1、引言
论文链接:ReadPaper
现在最先进的计算机视觉系统都是训练模型来预测一组固定的、预定义好的目标类别(如 ImageNet 的 1000 类和 COCO 的 80 类)。这种受限制的监督形式限制了它们的通用性和可用性,因为需要额外的标记数据和训练来指定任何其他视觉概念(新类别)。直接从有关图像的原始文本中学习是一种很有前途的替代方案,它利用了更广泛的监督来源。Alec Radford[1] 等证明了预测哪个 caption 与哪个图像是配对的这样一个简单预训练任务是在从互联网收集的 4 亿个图像-文本对数据集 WIT(WebImageText)[1] 上从头学习 SOTA(State of the Art) 图像表示的一个有效且可扩展的方法。预训练之后,自然语言引导模型去做物体分类,分类不局限于已经学到的视觉概念,还能扩展到新的类别,即这个模型是能够直接在下游任务上做 zero-shot 推理。这种方法被称为 CLIP(Contrastive Language-Image Pre-training)[1],在涵盖 OCR,视频动作识别、geo-localization 和许多细粒度的分类的 30 多个数据集上进行测试来评估其性能,发现 CLIP 能轻松地迁移到大多数任务,并且能达到和有监督的 baseline 方法差不多的性能,而无需任何数据集特定的训练。例如在 ImageNet 上,CLIP 在不使用那 1.28 M 训练样本的情况下,就能得到和有监督的 ResNet-50 差不多的结果[1]。
2、方法
2.1 预训练
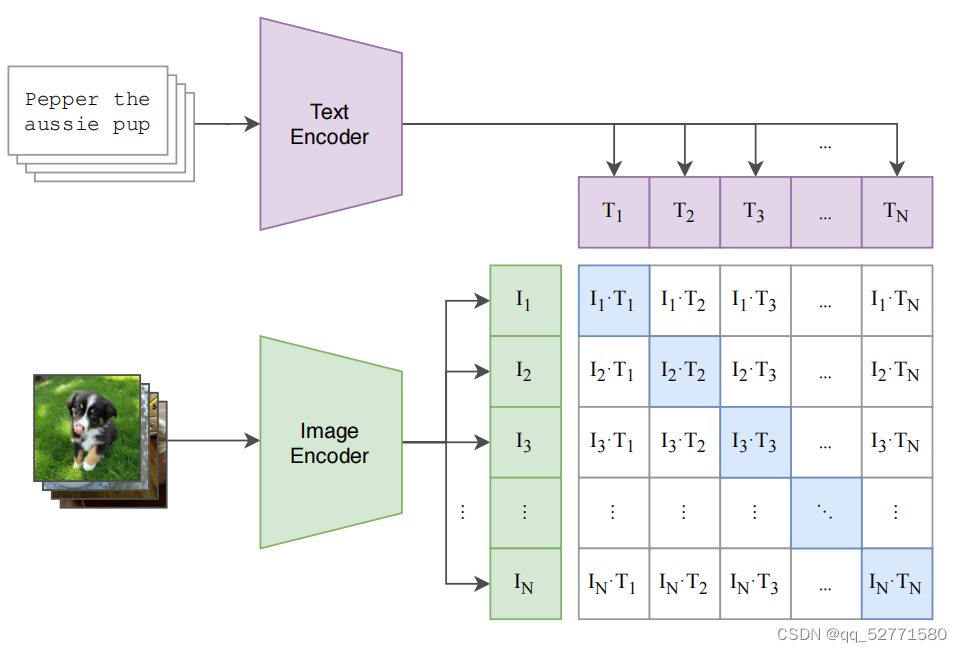
图1 对比预训练
如图 1 所示,CLIP 的训练数据是图像-文本对。假设每个训练 batch 里有 N 个图片-文本对,N 个图片输入到 Image Encoder 得到 N 个图片特征向量(I1、I2、I3、...、IN),N 个文本输入到 Text Encoder 得到 N 个文本特征向量(T1、T2、T3、...、TN),将图片特征向量和文本特征向量投影到相同的模态(维度)后,N 个图片特征向量和 N 个文本特征向量两两计算余弦相似度(两个向量夹角的余弦值,即先 L2 归一化再求点积)得到 N*N 的相似度矩阵。对比学习非常灵活,只需要正样本和负样本的定义,即配对的图片-文本对就是正样本,否则为负样本,特征矩阵里对角线上的都是正样本,其它元素都是负样本,即共 N 个正样本, N(N−1) 个负样本,有了正负样本,模型就可以通过对比学习的方式去训练了,不需要任何手工标注。这种无监督的训练方式需要大量训练数据。

图2 Numpy矩阵形式的CLIP伪代码
CLIP Numpy 矩阵形式的伪代码如图 2 所示, Image Encoder 输入的 shape 是 [n, h, w, c],Text Encoder 输入的 shape 是 [n, l],其中 n=batch_size,h、w、c 分别为图片的高、宽和通道数,l 是指序列长度。Image Encoder 是 ResNet/Vision Transformer,Text Encoder 是 CBOW/Text Transformer,Image Encoder 输出 n 个图片特征向量(shape=[n, d_i]),Text Encoder 输出 n 个文本特征向量(shape 为 [n, d_t] )。然后将图片特征向量和文本特征向量投影到相同的维度 d_e(模态)后 L2 归一化,再让 n 个图片特征向量和 n 个文本特征向量两两计算内积得到 shape=[n, n] 的相似度矩阵,相似度矩阵乘以一个温度系数 t(对数初始化)后便得到缩放的相似度矩阵 logits。根据上述正负样本的定义 labels 是 np.arange(n),分别计算图片-文本的交叉墒损失 loss_i(把图片看作样本,文本看作标签),和文本-图片的交叉墒损失 loss_t(把文本看作样本,图片看作标签),最终 loss 为 loss_i 和 loss_t 的均值。之所以 labels 是 np.arange(n) 是因为不管把图片看作样本还是把文本看作样本,样本和标签都是配对的,即第 0 个样本的标签一定是 0,第 1 个样本的标签是一定 1,...,第 n 个样本的标签一定是 n,从而使训练目标是使 logits 对角线上的元素尽量接近 1,其它元素尽量接近 0,即正确配对图片和文本。
2.2 Zero-Shot Transfer
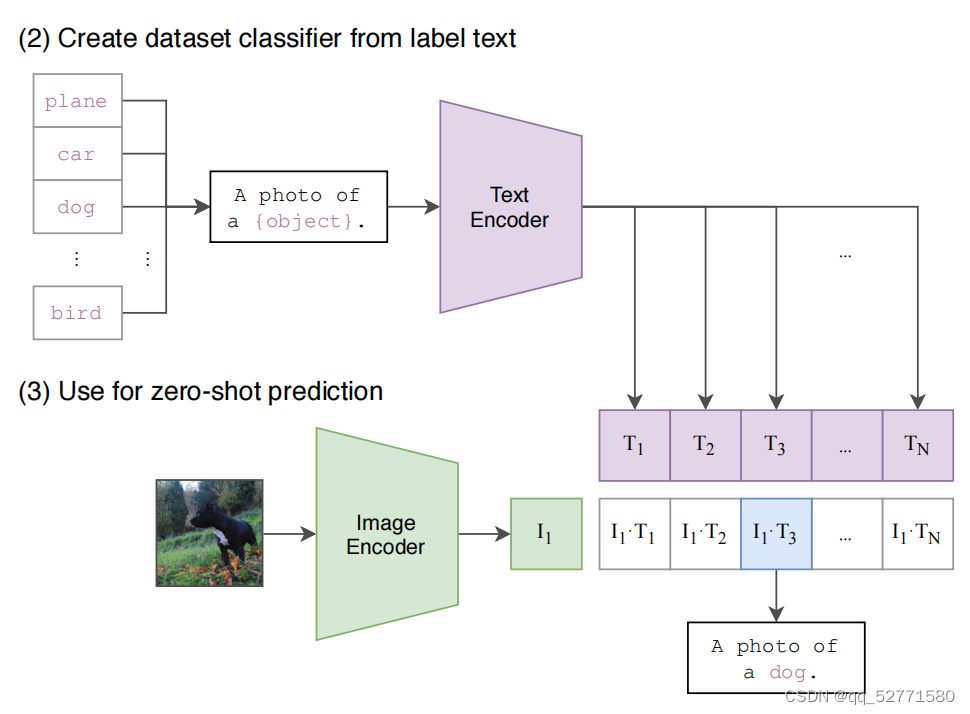
图3 CLIP实现zero-shot分类
CLIP 在 WIT 上预训练后,如图 3 所示只需 2 步就能实现 zero-shot 分类:
(1)从标签文本中构建数据集分类器:根据下游任务的分类标签构建每个类别的描述文本,例如 A photo of a {object},然后将这些文本送入 Text Encoder 得到对应的文本特征向量,如果类别数目为 N,那么将得到 N 个文本特征向量(T1、T2、T3、...、TN)。
(2)使用数据集分类器进行 zero-shot 预测:将要预测的图像送入 Image Encoder 得到图像特征向量 I1,所有向量投影到相同模态后计算 I1 与 N 个文本特征向量缩放的余弦相似度(和训练过程一致),然后选择相似度最大的文本对应的类别作为图像分类预测结果,可以进一步将这些相似度看成 logits,送入 softmax 后可以得到每个类别的预测概率。
如图 3 所示,利用 CLIP 的多模态特性为具体的任务构建了动态的分类器,其中 Text Encoder 提取的文本特征可以看成分类器(一个全连接层)的权重,而 Image Encoder 提取的图像特征是分类器的输入。
2.3 Prompt Engineering and Ensembling
如果在做文本和图片匹配的时候,每次只用标签对应的词(组)来做文本的特征提取,就有可能遇到一词多义问题,即因缺乏上下文信息使模型无法区分是哪个词义,比如在 ImageNet 里面同时包含两个类,construction cranes 和 cranes,在不同的语境下,这两个 cranes 对应的意义是不一样的,在建筑工地环境下,construction cranes 指起重机,作为动物,cranes 指的是鹤。同时在预训练时匹配的文本一般都是一个句子,很少出现一个单词的情况,如果推理时文本输入只是一个词(组),可能就存在 distribution gap 的问题,提取出来的特征可能不好。
基于这两个问题,作者提出使用提示模版(ImageNet 上使用“A photo of a {label}.”)把单词变成一个句子以缓解 distribution gap,且能一定程度上解决歧义性的问题。比如 remote 这个单词在模版中就是指遥控器,而不是遥远的。使用提示模板之后,CLIP 在 ImageNet 上的准确率提升了 1.3%[1]。
作者还尝试集成多个 zero shot 分类器,即 prompt ensembling ,作为提高性能的另一种方式。这些分类器是在不同的上下文提示下得到的,作者在 ImageNet 上共集成了 80 个不同的提示模版,在只使用一个提示模版的基础上进一步提高了 3.5% 的准确率[1]。
2.4 Representation Learning
[1] 中还进行了 representation Learning 实验,即自监督学习中常用的 linear probe:用预训练好的模型先提取特征,然后有监督训练一个线性分类器。发现 CLIP 在性能上超过其它模型,而且计算更高效。
3、总结
[1] 中还发现 CLIP 在自然分布漂移上表现得更鲁棒;人类从几个样本中学习的方式和 [1] 中的few-shot 方法之间存在很大差异,并推测找到一种将先验知识正确集成到 few-shot 学习中的方法是对 CLIP 算法改进的重要一步;采用一个重复检测器对训练集和测试集的重合率做了检测,发现重合率的中位数为 2.2%、平均值为 3.2%,去重前后在大部分数据集上的性能没有太大变化[1]。
CLIP 的局限性如下所示:
(1)CLIP 的 zero-shot 性能虽然和有监督的 ResNet50 相当,但仍远低于 SOTA,作者估计要达到 SOTA 的效果,还需要增加 1000 倍的计算量,目前而言没有可行性,有必要进一步研究如何提高 CLIP 的计算效率和数据效率。
(2)CLIP 的 zero-shot 性能在某些数据集上表现较差,如细粒度分类,抽象任务等。
(3)CLIP 在自然分布漂移上表现鲁棒,但是依然存在域外泛化问题。
(4)尽管 CLIP 可以灵活地为各种任务和数据集生成零样本分类器,但 CLIP 仍然仅限于从给定的零样本分类器中选择这些概念。与可以生成新颖输出的图像 captioning 等真正灵活的方法相比,这是一个重大限制。值得尝试的想法有:联合训练对比目标和生成目标;在推理时对给定图像的多个自然语言解释执行搜索。
(5)CLIP 并没有解决深度学习的数据效率低下难题,将 CLIP 与 self-supervision[2,3] 和 self- training[4] 方法相结合是一个很有前途的方向,因为它们具有比标准监督学习更高数据效率。
(6)尽管 CLIP 专注于 zero-shot 迁移,但作者反复查询完整验证集的性能以指导 CLIP 的开发。这些验证集通常有数千个示例,这对于真正的 zero-shot 场景是不现实的。 CLIP 的主要结果使用了 27 个数据集的一些随意组装集合,这些数据集不可否认地与 CLIP 的开发和功能共同适应。创建一个新的任务基准以明确评估广泛的零样本迁移能力,而不是重复使用现有的监督数据集,将有助于解决这些问题。
