CIC-DDoS2019
对CIC-DDoS2019数据集进行检测,本文提供了如下内容:
- 数据清洗与合并
- 机器学习模型
- 深度学习模型
- PCA,t-SNE分析
- 数据,结果可视化
代码地址:[daetz-coder](https://github.com/daetz-coder/CIC-DDoS2019-Detection)
1、数据集加载
选择的数据集是这里的csv文件CIC-DDoS2019 (kaggle.com)
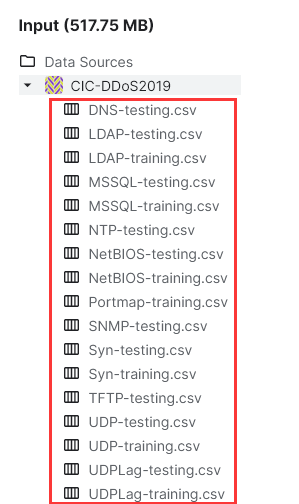
链接:https://pan.baidu.com/s/1gP86I08ZQhAOgcfCd5OVVw?pwd=2019
提取码:2019
2、数据分割
import os
import pandas as pd
# 设置包含CSV文件的目录
directory = 'class_split' # 替换为您的目录路径
# 列出目录下所有的CSV文件
csv_files = [f for f in os.listdir(directory) if f.endswith('.csv')]
# 读取每个CSV文件并打印行数
for csv_file in csv_files:
file_path = os.path.join(directory, csv_file)
try:
# 读取CSV文件
data = pd.read_csv(file_path)
# 获取行数
num_rows = len(data)
print(f"{csv_file}: {num_rows} 行")
except Exception as e:
print(f"无法读取 {csv_file}: {e}")
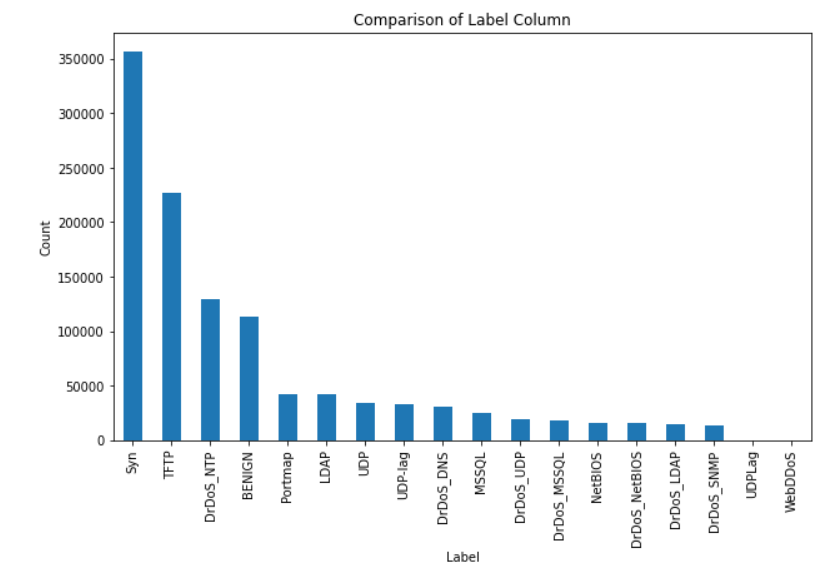

3、数据可视化
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
# 加载数据
file_path = './class_split/WebDDoS.csv'
data = pd.read_csv(file_path)
# 设置绘图样式
sns.set(style="whitegrid")
# 创建一个图形框架
fig, axes = plt.subplots(nrows=1, ncols=2, figsize=(16, 6))
# 散点图:流持续时间与前向数据包数量
sns.scatterplot(ax=axes[0], x=data[' Flow Duration'], y=data[' Total Fwd Packets'], color='blue')
axes[0].set_title('Flow Duration vs Total Fwd Packets')
axes[0].set_xlabel('Flow Duration')
axes[0].set_ylabel('Total Fwd Packets')
# 箱线图:前向和后向数据包的分布
sns.boxplot(data=data[[' Total Fwd Packets', ' Total Backward Packets']], ax=axes[1])
axes[1].set_title('Distribution of Packet Counts')
axes[1].set_ylabel('Packet Counts')
plt.tight_layout()
plt.show()

import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
import numpy as np
# 加载数据
file_path = './class_split/WebDDoS.csv'
data = pd.read_csv(file_path)
# 将时间列转换为 datetime 类型
data[' Timestamp'] = pd.to_datetime(data[' Timestamp'])
