先来看一个结论:只要redo log和binlog保证持久化到磁盘, 就能确保MySQL异常重启后, 数据可以恢复。
binlog写入逻辑
binlog的写入逻辑比较简单: 事务执行过程中, 先把日志写到binlog cache, 事务提交的时候, 再把binlog cache写到binlog文件中,并清空binlog cache。
在这个过程中,系统给binlog cache分配了一片内存,线程私有,参数binlog_cache_size用于控制单个线程内binlog cache所占内存的大小。如果超过了这个参数规定的大小,就要暂存到磁盘。
binlog写入逻辑状态图如下:
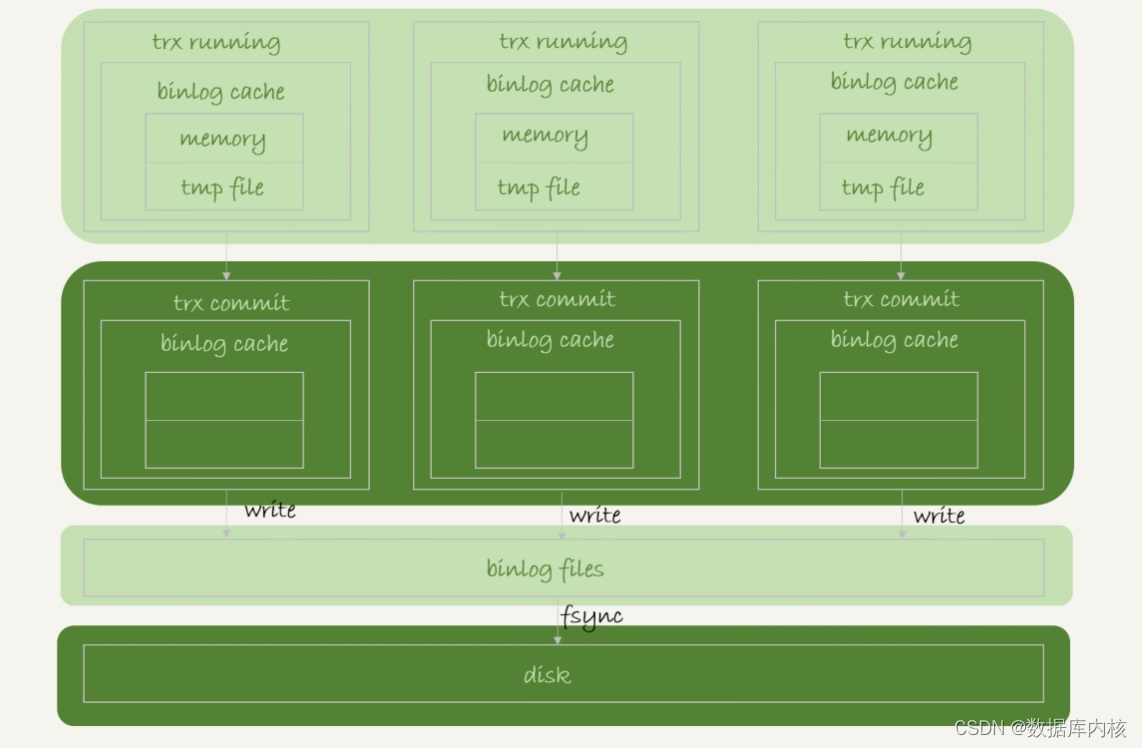
可以看到, 每个线程有自己binlog cache, 但是共用同一份binlog文件。
- 图中的write, 指的就是指把日志写入到文件系统的page cache, 并没有把数据持久化到磁盘, 所以速度比较快。(掉电会丢数据)
- 图中的fsync, 才是将数据持久化到磁盘的操作。 一般情况下, 我们认为fsync才占磁盘的IOPS(每秒的读写次数)。(掉电不丢数据)
write 和fsync的时机, 是由参数sync_binlog控制的:
1)sync_binlog=0的时候, 表示每次提交事务都只write, 不fsync。
2)sync_binlog=1的时候, 表示每次提交事务都会执行fsync。
3)sync_binlog=N(N>1)的时候, 表示每次提交事务都write, 但累积N个事务后才fsync。
因此, 在出现IO瓶颈的场景里, 将sync_binlog设置成一个比较大的值, 可以提升性能。 在实际的业务场景中, 考虑到丢失日志量的可控性, 一般不建议将这个参数设成0, 比较常见的是将其设置为100~1000中的某个数值。
注1:一个事务的binlog是不能被拆开的,因此不论这个事务多大,也要确保一次性写入。
注2:每个线程有自己binlog cache,但是共用同一份binlog file。
redo log写入逻辑
1)redo log写入逻辑
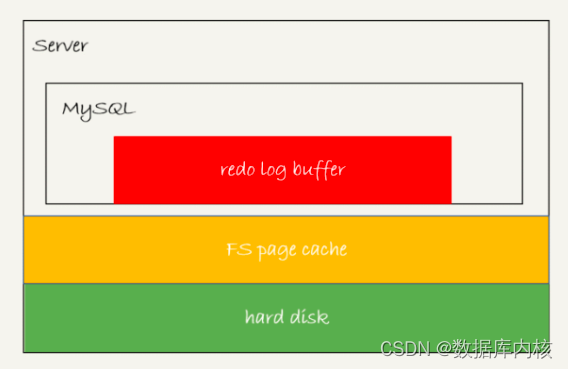