(7)CLIP 在从互联网收集的图像-文本对数据集上进行训练。这些图像-文本对未经过滤和整理,导致 CLIP 学习了许多社会偏见。
(8)人类从几个样本中学习的方式和 [1] 中的 few-shot 方法之间存在很大差异。未来的工作需要开发将 CLIP 的强 zero-shot 性能与高效的 few-shot 学习相结合的方法。
作者研究了是否能将 NLP(Natural Language Processing) 中与任务无关的 web 规模预训练的成功转移到另一个领域,发现采用这个套路会导致计算机视觉领域出现类似的行为;并讨论了这一研究方向的社会影响。为了优化他们的训练目标,CLIP 模型在预训练期间学会执行各种各样的任务。然后可以通过自然语言提示来利用此任务学习,以实现对许多现有数据集的 zero-shot 迁移。在足够的规模上,这种方法的性能可以媲美特定于任务的监督模型,尽管仍有很大的改进空间。
从本质上来讲,CLIP 其实并没有太大的创新,它只是将 ConVIRT[5] 方法进行简化,并采用更大规模的图像-文本对数据集来训练。作者想做的其实是直接用图像生成文本,但由于训练效率的制约,才采用了对比学习的方法。
参考文献
[1] Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, Gretchen Krueger, and Ilya Sutskever. Learning Transferable Visual Models From Natural Language Supervision. In ICML, 2021.
[2] Olivier J. H ́enaff, Aravind Srinivas, Jeffrey De Fauw, Ali Razavi, Carl Doersch, S. M. Ali Eslami, and Aaron van den Oord. Data-efficient image recognition with contrastive predictive coding. In ICML, 2020.
[3] Ting Chen, Simon Kornblith, Kevin Swersky, Mohammad Norouzi, and Geoffrey E. Hinton. Big Self-Supervised Models are Strong Semi-Supervised Learners. In NIPS, 2020.
[4] Qizhe Xie, Minh-Thang Luong, Eduard Hovy, and Quoc Le. Self-training with Noisy Student improves ImageNet classification. In CVPR, 2020.
[5] Yuhao Zhang, Hang Jiang, Yasuhide Miura, Christopher D. Manning, and Curtis P. Langlotz. Contrastive Learning of Medical Visual Representations from Paired Images and Text. In MLHC, 2022.