# 筛选出数值型数据列
numeric_data = data.select_dtypes(include=[np.number])
# 设置绘图样式
sns.set(style="whitegrid")
# 创建图形框架,一行两列
fig, axes = plt.subplots(nrows=1, ncols=2, figsize=(16, 6))
# 时间序列分析:数据包数量随时间的变化
data.sort_values(' Timestamp', inplace=True)
data['Packet Count'] = data[' Total Fwd Packets'] + data[' Total Backward Packets']
data.plot(x=' Timestamp', y='Packet Count', ax=axes[0], title='Packet Count Over Time')
# 热图:特征间的相关性
correlation_matrix = numeric_data.corr()
sns.heatmap(correlation_matrix, ax=axes[1])
axes[1].set_title('Feature Correlation Heatmap')
plt.tight_layout()
plt.show()

import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
# 加载数据
file_path = './class_split/WebDDoS.csv'
data = pd.read_csv(file_path)
# 设置绘图样式
sns.set(style="whitegrid")
# 创建图形框架,一行两列
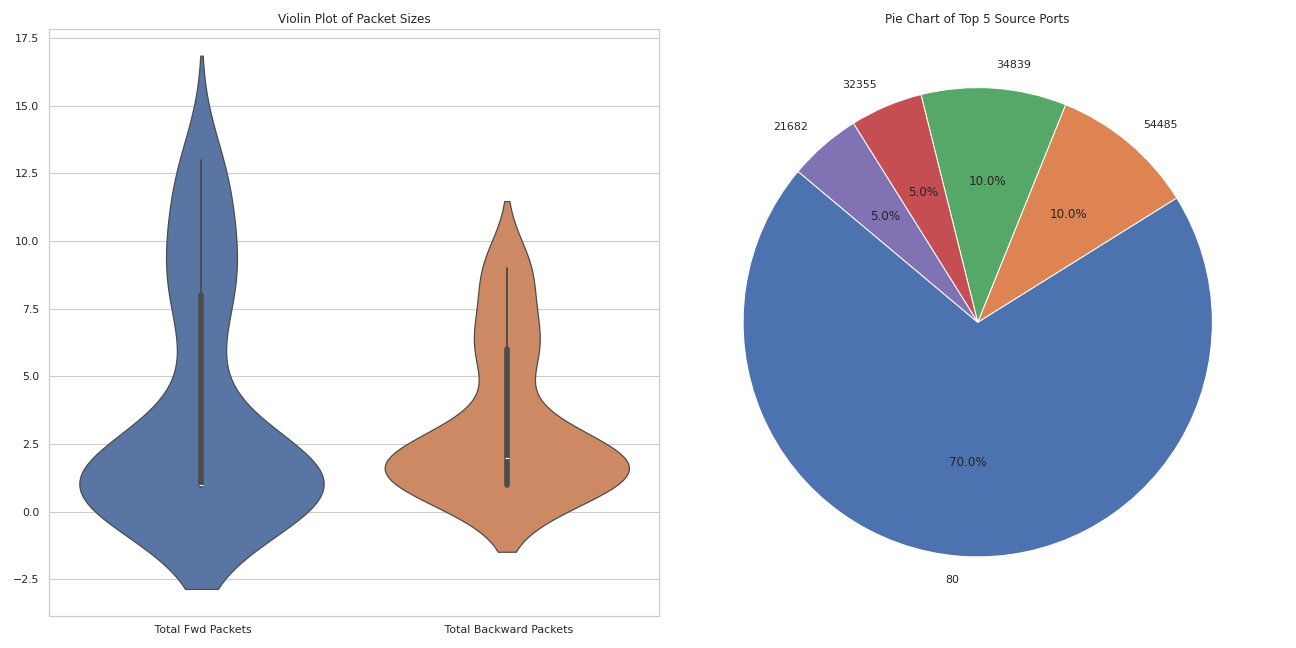
fig, axes = plt.subplots(nrows=1, ncols=2, figsize=(18, 9))
# 小提琴图:前向包大小与反向包大小
sns.violinplot(data=data[[' Total Fwd Packets', ' Total Backward Packets']], ax=axes[0])
axes[0].set_title('Violin Plot of Packet Sizes')
# 选择源端口和目的端口的频率最高的前5个端口
top_src_ports = data[' Source Port'].value_counts().nlargest(5)
top_dst_ports = data[' Destination Port'].value_counts().nlargest(5)
# 圆饼图:显示源端口的计数
axes[1].pie(top_src_ports, labels=top_src_ports.index, autopct='%1.1f%%', startangle=140)
axes[1].set_title('Pie Chart of Top 5 Source Ports')
plt.tight_layout()
plt.show()
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
import numpy as np
# 加载数据
file_path = './class_split/WebDDoS.csv'
data = pd.read_csv(file_path)
# 数据清洗,处理可能的无穷大或不合理的值
data['Flow Bytes/s'] = pd.to_numeric(data['Flow Bytes/s'], errors='coerce').replace([np.inf, -np.inf], np.nan).fillna(0)