- 事务执行过程中,生成的redo log会先写到redo log buffer。(内存)
- redo log buffer中的日志并不一定会立即持久化到磁盘。
- 当节点宕机或者系统掉电后,redo log buffer中的日志丢失,但由于事务并没有提交,binlog日志未落盘,所以这时日志丢了也不会有损失。
- InnoDB有一个后台线程,每隔1秒会把redo log buffer中的日志,flush到文件系统的page cache中,然后调用fsync持久化到磁盘。
注:redo log buffer是全局共用的。
2)redo log可能的状态
- 存在redo log buffer中,即进程内存中,对应图中红色部分。
- 写到磁盘(flush),但未持久化(fsync),物理上是在文件系统的page cache里面, 即图中的黄色部分。
- 持久化到磁盘,对应的是hard disk,即图中的绿色部分。(一般fsync才会占用磁盘的IOPS,所以较慢)
注:日志写到redo log buffer是很快的, wirte到page cache也差不多, 但是持久化到磁盘的速度就慢多了。
3)为了控制redo log的写入策略, InnoDB提供了innodb_flush_log_at_trx_commit参数, 它有三种可能取值:
- 设置为0,表示每次事务提交时都只是把redo log留在redo log buffer中。
- 设置为1,表示每次事务提交时都将redo log直接持久化到磁盘(把redo log buffer中的所有日志全部持久化到磁盘)。
- 设置为2,表示每次事务提交时都只是把redo log写到page cache。
注1:InnoDB有一个后台线程, 每隔1秒, 就会把redo log buffer中的日志, 调用write写到文件系统的page cache, 然后调用fsync持久化到磁盘。
注2:事务执行过程中的redo log也直接写在redo log buffer中的,这些redo log也会被后台线程一起持久化到磁盘。也就是说,一个没有提交的事务的redo log也可能已经被持久化到磁盘。
问1:除了后台线程每秒一次的轮询操作外,还有什么场景会让一个没有提交的事务的redo log写入磁盘?
