目录
引言
概述
CART决策树的特点
核心思想
减少不确定性的指标
基尼系数(Gini Index)
分类错误率
熵
银行实例
背景
数据准备
模型构建
模型评估与优化
应用与结果
代码示例

✈✈✈✈引言✈✈✈✈
CART算法既可以用于分类问题,也可以用于回归问题,这使得它在多个领域都有广泛的应用。例如,在电商推荐系统中,CART算法可以用于构建商品推荐模型,提高用户购物体验和销售额;在金融风控领域,CART算法可以应用于信用评分和欺诈检测等场景,帮助银行和其他金融机构降低风险。
相比于其他决策树算法(如ID3和C4.5),CART算法具有更强的适用性。它既可以处理离散型数据,也可以处理连续型数据,这使得CART算法能够处理更加复杂和多样化的数据集。
CART决策树生成的模型具有直观易懂的特点,每个节点和分支都代表了数据集中的一种模式或规则。这使得非专业人士也能够理解模型的工作原理,增加了模型的可信度和接受度。
今天来学习一下CART决策树吧
✈其他文章详见✈
【机器学习】机器的登神长阶——AIGC-CSDN博客
【Linux】进程地址空间-CSDN博客【linux】进程控制——进程创建,进程退出,进程等待-CSDN博客
⭐⭐⭐概述⭐⭐⭐
CART(Classification and Regression Trees)决策树是一种以基尼系数为核心评估指标的机器学习算法,适用于分类和回归任务。
CART决策树基于“递归二元切分”的方法,通过将数据集逐步分解为两个子集来构建决策树。CART既能作为分类树(预测离散型数据),也能作为回归树(预测连续型数据)。外观类似于二叉树。
对于每个节点,计算所有非类标号属性的基尼系数增益,选择增益值最大的属性作为决策树的划分特征。
通过递归的方式,将数据子集和分裂规则分解为一个二叉树,其中叶节点表示具体的类别(分类树)或预测值(回归树)。
CART决策树的特点
简单易懂:计算简单,易于理解,可解释性强。
处理缺失值:比较适合处理有缺失属性的样本。
处理大型数据集:能够在相对短的时间内对大型数据源得出可行且效果良好的结果。
模型复杂度:可以通过限制决策树的最大深度或叶子节点的最小样本数来控制模型的复杂度。
过拟合风险:CART决策树容易出现过拟合现象,生成的决策树可能对训练数据有很好的分类能力,但对未知的测试数据未必有很好的分类能力。
在线学习:CART决策树不支持在线学习,当有新的样本产生后,决策树模型需要重建。
以scikit-learn库中的CART决策树分类器为例,演示如何使用CART决策树进行分类任务
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeClassifier
from sklearn.metrics import accuracy_score
# 加载鸢尾花数据集
iris = load_iris()
X = iris.data
y = iris.target
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
# 创建CART决策树分类器对象(使用默认参数,即为CART决策树)
clf = DecisionTreeClassifier(random_state=42)
# 使用训练数据拟合模型
clf.fit(X_train, y_train)
# 使用测试数据进行预测
y_pred = clf.predict(X_test)
# 计算并打印准确率
accuracy = accuracy_score(y_test, y_pred)
print("Accuracy:", accuracy)🧠🧠🧠核心思想🧠🧠🧠
| 特征1 | 特征2 | 目标值 |
| 1 | 1 | 1 |
| 1 | 0 | 1 |
| 1 | 1 | 1 |
| 1 | 0 | 1 |
| 0 | 1 | 1 |
| 0 | 0 | 0 |
| 0 | 1 | 0 |
| 0 | 0 | 0 |
有两种决策树的构建方法
以不同的特征作为根节点会有不同的模型
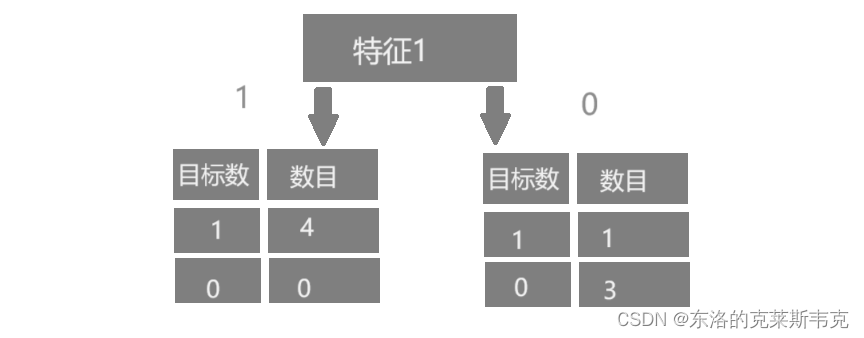
示例一
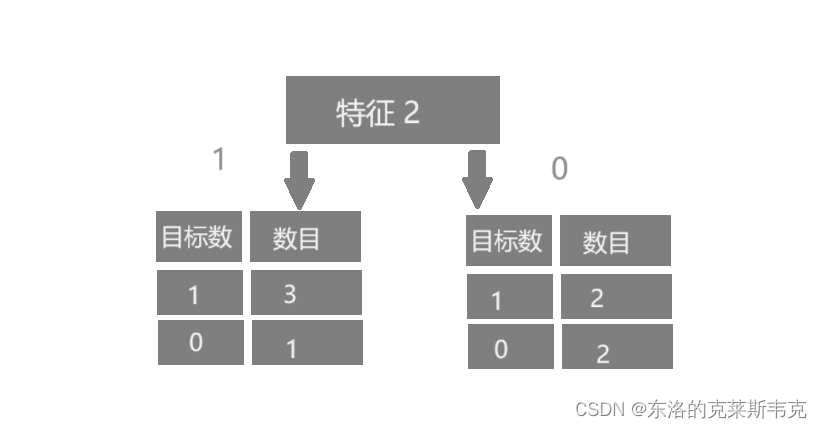
示例二
对于以特征一为根节点的树来说,传入参数为1,大概率会得到 1。传入参数为 0 大概率会得到 0。
