文章目录
- 基于 sys 系统信号量(XSI信号量)
- 常用api
- 参考
- 基于 POSIX 信号量
- 有名信号量
- 常用 api
- 无名信号量
- 常用 api
- 参考
- 实践-基于POSIX有名信号量
- 生产者消费者模型任务说明
- 同步关系
- 互斥关系
- 设置一个互斥信号量,实现对共享内存的互斥访问
- 设置两个信号量,用于标记资源的数目,实现进程间的两个同步关系
- 发送
- 接受
- 参考的文心一言的伪代码
- 代码分享
- 下一步
- 1、如何设置队列?
- 2、使用STL 容器在共享内存怎么搞?
- 3、消息队列,例如POSIX 消息队列
基于 sys 系统信号量(XSI信号量)
Linux内核提供了一些系统调用函数来创建和操作信号量,这些函数都定义在<sys/sem.h>头文件中。
XSI信号量相对于POSIX信号量要复杂很多,因为其以下特性:
(1) 信号量并非单个非负值,而是一个或多个信号量的集合。创建信号量时,要指定其中信号数量;
(2) 创建信号量(semget)和初始化信号量(semctl)相互独立,不能原子操作;
(3) XSI信号量不会在进程退出后自动销毁(所有XSI IPC都有这个毛病,包括消息队列,共享存储,信号量)。
每个信号量集合含有一个semid_ds结构体
struct semid_ds
{
struct ipc_perm sem_perm;
unsigned short sem_nsems; //信号数量
time_t sem_otime;
time_t sem_ctime;
//可能还有其他成员
}
常用api
函数名:semget
nsems表示信号集合的信号数量,如果创建新集合,指定nsems;如果引用现有集合,nsems=0
*/
int semget(key_t key,int nsems,int flag);
/*
函数名:semctl
设置选项,最后一个union参数可选,根据cmd的命令
cmd命令:
IPC_STAT:取semid_ds结构体,存于arg.buf中
IPC_SET:按照arg.buf中的semid_ds结构体,设置sem_perm.uid,sem_perm.gid,sem_perm.mode
IPC_RMID:删除信号量集合,跟共享存储的IPC_RMID不同,此处立即删除,其他还在引用的进程再次使用该信号量集合时报错EIDRM
GETVAL:获取semnum的semval值
SETVAL:设置成员semnum的semval
GETPID:获取成员semnum的sempid
GETNCNT:获取semnum的semcnt
GETALL:获取所有信号量的semval,保存在arg.array中
SETALL:将所有信号量的semval设置为对应的arg.array值
*/
int semctl(int semid,int semnum,int cmd,.../*union semun arg*/);
union semun
{
int val; //for SETVAL
struct semid_ds* buf; //for IPC_STAT and IPC_SET
unsigned short *array //for SETALL and GETALL
}
/*
函数名:semop(自动执行信号量集合上的操作数组)
semoparray:sembuf的数组
nops:semoparray中元素个数
*/
int semop(int semid,struct sembuf semoparray[],size_t nops); //sem_buf定义如下:
struct sem_buf
{
usigned short sem_num; //member int set,即信号量集合中信号的序号
short sem_op; //operations
short sem_flag; //IPC_NOWAIT,SEM_UNDO
};
参考
https://blog.csdn.net/BrilliantAntonio/article/details/120606129
https://zhuanlan.zhihu.com/p/642216249