- 一种是, redo log buffer占用的空间即将达到 innodb_log_buffer_size一半的时候(即redo log buffer使用率过半时),后台线程会主动写盘。 注意, 由于这个事务并没有提交, 所以这个写盘动作只是write, 而没有调用fsync, 也就是只留在了文件系统的page cache。
- 另一种是, 并行的事务提交的时候, 顺带将这个事务的redo log buffer持久化到磁盘。 假设一个事务A执行到一半, 已经写了一些redo log到buffer中, 这时候有另外一个线程的事务B提交, 如果innodb_flush_log_at_trx_commit设置的是1, 那么按照这个参数的逻辑, 事务B要把redo log buffer里的日志全部持久化到磁盘。 这时候, 就会带上事务A在redo log buffer里的日志一起持久化到磁盘。
注1:如果把innodb_flush_log_at_trx_commit设置成1, 那么redo log在prepare阶段就要持久化一次,因为有一个崩溃恢复逻辑是要依赖于prepare 的redo log, 再加上binlog来恢复的。
注2:每秒一次后台轮询刷盘, 再加上崩溃恢复这个逻辑, InnoDB就认为redo log在commit的时候就不需要fsync了, 只会write到文件系统的page cache中就够了。
问2:如果一个事务提交,需要等待两次刷盘,这是不是意味着从MySQL看到的TPS是每秒两万的话, 每秒就会写四万次磁盘。 但是, 我用工具测试出来, 磁盘能力也就两万左右, 怎么能实现两万的TPS?
答:通过组提交实现。
组提交机制
通常我们说MySQL的“双1”配置, 指的就是sync_binlog和innodb_flush_log_at_trx_commit都设置成 1。 也就是说, 一个事务完整提交前, 需要等待两次刷盘, 一次是redo log(prepare 阶段) , 一次是binlog。
问1:日志逻辑序列号(log sequence number, LSN) 是什么?
LSN是单调递增的, 用来对应redo log的一个个写入点。 每次写入长度为length的redo log, LSN的值就会加上length。
LSN也会写到InnoDB的数据页中, 来确保数据页不会被多次执行重复的redo log。
