二、NumPy基础:数组和矢量计算
本文源自微博客(www.microblog.store),且以获得授权
NumPy(Numerical Python的简称)是Python数值计算最重要的基础包。大多数提供科学计算的包都是用NumPy的数组作为构建基础。
NumPy的部分功能如下:
- ndarray,一个具有矢量算术运算和复杂广播能⼒的快速且节省空间的多维数组。
- 用于对整组数据进行快速运算的标准数学函数(⽆需编写循环)。
- 用于读写磁盘数据的工具以及用于操作内存映射文件的工具。
- 线性代数、随机数生成以及傅⾥叶变换功能。
- 用于集成由C、C++、Fortran等语言编写的代码的A C API。
由于NumPy提供了一个简单易用的C API,因此很容易将数据传递给由低级语言编写的外部库,外部库也能以NumPy数组的形式将数据返回给Python。这个功能使Python成为一种包装C/C++/Fortran历史代码库的选择,并使被包装库拥有一个动态的、易用的接口。
NumPy本身并没有提供多么高级的数据分析功能,理解NumPy数组以及面向数组的计算将有助于你更加高效地使用诸如pandas之类的工具。因为NumPy是一个很大的题目,我会在附录A中介绍更多NumPy高级功能,比如广播。
对于大部分数据分析应用而言,我最关注的功能主要集中在:
- 用于数据整理和清理、子集构造和过滤、转换等快速的矢量化数组运算
- 常用的数组算法,如排序、唯一化、集合运算等
- 高效的描述统计和数据聚合/摘要运算
- 用于异构数据集的合并/连接运算的数据对⻬和关系型数据运算
- 将条件逻辑表述为数组表达式(而不是带有if-elif-else分⽀的循环)
- 数据的分组运算(聚合、转换、函数应用等)
虽然NumPy提供了通用的数值数据处理的计算基础,但大多数读者可能还是想将pandas作为统计和分析工作的基础,尤其是处理表格数据时。pandas还提供了一些NumPy所没有的更加领域特定的功能,如时间序列处理等。
Python的面向数组计算可以追溯到1995年,JimHugunin创建了Numeric库。接下来的10年,许多科学编程社区纷纷开始使用Python的数组编程,但是进入21世纪,库的生态系统变得碎片化了。2005年,Travis Oliphant从Numeric和Numarray项目整了出了NumPy项目,进而所有社区都集合到了这个框架下。
NumPy之于数值计算特别重要的原因之一,是因为它可以高效处理大数组的数据。这是因为:
-
- NumPy是在一个连续的内存块中存储数据,独立于其他Python内置对象。NumPy的C语言编写的算法库可以操作内存,而不必进行类型检查或其它前期工作。比起Python的内置序列,NumPy数组使用的内存更少。
- NumPy可以在整个数组上执行复杂的计算,而不需要Python的for循环
2.1、NumPy的ndarray:一种多维数组对象
NumPy最重要的一个特点就是其N维数组对象(即ndarray),该对象是一个快速而灵活的大数据集容器。你可以利用这种数组对整块数据执行一些数学运算,其语法跟标量元素之间的运算一样。
要明⽩Python是如何利用与标量值类似的语法进行批次计算,我们先引入NumPy,然后生成一个包含随机数据的小数组:
import numpy as np
data = np.random.randn(2,3)
data
data*10
data+data
然后进行数学运算:
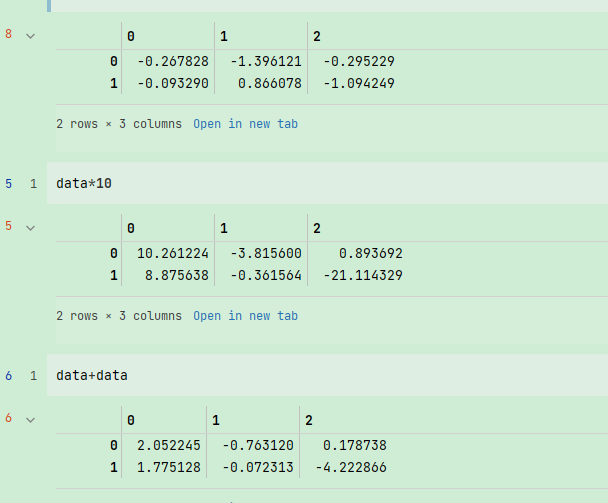
第一个例子中,所有的元素都乘以10。第二个例子中,每个元素都与自身相加。
ndarray是一个通用的同构数据多维容器,也就是说,其中的所有元素必须是相同类型的。每个数组都有一个shape(一个表示各维度大小的元组)和一个dtype(一个用于说明数组数据类型的对象):
data.shape
(2, 3)
data.dtype
dtype('float64')
本章将会介绍NumPy数组的基本用法,这对于本书后面各章的理解基本够用。虽然大多数数据分析工作不需要深入理解NumPy,但是精通面向数组的编程和思维方式是成为Python科学计算⽜⼈的一大关键步骤。
2.1.1 创建ndarray
创建数组最简单的办法就是使用array函数。它接受一切序列型的对象(包括其他数组),然后产生一个新的含有传入数据的NumPy数组。以一个列表的转换为例:
data1 = [6,7.5,8,0.5]
arr1 = np.array(data1)
arr1
array([ 6. , 7.5, 8. , 0. , 1. ])
嵌套序列(比如由一组等长列表组成的列表)将会被转换为一个多维数组:
data2 = [[1, 2, 3, 4], [5, 6, 7, 8]]
arr2 = np.array(data2)
arr2
array([[1, 2, 3, 4],
[5, 6, 7, 8]])
因为data2是列表的列表,NumPy数组arr2的两个维度的shape是从data2引入的。可以用属性ndim和shape验证:
In [25]: arr2.ndim
Out[25]: 2
In [26]: arr2.shape
Out[26]: (2, 4)
除非特别说明(稍后将会详细介绍),np.array会尝试为新建的这个数组推断出一个较为合适的数据类型。数据类型保存在一个特殊的dtype对象中。比如说,在上面的两个例子中,我们有:
dtype('float64')
除np.array之外,还有一些函数也可以新建数组。比如,zeros和ones分别可以创建指定长度或形状的全0或全1数组。empty可以创建一个没有任何具体值的数组。要用这些方法创建多维数组,只需传入一个表示形状的元组即可:
np.zeros(10)
np.zeros((3, 6))
np.empty((2, 3, 2))
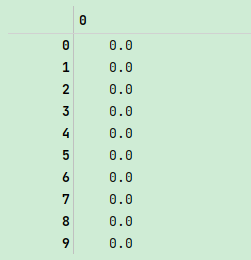
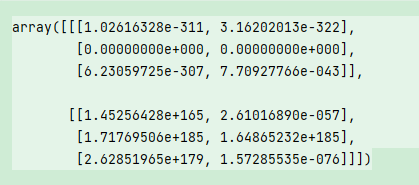
注意:认为np.empty会返回全0数组的想法是不安全的。很多情况下(如前所示),它返回的都是一些未初始化的垃圾值。
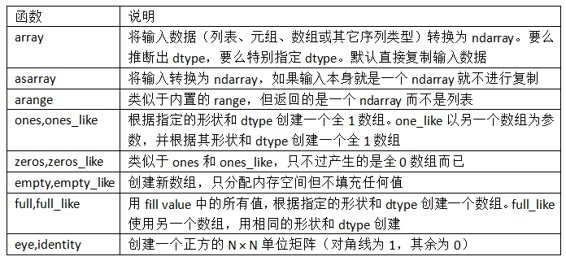
下表列出了一些数组创建函数。由于NumPy关注的是数值计算,因此,如果没有特别指定,数据类型基本都是float64(浮点数)。
2.1.2 ndarray的数据类型
dtype(数据类型)是一个特殊的对象,它含有ndarray将一块内存解释为特定数据类型所需的信息:
In [33]: arr1 = np.array([1, 2, 3], dtype=np.float64)
In [34]: arr2 = np.array([1, 2, 3], dtype=np.int32)
In [35]: arr1.dtype
Out [35]: dtype('float64')
In [36]: arr2.dtype
Out [36]: dtype('int32')
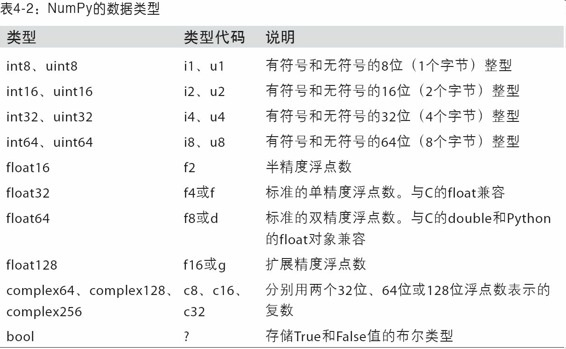
dtype是NumPy灵活交互其它系统的源泉之一。多数情况下,它们直接映射到相应的机器表示,这使得“读写磁盘上的二进制数据流”以及“集成低级语言代码(如C、Fortran)”等工作变得更加简单。数值型dtype的命名方式相同:一个类型名(如float或int),后面跟一个用于表示各元素位长的数字。标准的双精度浮点值(即Python中的float对象)需要占用8字节(即64位)。因此,该类型在NumPy中就记作float64。下表列出了NumPy所⽀
持的全部数据类型。
你可以通过ndarray的astype方法明确地将一个数组从一个dtype转换成另一个dtype:
arr = np.array([1, 2, 3, 4, 5])
float_arr = arr.astype(np.float64)
2.1.3 NumPy数组的运算
数组很重要,因为它使你不用编写循环即可对数据执行批量运算。NumPy用户称其为矢量化vectorization)。大小相等的数组之间的任何算术运算都会将运算应用到元素级:
import numpy as np
arr = np.array([[1., 2., 3.], [4., 5., 6.]])
arr