# 选择几个数值变量进行分析
selected_columns = [' Flow Duration', ' Total Fwd Packets', ' Total Backward Packets', 'Flow Bytes/s']
selected_data = data[selected_columns]
# 设置绘图样式
sns.set(style="whitegrid")
# 创建对角线分布图
pair_plot = sns.pairplot(selected_data)
pair_plot.fig.suptitle("Pair Plot of Selected Features", y=1.02) # 添加总标题并调整位置
plt.savefig("pair_plot.png")
plt.show()
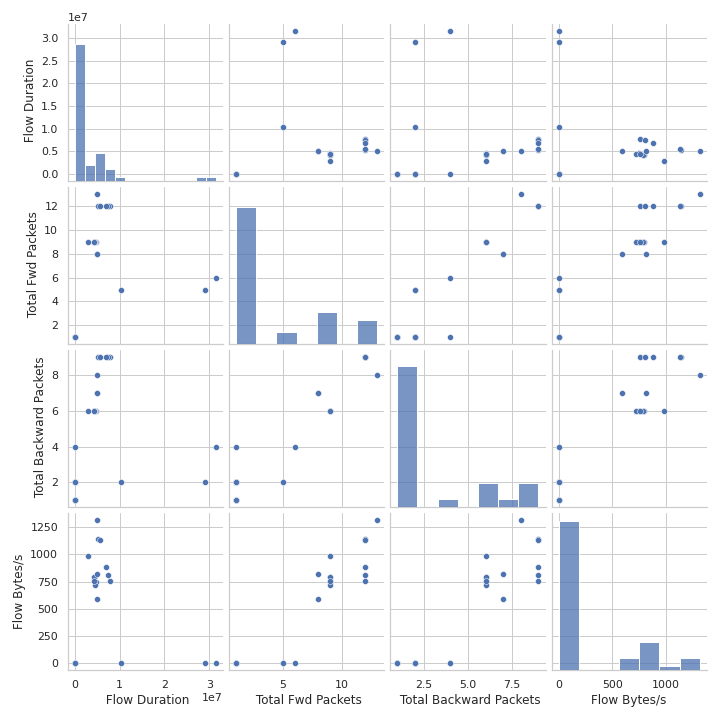
4、数据合并
import pandas as pd
import os
# 文件目录
directory = './class_split/'
# 文件列表
files = [
'BENIGN.csv', 'DrDoS_DNS.csv', 'DrDoS_LDAP.csv', 'DrDoS_MSSQL.csv',
'DrDoS_NTP.csv', 'DrDoS_NetBIOS.csv', 'DrDoS_SNMP.csv', 'DrDoS_UDP.csv',
'LDAP.csv', 'MSSQL.csv', 'NetBIOS.csv', 'Portmap.csv',
'Syn.csv', 'TFTP.csv', 'UDP.csv', 'UDP-lag.csv'
]
# 创建空的DataFrame
combined_data = pd.DataFrame()
# 对每个文件进行处理
for file in files:
file_path = os.path.join(directory, file)
# 加载数据
data = pd.read_csv(file_path)
# 随机选取500条数据
sample_data = data.sample(n=500, random_state=1)
# 将数据加入到总的DataFrame中
combined_data = pd.concat([combined_data, sample_data], ignore_index=True)
# 保存到新的CSV文件
combined_data.to_csv('./combined_data.csv', index=False)
print("数据合并完成,已保存到combined_data.csv")
对于每一种类型都选择500个样本combined_data.csv
【注:本文提供的csv可满足简单的训练,如果需要更多的数据,可以下载官方数据】
5、机器学习
Logistic
# 训练逻辑回归模型
logreg.fit(X_train, y_train)
y_pred_logreg = logreg.predict(X_test)
print("Logistic Regression Accuracy: {:.2f}%".format(accuracy_score(y_test, y_pred_logreg) * 100))
Random Forest
# 训练随机森林模型
rf.fit(X_train, y_train)
y_pred_rf = rf.predict(X_test)
print("Random Forest Accuracy: {:.2f}%".format(accuracy_score(y_test, y_pred_rf) * 100))
SVM
# 训练支持向量机模型
svm.fit(X_train, y_train)
y_pred_svm = svm.predict(X_test)
print("SVM Accuracy: {:.2f}%".format(accuracy_score(y_test, y_pred_svm) * 100))
XGBoost
# 训练XGBoost模型
xgb.fit(X_train, y_train)