https://zhuanlan.zhihu.com/p/621670727
基于 POSIX 信号量
基于的头文件是#include <semphore.h>
在 POSIX标准中,信号量分两种,一种是无名信号量,一种是有名信号量。 无名信号量一般用于线程间同步或互斥,而有名信号量一般用于进程间同步或互斥。 有名信号量和无名信号量的差异在于创建和销毁的形式上,但是其他工作一样,无名信号量则直接保存在内存中, 而有名信号量则要求创建一个文件。
抽象的来讲,信号量中存在一个非负整数,所有获取它的进程/线程都会将该整数减一, 当该整数值为零时,所有试图获取它的进程/线程都将处于阻塞状态。通常一个信号量的计数值用于对应有效的资源数, 表示剩下的可被占用的互斥资源数。其值的含义分两种情况:
-
0:表示没有可用的信号量,进程/线程进入睡眠状态,直至信号量值大于 0。
-
正值:表示有一个或多个可用的信号量,进程/线程可以使用该资源。进程/线程将信号量值减1, 表示它使用了一个资源单位。
对信号量的操作可以分为两个:
-
P 操作:如果有可用的资源(信号量值大于0),则占用一个资源(给信号量值减去一,进入临界区代码); 如果没有可用的资源(信号量值等于0),则被阻塞,直到系统将资源分配给该进程/线程(进入等待队列, 一直等到资源轮到该进程/线程)。这就像你要把车开进停车场之前,先要向保安申请一张停车卡一样, P操作就是申请资源,如果申请成功,资源数(空闲的停车位)将会减少一个,如果申请失败,要不在门口等,要不就走人。
-
V 操作:如果在该信号量的等待队列中有进程/线程在等待资源,则唤醒一个阻塞的进程/线程。如果没有进程/线程等待它, 则释放一个资源(给信号量值加一),就跟你从停车场出去的时候一样,空闲的停车位就会增加一个。
有名信号量
如果要在Linux中使用信号量同步,需要包含头文件<semaphore.h>。
有名信号量其实是一个文件,它的名字由类似 " sem.[信号量名字] " 这样的字符串组成,注意看文件名前面有" sem. ", 它是一个特殊的信号量文件,在创建成功之后,系统会将其放置在 /dev/shm 路径下,不同的进程间只要约定好一个相同的信号量文件名字,就可以访问到对应的有名信号量,并且借助信号量来进行同步或者互斥操作,需要注意的是,有名信号量是一个文件,在进程退出之后它们并不会自动消失,而需要手动删除并释放资源。
常用 api
sem_t *sem_open(const char *name, int oflag, mode_t mode, unsigned int value);
int sem_wait(sem_t *sem);
int sem_trywait(sem_t *sem);
int sem_post(sem_t *sem);
int sem_close(sem_t *sem);
int sem_unlink(const char *name);
无名信号量
无名信号量的操作与有名信号量差不多,但它不使用文件系统标识,直接存在程序运行的内存中, 不同进程之间不能访问,不能用于不同进程之间相互访问。
常用 api
int sem_init(sem_t *sem, int pshared, unsigned int value);
int sem_destroy(sem_t *sem);
int sem_wait(sem_t *sem);
int sem_trywait(sem_t *sem);
int sem_post(sem_t *sem);
参考
https://blog.csdn.net/qq_53508543/article/details/135471988
实践-基于POSIX有名信号量
上一篇博客写了共享内存,给了大家示例的代码。《opencv 打开图片后,cv::mat存入共享内存的代码,以及如何设置共享内存的大小?图片的3840x2160 pixels》,基于此进行生产者消费者尝试。
生产者消费者模型任务说明
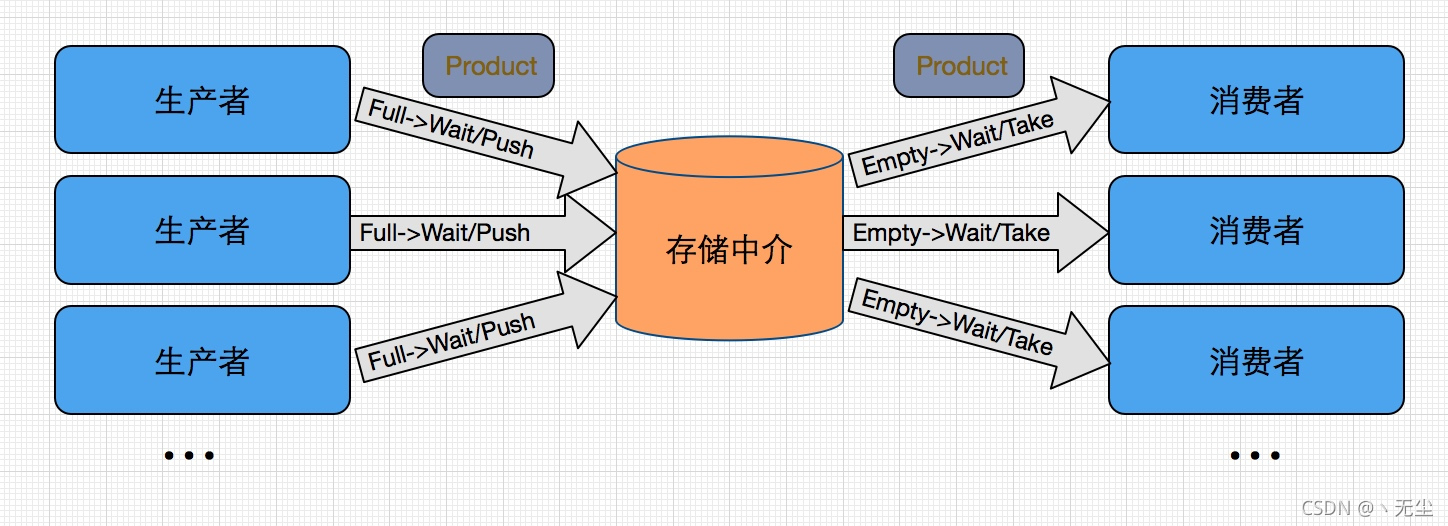
