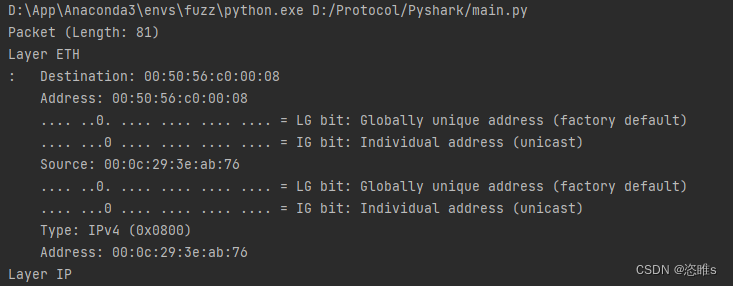
import pyshark
# 读取PCAP文件
pcap_file = 'captured_packets.pcap' # 替换为你的PCAP文件路径
cap = pyshark.FileCapture(pcap_file)
# 遍历数据包并提取FTP数据包
ftp_packets = []
for packet in cap:
if 'FTP' in packet:
ftp_packets.append(packet)
# 输出FTP数据包
for ftp_packet in ftp_packets:
print(ftp_packet)
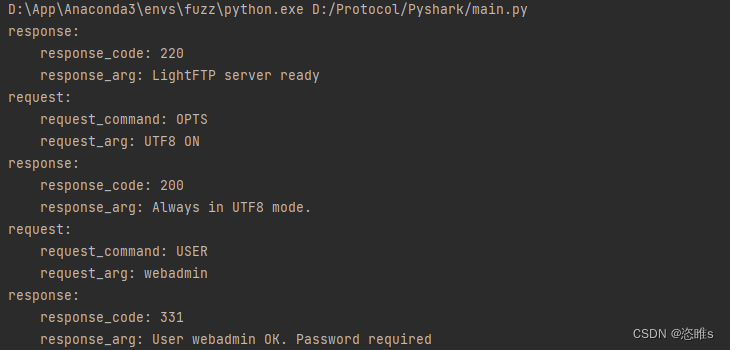
输出每条FTP请求或响应的功能码和含义:
import pyshark
# 读取PCAP文件
pcap_file = 'captured_packets.pcap' # 替换为你的PCAP文件路径
cap = pyshark.FileCapture(pcap_file)
# 遍历数据包并提取FTP数据包
ftp_packets = []
for packet in cap:
if 'FTP' in packet:
ftp_packets.append(packet)
# 输出FTP数据包
for ftp_packet in ftp_packets:
# 打印整个FTP层信息
for layer in ftp_packet.layers:
if layer.layer_name == 'ftp':
if layer.get_field("request") == 'True':
print("request:")
print(f" request_command: {layer.get_field('request_command')}")
print(f" request_arg: {layer.get_field('request_arg')}")
if layer.get_field("request") == 'False':
print("response:")
print(f" response_code: {layer.get_field('response_code')}")
print(f" response_arg: {layer.get_field('response_arg')}")
说明:本文章主要是对mongodb的单击安装
1.创建文件夹,准备安装包
cd /user/local
mkdir tools 2.解压mongodb包
mkdir mongodb
tar -xvf mongodb-linux-x86_64-rhel70-5.0.11.tgz -C mongodb 3.进入解压目录
cd mongodb
cd mongodb-linux-x86_64-…
MySQL 自增 ID 一般用的数据类型是 INT 或 BIGINT,正常情况下这两种类型可以满足大多数应用的需求。
当然也有不正常的情况,当达到其最大值时,尝试插入新的记录会导致错误,错误信息类似于:
ERROR 167 (22003): Out o…