y_pred_xgb = xgb.predict(X_test)
print("XGBoost Accuracy: {:.2f}%".format(accuracy_score(y_test, y_pred_xgb) * 100))
# 打印分类报告(以XGBoost为例)
print("\nClassification Report for XGBoost:")
print(classification_report(y_test, y_pred_xgb))
from sklearn.linear_model import LogisticRegression
from sklearn.ensemble import RandomForestClassifier
from sklearn.svm import SVC
from xgboost import XGBClassifier
from sklearn.metrics import accuracy_score, classification_report
# 初始化模型
logreg = LogisticRegression(max_iter=1000)
rf = RandomForestClassifier(n_estimators=100)
svm = SVC()
xgb = XGBClassifier(use_label_encoder=False, eval_metric='mlogloss')
# 训练逻辑回归模型
logreg.fit(X_train, y_train)
y_pred_logreg = logreg.predict(X_test)
print("Logistic Regression Accuracy: {:.2f}%".format(accuracy_score(y_test, y_pred_logreg) * 100))
# 训练随机森林模型
rf.fit(X_train, y_train)
y_pred_rf = rf.predict(X_test)
print("Random Forest Accuracy: {:.2f}%".format(accuracy_score(y_test, y_pred_rf) * 100))
# 训练支持向量机模型
svm.fit(X_train, y_train)
y_pred_svm = svm.predict(X_test)
print("SVM Accuracy: {:.2f}%".format(accuracy_score(y_test, y_pred_svm) * 100))
# 训练XGBoost模型
xgb.fit(X_train, y_train)
y_pred_xgb = xgb.predict(X_test)
print("XGBoost Accuracy: {:.2f}%".format(accuracy_score(y_test, y_pred_xgb) * 100))
# 打印分类报告(以XGBoost为例)
print("\nClassification Report for XGBoost:")
print(classification_report(y_test, y_pred_xgb))
Logistic Regression Accuracy: 54.96%
Random Forest Accuracy: 62.04%
SVM Accuracy: 50.17%
XGBoost Accuracy: 62.75%
Classification Report for XGBoost:
precision recall f1-score support
0 0.99 0.99 0.99 170
1 0.50 0.42 0.45 143
2 0.31 0.25 0.28 174
3 0.56 0.52 0.54 159
4 0.99 0.99 0.99 145
5 0.45 0.42 0.43 146
6 0.60 0.65 0.63 148
