leetcode349. 两个数组的交集
- 1 题目
- 2 思路--set
- 2.1 拓展/后记
- 3 代码
- 3.1 C++版本
- 3.2 C版本
- 3.3 Java版本
- 3.4 Python 版本
- 3.5 JavaScript版本
- 4 总结
1 题目
题源链接
给定两个数组 nums1 和 nums2 ,返回 它们的交集 。输出结果中的每个元素一定是 唯一 的。我们可以 不考虑输出结果的顺序 。
示例 1:
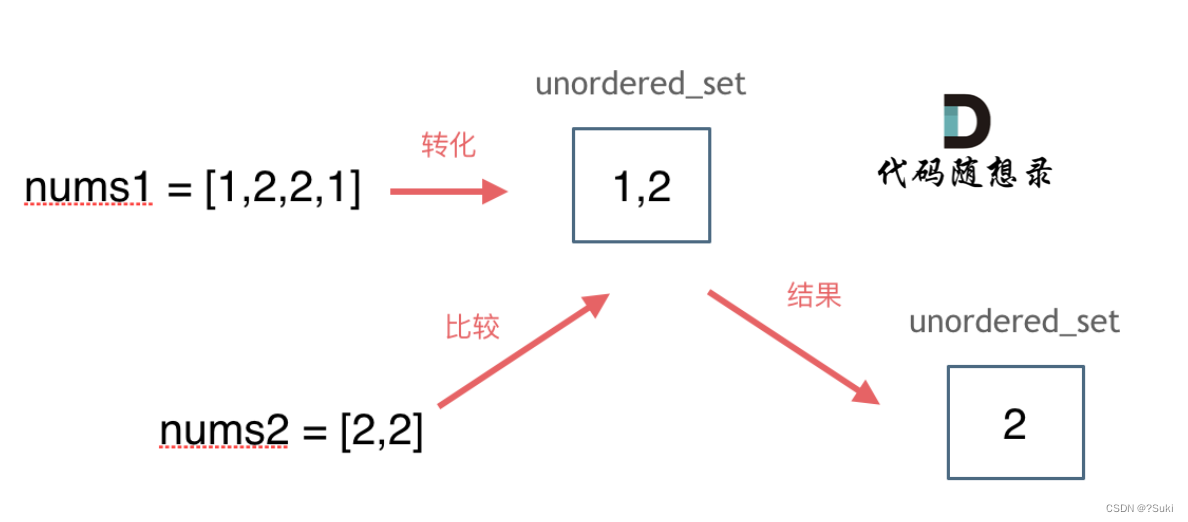
输入:nums1 = [1,2,2,1], nums2 = [2,2]
输出:[2]
示例 2:
输入:nums1 = [4,9,5], nums2 = [9,4,9,8,4]
输出:[9,4]
解释:[4,9] 也是可通过的
提示:
1 <= nums1.length, nums2.length <= 1000
0 <= nums1[i], nums2[i] <= 1000
2 思路–set
这道题目,主要要学会使用一种哈希数据结构:unordered_set,这个数据结构可以解决很多类似的问题。
注意题目特意说明:输出结果中的每个元素一定是唯一的,也就是说输出的结果的去重的, 同时可以不考虑输出结果的顺序
这道题用暴力的解法时间复杂度是O(n^2),那来看看使用哈希法进一步优化。
- 为什么不使用数组做哈希表?
使用数组来做哈希的题目,是因为题目都限制了数值的大小。
而这道题目如果没有限制数值的大小,就无法使用数组来做哈希表了。
而且如果哈希值比较少、特别分散、跨度非常大,使用数组就造成空间的极大浪费。
此时就要使用另一种结构体了,set
关于set,C++ 给提供了如下三种可用的数据结构:
- std::set
- std::multiset
- std::unordered_set
std::set和std::multiset底层实现都是红黑树,std::unordered_set的底层实现是哈希表, 使用unordered_set 读写效率是最高的,并不需要对数据进行排序,而且还不要让数据重复,所以选择unordered_set。
思路如图所示:
2.1 拓展/后记
那有同学可能问了,遇到哈希问题我直接都用set不就得了,用什么数组啊。
直接使用set 不仅占用空间比数组大,而且速度要比数组慢,set把数值映射到key上都要做hash计算的。
不要小瞧 这个耗时,在数据量大的情况,差距是很明显的。
本题后面 力扣改了 题目描述 和 后台测试数据,增添了 数值范围:
1 <= nums1.length, nums2.length <= 1000
0 <= nums1[i], nums2[i] <= 1000
所以就可以 使用数组来做哈希表了, 因为数组都是 1000以内的。
对应C++代码如下:
class Solution {
public:
vector<int> intersection(vector<int>& nums1, vector<int>& nums2) {
unordered_set<int> result_set; // 存放结果,之所以用set是为了给结果集去重
int hash[1005] = {0}; // 默认数值为0
for (int num : nums1) { // nums1中出现的字母在hash数组中做记录
hash[num] = 1;
}
for (int num : nums2) { // nums2中出现话,result记录
if (hash[num] == 1) {
result_set.insert(num);
}
}
return vector<int>(result_set.begin(), result_set.end());
}
};
3 代码
3.1 C++版本
class Solution {
public:
vector<int> intersection(vector<int>& nums1, vector<int>& nums2) {
unordered_set<int> result_set; // 存放结果,之所以用set是为了给结果集去重
unordered_set<int> nums_set(nums1.begin(), nums1.end());
for (int num : nums2) {
// 发现nums2的元素 在nums_set里又出现过
if (nums_set.find(num) != nums_set.end()) {
result_set.insert(num);
}
}
return vector<int>(result_set.begin(), result_set.end());
}
};
3.2 C版本
int* intersection1(int* nums1, int nums1Size, int* nums2, int nums2Size, int* returnSize){
int nums1Cnt[1000] = {0};
int lessSize = nums1Size < nums2Size ? nums1Size : nums2Size;
int * result = (int *) calloc(lessSize, sizeof(int));
int resultIndex = 0;
int* tempNums;
int i;
/* Calculate the number's counts for nums1 array */
for(i = 0; i < nums1Size; i ++) {
nums1Cnt[nums1[i]]++;
}
/* Check if the value in nums2 is existing in nums1 count array */
for(i = 0; i < nums2Size; i ++) {
if(nums1Cnt[nums2[i]] > 0) {
result[resultIndex] = nums2[i];
resultIndex ++;
/* Clear this count to avoid duplicated value */
nums1Cnt[nums2[i]] = 0;
}
}
* returnSize = resultIndex;
return result;
}
3.3 Java版本
import java.util.HashSet;
import java.util.Set;
class Solution {
public int[] intersection(int[] nums1, int[] nums2) {
if (nums1 == null || nums1.length == 0 || nums2 == null || nums2.length == 0) {
return new int[0];
}
Set<Integer> set1 = new HashSet<>();
Set<Integer> resSet = new HashSet<>();
//遍历数组1
for (int i : nums1) {
set1.add(i);
}
//遍历数组2的过程中判断哈希表中是否存在该元素
for (int i : nums2) {
if (set1.contains(i)) {
resSet.add(i);
}
}
//将结果几何转为数组
return resSet.stream().mapToInt(x -> x).toArray();
}
}
3.4 Python 版本
class Solution:
def intersection(self, nums1: List[int], nums2: List[int]) -> List[int]:
val_dict = {}
ans = []
for num in nums1:
val_dict[num] = 1
for num in nums2:
if num in val_dict.keys() and val_dict[num] == 1:
ans.append(num)
val_dict[num] = 0
return ans
3.5 JavaScript版本
/**
* @param {number[]} nums1
* @param {number[]} nums2
* @return {number[]}
*/
var intersection = function(nums1, nums2) {
// 根据数组大小交换操作的数组
if(nums1.length < nums2.length) {
const _ = nums1;
nums1 = nums2;
nums2 = _;
}
const nums1Set = new Set(nums1);
const resSet = new Set();
// for(const n of nums2) {
// nums1Set.has(n) && resSet.add(n);
// }
// 循环 比 迭代器快
for(let i = nums2.length - 1; i >= 0; i--) {
nums1Set.has(nums2[i]) && resSet.add(nums2[i]);
}
return Array.from(resSet);
};
4 总结
题目如果没有限制数值的大小,就无法使用数组来做哈希表了。
而且如果哈希值比较少、特别分散、跨度非常大,使用数组就造成空间的极大浪费。
此时就要使用另一种结构体了,set
Carl老师视频讲解
这道题目,主要要学会使用一种哈希数据结构:unordered_set,这个数据结构可以解决很多类似的问题。
By Suki —2023/1/29







![[cpp进阶]C++类型转换](https://img-blog.csdnimg.cn/b50de067291d4822bbcd0a31ccff6931.png)