生产者消费者问题(Producer-consumer problem),也称有限缓冲问题(Bounded-buffer problem),是一个著名的进程同步问题的经典案例。它描述的是有一组生产者进程在生产产品,并将这些产品提供给一组消费者进程去消费。为使生产者进程和消费者进程能够并发执行,在这两者之间设置里一个具有 n 个缓冲区的缓冲池,生产者进程将他所生产的的产品放入一个缓冲区中;消费者进程可从一个缓冲区中取走产品并进行消费。尽管所有的生产者进程和消费者进程都是以异步方式运行的,但亡们之间必须保特同步,即不允许消费者进程到一个空缓冲区中去取产品;也不允许生产者进程向一个已装满产品且产品尚未被取走的缓冲区投放产品。
思路分析
我们分析题目中的同步和互斥关系:
同步关系
当缓冲区有空位时,生产者进程才可以生产
当缓冲区有产品是,消费者进程才可以消费
互斥关系
生产者进程与消费者进程对缓冲区的访问是互斥的
 整体思路
整体思路
总体思路如下:
- 设置一个生产者进程,负责生产产品
- 设置一个消费这进程,负责消费产品
- 生产者与消费者进程间的通讯通过共享内存实现
- 设置一个互斥信号量,实现对共享内存的互斥访问
- 设置两个信号量,用于标记资源的数目,实现进程间的两个同步关系
设置一个互斥信号量,实现对共享内存的互斥访问
参考例子
#include <unistd.h>
#include <stdio.h>
#include <pthread.h>
#include <semaphore.h>
#include <stdlib.h>
#include <stdio.h>
#include <sys/types.h>
#include <fcntl.h>
#include <sys/wait.h>
int main(int argc, char **argv)
{
int pid;
sem_t *sem;
const char sem_name[] = "my_sem_test";
pid = fork();
if (pid < 0) {
printf("error in the fork!\n");
}
/* 子进程 */
else if (pid == 0) {
/*创建/打开一个初始值为1的信号量*/
sem = sem_open(sem_name, O_CREAT, 0644, 1);
if (sem == SEM_FAILED) {
printf("unable to create semaphore...\n");
sem_unlink(sem_name);
exit(-1);
}
/*获取信号量*/
sem_wait(sem);
for (int i = 0; i < 3; ++i) {
printf("child process run: %d\n", i);
/*睡眠释放CPU占用*/
sleep(1);
}
/*释放信号量*/
sem_post(sem);
}
/* 父进程 */
else {
/*创建/打开一个初始值为1的信号量*/
sem = sem_open(sem_name, O_CREAT, 0644, 1);
if (sem == SEM_FAILED) {
printf("unable to create semaphore...\n");
sem_unlink(sem_name);
exit(-1);
}
/*申请信号量*/
sem_wait(sem);
for (int i = 0; i < 3; ++i) {
printf("parent process run: %d\n", i);
/*睡眠释放CPU占用*/
sleep(1);
}
/*释放信号量*/
sem_post(sem);
/*等待子进程结束*/
wait(NULL);
/*关闭信号量*/
sem_close(sem);
/*删除信号量*/
sem_unlink(sem_name);
}
return 0;
}
设置两个信号量,用于标记资源的数目,实现进程间的两个同步关系
一个表示空槽位(empty slots)的信号量(empty),用于同步生产者和消费者。当缓冲区为空时,消费者必须等待生产者生成数据。
一个表示满槽位(full slots)的信号量(full),也用于同步生产者和消费者。当缓冲区已满时,生产者必须等待消费者消费数据。
发送
考虑到只有一个内存,存满了就没有了,因此设置信号量队列是1。
sem_t * sem_empty = sem_open("/sem_name1", O_CREAT, 0644, 1);
if (sem_empty == SEM_FAILED) {
printf("unable to create semaphore...\n");
sem_unlink("/sem_name1");
exit(-1);
}
sem_t * sem_full = sem_open("/sem_name2", O_CREAT, 0644, 0);
if (sem_full == SEM_FAILED) {
printf("unable to create semaphore...\n");
sem_unlink("/sem_name2");
exit(-1);
}
处理过程
// wait for empty slot
sem_wait(sem_empty);
// get lock
sem_wait(sem);
memcpy(mem, image.data, image.total() * image.elemSize());
sem_post(sem);
// tell customer to use
sem_post(sem_full);
接受
sem_t * sem_empty = sem_open("/sem_name1", 0);
if (sem_empty == SEM_FAILED) {
printf("unable to create semaphore...\n");
sem_unlink("/sem_name1");
exit(-1);
}
sem_t * sem_full = sem_open("/sem_name2",0);
if (sem_full == SEM_FAILED) {
printf("unable to create semaphore...\n");
sem_unlink("/sem_name2");
exit(-1);
}
处理过程
// wait
sem_wait(sem_full);
// get lock
sem_wait(sem);
cv::Mat image(height, width, type, mem);
sem_post(sem);
// tell producer to make
sem_post(sem_empty);
参考的文心一言的伪代码
// 初始化信号量
semaphore mutex = 1; // 互斥信号量,初始化为1,表示没有进程在访问共享缓冲区
semaphore empty = N; // 空槽位信号量,初始化为缓冲区大小N
semaphore full = 0; // 满槽位信号量,初始化为0,因为缓冲区开始时是空的
// 生产者进程
while (true) {
// 生产数据项
item = produce_item();
// 等待缓冲区有空槽位
P(empty); // P操作,即等待(wait)信号量empty变为非零,然后将其减1
// 访问共享缓冲区(临界区)
P(mutex); // 等待mutex变为非零,然后将其减1,进入临界区
// 将数据放入缓冲区
put_item_into_buffer(item);
V(mutex); // V操作,即释放(signal)mutex,将其加1
// 通知消费者缓冲区有数据
V(full); // 释放full信号量,将其加1
}
// 消费者进程
while (true) {
// 等待缓冲区有数据
P(full); // 等待full变为非零,然后将其减1
// 访问共享缓冲区(临界区)
P(mutex); // 等待mutex变为非零,然后将其减1,进入临界区
// 从缓冲区取出数据
item = get_item_from_buffer();
V(mutex); // 释放mutex信号量,将其加1
// 处理数据项
consume_item(item);
// 通知生产者缓冲区有空槽位
V(empty); // 释放empty信号量,将其加1
}
代码分享
https://gitee.com/hiyanyx/share-memory-mmap-opencv/tree/Producer-consumer
下一步
1、如何设置队列?