如下图所示,是三个并发事务(trx1, trx2, trx3)在prepare 阶段, 都写完redo log buffer, 持久化到磁盘的过程, 对应的LSN分别是50、 120 和160。
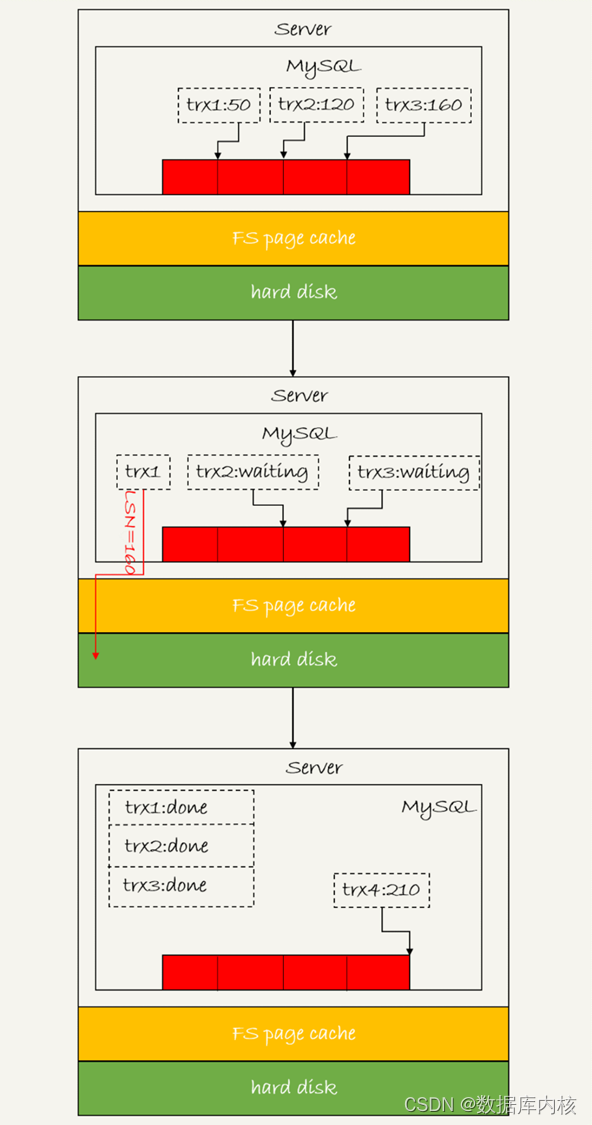
从图中可以看到:
1)trx1是第一个到达的, 会被选为这组的 leader。
2)等trx1要开始写盘的时候, 这个组里面已经有了三个事务, 这时候LSN也变成了160。
3)trx1去写盘的时候, 带的就是LSN=160, 因此等trx1返回时, 所有LSN小于等于160的redolog, 都已经被持久化到磁盘。
4)这时候trx2和trx3就可以直接返回了。(即trx2和trx3的redo log都被trx1 redo log持久化到磁盘时,一并持久化了)
所以, 一次组提交里面, 组员越多, 节约磁盘IOPS的效果越好。 但如果只有单线程压测, 那就只能老老实实地一个事务对应一次持久化操作了。
也就是说,在并发更新场景下, 第一个事务写完redo log buffer以后, 接下来这个fsync越晚调用, 组员可能越多, 节约IOPS的效果就越好。
为了让一次fsync带的组员更多, MySQL有一个很有趣的优化: 拖时间。如下图所示。

图中, 我把“写binlog”当成一个动作。 但实际上, 写binlog是分成两步的:
1)先把binlog从binlog cache中写到磁盘上的binlog文件。
2)调用fsync持久化。
MySQL为了让组提交的效果更好, 把redo log做fsync的时间拖到了步骤1之后。 也就是说, 上面的图变成了这样:
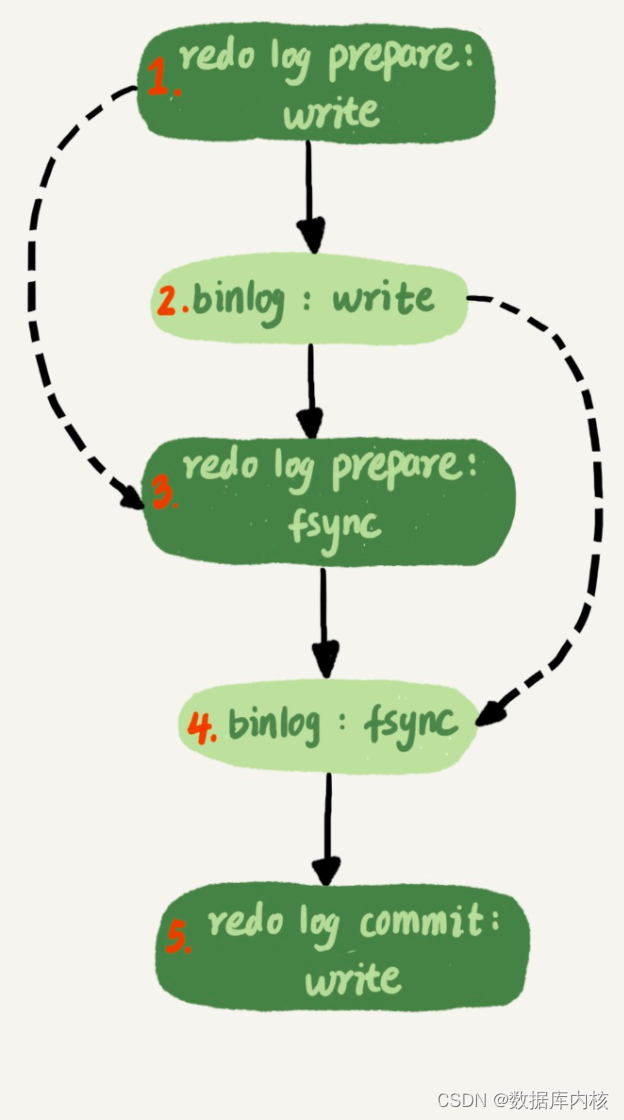
这么一来, binlog也可以组提交了。 在执行图中第4步把binlog fsync到磁盘时, 如果有多个事务的binlog已经写完了(即多个事务已提交), 也是一起持久化的, 这样也可以减少IOPS的消耗。
不过通常情况下第3步执行得会很快, 所以binlog的write和fsync间的间隔时间短, 导致能集合到一起持久化的binlog比较少, 因此binlog的组提交的效果通常不如redo log的效果那么好。
问2:如何提升binlog组提交的效果?
答:可以通过设置 binlog_group_commit_sync_delay和binlog_group_commit_sync_no_delay_count来实现。
1)binlog_group_commit_sync_delay参数, 表示延迟多少微秒后才调用fsync。(强行拖延时间)
2)binlog_group_commit_sync_no_delay_count参数, 表示累积等待的事务数量以后才调用fsync。
注1:这两个条件是或的关系, 也就是说只要有一个满足条件就会调用fsync。
注2:当binlog_group_commit_sync_delay设置为0的时候, binlog_group_commit_sync_no_delay_count也无效了。
问3:WAL机制是减少磁盘写, 可是每次提交事务都要写redo log和binlog, 这磁盘读写次数也没变少呀?
答:WAL机制主要得益于两个方面:
1)redo log 和 binlog都是顺序写, 磁盘的顺序写比随机写速度要快。
2)组提交机制, 可以大幅度降低磁盘的IOPS消耗。
问4:如果你的MySQL现在出现了性能瓶颈, 而且瓶颈在IO上, 可以通过哪些方法来提升性能呢?
答:针对这个问题, 可以考虑以下三种方法:
1)设置 binlog_group_commit_sync_delay和 binlog_group_commit_sync_no_delay_count参数, 减少binlog的写盘次数。 这个方法是基于“额外的故意等待”来实现的, 因此可能会增加语句的响应时间, 但没有丢失数据的风险。
2)将sync_binlog 设置为大于1的值(比较常见是100~1000) 。 这样做的风险是, 主机掉电时会丢binlog日志。
3)将innodb_flush_log_at_trx_commit设置为2。 这样做的风险是, 主机掉电的时候会丢数据。
注1:不建议把innodb_flush_log_at_trx_commit 设置成0。 因为把这个参数设置成0, 表示redo log只保存在内存中, 这样的话MySQL本身异常重启也会丢数据, 风险太大。 而redo log写到文件系统的page cache的速度也是很快的, 所以将这个参数设置成2跟设置成0其实性能差不多,但这样做MySQL异常重启时就不会丢数据了, 相比之下风险会更小。
注2:redo log在内存中,MySQL异常重启会丢失数据。redo log在page cache(文件系统)中,MySQL异常重启不会丢失数据,但主机掉电会丢失数据。
小结:什么是WAL?
回答这个问题前,先看一下磁盘、SSD、内存随机读写与顺序读写的性能对比,如下图所示:
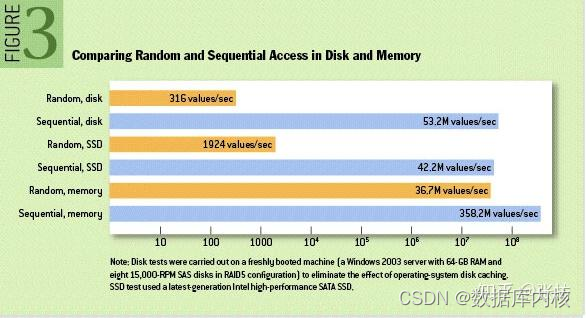
从上图可以看出两点:
1)内存的读写速度比磁盘随机读写高出几个数量级。
2)磁盘顺序读写速度堪比内存读写速度。
问1:什么是WAL呢?
WAL即 Write Ahead Log,WAL的核心思想是,每次更新操作都先写入日志,只做了写日志这一个磁盘操作。这个日志叫做redo log(重做日志),也就是《孔乙己》记账的粉板,在更新完内存写完redo log后,就返回给客户端,本次更新成功。而实际更新操作是由后台线程根据redo log异步写入。因此,对Client来说,延迟会减少。同时,顺序写入的可能性很大,如果更新的多条记录位于同一Page,则磁盘IO次数也能大大降低。
所以,WAL机制主要得益于三个方面:
1)减少更新数据的磁盘IO。
2)redo log 和 binlog都是顺序写, 磁盘的顺序写比随机写速度要快很多。
3)组提交机制, 可以大幅度降低磁盘的IOPS消耗。
问2:WAL和两阶段提交的区别是什么?
