更多2024最新AI大模型-LLm八股合集可以拉到文末!!!
MHA & MQA & MGA
(1)MHA
从多头注意力的结构图中,貌似这个所谓的多个头就是指多组线性变换层,其实并不是,只有使用了一组线性变化层,即三个变换张量对Q,K,V分别进行线性变换,这些变换不会改变原有张量的尺寸,因此每个变换矩阵都是方阵,得到输出结果后,多头的作用才开始显现,每个头开始从词义层面分割输出的张量,也就是每个头都想获得一组Q,K,V进行注意力机制的计算,但是句子中的每个词的表示只获得一部分,也就是只分割了最后一维的词嵌入向量。这就是所谓的多头,将每个头的获得的输入送到注意力机制中, 就形成多头注意力机制.
Multi-head attention允许模型共同关注来自不同位置的不同表示子空间的信息,如果只有一个attention head,它的平均值会削弱这个信息。


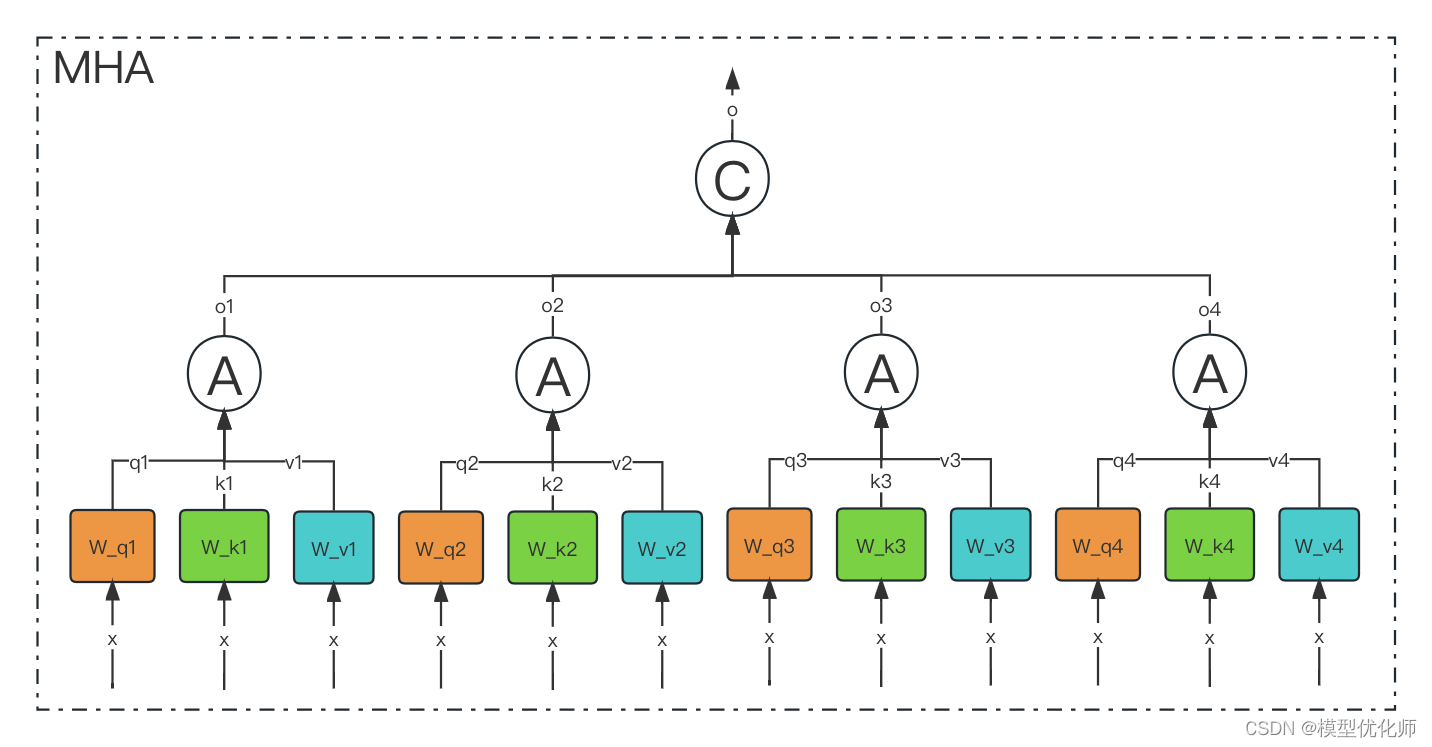
多头注意力作用
这种结构设计能让每个注意力机制去优化每个词汇的不同特征部分,从而均衡同一种注意力机制可能产生的偏差,让词义拥有来自更多元的表达,实验表明可以从而提升模型效果.
