前言
最近准备做一个监控系统,正好看到了这篇文章,这篇文章很简单,但很清晰,结合原文的图片,我进行一下翻译。
原文地址
ByteByteGo
原文
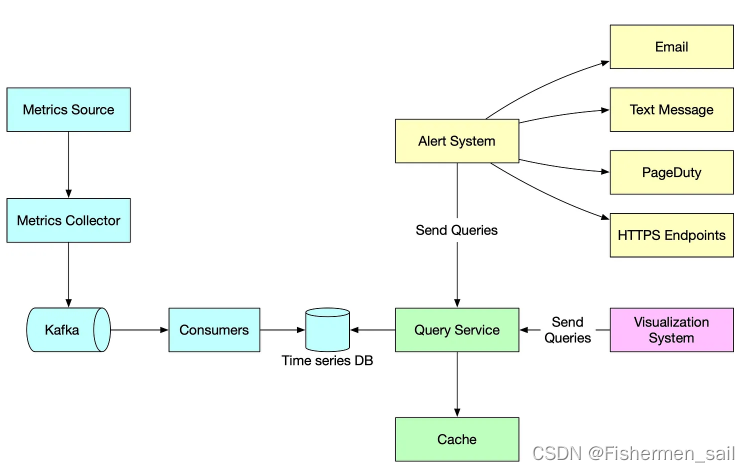
A well-designed metric monitoring and alerting system plays a key role in providing clear visibility into the health of the infrastructure to ensure high availability and reliability. The diagram below explains how it works at a high level.
Metrics source: This can be application servers, SQL databases, message queues, etc.
Metrics collector: It gathers metrics data and writes data into the time-series database.
Time-series database: This stores metrics data as time series. It usually provides a custom query interface for analyzing and summarizing a large amount of time-series data. It maintains indexes on labels to facilitate the fast lookup of time-series data by labels.
Kafka: Kafka is used as a highly reliable and scalable distributed messaging platform. It decouples the data collection and data processing services from each other.
Consumers: Consumers or streaming processing services such as Apache Storm, Flink and Spark, process and push data to the time-series database.
Query service: The query service makes it easy to query and retrieve data from the time-series database. This should be a very thin wrapper if we choose a good time-series database. It could also be entirely replaced by the time-series database’s own query interface.
Alerting system: This sends alert notifications to various alerting destinations.
Visualization system: This shows metrics in the form of various graphs/charts.
翻译
一个不错的指标监管系统和报警系统可以提供很清晰的可视化,来去确保系统的健康运行,保证它的可用性以及可靠性,下面的架构图回答了监管系统是如何工作的。
- Metrics source:这代表了一个应用服务,也就是被监控的对象,可以是Oracle、MySQL、Linux、Docker等等。
- Metrics collector:负责收集采集到的各项被监控指标,之后存到时序数据库中。
- Kafka:被用来作为一个高可靠且可扩展的分布式消息平台,它解耦了数据采集和数据运行服务间的关系。
- Consumers:“消费者”,或者流处理服务像是Spark、Flink等,进行实时计算然后推送到时序数据库。
- Time-series database:将各项指标数据作为时间序列进行存储,它会提供一个自定义的接口来实现对庞大的时间序列数据的分析和汇总。它通过维护标签上的索引来促进快速的时间序列数据的搜索。
- Query service:可以从时序数据库中查询数据,如果数据库性能比较好,这会是一个轻量的封装,甚至有的时序数据库自带查询的实现。
- Alerting system:通过不同的方式发送告警通知。
- Visualization system:用表或图的方式对数据进行可视化展示。
文章批注
备注:这些东西我都没有使用过,只是简单批注。
1)Time-series database
时序数据库简称TSDB,可以理解为时间是它的index,比较出名的有InfluxDB。
TSDB有很多应用场景,像是监控系统,需要实时的或是每间隔几秒就要收集一个监控对象的相关指标。
那传统的关系型数据库将时间作为一个表的index来存数据库就是TSDB吗?肯定不是,因为要实时,数据量是非常大的,像传统的关系型数据库,处理大数据时的效果非常糟糕,数据量太大会给记录和查询操作带来严重的性能问题,而且写入还是以非常快的速度,这就需要用到一些非关系型数据库。而且TSDB是以时间为核心的,肯定会针对时间单独进行一些设计,提高性能,更能适应像监控系统这种非常依赖于时间的应用场景。
2)Message queues
消息队列,简单来讲,我觉得MQ就像一个比较高级的缓冲池。知乎文章里高赞举了一个比较通俗的例子,写的非常清楚。比如说小红和小明,小红要经常给小明书看,在这个背景下,可以造一个书架,这个书架就是消息队列。这样带来了很多好处:
- 解耦:小红可以不用关心啥时候取走了书,小明也不需要知道书啥时候来了,需要看的时候自己去取就行,两个人不需要建立联系。
- 提速:小红把书放到书架上就行了,不用非要等小明来拿。
- 广播:如果又有小张想看书,那小红依然是可以把书放在书架上。
- 消峰:小明拿到书后,没看完可以不用急着去取书,否则都堆在自己手上压力太大。
坏处就是,使得系统的复杂度增加,而且会造成暂时的不一致性,比如说小红给你了一本书,理论上小明手里应该有一本,但小明还没有去拿。
消息队列有很多,应该学哪个呢?网上有很多分析的文章,下面这个来自知乎一篇文章的总结。
- 如果消息队列不是将要构建系统的重点,对消息队列功能和性能没有很高的要求,只需要一个快速上手易于维护的消息队列,建议使用 RabbitMQ。
- 如果系统使用消息队列主要场景是处理在线业务,比如在交易系统中用消息队列传递订单,需要低延迟和高稳定性,建议使用 RocketMQ。
- 如果需要处理海量的消息,像收集日志、监控信息或是埋点这类数据,或是你的应用场景大量使用了大数据、流计算相关的开源产品,那 Kafka 是最适合的消息队列。
3)Consumer里提到了“streaming processing services”,还提到了Spark,所以Spark和Streaming有什么关系?
Spark主要用来做数据计算,而Spark Streaming针对实时数据做计算的。Spark程序是使用一个Spark应用实例一次性对一批历史数据进行处理,Spark Streaming是将持续不断输入的数据流转换成多个batch分片,使用一批spark应用实例进行处理,侧重点在Steaming上面。具体的应用场景比如说机器学习这种需要计算大量数据。
4)Metrics collector
比如说Zabbix,用它自己的方式,可以采集Windows、Linux等各项指标内容。
5)Query service
主要就是指对TSDB提供一种查询方式,类似于关系型数据库的SQL。