因此,WAL技术的关键是把随机写转化为顺序写,减少磁盘IO次数,以此提升数据库性能。
而两阶段提交是为了保证分布式事务架构数据的一致性,通常由redo log和binlog来保证。(具体什么是两阶段提交,在本文后面叙述)
注:使用redo log记录变更后的操作,使用undo log记录变更前的数据(用于回滚)。日志写入成功后,事务不会丢失。
小结:思考题
思考1:redo log和binlog是怎么关联起来的?
它们有一个共同的数据字段,叫XID。
1)崩溃恢复的时候,会先扫描最近的binlog,获取所有已提交的XID列表。
2)之后按顺序扫描redo log。
- 如果碰到既有prepare、又有commit的redo log,就直接提交。
- 如果碰到只有parepare、而没有commit的redo log,就拿着XID去binlog找对应的事务。若有,则提交。反之,回滚。
思考2:处于prepare阶段的redo log加上完整binlog,重启就能恢复,MySQL为什么要这么设计?
其实, 这个问题还是跟我们在反证法中说到的数据与备份的一致性有关。 在时刻B, 也就是binlog写完以后MySQL发生崩溃, 这时候binlog已经写入了, 之后就会被从库(或者用这个binlog恢复出来的库) 使用。所以, 在主库上也要提交这个事务。 采用这个策略, 主库和备库的数据就保证了一致性。
思考3:如果这样的话, 为什么还要两阶段提交呢? 干脆先redo log写完, 再写binlog。 崩溃恢复的时候, 必须得两个日志都完整才可以。 是不是一样的逻辑?
其实, 两阶段提交是经典的分布式系统问题, 并不是MySQL独有的。
如果必须要举一个场景, 来说明这么做的必要性的话, 那就是事务的持久性问题。对于InnoDB引擎来说, 如果redo log提交完成了, 事务就不能回滚(如果这还允许回滚, 就可能覆盖掉别的事务的更新) 。 而如果redo log直接提交, 然后binlog写入的时候失败, InnoDB又回滚不了, 数据和binlog日志又不一致了。
两阶段提交就是为了给所有人一个机会, 当每个人都说“我ok”的时候, 再一起提交。
思考4:redo log一般设置多大?
redo log太小的话,会导致很快就被写满,然后不得不强行刷redo log,这样WAL机制的能力就发挥不出来了。
所以,如果是现在常见的几个TB的磁盘的话,直接将redo log设置为4个文件、每个文件1GB。
思考5:正常运行中的实例,数据写入后的最终落盘,是从redo log更新过来的还是从buffer pool更新过来的呢?
redo log并没有记录数据页的完整数据,所以它并没有能力自己去更新磁盘数据页,也就不存在“数据最终落盘,是由redo log更新过去”的情况。
1)如果是正常运行的实例,数据页被修改以后,跟磁盘的数据页不一致,称为脏页。最终数据落盘,就是把内存中的数据页写盘。这个过程,基本与redo log毫无关系。
2)在崩溃恢复场景中,InnoDB如果判断到一个数据页可能在崩溃恢复的时候丢失了更新,就会将它读到内存,然后让redo log更新内存内容。更新完成后,内存页变成脏页,就回到了第一种情况的状态。
注:加载数据页的时候是以page为单位,所以数据落盘的时候也是以page为单位。
思考6:执行update语句以后,去执行hexdump命令直接查看ibd文件内容,为什么没有看到数据有改变呢?
这可能是因为WAL机制的原因。update语句执行完成后,InnoDB只保证写完了redo log、内存,可能还没来得及将数据写到磁盘。
思考7:为什么binlog cache是每个线程自己维护的,而redo log buffer是全局共用的?
