七. 负载均衡
1. 需求分析
目前我们的RPC框架仅允许消费者读取第一个服务提供者的服务节点,但在实际应用中,同一个服务会有多个服务提供者上传节点信息。如果消费者只读取第一个,势必会增大单个节点的压力,并且也浪费了其它节点资源。
//获取第一个服务节点
ServiceMetaInfo selectedServiceMetaInfo = serviceMetaInfoList.get(0);因此,RPC框架应该允许对服务节点进行选择,而非调用固定的一个。采用负载均衡能够有效解决这个问题。
2. 设计方案
(1)什么是负载均衡
负载,可以理解为要处理的工作和压力,比如网络请求、事务、数据处理任务等。
均衡,就是将工作和压力平均地分配给多个工作者,从而分摊每个工作者的压力。
即将工作负载均匀分配到多个计算资源(如服务器、网络链路、硬盘驱动器等)的技术,以优化资源使用、最大化吞吐量、最小化响应时间和避免过载。
在RPC框架中,负载均衡的作用是从一组可用的服务节点中选择一个进行调用。
(2)常见的负载均衡算法
所谓负载均衡算法,就是按照何种策略选择资源。不同的算法有不同的适用场景,要根据实际情况选择。
- 轮询(Round Robin):按照循环的顺序将请求分配给每个服务器,适用于各服务器性能相近的情况。
//5台服务器节点,请求调用顺序:
1,2,3,4,5,1,2,3,4,5- 随机(Random):随机选择一个服务器处理请求,适用于各服务器性能相近且当前负载均匀的情况。
//5台服务器节点,请求调用顺序:
2,4,1,3,2,5,1,4,4,1- 加权轮询(Weighted Round Robin):根据服务器的性能或权重来分配请求,权重更高的服务器会获得更多的请求,适用于服务器性能不均匀的情况。
//假设有1台千兆带宽的服务器节点和4台百兆带宽的服务器节点,请求调用顺序:
1,1,1,2, 1,1,1,3, 1,1,1,4, 1,1,1,5- 加权随机(Weighted Random):根据服务器的权重随机选择一个处理请求,适用于服务器性能不均匀的情况。
//假设有2台千兆带宽,3台百兆带宽的服务器节点,请求调用顺序:
1,2,2,1,3, 1,1,1,2,4, 2,2,2,1,5- 最小连接数(Least Connections):选择当前连接数最少的服务器处理请求,适用于长连接场景。
- IP Hash:根据客户端IP地址的哈希值选择服务器处理请求,确保同一客户端的请求始终被分配到同一台服务器上,适用于需要保持会话一致性的场景。
另一种比较经典的哈希算法,
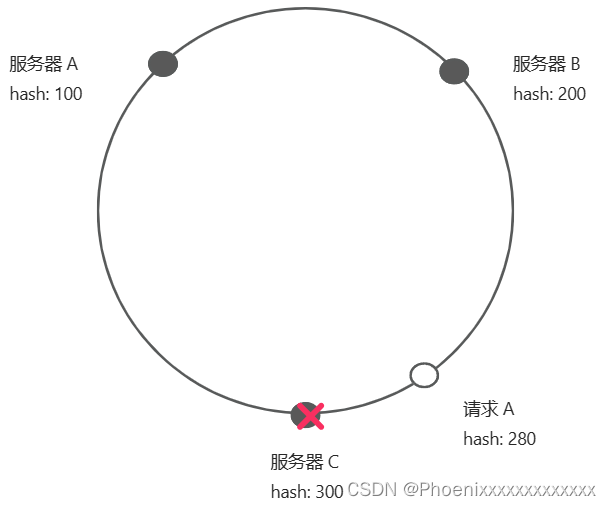
一致性哈希(Consistent Hashing):将整个哈希值空间划分成一个环状结构,每个节点或服务器在环上占据一个位置,每个请求根据其哈希值映射到环上的一个点,然后顺时针寻找第一个遇见的节点,将请求路由到该节点上。
一致性哈希结构图如下图所示,并且请求A会在服务器C进行处理。

此外,一致性哈希还能有效解决节点下线和倾斜问题。
- 节点下线:某个节点下线后,其负载会被平均分摊到其它节点上,不会影响到整个系统的稳定性,只会产生局部变动。
当服务器C下线后,请求A会交由服务器A处理。服务器B接收到的请求不变。
- 倾斜问题:如果服务节点在哈希环上分布不均匀,可能会导致大部分请求全都集中在某一台服务器上,造成数据分布不均匀。通过引入虚拟节点,对每个服务节点计算多个哈希,每个计算结果位置都放置该服务节点,即一个实际物理节点对应多个虚拟节点,使得请求能够被均匀分布,减少节点间的负载差异。

如上图所示节点分布情况,大部分请求都会落在服务器C中,服务器A中的请求会很少。
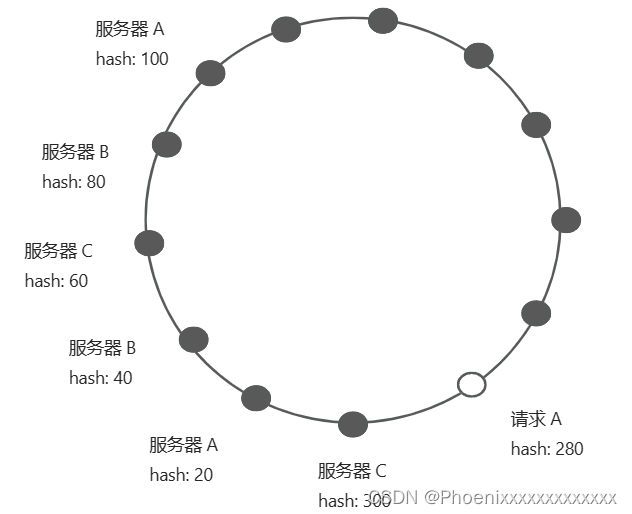
引入虚拟节点后,每个服务器会有多个节点,使得请求分布更加均匀。
3. 具体实现
(1)实现三种负载均衡器
根据轮询、随机和一致性哈希三种负载均衡算法实现对应的负载均衡器。
创建loadbalancer包,将所有负载均衡器相关的代码都放在该包下。
创建LoadBalancer负载均衡器通用接口。
提供一个选择服务方法,接收请求参数和可用服务列表,可以根据这些信息进行选择:
package com.khr.krpc.loadbalancer;
import com.khr.krpc.model.ServiceMetaInfo;
import java.util.List;
import java.util.Map;
/**
* 负载均衡器(消费端使用)
*/
public interface LoadBalancer {
/**
* 选择服务调用
*
* @param requestParams 请求参数
* @param serviceMetaInfoList 可用服务列表
* @return
*/
ServiceMetaInfo select(Map<String,Object> requestParams,List<ServiceMetaInfo>serviceMetaInfoList);
}
实现轮询负载均衡器。