7 0.46 0.55 0.50 121
8 0.36 0.46 0.40 144
9 0.54 0.56 0.55 156
10 0.38 0.40 0.39 154
11 0.40 0.44 0.42 146
12 0.99 0.98 0.99 150
13 1.00 0.97 0.99 158
14 0.51 0.49 0.50 130
15 0.92 0.90 0.91 156
accuracy 0.63 2400
macro avg 0.62 0.62 0.62 2400
weighted avg 0.63 0.63 0.63 2400
from sklearn.metrics import confusion_matrix
import seaborn as sns
from sklearn.linear_model import LogisticRegression
from sklearn.ensemble import RandomForestClassifier
from sklearn.svm import SVC
from xgboost import XGBClassifier
from sklearn.metrics import accuracy_score, classification_report
import matplotlib.pyplot as plt
# 初始化模型
logreg = LogisticRegression(max_iter=1000)
rf = RandomForestClassifier(n_estimators=100)
svm = SVC()
# 训练模型
logreg.fit(X_train, y_train)
rf.fit(X_train, y_train)
svm.fit(X_train, y_train)
# 预测结果
y_pred_logreg = logreg.predict(X_test)
y_pred_rf = rf.predict(X_test)
y_pred_svm = svm.predict(X_test)
# 混淆矩阵
cm_logreg = confusion_matrix(y_test, y_pred_logreg)
cm_rf = confusion_matrix(y_test, y_pred_rf)
cm_svm = confusion_matrix(y_test, y_pred_svm)
# 绘制混淆矩阵的热图
fig, axes = plt.subplots(nrows=1, ncols=3, figsize=(18, 6))
sns.heatmap(cm_logreg, annot=True, fmt="d", ax=axes[0], cmap='Blues')
axes[0].set_title('Logistic Regression Confusion Matrix')
axes[0].set_xlabel('Predicted labels')
axes[0].set_ylabel('True labels')
sns.heatmap(cm_rf, annot=True, fmt="d", ax=axes[1], cmap='Blues')
axes[1].set_title('Random Forest Confusion Matrix')
axes[1].set_xlabel('Predicted labels')
axes[1].set_ylabel('True labels')
sns.heatmap(cm_svm, annot=True, fmt="d", ax=axes[2], cmap='Blues')
axes[2].set_title('SVM Confusion Matrix')
axes[2].set_xlabel('Predicted labels')
axes[2].set_ylabel('True labels')
plt.tight_layout()
plt.savefig("confusion.png")
