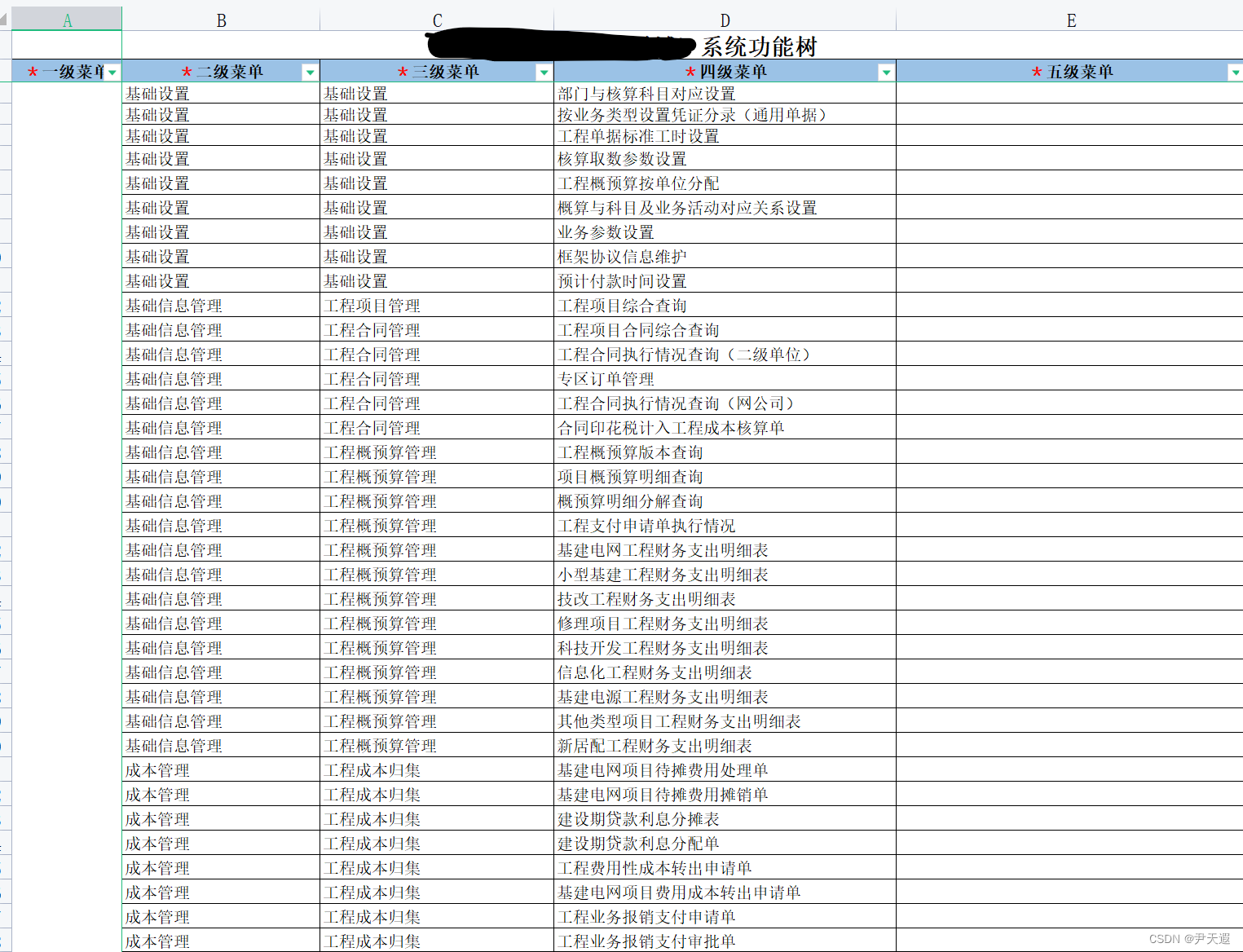
今天读的是发表在CVPR2022上的无监督MVS文章,作者来自于国防科大。
文章链接:RayMVSNet
项目地址:Github
Abstract
作者希望直接优化每个camera ray上的深度值,所以提出这个RayMVSNet来学习1D implicit field的序列预测。使用了传统MVS里的方法进行极线搜索和transformer提取特征,并且使用了mutli-task learning。
1 Introduction
贡献主要是:
- 一个新颖的表现形式,来学习1D隐式场。
- epipolar transformer来学习特征。
- mutli-task learning来建模和预测,并且基于LSTM。
- 效果好。
2 Related Work
介绍了基于深度学习的MVS和implicit的表征。
3 Method

3.1 3D Cost Volume and Coarse Depth Prediction
Build a variance-based 3D cost volume and get coarse depth map.
3.2 Epipolar Transformer
Goal is to estimate the location of the zero-crossing point on each ray, so we can obtainthe depth map of reference image.
Why ray-based?
- depth map is view-dependent. So optimization is more straightforward and lightweight.
- all the 1D implicit fields share an identical spatial property, i.e. the monotonicity of the SDFs along the ray direction.
Zero-crossing hypothesis sampling
adopt coarse depth map and uniformly sample K K K points P = { p k } 1 K P=\{p_k\}_{1}^{K} P={pk}1K on the ray in the range of ± δ \pm \delta ±δ.
Epipolar transformer
Use 4 self-attention layers, each followed by 2 AddNorm and 1 feed-forward layer.


3.3 Ray-based 1D Implicit Field
Given the features of the hypothesized points, the ray-based 1D implicit fields are learned with an LSTM. Crucially, we leverage two attributes of LSTM.
- The mechanism of sequential processing inherently facilitates the learning of the SDF monotonicity along the ray direction.
- The property of time invariance increases the network robustness by allowing the zero-crossing position to appear at any place (time-step) on the ray.

3.4 Implementations
4 Results and Evaluation








![[linux] 系统的基本使用](https://img-blog.csdnimg.cn/direct/0a70bd16dec04b5493d80de80b351d0e.png)