Midjonery使用简单,效果出色,不过需要付费。本文将介绍完全开源的另一款产品StableDiffusion,它的社区目前非常活跃,各种插件和微调模型都非常多,而且它无需付费注册,没有速度、网络限制,非常推荐一试。
目前主流AI绘画产品:
| 产品 | 优点 | 缺点 |
|---|---|---|
| StableDiffusion | StablityAI公司开源、免费,可本地部署,生成速度快,社区活跃,各种插件和微调模型丰富 | 部署相对较难 |
| DALL-E2 | OpenAI公司产品,未开源 | 未开源,社区不够活跃 |
| Midjounery | 部署在Discord社区,社区活跃,使用简单 | 未开源,需付费使用,需魔法 |
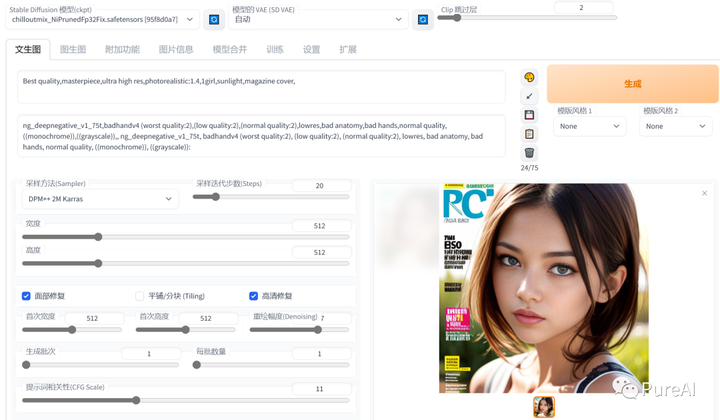
SD效果展示
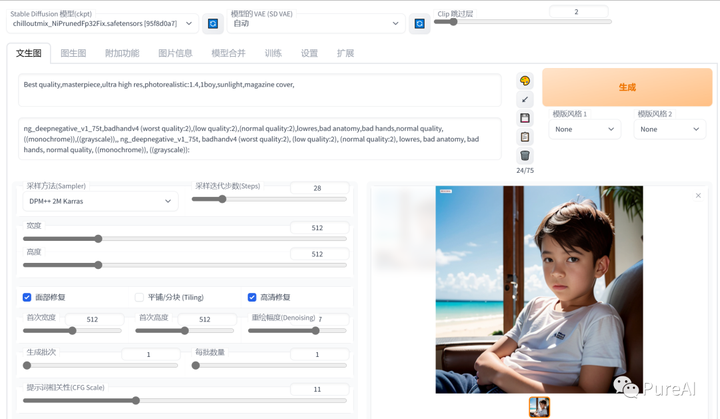
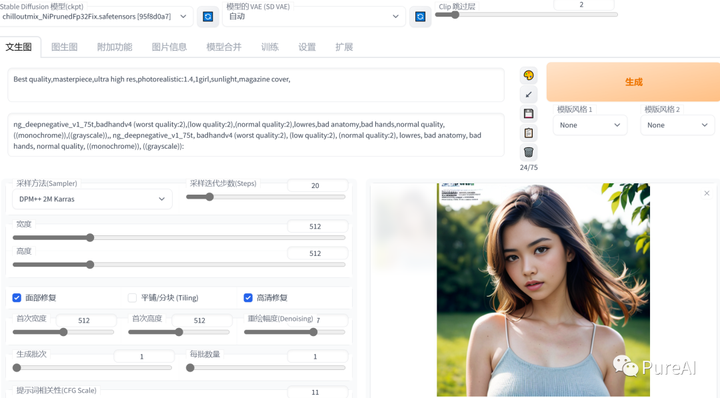


提示词参数:
prompt: Best quality,masterpiece,ultra high res,photorealistic:1.4,1boy,sunlight,magazine cover,
Negative prompt: ng_deepnegative_v1_75t,badhandv4 (worst quality:2),(low quality:2),(normal quality:2),lowres,bad anatomy,bad hands,normal quality,((monochrome)),((grayscale)),, ng_deepnegative_v1_75t, badhandv4 (worst quality:2), (low quality:2), (normal quality:2), lowres, bad anatomy, bad hands, normal quality, ((monochrome)), ((grayscale)):
Steps: 28, Size: 1024x1536, Seed: 141880510, Model: 2.8D_9.fp16, Sampler: DPM++ 2M Karras, CFG scale: 11几种使用stable diffusion的途径
1、在线云服务部署
从最开始的google colab,到现在很多国内的云服务商比如阿里云。都在推出stable diffusion相关的服务,按算力付费,新人注册可以免费体验,优点就是方便
2、市场上基于SD封装的产品
比如liblibAI,体验下来效果还不错,方便易上手,社区活跃;缺点是受制于平台,免费的很慢。
阿里云部署步骤
创建一个新实例
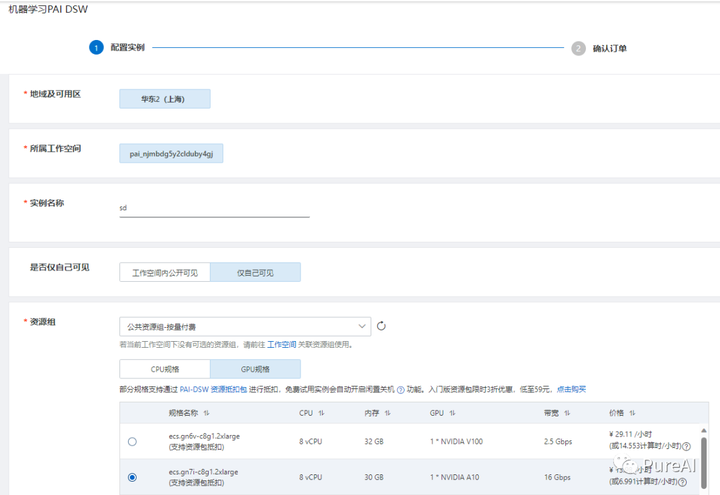
选择stablediffusion镜像:stable-diffusion-webui-env:pytorch1.13-gpu-py310-cu117-ubuntu22.04(可以看出其部署的环境要求)

进入workspace,创建sd文件夹,并下载stable-diffusion-webui源码
git clone https://github.com/AUTOMATIC1111/stable-diffusion-webui.git
cd stable-diffusion-webui
git checkout a9fed7c364061ae6efb37f797b6b522cb3cf7aa2
cd repositories
git clone https://github.com/sczhou/CodeFormer.git有可能会连接github超时,需要多试几次

安装pip,并替换为国内源
sudo apt-get install python3-pip
pip config set global.index-url https://mirrors.aliyun.com/pypi/simple这里注意:我开始使用清华源报错找不到tb-nightly,需要切换到阿里源

安装webui所需要的依赖包
cd stable-diffusion-webui
pip install -r requirements_versions.txt
pip install -r requirements.txt下载常用插件
cd extensions
git clone https://gitcode.net/mirrors/DominikDoom/a1111-sd-webui-tagcomplete.git
git clone https://gitcode.net/ranting8323/stable-diffusion-webui-localization-zh_CN
wget -c http://pai-vision-data-sh.oss-cn-shanghai.aliyuncs.com/aigc-data/webui_config/config.jsona1111-sd-webui-tagcomplete:tag自动补全插件,非常好用
stable-diffusion-webui-localization-zh_CN:是汉化插件
下载 chilloutmix 大模型,是一个爆火的真人模型
cd models/Stable-diffusion
wget -c https://huggingface.co/naonovn/chilloutmix_NiPrunedFp32Fix/resolve/main/chilloutmix_NiPrunedFp32Fix.safetensors -O chilloutmix_NiPrunedFp32Fix.safetensors下载基础推理模型lora
cd .. && mkdir Lora && cd Lora
wget -c https://huggingface.co/Kanbara/doll-likeness-series/resolve/main/koreanDollLikeness_v10.safetensors下载codeformer 面部修复模型(非必须),这个地方我下了好多次,太慢了,提醒自己耐心再耐心
cd ../Codeformer/
wget -c http://pai-vision-data-hz.oss-cn-zhangjiakou.aliyuncs.com/EasyCV/datasets/try_on/codeformer-v0.1.0.pth
cd /stable-diffusion-webui/repositories/CodeFormer/weights/facelib
wget -c https://github.com/xinntao/facexlib/releases/download/v0.1.0/detection_Resnet50_Final.pth下载embeddings
cd ../../embeddings
wget -c http://pai-vision-data-hz.oss-cn-zhangjiakou.aliyuncs.com/EasyCV/datasets/try_on/ng_deepnegative_v1_75t.pt启动服务
cd ..
python3 -m venv --system-site-packages --symlinks venv
sed -i 's/can_run_as_root=0/can_run_as_root=1/g' webui.sh && ./webui.sh踩坑经验
这里有几个重要的原则
- 遇到各种报错,先找到trace最后的根本问题,80%是各种依赖的版本问题
- 任何问题都可以尝试去sd官方github的issue中寻找解决办法:
- 一半的问题是网络问题,保持耐心再耐心
比如我碰到的如下几个问题,分别都在issue中找打了解决办法。
Q1:pydantic版本问题
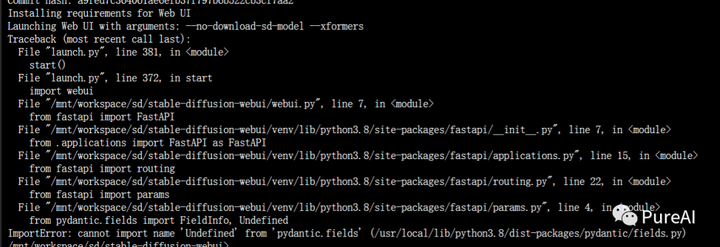
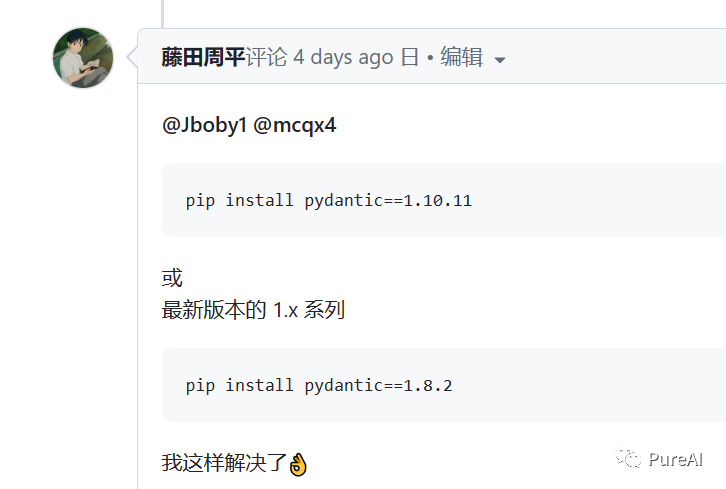
Q2:torch版本问题
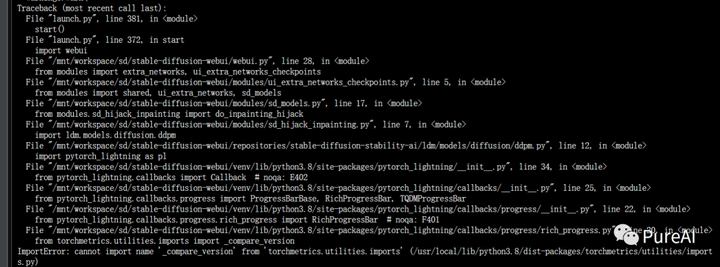

Q3:fastapi版本问题
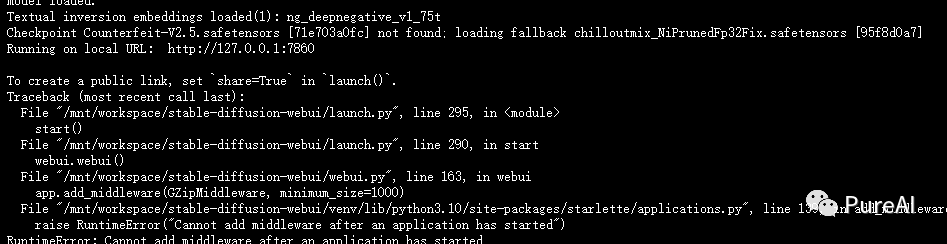
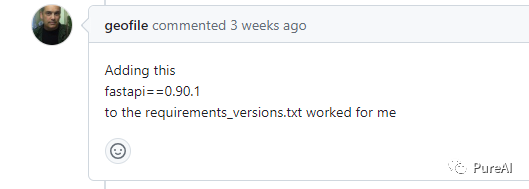

Q4,生成成功,但是页面展示不了,检查后台报错
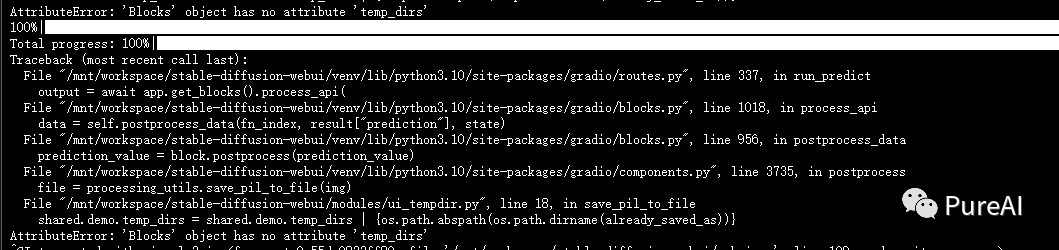
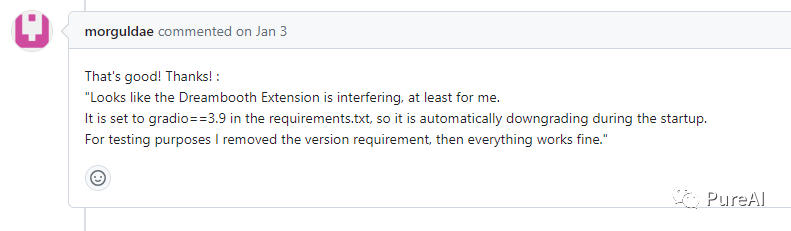
Q5,使用面部修复模型失败
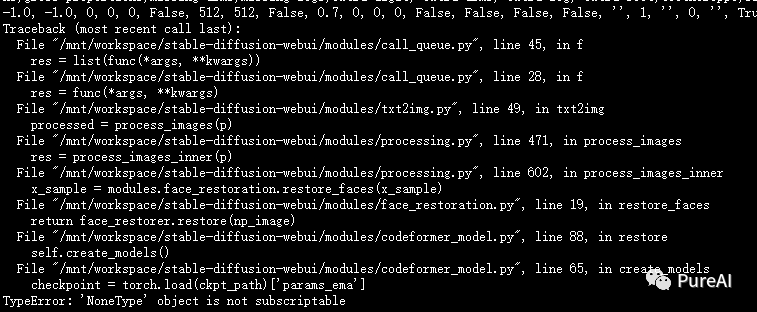
解决:重新下载codeformer模型
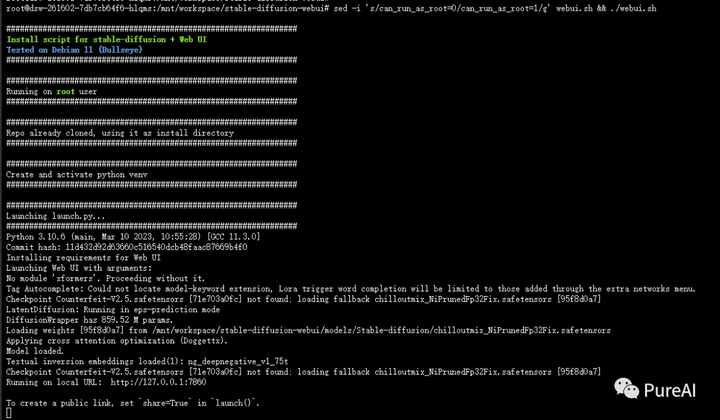
按上述一步步排错修改后,最终看到了启动成功!感动到想哭
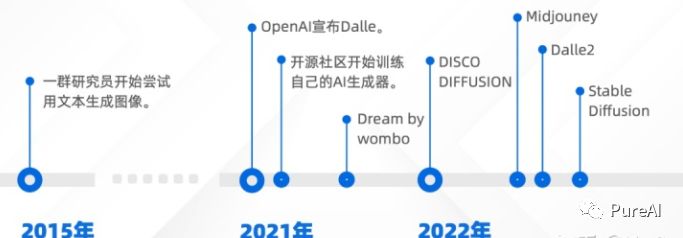
AI模型技术
AI绘画技术的发展历程经历了从GAN(生成式对抗网络)到自回归生成,再到目前的扩散(diffusion)模型+CLIP生成阶段,已经具备了强大的能力。
| 模型 | 特点 |
|---|---|
| GAN | 上一代图像生成技术,通过生成器和判别器的对抗训练提升绘画,稳定性比较差 |
| 自回归 | 基于transformer提升稳定性和效果,但训练成本高速度慢 |
| 扩散模型 | 显著提升稳定性和出图效率,结合CLIP可应用于跨模态图像生成。当前主流 |
下图展示的AI绘画发展史,2021开始的主流的AI绘画模型基本都运用了扩散模型
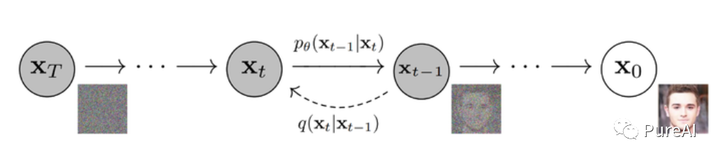
Diffusion 扩散模型
扩散模型简单理解可以分为加噪和去噪的过程,或者说,是一个有码到无码”的艺术。
它通过定义一个马尔可夫链,通过连续向数据添加随机噪声,直到得到一个纯高斯噪声数据,然后再学习逆扩散的过程,经过反向降噪推断来生成图像。整个过程是逐步优化的,确保了模型的可控性和稳定度。
CLIP(Contrastive Language-image Pre-training)
CLIP 是文本-图像跨模态预训练模型,它的训练过程可以简单理解为给图片加上文字说明。
其实现方式可以类别前两篇介绍利用LLM实现私有知识库文章提到的embedding技术,也是先将描述文字向量化,找到关联的图片向量,反向生成。
这里直接将该软件分享出来给大家吧~
1.stable diffusion安装包
随着技术的迭代,目前 Stable Diffusion 已经能够生成非常艺术化的图片了,完全有赶超人类的架势,已经有不少工作被这类服务替代,比如制作一个 logo 图片,画一张虚拟老婆照片,画质堪比相机。
最新 Stable Diffusion 除了有win多个版本,就算说底端的显卡也能玩了哦!此外还带来了Mac版本,仅支持macOS 12.3或更高版本。

2.stable diffusion视频合集
我们在学习的时候,往往书籍源码难以理解,阅读困难,这时候视频教程教程是就很适合了,生动形象加上案例实战,一步步带你入坑stable diffusion,科学有趣才能更方便的学习下去。

3.stable diffusion模型下载
stable diffusion往往一开始使用时图片等无法达到理想的生成效果,这时则需要通过使用大量训练数据,调整模型的超参数(如学习率、训练轮数、模型大小等),可以使得模型更好地适应数据集,并生成更加真实、准确、高质量的图像。

4.stable diffusion提示词
提示词是构建由文本到图像模型解释和理解的单词的过程。可以把它理解为你告诉 AI 模型要画什么而需要说的语言,整个SD学习过程中都离不开这本提示词手册。

5.SD从0到落地实战演练

如果你能在15天内完成所有的任务,那你堪称天才。然而,如果你能完成 60-70% 的内容,你就已经开始具备成为一名SD大神的正确特征了。
这份完整版的stable diffusion资料我已经打包好,需要的点击下方插件,即可前往免费领取!