使用到了JUC包的AtomicInteger实现原子计数器,防止并发冲突。
package com.khr.krpc.loadbalancer;
import com.khr.krpc.model.ServiceMetaInfo;
import java.util.List;
import java.util.Map;
import java.util.concurrent.atomic.AtomicInteger;
/**
* 轮询负载均衡器
*/
public class RoundRobinLoadBalancer implements LoadBalancer{
/**
* 当前轮询的下标
*/
private final AtomicInteger currentIndex = new AtomicInteger(0);
@Override
public ServiceMetaInfo select(Map<String,Object> requestParams,List<ServiceMetaInfo> serviceMetaInfoList){
if (serviceMetaInfoList.isEmpty()){
return null;
}
//只有一个服务,无需轮询
int size = serviceMetaInfoList.size();
if (size == 1){
return serviceMetaInfoList.get(0);
}
//取模算法轮询
int index = currentIndex.getAndIncrement() % size;
return serviceMetaInfoList.get(index);
}
}
currentIndex是一个AtomixInteger,它是一个线程安全的整数变量。getAndIncrement() 方法会返回当前值,然后将其递增。例如 currentIndex 当前值是0,那么 getAndIncrement() 会返回0,并将currentIndex设置为1,依次类推。
size是 serviceMetaInfoList 的大小,取模运算大致流程如下:
//假设size=5
第一次调用:currentIndex.getAndIncrement() % 5 -> 0 % 5 = 0 返回服务1。
第二次调用:currentIndex.getAndIncrement() % 5 -> 1 % 5 = 1 返回服务2。
第三次调用:currentIndex.getAndIncrement() % 5 -> 2 % 5 = 2 返回服务3。
第四次调用:currentIndex.getAndIncrement() % 5 -> 3 % 5 = 3 返回服务4。
第五次调用:currentIndex.getAndIncrement() % 5 -> 4 % 5 = 4 返回服务5。
第六次调用:currentIndex.getAndIncrement() % 5 -> 5 % 5 = 0 返回服务1。
(循环开始)
实现随机负载均衡器。
使用Java自带的Random类实现随机选取:
package com.khr.krpc.loadbalancer;
import com.khr.krpc.model.ServiceMetaInfo;
import java.util.List;
import java.util.Map;
import java.util.Random;
/**
* 随机负载均衡器
*/
public class RandomLoadBalancer implements LoadBalancer{
private final Random random = new Random();
@Override
public ServiceMetaInfo select(Map<String,Object> requestParams,List<ServiceMetaInfo> serviceMetaInfoList){
int size = serviceMetaInfoList.size();
if (size == 0){
return null;
}
//只有一个服务,不用随机
if (size == 1){
return serviceMetaInfoList.get(0);
}
return serviceMetaInfoList.get(random.nextInt(size));
}
}
实现一致性哈希负载均衡器。
使用TreeMap实现一致性哈希环,该数据结构提供了 ceilingEntry 和 firstEntry 两个方法,便于获取符合算法要求的节点:
package com.khr.krpc.loadbalancer;
import com.khr.krpc.model.ServiceMetaInfo;
import java.util.List;
import java.util.Map;
import java.util.TreeMap;
/**
* 一致性哈希负载均衡器
*/
public class ConsistentHashLoadBalancer implements LoadBalancer{
/**
* 一致性 Hash 环,存放虚拟节点
*/
private final TreeMap<Integer, ServiceMetaInfo> virtualNodes = new TreeMap<>();
/**
* 虚拟节点数
*/
private static final int VIRTUAL_NODE_NUM = 100;
@Override
public ServiceMetaInfo select(Map<String, Object> requestParams,List<ServiceMetaInfo> serviceMetaInfoList){
if (serviceMetaInfoList.isEmpty()){
return null;
}
//构建虚拟节点
for (ServiceMetaInfo serviceMetaInfo : serviceMetaInfoList){
for (int i = 0; i < VIRTUAL_NODE_NUM; i++){
int hash = getHash(serviceMetaInfo.getServiceAddress() + "#" + i);
virtualNodes.put(hash,serviceMetaInfo);
}
}
//获取调用请求的 hash 值
int hash = getHash(requestParams);
//选择最接近且大于等于调用请求 hash 值的虚拟节点
Map.Entry<Integer,ServiceMetaInfo> entry = virtualNodes.ceilingEntry(hash);
if (entry == null){
//如果没有大于等于调用请求 hash 值的虚拟节点,则返回环首部的节点
entry = virtualNodes.firstEntry();
}
return entry.getValue();
}
/**
* Hash 算法
*
* @param key
* @return
*/
private int getHash(Object key){
return key.hashCode();
}
}
该均衡器给每个服务实例创建100个虚拟节点,并且每个节点的哈希值由其服务地址 getServiceAddress() 和虚拟节点索引 i 组成一个字符串构成。
//某服务1地址为"192.168.0.1":
虚拟节点 0 的哈希值:getHash("192.168.0.1#0")
虚拟节点 1 的哈希值:getHash("192.168.0.1#1")
虚拟节点 2 的哈希值:getHash("192.168.0.1#2")
……
//某服务2地址为"192.168.0.2":
虚拟节点 0 的哈希值:getHash("192.168.0.2#0")
虚拟节点 1 的哈希值:getHash("192.168.0.2#1")
虚拟节点 2 的哈希值:getHash("192.168.0.2#2")
……
依次类推
此外,该一致性哈希均衡器中的 Hash 算法只是简单调用了对象的 hashCode 方法,可以自定义更复杂的哈希算法。
(2)支持配置和扩展负载均衡器
像注册中心和序列化器一样,负载均衡器同样支持自定义,让开发者能够填写配置来指定使用的负载均衡器。依旧使用工厂创建对象、使用SPI动态加载。
在loadbalancer包下创建LoadBalancerKeys类,列举所有支持的负载均衡器键名:
package com.khr.krpc.loadbalancer;
/**
* 负载均衡器键名常量
*/
public interface LoadBalancerKeys {
/**
* 轮询
*/
String ROUND_ROBIN = "roundRobin";
/**
* 随机
*/
String RANDOM = "random";
/**
* 一致性哈希
*/
String CONSISTENT_HASH = "consistentHash";
}
在loadbalancer包下创建LoadBalancerFactory类。
使用工厂模式,支持根据 key 从SPI获取负载均衡器对象实例(和SerializerFactory几乎一致):
package com.khr.krpc.loadbalancer;
import com.khr.krpc.spi.SpiLoader;
/**
* 负载均衡器工厂(工厂模式,用于获取负载均衡器对象)
*/
public class LoadBalancerFactory {
static {
SpiLoader.load(LoadBalancer.class);
}
/**
* 默认负载均衡器
*/
private static final LoadBalancer DEFAULT_LOAD_BALANCER = new RoundRobinLoadBalancer();
/**
* 获取实例
*
* @param key
* @return
*/
public static LoadBalancer getInstance(String key){
return SpiLoader.getInstance(LoadBalancer.class, key);
}
}
在META-INF的rpc/system目录下编写负载均衡器接口的SPI配置文件,文件名称为com.khr.krpc.loadbalancer.LoadBalancer:
roundRobin=com.khr.krpc.loadbalancer.RoundRobinLoadBalancer
random=com.khr.krpc.loadbalancer.RandomLoadBalancer
consistentHash=com.khr.krpc.loadbalancer.ConsistentHashLoadBalancer在RpcConfig类中新增负载均衡器全局配置:
package com.khr.krpc.config;
import com.khr.krpc.loadbalancer.LoadBalancerKeys;
import com.khr.krpc.serializer.SerializerKeys;
import lombok.Data;
/**
* RPC框架配置
*/
@Data
public class RpcConfig {
……
/**
* 负载均衡器
*/
private String loadBalancer = LoadBalancerKeys.ROUND_ROBIN;
}
(3)应用负载均衡器
修改ServiceProxy类中针对服务节点调用的代码,改为调用负载均衡器获取节点:
//负载均衡器
LoadBalancer loadBalancer = LoadBalancerFactory.getInstance(rpcConfig.getLoadBalancer());
//将调用方法名(请求路径)作为负载均衡参数
Map<String, Object> requestParams = new HashMap<>();
requestParams.put("methodName", rpcRequest.getMethodName());
ServiceMetaInfo selectedServiceMetaInfo = loadBalancer.select(requestParams,serviceMetaInfoList);4. 测试
(1)测试负载均衡算法
编写单元测试类LoadBalancerTest:
package com.khr.rpc.loadbalancer;
import com.khr.krpc.loadbalancer.ConsistentHashLoadBalancer;
import com.khr.krpc.loadbalancer.LoadBalancer;
import com.khr.krpc.loadbalancer.RandomLoadBalancer;
import com.khr.krpc.loadbalancer.RoundRobinLoadBalancer;
import com.khr.krpc.model.ServiceMetaInfo;
import org.junit.Assert;
import org.junit.Test;
import java.util.Arrays;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
import static org.junit.Assert.*;
/**
* 负载均衡器测试
*/
public class LoadBalancerTest {
final LoadBalancer loadBalancer = new RandomLoadBalancer();
@Test
public void select(){
//请求参数
Map<String, Object> requestParams = new HashMap<>();
requestParams.put("methodName","apple");
//服务列表
ServiceMetaInfo serviceMetaInfo1 = new ServiceMetaInfo();
serviceMetaInfo1.setServiceName("MyService");
serviceMetaInfo1.setServiceVersion("1.0");
serviceMetaInfo1.setServiceHost("localhost");
serviceMetaInfo1.setServicePort(1234);
ServiceMetaInfo serviceMetaInfo2 = new ServiceMetaInfo();
serviceMetaInfo2.setServiceName("MyService");
