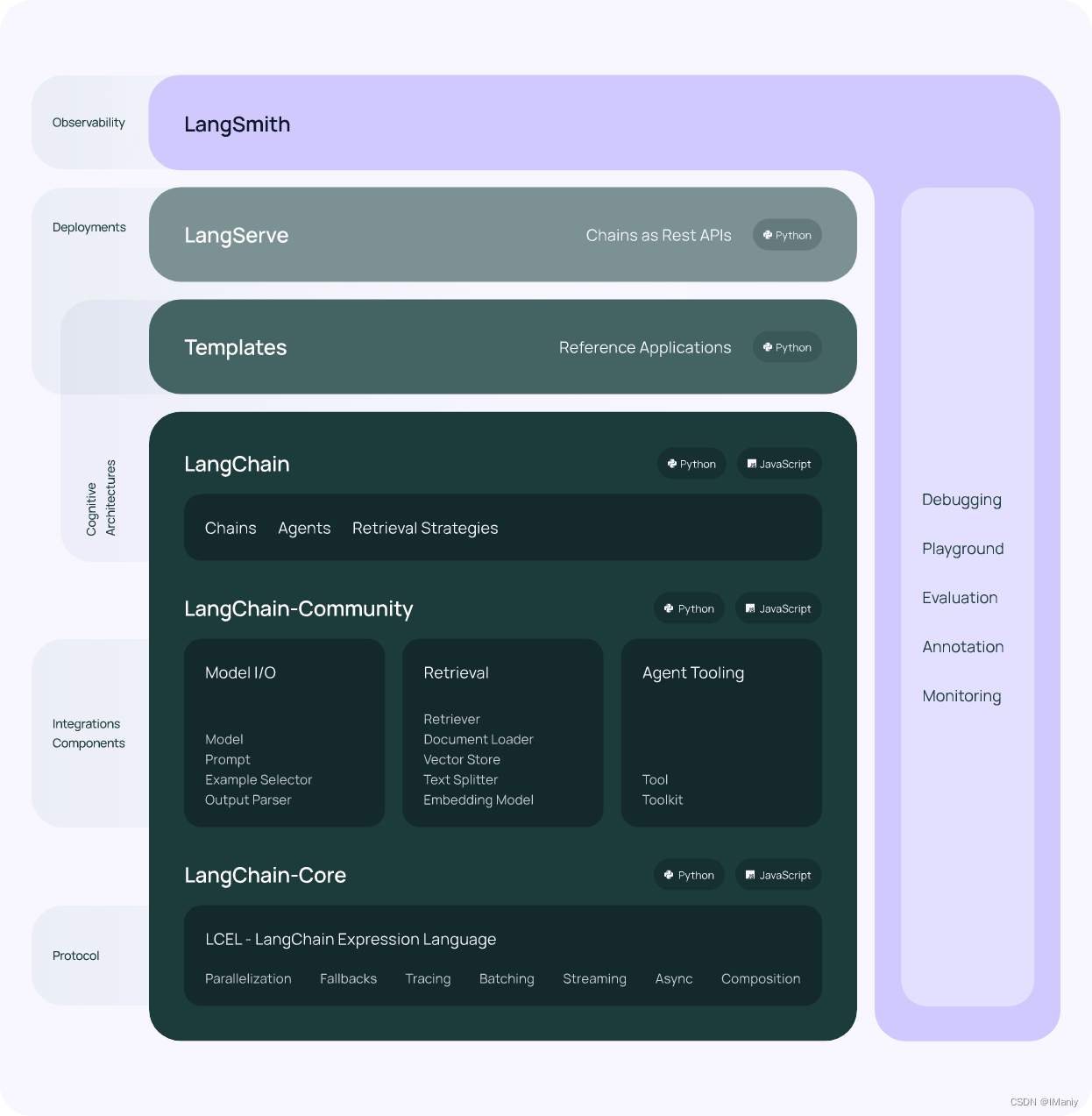
视频帧画面知识点区域划分
知识点区域精确分割技术:
在深度学习检测模型结果基础上使用基于交并比(IoU)阈值的目标合并算法,合并过度重合目标区域面积,实现知识点区域精确分割
多模态知识点内容匹配策略:
图像:利用GPT-4模型的多模态处理能力,将视频帧中的图像与预设的知识点语义注解进行匹配 文本:使用Sentence Transformer模型对视频帧中提取的文本内容进行深度语义编码,将其嵌入向量与知识点数据库中的语义向量进行比较。通过计算语义相似度,精确匹配相关知识点,实现高效的文本内容到知识点的映射;
自此,可以使视频帧画面的各部分都有对应的知识点;
import os
import re
from sentence_transformers import SentenceTransformer, util
from test_gpt import detection_gpt
# 初始化Sentence Transformer模型
model = SentenceTransformer('all-MiniLM-L6-v2')
def get_embedding(text):
return model.encode(text, convert_to_tensor=True)
def semantic_similarity(text1, text2):
embedding1 = get_embedding(text1)
embedding2 = get_embedding(text2)
return util.pytorch_cos_sim(embedding1, embedding2).item()
def parse_knowledge_content(content):
knowledge_points = []
kp_blocks = content.strip().split("\n\n")
for block in kp_blocks:
lines = block.split("\n")
kp_dict = {}
for line in lines:
key, value = line.split(":", 1)
kp_dict[key.strip()] = value.strip()
knowledge_points.append(kp_dict)
return knowledge_points
def read_knowledge_file(timestamp, json_folder_path):
knowledge_file_path = os.path.join(json_folder_path, f"{timestamp}.txt")
try:
with open(knowledge_file_path, 'r') as file:
content = file.read()
return parse_knowledge_content(content)
except FileNotFoundError:
return "Knowledge file not found"
except Exception as e:
return str(e)
def parse_merge_text(file_path):
with open(file_path, 'r') as file:
content = file.read()
timestamps = re.split(r'Timestamp: (\d+)', content)[1:]
timestamp_data = {timestamps[i]: timestamps[i+1] for i in range(0, len(timestamps), 2)}
return timestamp_data
def kp_match_data(merge_text_path, json_folder_path, object_frames_folder, output_path):
data = parse_merge_text(merge_text_path)
output_data = []
for timestamp, contents in data.items():
knowledge_content = read_knowledge_file(timestamp, json_folder_path)
knowledge_txt_path = os.path.join("json_files", f"{timestamp}.txt")
if isinstance(knowledge_content, str):
output_data.append(f"Timestamp: {timestamp}\n{contents}\n{knowledge_content}\n")
continue
try:
with open(knowledge_txt_path, 'r', encoding='utf-8') as file:
knowledge_txt = file.read()
except FileNotFoundError:
print(f"Knowledge file not found for timestamp {timestamp}")
continue
contents_processed = contents
detection_matches = re.findall(r'(Detection \d+): \((\d+, \d+, \d+, \d+)\)', contents)
for match in detection_matches:
detection_label, detection_data = match
detection_number = detection_label.split(' ')[1].lower() # e.g., 'detection1'
detection_image_path = os.path.join(object_frames_folder, f"{timestamp}_detection{detection_number}.jpg")
kp_id = detection_gpt(detection_image_path, knowledge_txt)
contents_processed = contents_processed.replace(detection_label, f"{detection_label} (Knowledge_pdoint_id: {kp_id})")
ocr_texts = re.findall(r'OCR \d+: \(\d+, \d+, \d+, \d+\) (.+)', contents)
for ocr_text in ocr_texts:
best_match = None
best_score = -float('inf')
for kp in knowledge_content:
score = semantic_similarity(ocr_text, kp['Original_text'])
if score > best_score:
best_match = kp
best_score = score
if best_match:
contents_processed = contents_processed.replace(
ocr_text,
f"(Knowledge_point_id: {best_match['Knowledge_point_id']}) {ocr_text}"
)
output_data.append(f"Timestamp: {timestamp}\n{contents_processed}\n")
with open(output_path, 'w', encoding='utf-8') as file:
file.write("\n".join(output_data))
OCR得到的音频文本以及YOLO得到的detection区域对应知识点匹配:

下一步即是匹配三方数据:语音文本知识点、帧知识点区域、实时注视点位置




![【2024最新华为OD-C/D卷试题汇总】[支持在线评测] 连续字母长度(100分) - 三语言AC题解(Python/Java/Cpp)](https://img-blog.csdnimg.cn/direct/7b8039a50ddb4c3ab739f049107c0891.png)