对于以特征二为根节点的树来说,传入参数为1,大概率会得到 1。传入参数为 0 ,输出 1 的概率和输出0,的概率是相等的。这样的决策树的不确定性太高。
综上,应以以特征1为根节点
✌✌减少不确定性的指标✌✌
基尼系数(Gini Index)
基尼系数是CART决策树中用于分类任务的一个评估指标,用于衡量数据集的不确定性。基尼系数的值介于0和1之间,值越大,表示数据集的不确定性越高,纯度越低。
对于包含K个类别的数据集D,其基尼系数的定义为:
Gini(D)=1−∑k=1Kpk2
其中,pk表示第k个类别在数据集D中出现的概率。
当使用某个特征A对数据进行划分时,划分后数据集D的基尼系数定义为:
Gini(D,A)=∣D∣∣D1∣Gini(D1)+∣D∣∣D2∣Gini(D2)
其中,D1和D2表示按照特征A进行划分后得到的两个子集,∣D∣、∣D1∣和∣D2∣分别表示数据集D、D1和D2的样本数量。
分类错误率
CART决策树的分类错误率是指在使用CART算法构建的决策树模型对测试集进行分类时,错误分类的样本数占总样本数的比例。错误率的计算依赖于具体的数据集和模型表现。
在CART决策树的构建过程中,为了降低分类错误率,通常会使用诸如Gini指数(Gini Index)或信息增益(Information Gain)等度量标准来选择最佳划分特征。CART算法倾向于选择那些能够使得划分后子节点纯度更高的特征,即分类错误率更低的特征。
CART决策树的分类错误率可以通过以下步骤计算:
数据准备:首先,需要有一个已经标记好类别的数据集,并将其划分为训练集和测试集。
模型训练:使用训练集来训练CART决策树模型。在这个过程中,模型会基于Gini指数或其他度量标准来选择最佳划分特征,并递归地构建决策树。
模型评估:将训练好的CART决策树模型应用于测试集,并对测试集中的每个样本进行分类。
计算错误率:统计测试集中被错误分类的样本数,并将其除以测试集的总样本数,得到CART决策树的分类错误率。
需要注意的是,CART决策树的分类错误率会受到多种因素的影响,包括数据集的特性、特征的选择、树的深度(即剪枝的程度)等。因此,在实际应用中,通常需要通过交叉验证等技术来评估模型的表现,并选择最优的模型参数。
此外,对于不同的数据集和任务,CART决策树的分类错误率也会有所不同。在一些复杂的数据集上,CART决策树可能难以达到很低的错误率,但在一些简单的数据集上,CART决策树可以取得很好的效果。因此,在选择使用CART决策树时,需要根据具体的应用场景和数据集特性来评估其适用性。
熵
CART决策树在分类任务中并不直接使用熵(Entropy)作为划分标准,而是采用基尼不纯度(Gini Impurity)或者说基尼系数。
熵是信息论中的一个重要概念,用于衡量数据的不确定性或混乱程度。
在决策树中,熵通常用于ID3算法,作为划分数据集的特征选择。
熵的计算公式为:
(H(X) = -\sum_{i=1}^{n} p(x_i) \log_2 p(x_i)),其中(p(x_i))是某个类别在数据集中的比例。
CART决策树与熵的关系:
不直接使用熵:CART决策树在分类任务中不直接使用熵作为划分标准,而是采用基尼不纯度。
基尼不纯度:基尼不纯度也是衡量数据混乱程度的一个指标,但计算上更为简单。其计算公式为:(Gini(D) = 1 - \sum_{i=1}{n} p(x_i)2),其中(p(x_i))是类别(i)在数据集(D)中的概率。
选择划分特征:CART决策树通过计算每个特征的基尼不纯度增益来选择最佳划分特征。基尼不纯度增益定义为父节点的基尼不纯度减去所有子节点基尼不纯度的加权平均。
CART决策树的特征选择:CART决策树通过递归地将数据集划分为越来越小的子集来构建决策树。
在每个节点上,CART决策树会评估每个特征,并选择能够最大程度地减少基尼不纯度的特征进行划分。
通过不断地划分,CART决策树可以逐渐构建出一个高效的分类器。
💵💵💵银行实例💵💵💵

背景
一家大型银行为了提高信贷审批的效率和准确性,决定采用决策树算法来辅助审批过程。银行收集了包括客户年龄、收入、信用记录等多个维度的数据,这些数据将作为特征数据输入到决策树模型中。
数据准备
数据收集:银行从客户档案、信贷申请表中提取关键信息,如年龄、收入、职业、信用历史等。
数据清洗:对收集到的数据进行清洗,去除重复、错误或无效的数据,确保数据的准确性和可靠性。