arr * arr

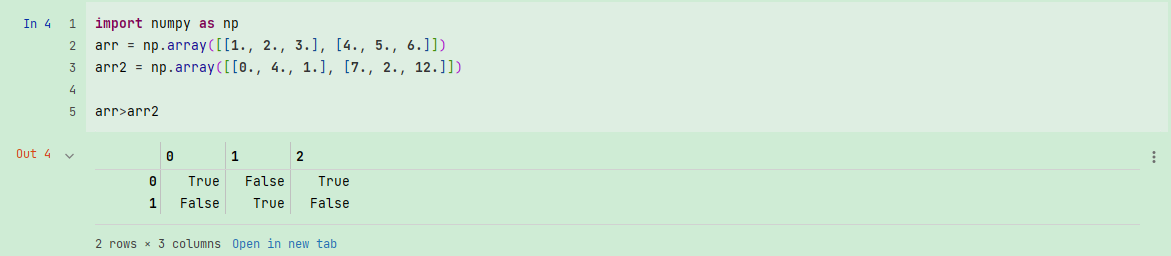
大小相同的数组之间的比较会生成布尔值数组:
import numpy as np
arr = np.array([[1., 2., 3.], [4., 5., 6.]])
arr2 = np.array([[0., 4., 1.], [7., 2., 12.]])
arr>arr2
2.1.4 基本的索引和切片
NumPy数组的索引是一个内容丰富的主题,因为选取数据子集或单个元素的方式有很多。一维数组很简单。从表面上看,它们跟Python列表的功能差不多:
arr = np.arange(10)
arr[5:8]

arr[5:8] = 12
arr[5:8]