为什么要做多头注意力机制呢?
一个 dot product 的注意力里面,没有什么可以学的参数。具体函数就是内积,为了识别不一样的模式,希望有不一样的计算相似度的办法。加性 attention 有一个权重可学,也许能学到一些内容。
multi-head attention 给 h 次机会去学习 不一样的投影的方法,使得在投影进去的度量空间里面能够去匹配不同模式需要的一些相似函数,然后把 h 个 heads 拼接起来,最后再做一次投影。
每一个头 hi 是把 Q,K,V 通过 可以学习的 Wq, Wk, Wv 投影到 dv 上,再通过注意力函数,得到 headi。
(2)MQA
MQA(Multi Query Attention)最早是出现在2019年谷歌的一篇论文 《Fast Transformer Decoding: One Write-Head is All You Need》。
MQA的思想其实比较简单,MQA 与 MHA 不同的是,MQA 让所有的头之间共享同一份 Key 和 Value 矩阵,每个头正常的只单独保留了一份 Query 参数,从而大大减少 Key 和 Value 矩阵的参数量。
Multi-query attention is identical except that the different heads share a single set of keys and values.

在 Multi-Query Attention 方法中只会保留一个单独的key-value头,这样虽然可以提升推理的速度,但是会带来精度上的损失。《Multi-Head Attention:Collaborate Instead of Concatenate 》这篇论文的第一个思路是基于多个 MQA 的 checkpoint 进行 finetuning,来得到了一个质量更高的 MQA 模型。这个过程也被称为 Uptraining。
具体分为两步:
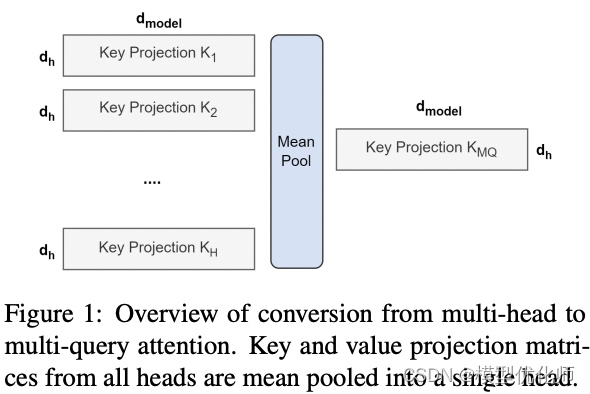
对多个 MQA 的 checkpoint 文件进行融合,融合的方法是: 通过对 key 和 value 的 head 头进行 mean pooling 操作,如下图。
对融合后的模型使用少量数据进行 finetune 训练,重训后的模型大小跟之前一样,但是效果会更好
(3)GQA
Google 在 2023 年发表的一篇 《GQA: Training Generalized Multi-Query Transformer Models from Multi-Head Checkpoints》的论文
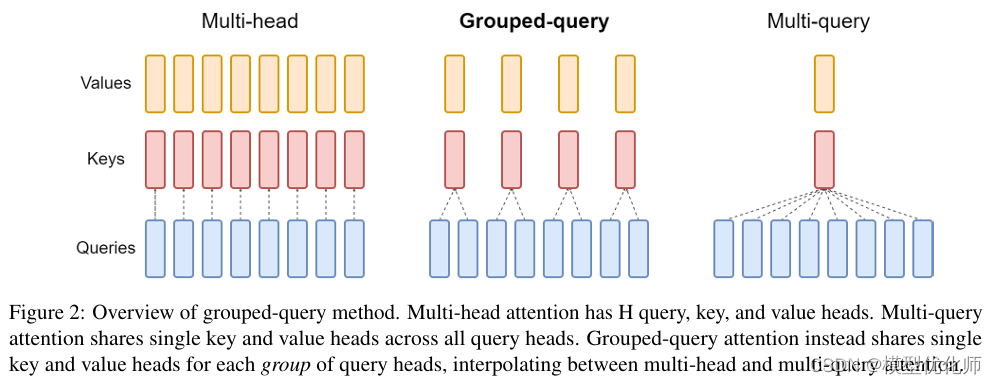
如下图所示,
在
MHA(Multi Head Attention)
中,每个头有自己单独的 key-value 对;
在
MQA(Multi Query Attention)
中只会有一组 key-value 对;
在