plt.show()

6、PCA t-SNE
from sklearn.decomposition import PCA
from sklearn.manifold import TSNE
import matplotlib.pyplot as plt
import pandas as pd
from sklearn.preprocessing import StandardScaler, LabelEncoder
from sklearn.model_selection import train_test_split
import numpy as np
# 加载数据
data = pd.read_csv('./combined_data.csv')
# 删除不需要的列,例如时间戳或IP地址(假设你的数据集中有这些列)
data.drop([' Timestamp'], axis=1, inplace=True)
# 类型转换,将分类标签编码
label_encoder = LabelEncoder()
data[' Label'] = label_encoder.fit_transform(data[' Label'])
# 检查并处理无穷大和非常大的数值
data.replace([np.inf, -np.inf], np.nan, inplace=True) # 将inf替换为NaN
data.fillna(data.median(), inplace=True) # 使用中位数填充NaN,确保之前中位数计算不包括inf
# 特征标准化
scaler = StandardScaler()
X = scaler.fit_transform(data.drop(' Label', axis=1)) # 确保标签列不参与标准化
y = data[' Label']
# PCA
pca = PCA(n_components=2)
X_pca = pca.fit_transform(X)
# t-SNE
tsne = TSNE(n_components=2, random_state=42)
X_tsne = tsne.fit_transform(X)
# 可视化 PCA
plt.figure(figsize=(8, 8))
plt.scatter(X_pca[:, 0], X_pca[:, 1], c=y, cmap='viridis', alpha=0.5)
plt.title('PCA of Dataset')
plt.xlabel('Principal Component 1')
plt.ylabel('Principal Component 2')
plt.colorbar()
plt.show()
# 可视化 t-SNE
plt.figure(figsize=(8, 8))
plt.scatter(X_tsne[:, 0], X_tsne[:, 1], c=y, cmap='viridis', alpha=0.5)
plt.title('t-SNE of Dataset')
plt.xlabel('t-SNE Feature 1')
plt.ylabel('t-SNE Feature 2')
plt.colorbar()
plt.show()
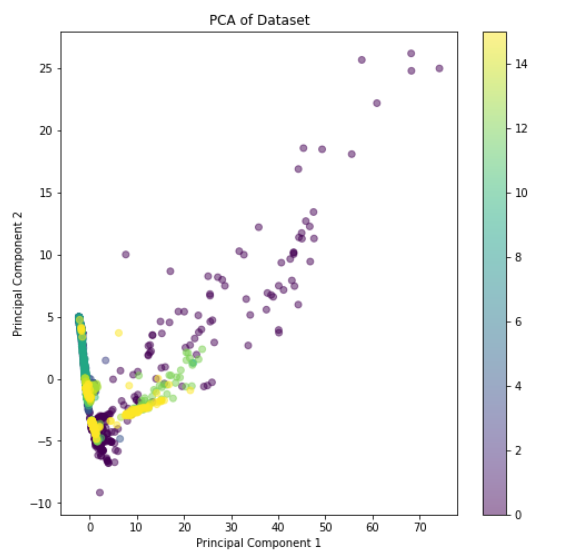
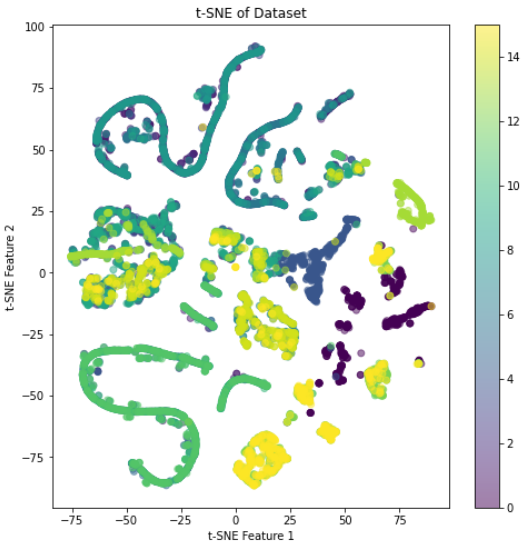
7、深度学习
MLP
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import DataLoader, TensorDataset
# 定义模型
class NeuralNetwork(nn.Module):
def __init__(self, input_size, num_classes):
super(NeuralNetwork, self).__init__()
self.layer1 = nn.Linear(input_size, 64)