如上所示,当你将一个标量值赋值给一个切片时(如arr[5:8]=12),该值会自动传播(也就说后面将会讲到的“广播”)到整个选区。跟列表最重要的区别在于,数组切片是原始数组的视图(相当于java中的引用)。这意味着数据不会被复制,视图上的任何修改都会直接反映到源数组上。
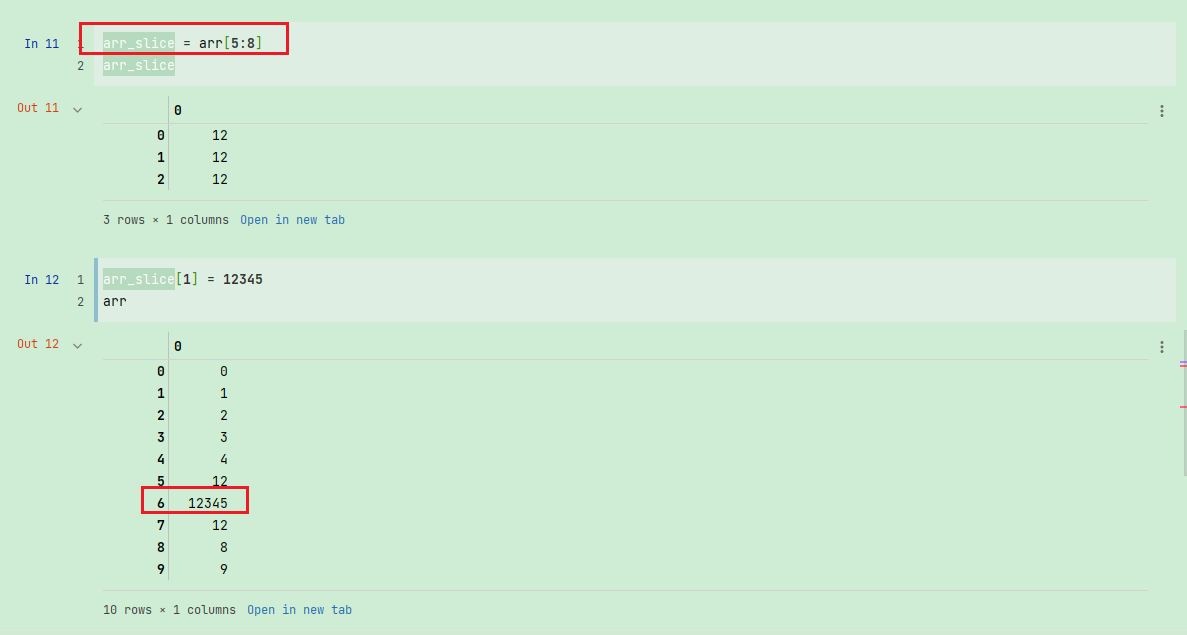
作为例子,先创建一个arr的切片:
arr_slice = arr[5:8]
arr_slice

现在,当我修稿arr_slice中的值,变动也会体现在原始数组arr中:
arr_slice[1] = 12345
arr
切片[ : ]会给数组中的所有值赋值:
arr_slice[:] = 64

如果你刚开始接触NumPy,可能会对此感到惊讶(尤其是当你曾经用过其他热衷于复制数组数据的编程语言)。由于NumPy的设计目的是处理大数据,所以你可以想象一下,假如NumPy坚持要将数据复制来复制去的话会产生何等的性能和内存问题。
注意:如果你想要得到的是ndarray切片的一份副本而非视图,就需要明确地进行复制操作,例如arr[5:8].copy()。
在多维数组中,如果省略了后面的索引,则返回对象会是一个维度低一点的ndarray(它含有高一级维度上的所有数据)。因此,在2×2×3数组arr3d中:
arr3d = np.array([[[1, 2, 3], [4, 5, 6]], [[7,8,9],[10,11,12]]])
arr3d
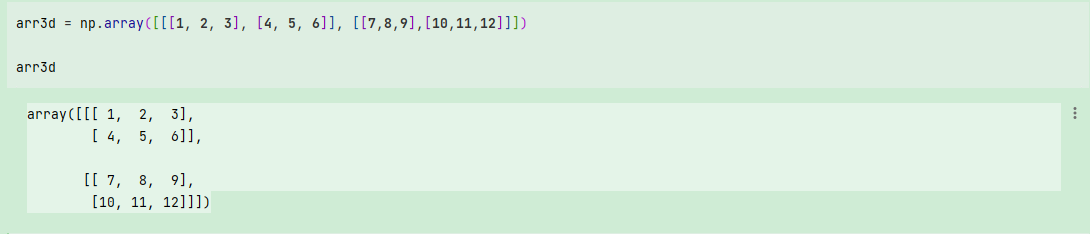
arr3d[0]是一个2×3数组:

标量值和数组都可以被赋值给arr3d[0]:
old_values = arr3d[0].copy()
arr3d[0] = 42
arr3d

arr3d[0] = old_values
arr3d

2.1.5 切片索引
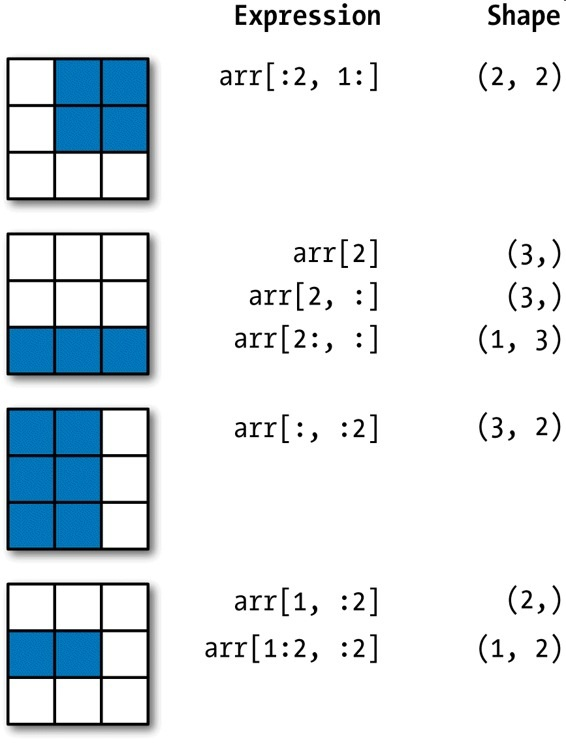
ndarray的切片语法跟Python列表这样的一维对象差不多,对于之前的二维数组arr2d,其切片方式稍显不同:
arr2d=([[1, 2, 3],
[4, 5, 6],
[7, 8, 9]])
arr2d


可以看出,它是沿着第0轴(即第一个轴)切片的。也就是说,切片是沿着一个轴向选取元素的。表达式arr2d[:2]可以被认为是“选取arr2d的前两行”。
你可以一次传入多个切片,就像传入多个索引那样:
arr2d=np.array([[1, 2, 3],
[4, 5, 6],
[4, 9, 6],
[7, 8, 9]])
arr2d[1, :2]

像这样进行切片时,只能得到相同维数的数组视图。通过将整数索引和切片混合,可以得到低维度的切片。
例如,我可以选取第二行的前两列:

相似的,还可以选择第三列的前两行:

注意,“只有冒号”表示选取整个轴,因此你可以像下面这样只对高维轴进行切片:

自然,对切片表达式的赋值操作也会被扩散到整个选区。
2.1.6 布尔型索引
来看这样一个例子,假设我们有一个用于存储数据的数组以及一个存储姓名的数组(含有重复项)。在这⾥,我将使用numpy.random中的randn函数生成一些正态分布的随机数据:
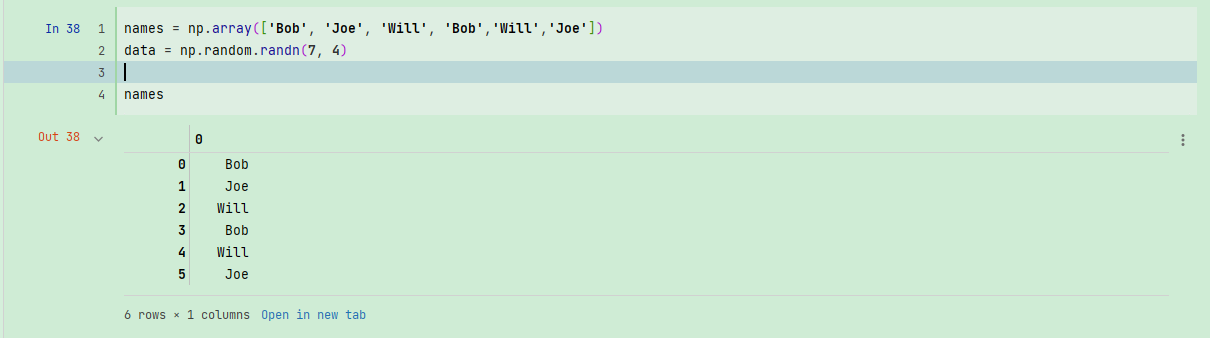
names = np.array(['Bob', 'Joe', 'Will', 'Bob','Will','Joe'])
data = np.random.randn(7, 4)
names
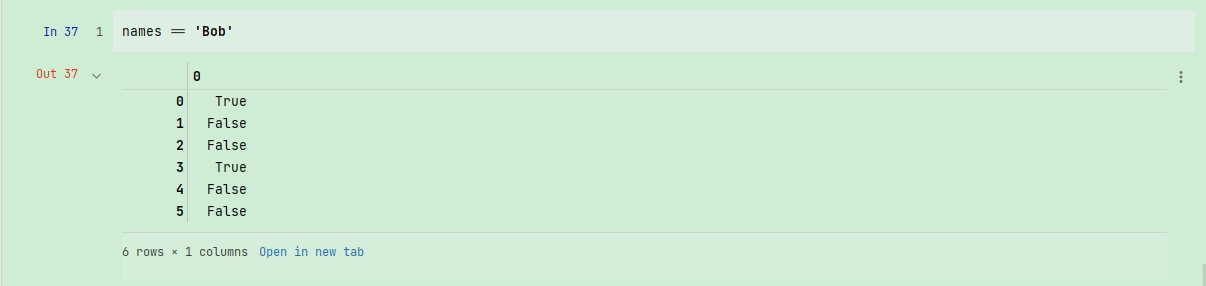
假设每个名字都对应data数组中的一行,而我们想要选出对应于名字"Bob"的所有行。跟算术运算一样,数组的比较运算(如==)也是矢量化的。因此,对names和字符串"Bob"的比较运算将会产生一个布尔型数组:
这个布尔型数组可用于数组索引:

