目录
1. CLIP
2. ALBEF
3. BLIP
4. BLIP2
参考文献
(2023年)视觉+语言的多模态大模型的目前主流方法是:借助预训练好的LLM和图像编码器,用一个图文特征对齐模块来连接,从而让语言模型理解图像特征并进行深层次的问答推理。
这样可以利用已有的大量单模态训练数据训练得到的单模态模型,减少对于高质量图文对数据的依赖,并通过特征对齐、指令微调等方式打通两个模态的表征。下图来自其他 up 的概括内容,来自:https://zhuanlan.zhihu.com/p/653902791
对于CLIP部分公式均参照该链接,仅了解损失函数。

图 基础MLLM的架构整理
1. CLIP
分别对图像、文本进行特征提取,两部分的backbone可以分别采用Resnet系列模型/VIT系列模型、BERT模型。特征提取后,直接相乘计算余弦相似度,然后采用对比损失(info-nce-loss)。
训练损失
- 交叉熵代价损失(cross entropy):基础有监督学习分类损失函数。

图 n个类别多分类的交叉熵代价函数
- NCE(noise contrastive estimation):相比于交叉熵损失,这里将多问题转化为二分类问题,即正样本和噪声样本,目标学习正样本和噪声样本之间的差异。

图 噪声对比
- info-NCE:NCE的变体,将噪声样本按多类别看待。存在一个temp的温度系数。
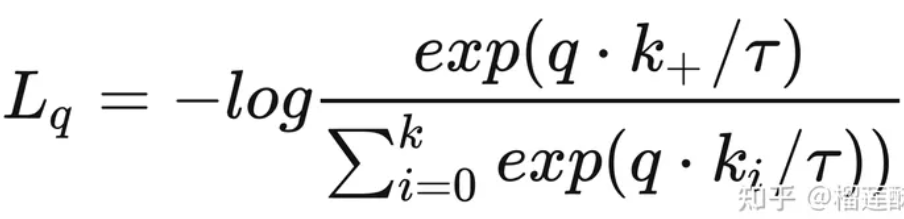
图 info-NCE loss
2. ALBEF
动机:该项工作之前的视觉预训练模型一般采用Object Detector的方式,这种Detector能够提取图像上的目标或边界信息。然而这种训练方式有如下几点限制:
- 图像特征和文本编码token分别处于各子的特征空间,这使得多模态关联性挖掘存在巨大挑战;
- 这种训练方式会产生额外的解释开销和计算开销;
- 对于物体目标含量低的样本,模型性能受限于Detector的检测精度;
- 图像文本样本数据一般来源于网络,具有严重的噪声影响,会导致模型性能降级。
ALBEF模型架构:如图所示,ALBEF模型架构分为image encoder 、text encoder 和多模态编码器,其中左半部分类似Transformer,text encoder将12层分为两部分,前6层作为text encoder,后6层作为视觉特征和文本特征的融合。由于视觉和文本的编码都包含[CLS]标签,这种标签因自注意力机制的影响被认为包含全局信息,所以可以将视觉和文本的全局信息进行 Image-Text Contrastive Loss。

图 ALBEF架构图
如图ITM部分,该部分称为图像文本匹配(Image-Text matching),该部分利用的负样本采用 hard negatives 的方式进行生成,即通过ITC(iamge-text Contrastive)计算出的次分类结果,该结果能够作为模型难以理解的样本,进而计算损失。
除此之外,由于动机中描述的网络图文样本对的噪声影响,ALBEF设计一个Momentum Model(动量模型)解决上述问题。简要描述该组件的作用,即类似知识蒸馏方法,拷贝出原始模型的动量版本,通过动量模型对原始模型规约,加深原始模型和动量模型间的图文对匹配程度,进而消除原始样本数据中的噪声干扰。
3. BLIP
动机:从模型的角度,当前预训练模型的任务涵盖范围受限。例如,基于Encoder的模型无法做生成任务,而基于Encoder-Decoder的模型无法做检索任务,不能更充分的理解任务信息。从数据的角度,网络图文对具有严重的数据噪声。
BLIP模型架构:BLIP全称Bootstrapped Language-Image Pre-training,该模型包括三个下游任务:图像文本对比学习、图像文本匹配和语言建模(LM,该任务类似GPT,给定段落前一段话,预测后一段;而不是BERT那种完型填空的方式)。