GQA(Grouped Query Attention)
中,会对 attention 进行分组操作,query 被分为 N 组,每个组共享一个 Key 和 Value 矩阵。
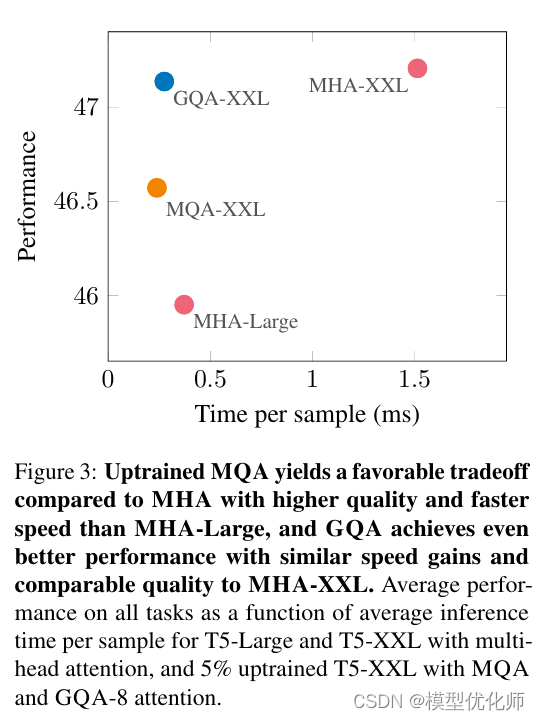
GQA-N 是指具有 N 组的 Grouped Query Attention。GQA-1具有单个组,因此具有单个Key 和 Value,等效于MQA。而GQA-H具有与头数相等的组,等效于MHA。
在基于 Multi-head 多头结构变为 Grouped-query 分组结构的时候,也是采用跟上图一样的方法,对每一组的 key-value 对进行 mean pool 的操作进行参数融合。融合后的模型能力更综合,精度比 Multi-query 好,同时速度比 Multi-head 快。

(4)总结
MHA(Multi-head Attention)是标准的多头注意力机制,h个Query、Key 和 Value 矩阵。
MQA(Multi-Query Attention)是多查询注意力的一种变体,也是用于自回归解码的一种注意力机制。与MHA不同的是,MQA 让所有的头之间共享同一份 Key 和 Value 矩阵,每个头只单独保留了一份 Query 参数,从而大大减少 Key 和 Value 矩阵的参数量。
GQA(Grouped-Query Attention)是分组查询注意力,GQA将查询头分成G组,每个组共享一个Key 和 Value 矩阵。GQA-G是指具有G组的grouped-query attention。GQA-1具有单个组,因此具有单个Key 和 Value,等效于MQA。而GQA-H具有与头数相等的组,等效于MHA。
GQA介于MHA和MQA之间。GQA 综合 MHA 和 MQA ,既不损失太多性能,又能利用 MQA 的推理加速。不是所有 Q 头共享一组 KV,而是分组一定头数 Q 共享一组 KV,比如上图中就是两组 Q 共享一组 KV。
面试题笔记分享
为了助力朋友们跳槽面试、升职加薪、职业困境,提高自己的技术,本文给大家整了一套涵盖Android所有技术栈的快速学习方法和笔记。目前已经收到了七八个网友的反馈,说是面试问到了很多这里面的知识点。
每一章节都是站在企业考察思维出发,作为招聘者角度回答。从考察问题延展到考察知识点,再到如何优雅回答一面俱全,可以说是求职面试的必备宝典,每一部分都有上百页内容,接下来具体展示,完整版可直接下方扫码领取。
😝有需要的小伙伴,可以V扫描下方二维码免费领取🆓
 ## 大模型(LLMs)基础面
## 大模型(LLMs)基础面
1.目前 主流的开源模型体系 有哪些?
2.prefix LM 和 causal LM 区别是什么?
3.涌现能力是啥原因?
4.大模型 LLM的架构介绍?
大模型(LLMs)进阶面
1.llama 输入句子长度理论上可以无限长吗?
2.什么是 LLMs 复读机问题?
3.为什么会出现 LLMs 复读机问题?