布尔型数组的长度必须跟被索引的轴长度一致。此外,还可以将布尔型数组跟切片、整数(或整数序列)混合使用.
通过布尔型数组设置值是一种经常用到的手段。为了将data中的所有负值都设置为0,我们只需:
data[data < 0] = 0
2.1.7 花式索引
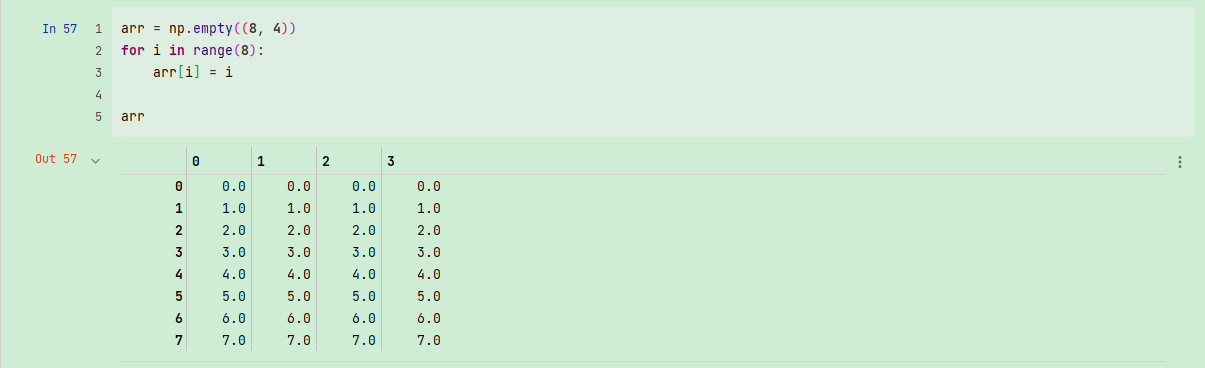
花式索引(Fancy indexing)是一个NumPy术语,它指的是利用整数数组进行索引。假设我们有一个8×4数组:
arr = np.empty((8, 4))
for i in range(8):
arr[i] = i
arr
为了以特定顺序选取行子集,只需传⼊一个用于指定顺序的整数列表或ndarray即可:

这段代码确实达到我们的要求了!使用负数索引将会从末尾开始选取行。一次传⼊多个索引数组会有一点特别。它返回的是一个一维数组,其中的元素对应各个索引元组:
arr = np.arange(32).reshape((8, 4))
arr
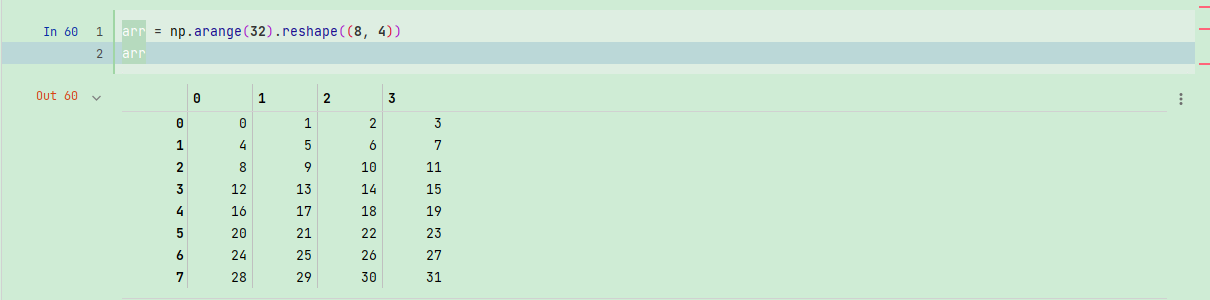
最终选出的是元素(1,0)、(5,3)、(7,1)和(2,2)。⽆论数组是多少维的,花式索引总是一维的。这个花式索引的行为可能会跟某些用户的预期不一样(包括我在内),选取矩阵的行列子集应该是矩形区域的形式才对。下面是
得到该结果的一个办法:

记住,花式索引跟切片不一样,它总是将数据复制到新数组中。
2.1.8 数组转置和轴对换
转置是重塑的一种特殊形式,它返回的是源数据的视图(不会进行任何复制操作)。数组不仅有transpose方法,还有一个特殊的T属性:
arr = np.arange(15).reshape((3, 5))
arr


在进行矩阵计算时,经常需要用到该操作。
对于⾼维数组,transpose需要得到一个由轴编号组成的元组才能对这些轴进行转置(比较费脑子):
arr = np.arange(16).reshape((2, 2, 4))
arr


这⾥,第一个轴被换成了第二个,第二个轴被换成了第一个,最后一个轴不变。
简单的转置可以使用.T,它其实就是进行轴对换而已。ndarray还有一个swapaxes方法,它需要接受一对轴编号:

swapaxes也是返回源数据的视图(不会进行任何复制操作)。
2.2 通用函数:快速的元素级数组函数
通用函数(即ufunc)是一种对ndarray中的数据执行元素级运算的函数。你可以将其看做简单函数(接受一个或多个标量值,并产生一个或多个标量值)的矢量化包装器。
许多ufunc都是简单的元素级变体,如sqrt和exp:
arr = np.arange(10)
arr