图 BLIT模型架构
- Bootstrapped机制:采用一种迭代的、自我改进的学习过程来提升模型性能,该机制有助于提高模型在跨模态任务中的对齐和理解能力。(1)初始模型训练阶段:首先使用大量的单模态数据(如图像/文本)对文本编码器和图像编码器进行预训练(如图中的 Image Encoder 和 Text Encoder)。然后利用多模态数据,即图文对数据,对初始模型进行训练;(2)迭代更新阶段:采用Captioning and Filtering的方式,从网页噪声图像文本对中学习,训练BLIP。
- image-text contrastive(图像文本对比):和ALBEF类似,利用[CLS]信息进行对比学习。
- Image-grounded Text Encoder(图像文本匹配编码器):采用一种 Cross Attention 模块,将图像信息融入文本编码过程中,增强文本的上下文表示,进而理解图像的相关描述。
- Image-grounded Text Decoder(图像关联文本解码器):将原来的 Bi Self-Attention 替换为 Causal Self-Attention(用于预测下一个token),该解码器用于文本生成或多模态推理任务。
- soft lables:是指标签值在[0,1]之间的概率值,而不是离散的0或1,反映样本属于某一个类的置信度。有助于平滑标签分布,提高模型的泛化能力,减少过拟合。
- Hard Negative Mining Strategy:在训练过程中,专门选择那些模型难以区分的负样本,以增强模型的判别能力。
如何消除网络样本噪声的影响:BLIP采用 Filter-Captioner 的方式,如图所示,通过生成+过滤的方式生成更匹配图像的Caption,进而完善样本集。具体而言,对于给定的训练集,包含网络文本
、人工正确标注文本
,由于前文有 ITC、ITM 和 LM 损失,因此在部分利用这些指标训练 Filter(grounded Encoder)和 Captioner(grounded Decoder),Captioner会生成文本数据
,将
和
交由 Filter 微调更加匹配图像的文本信息,最终获得信息匹配程度更紧密的样本集。

图 Filter-Captioner机制
4. BLIP2
动机:回顾之前的研究,无论是视觉预训练模型还是语言预训练模型,其规模都是庞大的,这种模型架构会产生巨额开销。
BLIP2架构:BLIP2全称Bootstrapping Language-Image Pre-training with Frozen Image Encoders and Large Language Models,视图将视觉预训练模型和语言预训练模型参数均进行冻结。然而,这会导致视觉特征和文本特征都处于各自的特征空间,存在巨大的 modality gap。因此BLIP2中采用 Q-Former(Query Transformer) 的一种轻量级Transformer技术,该技术用于弥补视觉和语言两种模态的 modality gap,选取最匹配的视觉特征给后续LLM生成文本。
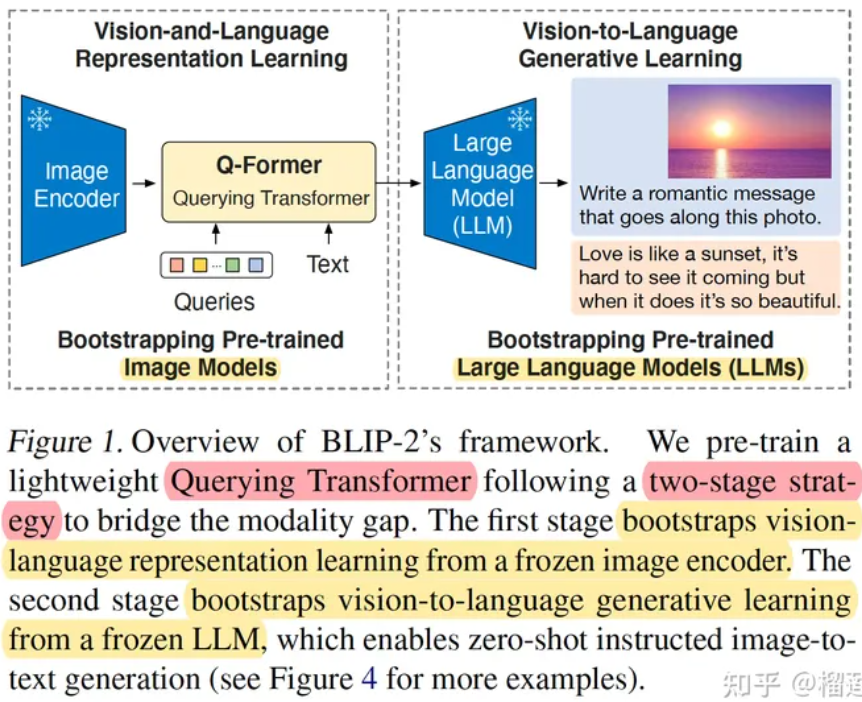
图 BLIP2的模型架构
Q-Former是一个可学习的组件,学习的参数包括若干queries,这些queries最终从 image encoder中提取固定数量的视觉特征,学习与文本更匹配的视觉特征。
queries间的彼此交互通过共享自注意力层,和冻结的图像特征交互使用的跨模态注意力机制层,然后queries也能通过共享自注意力层与文本特征进行交互。整个Q-Former由Image Transformer和Text Transformer两个子模块构成,它们共享相同自注意力层。
- Image Transformer:通过和image encoder交互来提取视觉特征,输入是一系列(文中用的32个*768长度)可学习的 Queries,这些Query通过自注意力层相互交互,并通过交叉注意力层与冻结的图像特征交互,还可以通过共享的自注意力层与文本进行交互;输出的query尺寸是32*768,远小于冻结的图像特征257*1024(ViT-L/14)。
- Text Transformer:既作为文本编码器也作为文本解码器,它的自注意力层与Image Transformer共享,根据预训练任务,用不同的self-attention masks来控制Query和文本的交互方式。
参考文献
多模态大模型 CLIP, BLIP, BLIP2, LLaVA, miniGPT4, InstructBLIP 系列解读
BLIP2的前世与今生
ALBEF原文
BLIP原文
BLIP2原文