特征选择:从所有可能的特征中,选择对分类有较大贡献的特征。在信贷审批中,通常会选择年龄、收入、信用记录等作为关键特征。
模型构建
数据划分:将清洗后的数据集划分为训练集和测试集。训练集用于构建决策树模型,测试集用于评估模型的性能。
构建决策树:从根节点开始,递归地选择最优特征对数据进行划分。在信贷审批中,例如,第一个节点可能根据年龄进行划分,将客户分为青年、中年和老年三组。然后,在每个子节点上,再根据其他特征(如收入、信用记录等)进行进一步的划分。
计算节点纯度:计算每个节点的纯度,即该节点下数据属于同一类别的比例。纯度越高,说明该节点下的数据越纯净,分类效果越好。
停止条件:当节点中的样本数量低于预定阈值、节点纯度达到预定阈值或树的深度达到预定阈值时,停止划分并生成叶节点。叶节点对应于最终的决策结果,如“批准贷款”或“拒绝贷款”。
模型评估与优化
评估模型性能:使用测试集评估构建好的决策树模型的性能。常用的评估指标包括准确率、召回率、F1值等。通过评估结果,可以了解模型在信贷审批中的表现。
模型优化:如果模型性能不佳,可以通过调整参数(如树的深度、最小样本数等)或采用集成学习(如随机森林)等方法来优化模型。
应用与结果
自动化审批:将构建好的决策树模型集成到银行的信贷审批系统中,实现自动化审批。当客户提交信贷申请时,系统可以自动调用模型进行预测,并给出审批结果。
提高审批效率:通过自动化审批,银行可以大大提高审批效率,减少人工干预和等待时间据统计,采用决策树算法后,贷款审批的准确率提高了10%,审批时间缩短了30%。
优化客户体验:客户可以更快地获得审批结果,提高了客户满意度和忠诚度。同时,银行也能更准确地识别高风险客户,降低信贷风险。
代码示例
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeClassifier
from sklearn.metrics import accuracy_score
# 1. 数据准备
# 假设数据集为'credit_data.csv',包含'Age', 'Income', 'Credit_History', 'Loan_Status'等列
data = pd.read_csv('credit_data.csv')
# 查看数据前几行
print(data.head())
# 假设'Loan_Status'是目标变量,其中'Y'表示批准贷款,'N'表示拒绝贷款
X = data[['Age', 'Income', 'Credit_History']] # 特征变量
y = data['Loan_Status'].map({'Y': 1, 'N': 0}) # 目标变量,转换为0和1
# 2. 数据划分
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 3. 模型构建
clf = DecisionTreeClassifier(random_state=42) # 创建决策树分类器
clf.fit(X_train, y_train) # 训练模型
# 4. 预测与评估
y_pred = clf.predict(X_test) # 对测试集进行预测
accuracy = accuracy_score(y_test, y_pred) # 计算准确率
print(f"Accuracy: {accuracy}")
# 5. 可视化决策树(可选,对于较大的树可能不易阅读)
# 需要安装 graphviz 和 pydotplus 库
# from sklearn.tree import export_graphviz
# import pydotplus
# dot_data = export_graphviz(clf, out_file=None,
# feature_names=X.columns,
# class_names=['No', 'Yes'],
# filled=True, rounded=True,
# special_characters=True)
# graph = pydotplus.graph_from_dot_data(dot_data)
# graph.write_png('loan_approval_tree.png')
# 注意:可视化部分可能需要额外的库,并且对于复杂的树可能不太实用。