np.sqrt(arr)
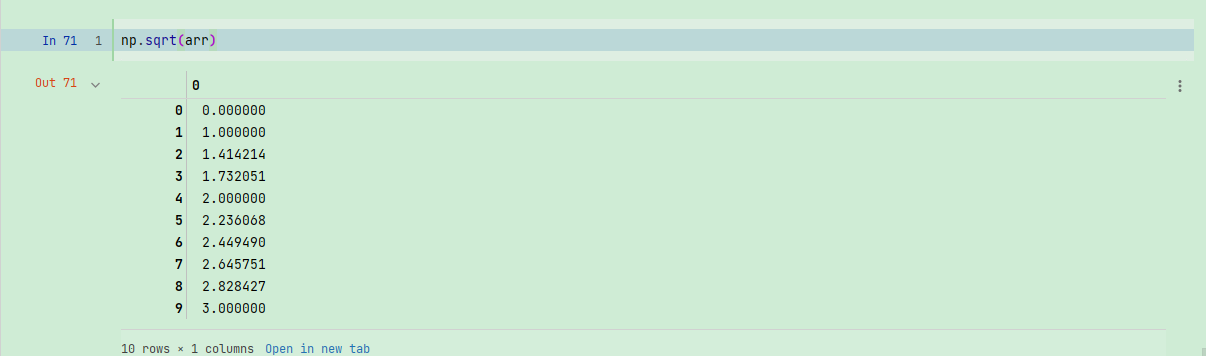
这些都是一元(unary)ufunc。另外一些(如add或maximum)接受2个数组(因此也叫二元(binary)ufunc),并返回一个结果数组:
x = np.random.randn(8)
y = np.random.randn(8)
np.maximum(x, y)
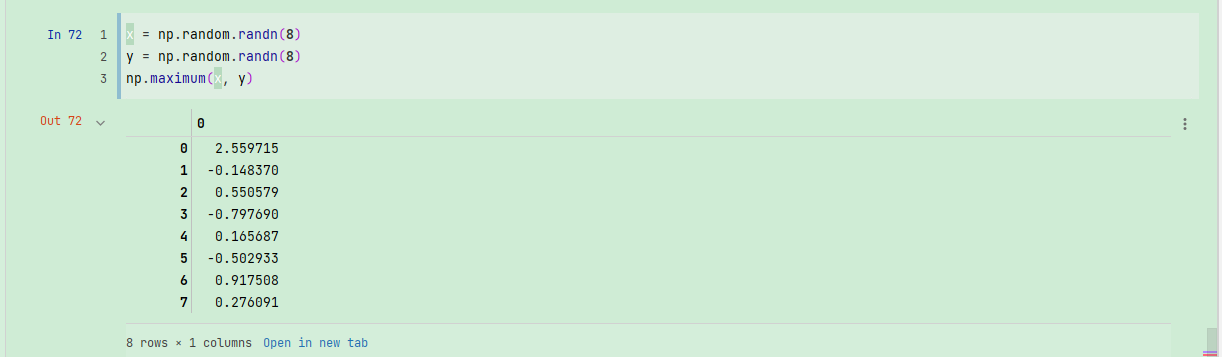
下图给出了一些一元和二元ufunc:





2.3 利用数组进行数据处理
NumPy数组使你可以将许多种数据处理任务表述为简洁的数组表达式(否则需要编写循环)。用数组表达式代替循环的做法,通常被称为矢量化。一般来说,矢量化数组运算要比等价的纯Python方式快上一两个数量级(甚至更多),尤其是各种数值计算。在后面内容中我将介绍广播,这是一种针对矢量化计算的强大手段。
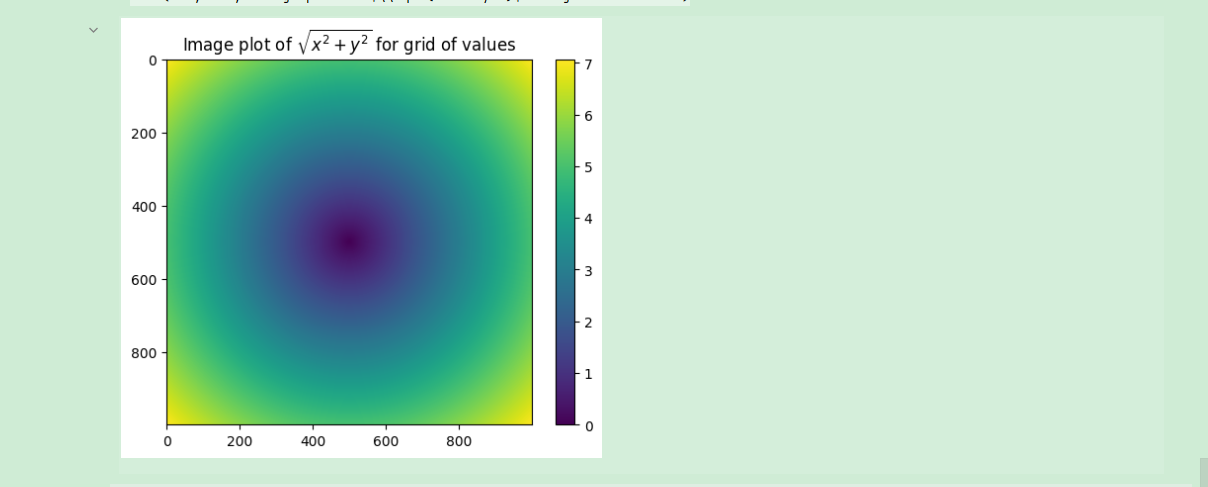
作为简单的例子,假设我们想要在一组值(网格型)上计算函数sqrt(x2 + y2)。np.meshgrid函数接受两个一维数组,并产生两个二维矩阵(对应于两个数组中所有的(x,y)对):
# 从-5开始,到5,步长为0.01,生成数据
points = np.arange(-5, 5, 0.01)
xs, ys = np.meshgrid(points, points)
ys
现在,对该函数的求值运算就好办了,把这两个数组当做两个浮点数那样编写表达式即可:
z = np.sqrt(xs ** 2 + ys ** 2)
z
对于z的分布,如下:
import matplotlib.pyplot as plt
plt.imshow(z)
plt.colorbar()
plt.title("Image plot of $\sqrt{x^2 + y^2}$ for grid of values")
2.3.1 将条件逻辑表述为数组运算
numpy.where函数是三元表达式x if condition else y的矢量化版本。假设我们有一个布尔数组和两个值数组:
xarr = np.array([1.1, 1.2, 1.3, 1.4, 1.5])
yarr = np.array([2.1, 2.2, 2.3, 2.4, 2.5])
cond = np.array([True, False, True, True, False])
假设我们想要根据cond中的值选取xarr和yarr的值:当cond中的值为True时,选取xarr的值,否则从yarr中选取。列表推导式的写法应该如下所示:
result = [(x if c else y)
for x, y, c in zip(xarr, yarr, cond)]
result
这有几个问题。第一,它对大数组的处理速度不是很快(因为所有工作都是由纯Python完成的)。第二,⽆法用于多维数组。若使用np.where,则可以将该功能写得非常简洁:
result = np.where(cond, xarr, yarr)
result
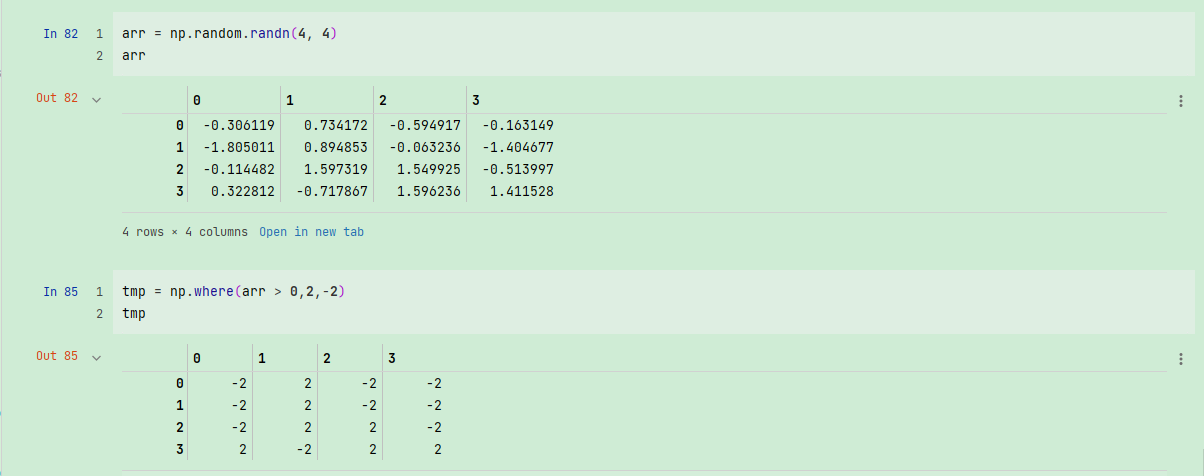
np.where的第二个和第三个参数不必是数组,它们都可以是标量值。在数据分析工作中,where通常用于根据另一个数组而产生一个新的数组。假设有一个由随机数据组成的矩阵,你希望将所有正值替换为2,将所有负值替换为-2。若利用np.where,则会非常简单:
arr = np.random.randn(4, 4)
arr
tmp = np.where(arr > 0,2,-1)
tmp
使用np.where,可以将标量和数组结合起来。例如,我可用常数2替换arr中所有正的值:
np.where(arr > 0, 2, arr)

传递给where的数组大小可以不相等,甚至可以是标量值。
2.3.2 数学和统计方法
可以通过数组上的一组数学函数对整个数组或某个轴向的数据进行统计计算。sum、mean以及标准差std等聚合计算(aggregation,通常叫做约简(reduction))既可以当做数组的实例方法调用,也可以当做顶级NumPy函数使用。
这⾥,我生成了一些正态分布随机数据,然后做了聚类统计:
arr = np.random.randn(5, 4)
np.mean(arr) # 0.06813175672246549
np.sum(arr) # 1.36263513444931
mean和sum这类的函数可以接受一个axis选项参数,用于计算该轴向上的统计值,最终结果是一个少一维的数组:
arr.mean(axis=1)

arr.sum(axis=0)

这⾥,arr.mean(1)是“计算行的平均值”,arr.sum(0)是“计算每列的和”。
其他如cumsum和cumprod之类的方法则不聚合,而是产生一个由中间结果组成的数组;在多维数组中,累加函数(如cumsum)返回的是同样大小的数组,但是会根据每个低维的切片沿着标记轴计算部分聚类。
下图列出了全部的基本数组统计方法。后续章节中有很多例子都会用到这些方法:


2.3.2 用于布尔型数组的方法
在上面这些方法中,布尔值会被强制转换为1(True)和0(False)。因此,sum经常被用来对布尔型数组中的True值计数:
arr = np.random.randn(100)
# arr
(arr > 0).sum() # 46
另外还有两个方法any和all,它们对布尔型数组非常有用。any用于测试数组中是否存在一个或多个True,而all则检查数组中所有值是否都是True:
bools = np.array([False, False, True, False, False])
bools.any() # True
bools.all() # False
这两个方法也能用于非布尔型数组,所有非0元素将会被当做True;
2.3.3 排序
跟Python内置的列表类型一样,NumPy数组也可以通过sort方法就地排序:
arr = np.random.randn(6)
arr.sort()
多维数组可以在任何一个轴向上进行排序,只需将轴编号传给sort即可:
arr.sort(1)
arr
顶级方法np.sort返回的是数组的已排序副本,而就地排序则会修改数组本身。计算数组分位数最简单的办法是对其进行排序,然后选取特定位置的值。
2.3.4 唯一化以及其它的集合逻辑
NumPy提供了一些针对一维ndarray的基本集合运算。最常用的可能要数np.unique了,它用于找出数组中的唯一值并返回已排序的结果:
names = np.array(['Bob', 'Joe', 'Will', 'Bob','Will','Joe','Will'])
np.unique(names)