4.如何缓解 LLMs 复读机问题?
5.LLMs 复读机问题
6.lama 系列问题
7.什么情况用 Bert模型,什么情况用LLaMA、ChatGLM类大模型,咋选?8.各个专业领域是否需要各自的大模型来服务?
9.如何让大模型处理更长的文本?
大模型(LLMs)微调面
1.如果想要在某个模型基础上做全参数微调,究竟需要多少显存?
2.为什么 SFT之后感觉 LLM傻了?
3.SFT 指令微调数据 如何构建?
4.领域模型 Continue PreTrain 数据选取?5.领域数据训练后,通用能力往往会有所下降,如何缓解模型遗忘通用能力?
6.领域模型 Continue PreTrain ,如何 让模型在预训练过程中就学习到更多的知识?7.进行 SFT操作的时候,基座模型选用Chat还是 Base?
8.领域模型微调 指令&数据输入格式 要求?
9.领域模型微调 领域评测集 构建?
10.领域模型词表扩增是不是有必要的?
11.如何训练自己的大模型?
12.训练中文大模型有啥经验?
13.指令微调的好处?
14.预训练和微调哪个阶段注入知识的?15.想让模型学习某个领域或行业的知识,是
应该预训练还是应该微调?
16.多轮对话任务如何微调模型?
17.微调后的模型出现能力劣化,灾难性遗忘
是怎么回事?
大模型(LLMs)langchain面
1.基于 LLM+向量库的文档对话 基础面
2.基于 LLM+向量库的文档对话 优化面
3.LLMs 存在模型幻觉问题,请问如何处理?
4.基于 LLM+向量库的文档对话 思路是怎么样?
5.基于 LLM+向量库的文档对话 核心技术是什么?
6.基于 LLM+向量库的文档对话 prompt 模板如何构建?
7.痛点1:文档切分粒度不好把控,既担心噪声太多又担心语义信息丢失
2.痛点2:在基于垂直领域 表现不佳
3.痛点 3:langchain 内置 问答分句效果不佳问题
4.痛点 4:如何 尽可能召回与 query相关的Document 问题
5.痛点5:如何让 LLM基于 query和 context
得到高质量的response
6.什么是 LangChain?
7.LangChain 包含哪些 核心概念?
8.什么是 LangChain Agent?
9.如何使用 LangChain ?
10.LangChain 支持哪些功能?
11.什么是 LangChain model?
12.LangChain 包含哪些特点?
大模型(LLMs):参数高效微调(PEFT)面
1.LORA篇2.QLoRA篇
3.AdaLoRA篇
4.LORA权重是否可以合入原模型?
5.LORA 微调优点是什么?
6.LORA微调方法为啥能加速训练?
7.如何在已有 LORA模型上继续训练?
1.1 什么是 LORA?
1.2 LORA 的思路是什么?
1.3 LORA 的特点是什么?
2.1 QLORA 的思路是怎么样的?
2.2 QLORA 的特点是什么?
8.3.1 AdaLoRA 的思路是怎么样的?为什么需
要 提示学习(Prompting)?
9.什么是 提示学习(Prompting)?10.提示学习(Prompting)有什么优点?11.提示学习(Prompting)有哪些方法,能不能稍微介绍一下它们间?
4.4.1为什么需要 P-tuning v2?
4.4.2 P-tuning v2 思路是什么?
4.4.3 P-tuning v2 优点是什么?
4.4.4 P-tuning v2 缺点是什么?
4.3.1为什么需要 P-tuning?
😝有需要的小伙伴,可以V扫描下方二维码免费领取🆓
## 大模型评测面(LLMs)三
大模型怎么评测?
大模型的 honest原则是如何实现的?模型如何判断回答的知识是训练过的已知的知识,怎么训练这种能力?大模型(LLMs)强化学习面奖励模型需要和基础模型一致吗?RLHF 在实践过程中存在哪些不足?如何解决 人工产生的偏好数据集成本较高很难量产问题?如何解决三个阶段的训练(SFT->RM->PPO)过程较长,更新迭代较慢问题?如何解决 PPO 的训练过程同时存在4个模型(2训练,2推理),对计算资源的要求较高问题?

![[WTL/Win32]_[中级]_[MVP架构在实际项目中的应用]](https://img-blog.csdnimg.cn/direct/466ffe7b1bcf4f74a032871c30ad58b8.png)