self.relu = nn.ReLU()
self.layer2 = nn.Linear(64, 64)
self.output_layer = nn.Linear(64, num_classes)
def forward(self, x):
x = self.relu(self.layer1(x))
x = self.relu(self.layer2(x))
x = self.output_layer(x)
return x
# 初始化模型
input_size = X_train.shape[1]
num_classes = len(np.unique(y))
model = NeuralNetwork(input_size, num_classes)
# 损失函数和优化器
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=0.001)
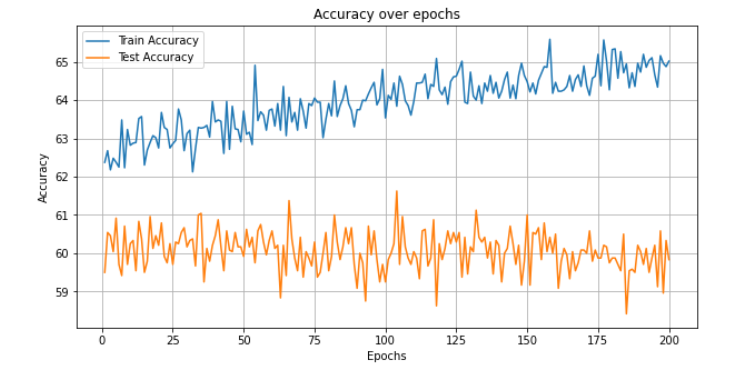
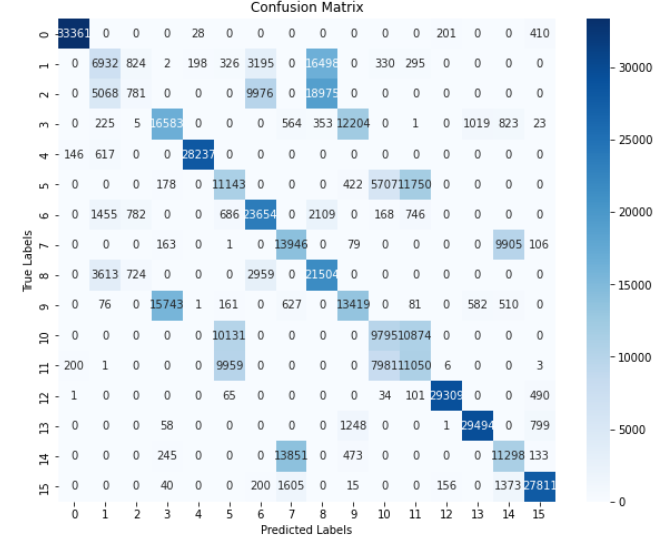
CNN
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import DataLoader, TensorDataset
# 定义模型
class CNN(nn.Module):
def __init__(self, input_size, num_classes):
super(CNN, self).__init__()
self.conv1 = nn.Conv1d(1, 16, kernel_size=3, stride=1, padding=1)
self.relu = nn.ReLU()
self.pool = nn.MaxPool1d(kernel_size=2, stride=2)
self.conv2 = nn.Conv1d(16, 32, kernel_size=3, stride=1, padding=1)
# 计算池化后的尺寸
conv1_out_size = (input_size + 2 * 1 - 3) / 1 + 1 # Conv1
pool1_out_size = conv1_out_size / 2 # Pool1
conv2_out_size = (pool1_out_size + 2 * 1 - 3) / 1 + 1 # Conv2
pool2_out_size = conv2_out_size / 2 # Pool2
final_size = int(pool2_out_size) * 32 # conv2 的输出通道数 * 输出长度
self.fc = nn.Linear(final_size, num_classes)
def forward(self, x):
x = x.unsqueeze(1) # Adding a channel dimension
x = self.relu(self.conv1(x))
x = self.pool(x)
x = self.relu(self.conv2(x))
x = self.pool(x)
x = torch.flatten(x, 1)
x = self.fc(x)
return x
# 初始化模型
input_size = X_train.shape[1]
num_classes = len(np.unique(y))
model = CNN(input_size,num_classes)
# 损失函数和优化器
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=0.001)
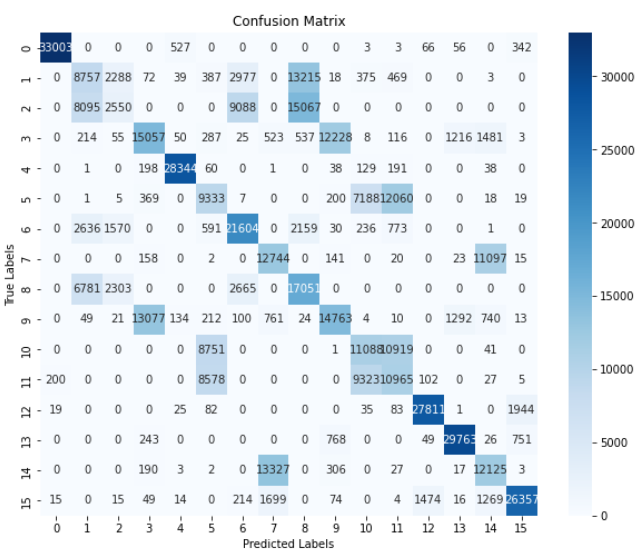





![[Qt的学习日常]--常用控件3](https://img-blog.csdnimg.cn/direct/ea9bc34104da484dbfc5cc28f22be9db.png)