serviceMetaInfo2.setServiceVersion("1.0");
serviceMetaInfo2.setServiceHost("khr.icu");
serviceMetaInfo2.setServicePort(80);
List<ServiceMetaInfo> serviceMetaInfoList = Arrays.asList(serviceMetaInfo1,serviceMetaInfo2);
//连续调用3次
ServiceMetaInfo serviceMetaInfo = loadBalancer.select(requestParams,serviceMetaInfoList);
System.out.println(serviceMetaInfo);
Assert.assertNotNull(serviceMetaInfo);
serviceMetaInfo = loadBalancer.select(requestParams,serviceMetaInfoList);
System.out.println(serviceMetaInfo);
Assert.assertNotNull(serviceMetaInfo);
serviceMetaInfo = loadBalancer.select(requestParams,serviceMetaInfoList);
System.out.println(serviceMetaInfo);
Assert.assertNotNull(serviceMetaInfo);
}
}
替换loadBalancer对象为不同的负载均衡器,有不同的运行结果:
Random

RoundRobin
 Consistent Hashing
Consistent Hashing

(2)测试负载均衡调用
在不同的端口启动两个服务提供者,然后启动消费者,通过Debug或控制台输出来观察每次请求的节点地址即可。这里不再做详细演示。
至此,扩展功能,负载均衡完成。
八. 重试机制
1. 需求分析
目前的RPC框架中,如果消费者调用接口失败,就会直接报错。
// rpc请求
RpcResponse rpcResponse = VertxTcpClient.doRequest(rpcRequest, selectedServiceMetaInfo);
return rpcResponse.getData();
} catch (Exception e) {
throw new RuntimeException("调用失败");
}调用接口失败可能是因为网络问题,也可能是服务提供者的问题。这种情况下,我们更希望消费者拥有自动重试的能力,提高系统可用性。
2. 设计方案
(1)什么是重试机制
当调用方发起的请求失败时,RPC框架可以进行自动重试,重新发送请求,用户可以设置是否开启重试机制以及重试次数等。
调用方或消费者发起RPC调用时,会通过负载均衡器选择一个合适的节点发送请求。如果请求失败或收到异常信息,就可以捕获异常并触发重试机制,即重新通过负载均衡器选择节点发送请求,同时记录重试的次数,当达到用户设置的最大次数限制后,抛出异常给消费者,否则一直重试。
(2)为什么需要重试机制
- 提高系统可用性可靠性:当远程服务调用失败,重试机制可以让系统自动重新发送请求,保证接口的调用执行。
- 有效处理临时性错误:重试机制能够有效缓解如网络延迟、连接异常等临时性错误的影响,提高调用成功率。
- 降低调用端复杂性:重试机制将捕获异常并触发重试的逻辑封装在框架内部,无需手动操作。
(3)重试算法
固定间隔重试(Fixed Interval Retry):
- 每次重试间隔一个固定时间,如 1 秒。
- 适用于对响应时间要求不严格的场景。
指数退避重试(Exponential Backoff Retry):
- 每次重试间隔的时间呈指数增长,如 1 秒、2 秒、4 秒、8 秒等。
- 适用于网络波动较大的场景,避免短时间内发送大量重复请求。
随机延迟重试(Random Delay Retry):
- 每次重试的时间间隔随机,在一定范围内波动。
- 适用于避免重试请求同步的场景,比如防止雪崩效应。
可变延迟重试(Variable Delay Retry):
- 根据先前重试的成功或失败情况,动态调整下一次重试的延迟时间。
不重试(No Retry):
- 直接返回失败结果,不重试。
- 适用于对响应时间要求较高的场景。
这些算法或策略可以组合使用,应当根据具体的业务场景灵活调整。比如可以先使用指数退避重试。如果连续多次重试失败,则切换到固定间隔重试策略。
(4)重试条件
即什么时候或者什么条件下触发重试。
考虑到提高系统可用性,当发生网络波动或其它异常情况时,触发重试。
(5)停止重试
通常情况下,重试是有次数限制的,不能无限制重试,否则会造成雪崩。
主流的停止重试策略:
- 最大尝试次数:重试达到最大次数后不再重试。
- 超时停止:重试达到最大时间后不再重试。
(6)重试工作
通常重试就是执行原本要做的操作,比如重新发送请求。
但如果重试达到上限,也需要进行一些其它操作,如:
- 通知告警:通知开发者人工介入。
- 降级容错:改为调用其它接口或执行其它操作。
3. 具体实现
(1)2 种重试策略实现
创建 fault.retry 包,将所有重试相关的代码都放到该包下。
创建 RetryStrategy 重试策略通用接口。
提供一个重试方法,接收一个具体的任务参数,使用 Callable 类代表一个任务:
package com.khr.krpc.fault.retry;
import com.khr.krpc.model.RpcResponse;
import java.util.concurrent.Callable;
/**
* 重试策略
*/
public interface RetryStrategy {
/**
* 重试
*
* @param callable
* @return
* @throws Exception
*/
RpcResponse doRetry(Callable<RpcResponse> callable) throws Exception;
}
引入 Guava-Retrying 重试库,使用该库能够轻松实现多种不同的重试算法:
<dependency>
<groupId>com.github.rholder</groupId>
<artifactId>guava-retrying</artifactId>
<version>2.0.0</version>
</dependency>不重试策略
即直接执行一次任务:
package com.khr.krpc.fault.retry;
import com.khr.krpc.model.RpcResponse;
import lombok.extern.slf4j.Slf4j;
import java.util.concurrent.Callable;
/**
* 重试策略 —— 不重试
*/
@Slf4j
public class NoRetryStrategy implements RetryStrategy{
/**
* 重试
*
* @param callable
* @return
* @throws Exception
*/
public RpcResponse doRetry(Callable<RpcResponse> callable) throws Exception {
return callable.call();
}
}
固定间隔重试策略
使用 Guave-Retrying 提供的 RetryerBuilder 能够轻松指定重试条件、重试等待策略、重试停止策略、重试工作等:
package com.khr.krpc.fault.retry;
import com.github.rholder.retry.*;
import com.khr.krpc.model.RpcResponse;
import lombok.extern.slf4j.Slf4j;
import java.util.concurrent.Callable;
import java.util.concurrent.ExecutionException;
import java.util.concurrent.TimeUnit;
/**
* 重试策略 —— 固定时间间隔
*/
@Slf4j
public class FixedIntervalRetryStrategy implements RetryStrategy {
/**
* 重试
*
* @param callable
* @return
* @throws ExecutionException
* @throws RetryException
*/
public RpcResponse doRetry(Callable<RpcResponse> callable) throws ExecutionException, RetryException{
Retryer<RpcResponse> retryer = RetryerBuilder.<RpcResponse>newBuilder()
.retryIfExceptionOfType(Exception.class)
.withWaitStrategy(WaitStrategies.fixedWait(3L,TimeUnit.SECONDS))
.withStopStrategy(StopStrategies.stopAfterAttempt(3))
.withRetryListener(new RetryListener() {
@Override
public <V> void onRetry(Attempt<V> attempt) {
log.info("重试次数 {}", attempt.getAttemptNumber());
}
})
.build();
return retryer.call(callable);
}
}
- retryIfExceptionOfType 方法指定重试条件,出现 Exception 异常时触发重试。
- withWaitStrategy 方法指定重试策略,选择 fixedWait 固定时间间隔策略。
- withStopStrategy 方法指定停止重试策略,选择 stopAfterAttempt 超过最大重试次数停止。
- withRetryListener 方法监听重试,每次重试时记录当前次数。
(2)支持配置和扩展重试策略
和序列化器、注册中心、负载均衡器一样,重试策略本身也可以使用SPI + 工厂设计模式,从而允许开发者动态配置和扩展自定义重试策略。
在 fault.retry 包下创建 RetryStrategyKeys 类,列举所有支持的重试策略键名:
package com.khr.krpc.fault.retry;
/**
* 重试策略键名常量
*/
public interface RetryStrategyKeys {
/**
* 不重试
*/
String NO = "no";
/**
* 固定时间间隔
*/
String FIXED_INTERVAL = "fixedInterval";
}
创建 RetryStrategyFactory 类,使用工厂模式,支持根据 key 从SPI获取重试策略对象实例:
package com.khr.krpc.fault.retry;
import com.khr.krpc.spi.SpiLoader;
/**
* 重试策略工厂(用于获取重试器对象)
*/
public class RetryStrategyFactory {
static {
SpiLoader.load(RetryStrategy.class);
}
/**
* 默认重试器
*/
private static final RetryStrategy DEFAULT_RETRY_STRATEGY = new NoRetryStrategy();
/**
* 获取实例
*
* @pram key
* @return
*/
public static RetryStrategy getInstance(String key) {
return SpiLoader.getInstance(RetryStrategy.class, key);
}
}
在META-INF的 rpc/system 目录下创建重试策略接口的SPI配置文件,名称为com.khr.krpc.fault.retry.RetryStrategy:
no=com.khr.krpc.fault.retry.NoRetryStrategy
fixedInterval=com.khr.krpc.fault.retry.FixedIntervalRetryStrategy在 RpcConfig 类中增加重试策略的全局配置:
package com.khr.krpc.config;
import com.khr.krpc.fault.retry.RetryStrategy;
import com.khr.krpc.fault.retry.RetryStrategyKeys;
import com.khr.krpc.loadbalancer.LoadBalancerKeys;
import com.khr.krpc.serializer.SerializerKeys;
import lombok.Data;
/**
* RPC框架配置
*/
@Data
public class RpcConfig {
……
/**
* 负载均衡器
*/
private String loadBalancer = LoadBalancerKeys.ROUND_ROBIN;
/**
* 重试策略
*/
private String retryStrategy = RetryStrategyKeys.NO;
}
(3)应用重试功能
修改 ServiceProxy 中请求失败部分的逻辑,先从工厂中获取重试器,然后将VertxTcpClient.doRequest 封装为一个可重试的任务,一个 Callable接口。并将请求失败作为重试条件,触发重试机制,系统自动执行重试。
//发送 TCP 请求
//使用重试机制
RetryStrategy retryStrategy = RetryStrategyFactory.getInstance(rpcConfig.getRetryStrategy());
RpcResponse rpcResponse = retryStrategy.doRetry(() ->
VertxTcpClient.doRequest(rpcRequest, selectedServiceMetaInfo)
); //使用 Lambda 表达式将 VertxTcpClient.doRequest 封装为一个匿名函数
return rpcResponse.getData();
} catch (IOException e){
throw new RuntimeException("调用失败");
}4. 测试
启动服务提供者后,使用Debug模模式启动消费者,当消费者发起调用时,立刻停止服务提供者,能看到调用失败后重试的情况。
至此,扩展功能,重试机制完成。