第一章 绪论
1.1机器学习的定义,什么是机器学习?
1)机器学习是这样一门学科,它致力于研究如何通过计算的手段,利用经验来改善系统自身的性能。
2)机器学习所研究的主要内容是关于在计算机上从数据中产生模型的算法,即“学习算法”。
1.2基本术语

数据相关概念:
- 数据集(data set):记录的集合;
- 示例(instance)/样本(sample):关于一个事件或对象的描述;注意一个示例也称为一个特征向量(因为一个示例是属性空间中的一个坐标向量)
- 属性(attribute)/特征(feature):反映事件或对象在某方面的表现或性质的事项
- 属性值(attribute value):属性上的取值
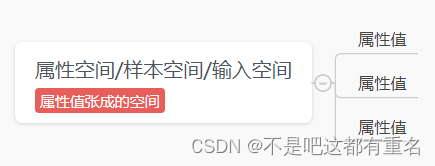
- 属性空间(attribute space)/样本空间(sample space):属性张成的空间
- 训练数据(training data):训练过程中使用的数据。
- 训练样本(training sample):训练数据中的每个样本称为一个训练样本。
- 训练集(training set):训练样本组成的集合;
- 标记(label):关于示例的结果的信息
- 样例(sample):拥有了标记信息的示例。
- 测试(testing):使用模型进行预测的过程称为测试。
- 测试样本(testing sample):被预测的样本。
- 假设(hypothesis):学得的模型对应了关于数据的某种潜在的规律。假设是对数据的某种规律或模式的假定。它是我们希望通过模型来捕捉和表达的数据内在规律。
- 真相/真实(ground-truth):潜在规律本身。
学习任务相关概念:
- 监督学习(supervised learning):训练数据有标记信息的任务,典型代表,分类和回归任务。
- 无监督学习(unsupervised learning):训练数据无标记信息的任务,典型代表,聚类。
- 分类(classification):预测值为离散值的学习任务。
- 回归(regression):预测值为连续值得学习任务。
- 二分类任务(binary classification):只涉及两个类别的分类任务,通常称一个类别为正类(positive class),另一个类别为反类(negative class)。
- 多分类任务(multi-class classification):涉及多个类别的分类任务。
- 聚类(clustering):将训练集中的样本分为若干组。分成的组称为族(cluster)。
模型相关概念
- 泛化(generalization):学得模型适用于新样本的能力。
1.3 假设空间和版本空间
再来回顾一下假设的概念:
- 假设(hypothesis):学得的模型对应了关于数据的某种潜在的规律。假设是对数据的某种规律或模式的假定。它是我们希望通过模型来捕捉和表达的数据内在规律。
可以理解,在机器学习中,假设是关于数据规律的,但通常通过模型来表示和实现这些假设。
假设空间 (Hypothesis Space)
假设空间是指所有可能假设的集合。这些假设是用来拟合数据、进行预测或解释数据模式的函数或模型。
版本空间 (Version Space)
版本空间是指在给定训练数据的条件下,所有与训练数据一致的假设的集合。换句话说,版本空间是从假设空间中筛选出的能够正确分类或预测训练数据的假设子集。
假设空间和版本空间的关系
假设空间:表示所有可能的假设集合,是整个搜索范围。
版本空间:表示所有与训练数据一致的假设集合,是在假设空间中的一个子集。
Tips:
事实上,假设空间既可以用假设的集合表示,也可以用模型表示。这两种表示方法其实是互通的,因为特定类型的模型就是我们对数据规律的假设,而所有可能的模型实例构成了假设空间。
1.4 理解归纳偏好
- 归纳偏好(inductive bias):机器学习算法在学习过程中对某种类型假设的偏好。
第二章 模型评估与选择
2.1经验误差与过拟合
- 错误率(error rate):分类错误的样本数占样本总数的比例;
- 精度(accuracy):1-错误率;
- 误差 (error):学习器的实际预测输出与样本的正式输出之间的差异;(更加一般的一个概念,错误率也是一种误差,在回归任务中错误率不适合表示误差还有其他的误差表示)。
- 训练误差/经验误差(training error/empirical error):学习器在训练集上的误差;
- 泛化误差(generalization error):在新样本上的误差。训练模型的目的是得到理想化的最小泛化误差的模型。
- 过拟合(overfitting):把训练样本自身的一些特点当作了所有潜在样本都具有的一般性质,导致泛化性能的下降。
- 欠拟合(underfitting):对训练样本的一般性质尚未充分学习。
2.2 评估方法
为了评估不同的模型的泛化性能,找到最小泛化误差的模型,我们需要用到测试集。
(1)测试集:用来测试学习器对新样本的判别能力,以测试集上的测试误差作为泛化误差的近似。
(2)测试集的选取标准:测试样本是从样本真实分布中独立同分布采样而得的,同时,测试集应该尽可能与训练集互斥,即测试样本尽量不在训练集中出现、未在训练过程中使用过。
如何从数据集中产生训练集和测试集?以下是常用的几种方法:
1.留出法(hold out):直接将数据集划分为两个互斥的集合,一个集合作为训练集,一个集合作为测试集。
注意,训练/测试的划分要尽可能的保持数据分布的一致性,避免因数据划分过程引入额外的偏差而对最终结果产生影响。同时即使给定划分比例,仍然存在多种划分方式,而不同的划分将导致不同的训练/测试集,模型的评估结果也会有差异,因此得到的结果往往不够稳定可靠,常常需要若干次随机划分后取平均值。
2.交叉验证法(cross validation):先将数据集D划分为k个大小相似的互斥子集,每个子集都尽可能保持数据分布的一致性(通过分层采样得到),然后每次用k-1个子集的并集作为训练集,剩下的一个作为测试集。最终返回的k个测试结果的均值。同样由于划分方式的不同,通常要随机使用不同的划分方式重复p次,最终的结果是这p次k折交叉验证结果的均值。
特殊情况: 当数据集包含m个样本,令k=m,则得到了交叉验证法的一个特例:留一法(Leave-One-Out)。
优点: 留一法的评估结果往往被认为比较准确;
缺点: 数据集较大时,训练m个模型的计算开销难以忍受。
3.自助法(bootstrapping):对于给定的包含m个样本的数据集D,对它进行采样得到数据集D’,每次随机从D中放回式的挑选一个样本放入D‘中,重复该过程m次,得到包含有m个样本的数据集D’。显然,D中有一部分样本会在D‘中多次出现,而另一部分样本不出现。约有38.6%(1/e)的样本未出现在采样数据集D’中。
优点:在数据集小,难以有效划分时很有用,对集成学习等方法有好处;
缺点:改变了初始数据集的分布,引入了估计偏差,在数据集足够时,一般不用。
2.3 性能度量
模型的好坏是相对的,不仅取决于算法和数据,还取决于任务需求。因此就需要有衡量模型泛化能力的评价标准,也就是性能度量(performance measure)。
回归任务常见的性能度量:
-
均方误差(mean squared error):
E ( f ; D ) = 1 m ∑ i = 1 m ( f ( x i ) − y i ) 2 E(f;D) = \frac{1}{m}\sum\limits_{i=1}^m(f(x_i)-y_i)^2 E(f;D)=m1i=1∑m(f(xi)−yi)2 -
错误率:分类错误的样本数占样本总数的比例
E ( f , D ) = 1 m ∑ i = 1 m I ( f ( x i ) ≠ y i ) E(f,D)=\frac{1}{m}\sum\limits_{i=1}^m\mathbb I (f(x_i)\neq{y_i}) E(f,D)=m1i=1∑mI(f(xi)=yi)
-
精度:分类正确的样本数占样本总数的比例.
a c c ( f , D ) = 1 m ∑ i = 1 m I ( f ( x i ) = y i ) = 1 − E ( f , D ) acc(f,D)=\frac{1}{m}\sum\limits_{i=1}^m\mathbb I (f(x_i)={y_i}) =1-E(f,D) acc(f,D)=m1i=1∑mI(f(xi)=yi)=1−E(f,D)
-
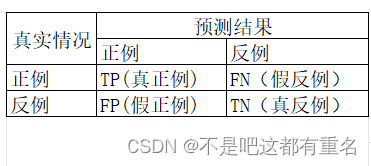
查准率/准确率(precision):它衡量的是模型预测的正类样本中有多少是正确的
P = T P T P + F P P=\frac{TP}{TP+FP} P=TP+FPTP -
查全率/召回率(recall):它衡量的是实际的正类样本中有多少被正确地预测为正类
R = T P T P + F N R=\frac{TP}{TP+FN} R=TP+FNTP -
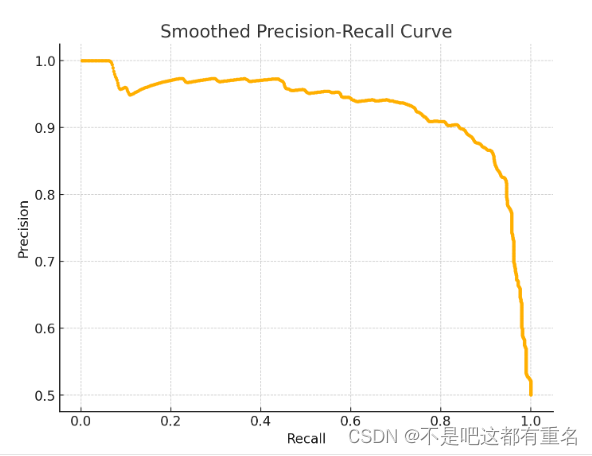
P-R曲线:P-R曲线是通过绘制不同阈值下精度和召回率的变化关系得到的。通常,曲线的横轴表示召回率,纵轴表示精度。
P-R曲线的绘制步骤:
1)模型预测: 对于给定的分类模型,使用不同的阈值对数据进行预测。每个阈值会产生一组不同的精度和召回率。
2)计算精度和召回率: 对每个阈值,计算对应的精度和召回率。
3)绘制曲线: 以召回率为横轴,精度为纵轴,绘制精度-召回曲线。
-
F1度量:
F 1 = 2 ∗ P ∗ R P + R F1=\frac{2*P*R}{P+R} F1=P+R2∗P∗R
一般形式:(能表达出对查准率/查全率的不同偏好)
F β = ( 1 + β 2 ) ∗ P ∗ R ( β 2 ∗ P ) + R F_\beta=\frac{(1+\beta^2)*P*R}{(\beta ^2*P)+R} Fβ=(β2∗P)+R(1+β2)∗P∗R
其中 β \beta β>0度量了查全率对查准率的相对重要性。 β = 1 \beta=1 β=1时退化为标准的F1; β > 1 \beta>1 β>1时查全率有更大影响; β < 1 \beta<1 β<1时查准率有更大影响。
宏F1(macro-F1):
微F1(micro-F1):
参考文献
[1]周志华.机器学习[M].清华大学出版社,2016.
[2]https://www.bilibili.com/video/BV1Mh411e7VU/?p=2&vd_source=0e750184037a989618cbfa3e8e030c7d