目前是一个内存,存满了就等待,如何处理呢?
写完了博客,链接:https://blog.csdn.net/djfjkj52/article/details/139806993
2、使用STL 容器在共享内存怎么搞?
STL的容器很方便使用啊,要是能联合,岂不乐哉
写完了博客,链接:https://blog.csdn.net/djfjkj52/article/details/139805285
3、消息队列,例如POSIX 消息队列
<sys/msg.h> 是 Unix 和类 Unix 系统(如 Linux)中用于支持 POSIX 消息队列的头文件。
-
消息队列是在消息的传输过程中保存消息的容器。它通常是在内核空间中维护的,进程通过特定的标识符(如msgid)对消息队列进行读写操作。
-
消息队列中的信息通常是一个结构体,包含了消息的种类(类似身份证)和消息的内容。通过这种方式,多个进程间可以通过消息的种类来进行通讯,实现了进程间的定向信息传输。
-消息队列克服了信号承载信息量少、管道只能承载无格式字节流以及缓冲区大小受限等缺点。 -
在传输数据方面,消息队列可以使用UDP进行传输。UDP为应用程序提供了一种无需建立连接就可以发送封装的IP数据包的方法。
消息队列可以基于多种机制进行数据传输,主要可以分为两大类:内存中的消息队列:
这类消息队列直接在系统内存中创建和管理消息,不需要通过网络传输。它们通常用于在同一台机器上的不同进程间进行通信。
例如,某些消息队列系统(如RabbitMQ、ActiveMQ等)可以在本地机器上运行,通过进程间的共享内存或其他内存管理机制进行消息的存储和传输。
基于网络的消息队列:
这类消息队列通过网络协议(如TCP/IP、UDP等)进行消息的传输,允许在不同机器上的进程间进行通信。
TCP/IP:TCP/IP协议提供了可靠的、面向连接的字节流传输服务。基于TCP/IP的消息队列系统可以确保消息的完整性和顺序性,即使在网络条件不佳的情况下也能保证消息的可靠传输。
UDP:虽然UDP协议本身不提供可靠的数据传输保证,但某些消息队列系统(如Kafka)可以选择使用UDP进行数据传输。UDP传输速度快,适用于对性能要求极高且对消息丢失或乱序不太敏感的场景。
此外,消息队列的传输方式还取决于具体的消息队列系统和其配置。例如:
- Kafka:Kafka主要特点是基于Pull的模式来处理消息消费,追求高吞吐量。它通常使用TCP/IP协议进行数据传输,但也可以配置为使用其他协议。
- RabbitMQ:RabbitMQ是基于AMQP(高级消息队列协议)的开源消息队列系统。AMQP协议更多用在企业系统内,对数据一致性、稳定性和可靠性要求很高的场景。它同样使用TCP/IP协议进行数据传输。
归纳来说,消息队列可以基于内存或网络进行数据传输。在网络传输方面,TCP/IP协议由于其可靠性和稳定性而被广泛采用,而UDP则因其高性能和轻量级在某些场景下被选择使用。但具体使用哪种传输方式,还需要根据实际需求、系统架构和网络环境来综合考虑。

![[面试题]RabbitMQ](https://img-blog.csdnimg.cn/direct/6507af77273149edbd66e3abcb940ebf.jpeg#pic_left)





![【2024最新华为OD-C/D卷试题汇总】[支持在线评测] 机器人搬砖(100分) - 三语言AC题解(Python/Java/Cpp)](https://img-blog.csdnimg.cn/direct/f8335274b3b44df3a537966511be76a4.png)