1)binlog方面的原因:
- MySQL这么设计的主要原因是,binlog是不能“被打断的”(如果binlog cache是全局的,则可能会导致binlog交叉写入)。一个事务的binlog必须连续写,因此要整个事务完成后,再一起写到文件里。
2)redo log方面的原因:
- 而redo log并没有这个要求,中间有生成的日志可以写到redo log buffer中。redo log buffer中的内容还能“搭便车”,其他事务提交的时候可以被一起写到磁盘中。
- redo log的主要目的是确保事务的持久性和崩溃恢复,这个目的是全局性的,因此redo log buffer设计为全局共享是合理的。
- binlog存储是以statement或者row格式存储的,而redo log是以page页格式存储的。page格式,天生就是共有的,而row格式,只跟当前事务相关。
思考8:如果binlog写完盘以后发生crash,这时候还没给客户端答复就重启了。等客户端再重连进来,发现事务已经提交成功了,这是不是bug?
不是。实际上数据库的crash-safe保证的是:
1)如果客户端收到事务成功的消息,事务就一定持久化了。
2)如果客户端收到事务失败(比如主键冲突、回滚等)的消息,事务就一定失败了。
3)如果客户端收到“执行异常”的消息,应用需要重连后通过查询当前状态来继续后续的逻辑。此时数据库只需要保证内部(数据和日志之间,主库和备库之间)一致就可以了。
思考9:sync_binlog和binlog_group_commit_sync_no_delay_count有什么区别?
1)sync_binlog = N:该参数用于binlog持久化策略,每个事务write后就响应客户端了。刷盘是N次事务后刷盘。N次事务之间宕机,数据丢失。
2)binlog_group_commit_sync_no_delay_count = N:该参数用于组提交策略,必须等到N个事务后才能提交。换言之,会增加响应客户端的时间。但是一旦响应了,那么数据就一定持久化了。宕机的话,数据是不会丢失的。该配置先于sync_binlog执行。
思考10:如果sync_binlog = N、binlog_group_commit_sync_no_delay_count = M、binlog_group_commit_sync_delay = 很大值,这种情况下何时刷盘?
答:达到N次以后, 可以刷盘了, 然后再进入(sync_delay和no_delay_count)这个逻辑。Sync_delay如果很大, 就达到no_delay_count才刷。
思考11:redo log buffer是什么? 是先修改内存, 还是先写redo log文件?
在一个事务的更新过程中, 日志是要写多次的。 比如下面这个事务:
begin; insert into t1... insert into t2... commit;
这个事务要往两个表中插入记录, 插入数据的过程中, 生成的日志都得先保存起来, 但又不能在还没commit的时候就直接写到redo log文件里。
所以, redo log buffer就是一块内存, 用来先存redo日志的。 也就是说, 在执行第一个insert的时候, 数据的内存被修改了, redo log buffer也写入了日志。
但是, 真正把日志写到redo log文件(文件名是 ib_logfile+数字) , 是在执行commit语句的时候做的。
思考12:你的生产库设置的是“双1”吗? 如果平时是的话, 你有在什么场景下改成过“非双1”吗? 你的这个操作又是基于什么决定的?
常见需要设置“非双1”场景如下:
1)业务高峰期。 一般如果有预知的高峰期, DBA会有预案, 把主库设置成“非双1”。
2)备库延迟, 为了让备库尽快赶上主库。
3)用备份恢复主库的副本, 应用binlog的过程, 这个跟上一种场景类似。
4)批量导入数据的时候。
一般情况下, 把生产库改成“非双1”配置, 是设置innodb_flush_logs_at_trx_commit=2、sync_binlog=1000。
注:“双1”设置虽然能够减少磁盘IO,但增加了相应时间。

![[NewStarCTF 2023 公开赛道]R!C!E!](https://img-blog.csdnimg.cn/direct/b4d86ef72d234aaaa922d3c0d5ab953d.png)