更多的集合运算如下:

2.4 用于数组的文件输⼊输出
NumPy能够读写磁盘上的文本数据或二进制数据。这一小节只讨论NumPy的内置二进制格式。
np.save和np.load是读写磁盘数组数据的两个主要函数。默认情况下,数组是以未压缩的原始二进制格式保存在扩展名为.npy的文件中的:
arr = np.arange(10)
np.save('some_array', arr)
如果文件路径末尾没有扩展名.npy,则该扩展名会被自动加上。然后就可以通过np.load读取磁盘上的数组:
np.load('some_array.npy')
通过np.savez可以将多个数组保存到一个未压缩文件中,将数组以关键字参数的形式传⼊即可:
np.savez('array_archive.npz', a=arr, b=arr)
加载.npz文件时,你会得到一个类似字典的对象,该对象会对各个数组进行延迟加载:
arch = np.load('array_archive.npz')
arch['b']
2.5 线性代数
线性代数(如矩阵乘法、矩阵分解、行列式以及其他方阵数学等)是任何数组库的重要组成部分。不像某些语言(如MATLAB),通过*对两个二维数组相乘得到的是一个元素级的积,而不是一个矩阵点积。因此,NumPy提供了一个用于矩阵乘法的dot函数(既是一个数组方法也是numpy命名空间中的一个函数):
x = np.array([[1., 2., 3.], [4., 5., 6.]])
y = np.array([[6., 23.], [-1, 7], [8, 9]])
x.dot(y) # np.dot(x, y)

一个二维数组跟一个大小合适的一维数组的矩阵点积运算之后将会得到一个一维数组:
np.dot(x, np.ones(3))

@符(类似Python 3.5)也可以用作中缀运算符,进行矩阵乘法:
x @ np.ones(3)

numpy.linalg中有一组标准的矩阵分解运算以及诸如求逆和行列式之类的东⻄。它们跟MATLAB和R等语言所使用的是相同的行业标准线性代数库,如BLAS、LAPACK、Intel MKL(MathKernel Library,可能有,取决于你的NumPy版本)等:
from numpy.linalg import inv, qr
X = np.random.randn(5, 5)
mat = X.T.dot(X)
inv(mat) #
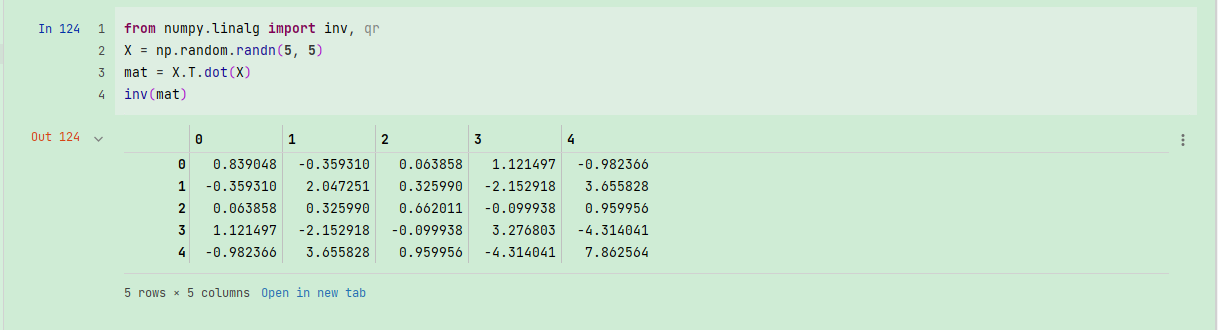
表达式X.T.dot(X)计算X和它的转置X.T的点积。
下表列出了一些最常用的线性代数函数:

2.6 伪随机数生成
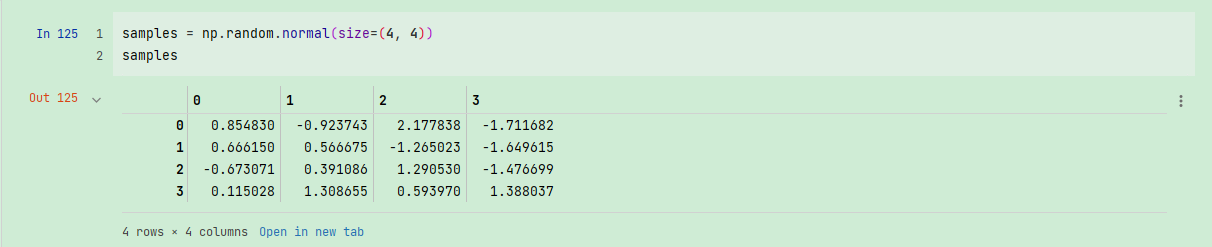
numpy.random模块对Python内置的random进行了补充,增加了一些用于⾼效生成多种概率分布的样本值的函数。例如,你可以用normal来得到一个标准正态分布的4×4样本数组:
samples = np.random.normal(size=(4, 4))
samples
我们说这些都是伪随机数,是因为它们都是通过算法基于随机数生成器种子,在确定性的条件下生成的。你可以用NumPy的np.random.seed更改随机数生成种子:np.random.seed(1234)
numpy.random的数据生成函数使用了全局的随机种子。要避免全局状态,你可以使用numpy.random.RandomState,创建一个与其它隔离的随机数生成器:rng = np.random.RandomState(1234)
下表列出了numpy.random中的部分函数: