文章目录
- 前言
- 常见概念总结
- 图的模拟实现
- 邻接矩阵和邻接表的优劣
- 图的模拟实现(邻接表)
- 广度优先遍历(BFS)
- 深度优先遍历(DFS)
前言
在聊图的结构之前,我们可以先从熟悉的地方开始,这有一条结论:树是一种特殊的图,图不一定是树。我们知道树形结构多用于搜索查找,典型的结构:搜索二叉树,红黑树和AVL树。在树的结构中,我们更侧重其存储的数据,你看,查找不就是判断给定的数据是否存储在结构中吗?因此,怎么快速的查找指定的数据就是树形结构的主要侧重问题。而图结构呢?它不侧重你存储了什么数据(因此它较少出现在需要快速查找某一元素的场景中,况且还有一个O(1)的哈希桶结构呢),它更侧重数据之间的关系,数据之间是否有联系?再看树形结构,双亲节点与子节点之间也有联系,这种联系通过一个指针体现,指针就是连接两个节点的“通道”。在图结构中,这样的用来连接的“通道”被强化成了边,节点在图结构中被称为顶点,顶点与顶点之间是否有边连接,是否有联系,这是图结构关心的问题。这条边甚至带有一个权值,用来表示顶点之间的某种关系的强弱。所以说,在树形结构中,“边”只是用来完成查找的工具,它是数据的附属,也是必要的,但不是主要的。但在图结构中,边的地位提升,成为结构中的主要部分,一张图需要保存一个顶点的集合(其存储了描述顶点的数据),还需要保存一个边的集合,可能还要表示边的权值。在模拟实现之前,先来认识几个图的概念
常见概念总结
图是由顶点及顶点间的关系构成的一种数据结构,G = (V, E)
顶点和边:节点在图中叫做顶点,连接顶点的是一条边
有向图和无向图:对于有向图,顶点对<x, y>是有序的,是指x->y,与<y, x>不同。对于无向图,顶点对(x, y)是无序的,是指x->y,y->x,与(y, x)相同
完全图:在n个顶点的无向图中,如果有n*(n - 1) / 2条边(即任意两顶点有且只有一条边的情况),则称此图为无向完全图。在n个顶点的有向图中,如果有n*(n - 1)条边(即任意两顶点有且仅有方向相反的两条边),则称此图为有向完全图
邻接顶点:对于无向图,如果边(u, v)是真实存在的一条边,则称u和v互为邻接顶点,边(u, v)依附于顶点u和v。对于有向图,如果<u, v>是真实存在的一条边,则称u 邻接到 v,v邻接自u,边<u, v>与顶点u和顶点v相关联
顶点的度:与树一样,顶点的度是指与顶点相关联的边的条数,对于有向图,顶点的度等于入度(以该顶点为终点的边的条数)+ 出度(以该顶点为起点的边的条数 ),对于无向图,顶点的度就是与其相关联的边的条数
路径:从顶点u出发,有一组边可以达到顶点v,则称这组边是u到v的路径
路径长度:对于无权的图来说,路径长度就是边的条数,对于有权的图来说,路径长度就是各边的权值相加
简单路径和回路:若路径上各顶点不重复,则称该路径是简单路径。如果第一个顶点与最后一个顶点重复,则称该路径是回路
子图:顶点或者边是原图的子集,则称该图是原图的子图
连通图:如果两顶点有路径相连(注意不是被边直接相连),则称两顶点是连通的,如果一张无向图中任意两顶点都是连通的,则称该图是连通图
强连通图:如果一张有向图的每一对顶点u和v,都存在一条从u到v的路径与一条从v到u的路径,则称该有向图是强连通图
生成树:对于无向图,一个连通图的最小连通子图称为该图的生成树。n个顶点的连通图的生成树有n个顶点和n-1条边
下面是一些图的逻辑结构

图的模拟实现
由于图结构侧重顶点之间的关系,所以顶点集合是结构的一个主体,我们用vector数组存储每个顶点的值,并使用模板参数V接收顶点的类型,但是顶点之间的关系要怎么表示呢?这有两种表示方法,一个是邻接矩阵,一个是邻接表。先说邻接矩阵,这是一个二维数组,数组的行和列分别代表一个顶点,由于行和列都是整数,所以它们表示的是顶点抽象后的整数(这一点与并查集很像)。因此我们需要保存每个顶点抽象后的整数,这里用unorder_ map存储<V, size_t>这样的键值对,first成员就是顶点的值,second成员是顶点抽象后的数组下标。顶点被抽象成数组的下标,这步操作使用者是不知道的,这是结构的内部细节,使用者只会传入顶点的值,如果此时需要操作邻接矩阵,我们就要注意顶点与下标之间的转换,需要先通过map表获取顶点的数组下标
接着说邻接矩阵,该二维数组的行和列分别对应了两个顶点,通过行和列就能锁定一个元素,该元素存储的值将表明两顶点之间是否相连,一般这个值是边的权重,如果图没有权重,我们就用某些特定值表示顶点是否相连,比如用1表示两顶点相连,用-1表示两顶点不相连。如果图有权重,我们也需要指定一个特定值,用它表示顶点间没有相连,比如整数的最大值。如果数组中u行v列存储的值不等于所指定的特定值,说明u顶点和v顶点相连。
有了大概的结构,我们来聊一下图的模板参数,首先顶点的值是一个泛型,我们用参数V表示,其次邻接矩阵保存的值是边的权重,权重也是一个泛型,并且还需要接收一个特定值以表示两顶点之间的不相连,最后需要一个bool变量表示该图为无向图还是有向图


然后是操作接口的实现,首先是构造函数,设计两个构造函数,一个是强制编译器生成的默认构造函数,它会调用自定义成员的默认构造,由于自定义成员都实现了默认构造,所以不会有成员为初始化的问题。还有一个构造是,使用者传入一个顶点的集合,我们调用add_tex依次添加顶点,最后再初始化邻接矩阵。

接着是add_tex接口,该接口将接收的顶点值添加到顶点集合vector和映射表unordered_map中,并且被构造函数复用。需要注意的是不要添加相同的顶点值

然后是要进入邻接矩阵前,对顶点进行的抽象整数获取的接口get_index,我们需要用unordered_map中查找该顶点值并返回键值对中其对应的整数值。同样要注意顶点是否存在的判断,不存在返回-1
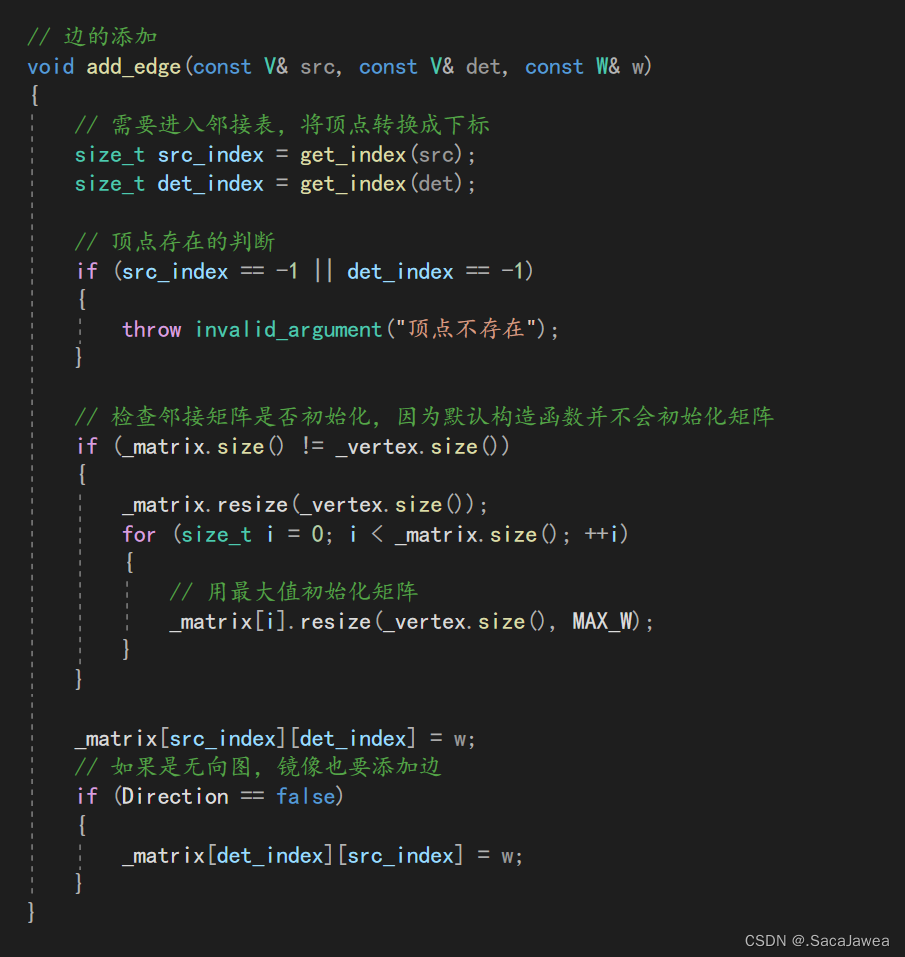
最后是边的添加,该接口接收两个顶点值,以及连接两顶点的边的权值。首先也是要判断两顶点是否存在:通过get_index达到顶点的下标,判断两下标中是否存在-1,如果存在-1说明有顶点不存在,需要抛异常。接着是邻接矩阵的进入,通过获取的两个下标,锁定邻接矩阵的一个元素(在此之前判断邻接矩阵是否有足够的空间,因为默认构造函数不会为邻接矩阵开辟足够的空间),将它的值修改为接收到的权值。此时还要注意图是否是无向图,如果是,我们还需要修改对称的元素,比如(u, v)和(v, u)两个元素都要修改
#pragma once
#include <iostream>
#include <vector>
#include <unordered_map>
using namespace std;
template <class V, class W, W MAX_W, bool Direction = false> // 默认无向图
class graph
{
public:
graph() = default;
graph(const V* arr, size_t n)
{
_vertex.reserve(n);
for (size_t i = 0; i < n; ++i)
{
add_tex(arr[i]); // 将数组中的顶点依次添加到顶点集合和映射map中
}
// 对邻接矩阵的初始化,默认顶点间不相连
_matrix.resize(_vertex.size());
for (size_t i = 0; i < _vertex.size(); ++i)
{
_matrix[i].resize(_vertex.size(), MAX_W);
}
}
// 添加顶点的接口
void add_tex(const V& v)
{
auto ret = _index_map.find(v);
if (ret != _index_map.end()) // 如果顶点不存在则添加,否则抛异常
{
throw invalid_argument("顶点重复");
}
_index_map[v] = _vertex.size(); // 建立顶点与数组下标之间的映射
_vertex.push_back(v); // 将顶点添加到顶点集合
}
// 查找顶点在数组中的下标,如果找不到返回-1
size_t get_index(const V& v)
{
auto ret = _index_map.find(v);
if (ret == _index_map.end())
{
return -1;
}
return ret->second;
}
// 边的添加
void add_edge(const V& src, const V& det, const W& w)
{
// 需要进入邻接表,将顶点转换成下标
size_t src_index = get_index(src);
size_t det_index = get_index(det);
// 顶点存在的判断
if (src_index == -1 || det_index == -1)
{
throw invalid_argument("顶点不存在");
}
// 检查邻接矩阵是否初始化,因为默认构造函数并不会初始化矩阵
if (_matrix.size() != _vertex.size())
{
_matrix.resize(_vertex.size());
for (size_t i = 0; i < _matrix.size(); ++i)
{
// 用最大值初始化矩阵
_matrix[i].resize(_vertex.size(), MAX_W);
}
}
_matrix[src_index][det_index] = w;
// 如果是无向图,镜像也要添加边
if (Direction == false)
{
_matrix[det_index][src_index] = w;
}
}
// for test,邻接矩阵的打印
void print()
{
for (size_t i = 0; i < _matrix.size(); ++i)
{
for (size_t j = 0; j < _matrix.size(); ++j)
{
if (_matrix[i][j] == INT_MAX)
cout << "* ";
else
cout << _matrix[i][j] << ' ';
}
cout << endl;
}
}
private:
vector<V> _vertex; //保存顶点的集合
unordered_map<V, size_t> _index_map; // 保存顶点与数组下标之间的转化
vector<vector<W>> _matrix; // 邻接矩阵
};
除此之外,我还设置了print接口打印邻接矩阵的值,用来测试模拟实现的图结构,以下面的有向图为例,用我们实现的图结构常见一个和它一样的图,然后打印邻接矩阵判断图结构是否正确
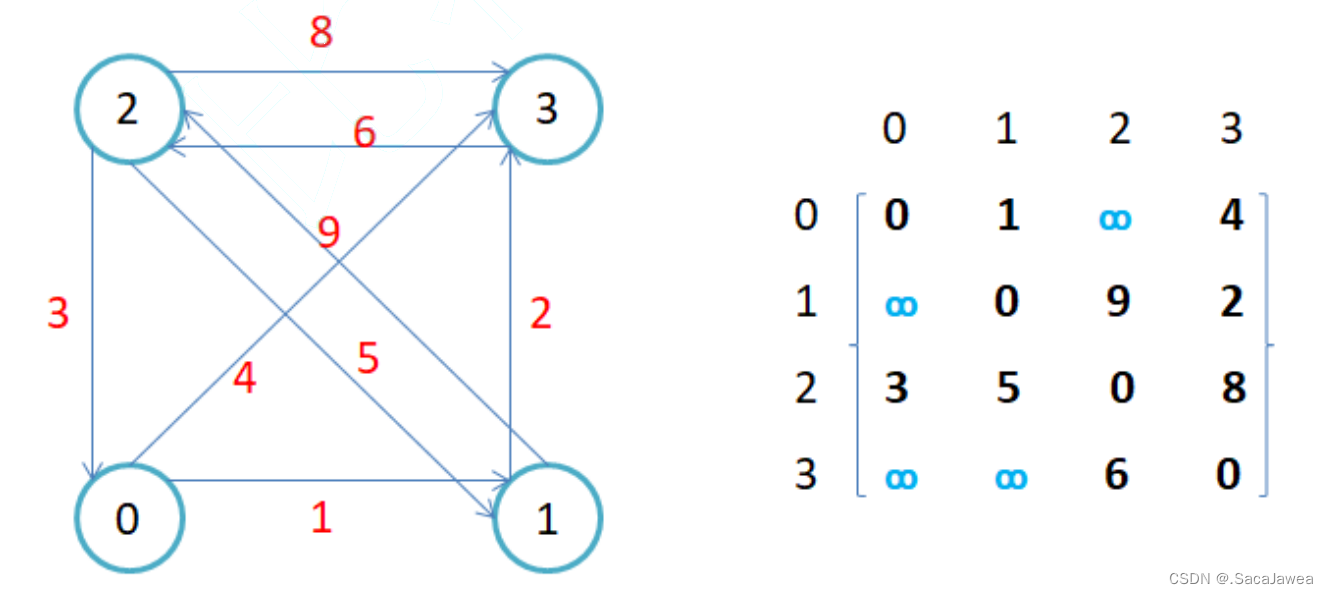
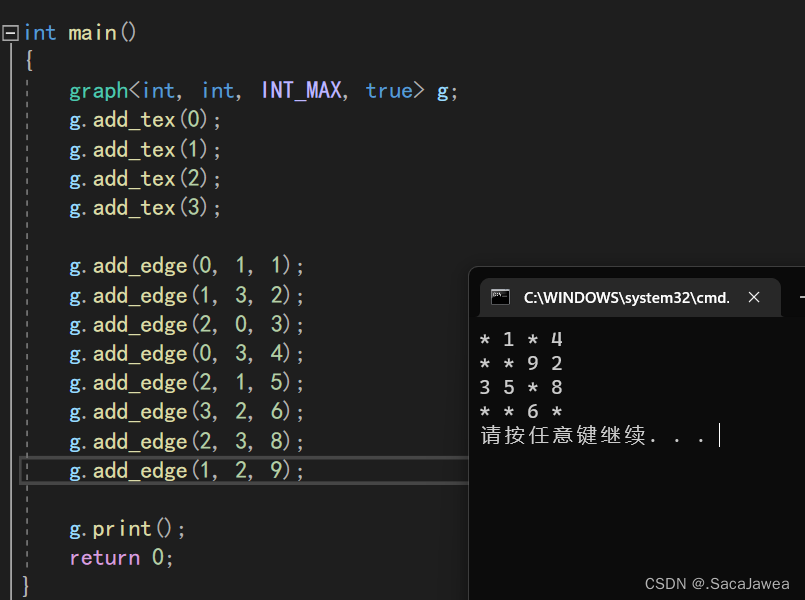
经过一些测试,以上结构没有出现严重的bug。至此图的基本结构就完成了
邻接矩阵和邻接表的优劣
刚才我实现的图是用邻接矩阵表示边之间的关系的,现在回头看邻接矩阵,我发现它需要接收一个特定值以表示顶点间的不相连,并且邻接矩阵是一个二维数组,如果一张图没有相连的顶点居多,那么这个二维数组存储的有效数据会很少,存储的数据都是表示顶点间不相连的特定值,一定程度上会造成空间的浪费。除了这个缺点呢,想要查找与一个顶点相连的所有顶点也优点费时,需要遍历数组的一行或者一列,复杂度达到O(n)。对于这些痛点,邻接表却可以很好的解决。
什么是邻接表呢?有点像哈希桶,它是一个指针数组,每个成员都是一个单链表的头指针,或者说这个单链表是与一个顶点相连的所有顶点的指针。哈希桶中,数据经过哈希函数的映射被抽象成了指针数组的下标,只要数据被抽象后的下标相同,它们就被存储在同一单链表中,链表的头指针被存储在了指针数组中,通过抽象后的下标就能在数组中找到链表的头指针。邻接表也是如此,只不过数据不经过哈希函数抽象成整数,而是被抽象成一个唯一的整数,这样的抽象关系被保存在一个map表中。但最后的结果都是数据被抽象成一个整数,每个顶点在邻接表中有了一个唯一的位置,用来存储与之相连的顶点指针
所以,使用邻接表保存顶点间的关系,可以不用接收一个特定值以表示顶点间的不相连,邻接表中的桶结构可以做到空间的按需分配,不浪费空间资源。而查找与一个顶点相连的所有顶点,只需要遍历一张单链表即可,复杂度为O(1),与图中的节点数无关。但邻接表也是有缺点的,比如快速判断了两个顶点是否相连,邻接矩阵可以用O(1)的复杂度得到答案,而邻接表却需要遍历单链表。至此,总结一下两者的优缺点,最后再用邻接表实现图结构
邻接矩阵,优点:
1.适合稠密图的顶点关系存储,不浪费空间
2.适合快速查找两顶点是否相连以及边的权值
缺点:不适合查找一个顶点的所有边
邻接表,优点:
1.适合稀疏图的顶点关系存储,节约空间
2.适合快速查找一个顶点的所有边
缺点:相对不适合查找两顶点是否相连以及边的权值
图的模拟实现(邻接表)
连接顶点的边,需要保存权值,需要保存边的终点(至于起点为什么不需要保存,因为起点已经被抽象成数组的下标,与该顶点连接的边都被存储在该下标下,可以保存但没有必要),最后还需要有一个指针域,指向下一个节点地址
struct edge_node
{
size_t _det; // 终点的下标
W _w; // 边的权值
edge_node* _next; // 下一个节点的地址
edge_node(size_t det, W w)
:_det(det)
,_w(w)
,_next(nullptr)
{}
};
vector<edge_node*> _tables; // 邻接表,保存edge_node的数组
接着是所有接口的实现,与邻接矩阵不同的是:构造函数和add_tex接口中对邻接矩阵的初始化需要修改为对邻接表的初始化,以及add_edge接口中,需要修改的不再是邻接矩阵而是邻接表,对矩阵中某个元素的修改变为对单链表的头插,具体的细节就看下面的实现吧
template <class V, class W, W MAX_W, bool Direction = false> // 默认无向图
class graph
{
private:
// 只保存边的终点
struct edge_node
{
size_t _det; // 终点的下标
W _w; // 边的权值
edge_node* _next; // 下一个节点的地址
edge_node(size_t det, W w)
:_det(det)
,_w(w)
,_next(nullptr)
{}
};
public:
graph() = default;
graph(const V* arr, size_t n)
{
_vertex.reserve(n);
for (size_t i = 0; i < n; ++i)
{
add_tex(arr[i]); // 将数组中的顶点依次添加到顶点集合和映射map中
}
// 对邻接表的初始化
_tables.resize(_vertex.size(), nullptr);
}
// 添加顶点的接口
void add_tex(const V& v)
{
auto ret = _index_map.find(v);
if (ret != _index_map.end()) // 如果顶点不存在则添加,否则抛异常
{
throw invalid_argument("顶点重复");
}
_index_map[v] = _vertex.size(); // 建立顶点与数组下标之间的映射
_vertex.push_back(v); // 将顶点添加到顶点集合
}
// 查找顶点在数组中的下标,如果找不到返回-1
size_t get_index(const V& v)
{
auto ret = _index_map.find(v);
if (ret == _index_map.end())
{
return -1;
}
return ret->second;
}
// 边的添加
void add_edge(const V& src, const V& det, const W& w)
{
// 需要进入邻接表,将顶点转换成下标
size_t src_index = get_index(src);
size_t det_index = get_index(det);
// 顶点存在的判断
if (src_index == -1 || det_index == -1)
{
throw invalid_argument("顶点不存在");
}
// 检查邻接表是否初始化,因为默认构造函数并不会初始化邻接表
if (_tables.size() != _vertex.size())
{
_tables.resize(_vertex.size(), nullptr);
}
// edge_node节点的构造
edge_node* new_edge = new edge_node(det_index, w);
// 将节点头插
new_edge->_next = _tables[src_index];
_tables[src_index] = new_edge;
// 如果是无向图,对方也要添加边
if (Direction == false)
{
edge_node* new_edge = new edge_node(src_index, w);
new_edge->_next = _tables[det_index];
_tables[det_index] = new_edge;
}
}
// for test,邻接表的打印
void print()
{
for (size_t i = 0; i < _tables.size(); ++i)
{
cout << '[' << i << "]->";
edge_node* cur = _tables[i];
while (cur)
{
cout << cur->_det << ' ';
cur = cur->_next;
}
cout << endl;
}
}
private:
vector<V> _vertex; //保存顶点的集合
unordered_map<V, size_t> _index_map; // 保存顶点与数组下标之间的转化
vector<edge_node*> _tables; // 邻接表
};
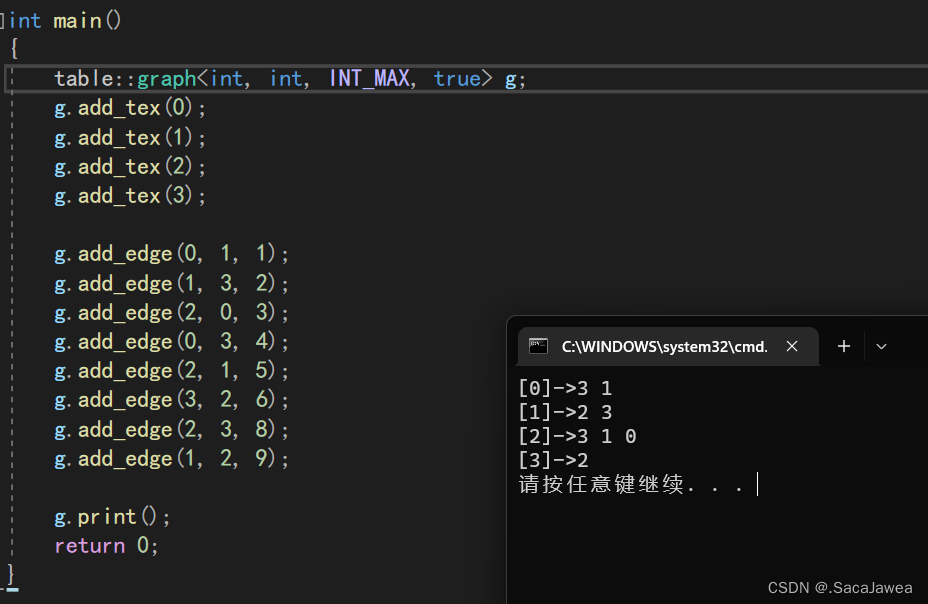
实现完成后,与邻接矩阵一样,选择一个例子进行测试,还是同样的例子,经过比较该模拟实现符合预期的逻辑,没有严重的问题
广度优先遍历(BFS)
图的广度优先遍历与二叉树的层序遍历很相似,都是先遍历与起始节点最近的节点,二叉树是先遍历节点的子节点,而图是优先遍历与顶点有直接的边的连接的顶点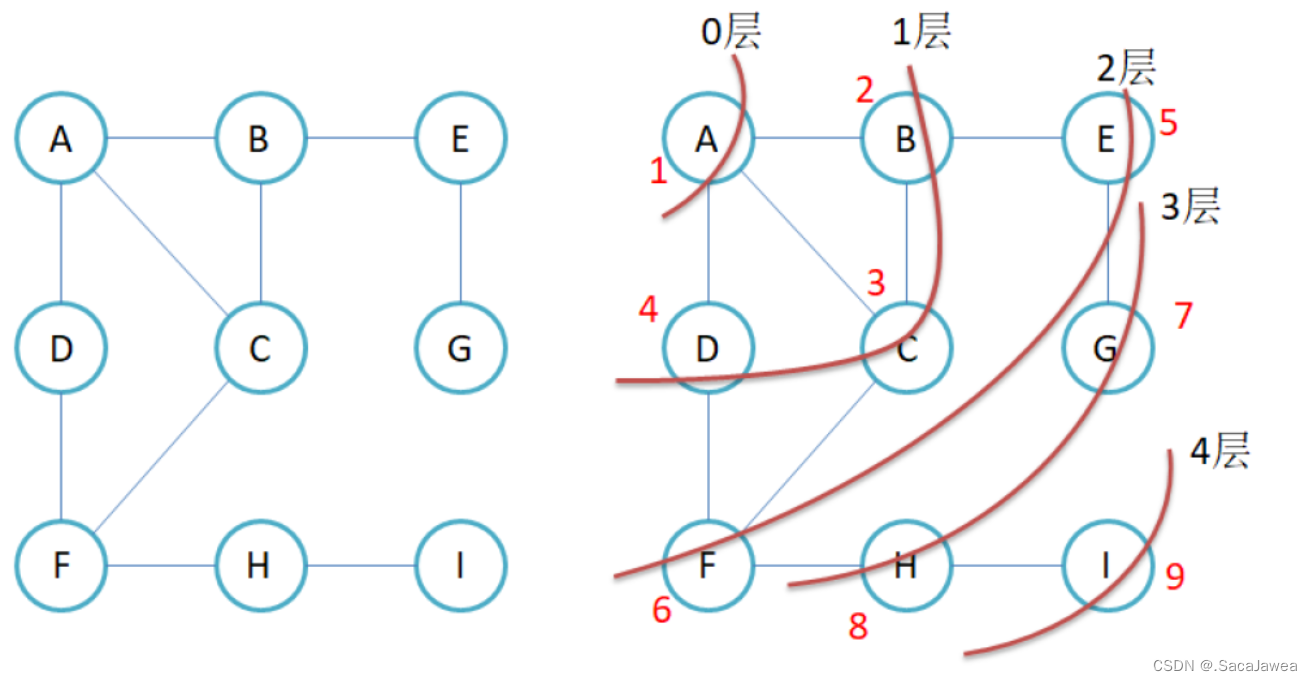
比如以A为起始顶点,先遍历的顶点是与A直接相连的顶点,B,C,D,接着再遍历与A次相连的顶点,也就是与B,C,D直接相连的顶点E,F…知道所有顶点遍历完。在这个过程中有一个问题,就是第二次遍历时,与B,C,D直接相连的顶点不止E,F,还有A顶点,但是这里不需要遍历A顶点了,所以我们需要给A顶点做一个标记,只有没有被标记顶点才会被遍历
我们可以创建一个bool数组,对应顶点的下标在数组中的值为true,说明顶点被遍历过,不需要遍历,只有数组中的值为false时,顶点才需要遍历。那么怎么控制程序遍历与A直接相连的顶点呢?可以遍历邻接表或者邻接矩阵,得到这些顶点。在遍历开始之前,将A存储到一个队列中,并在标记数组中将A标记为true,表示已经遍历过该顶点,然后取出队列中第一个数据,顶点A,对A进行遍历操作,遍历完成后将与A直接相连的顶点也存储到队列中,并在标记数组中将它们标记为true。接着取出队列中第一个数据,遍历,将与其直接相连的顶点入队,再出队,遍历顶点,入队…直到图被遍历完
void BFS(const V& v) // 根据节点的值进行广度优先遍历
{
// 先查找该顶点在矩阵中的下标
size_t src_index = get_index(v);
if (src_index == -1) // 顶点不存在直接返回
{
return;
}
// 标记数组与控制广度优先的队列的创建
vector<bool> visited(_vertex.size(), false);
queue<size_t> con_queue;
// 将起始顶点入队
con_queue.push(src_index);
// 标记数组的修改
visited[src_index] = true;
// 每一层的顶点数量,一开始当然是1了
size_t level_size = 1;
// 队列不为空,说明图中还有顶点没有遍历
while (!con_queue.empty())
{
// 一层一层的遍历
while (level_size--)
{
size_t cur_index = con_queue.front();
con_queue.pop();
// 这里是遍历操作,比如打印该顶点的值
cout << _vertex[cur_index] << ' ';
// 将与队头顶点直接相连的顶点入队
for (size_t i = 0; i < _matrix.size(); ++i)
{
// 遍历该顶点所在的行或者列,如果矩阵中的值不等于MAX_W就说明有顶点与之相连
// 当然还需要注意顶点是否被访问过
if (_matrix[cur_index][i] != MAX_W && visited[i] == false)
{
con_queue.push(i);
// 入队时记得修改标记数组
visited[i] = true;
}
}
}
cout << endl; // 打印格式的控制
// 每层顶点个数的控制
level_size = con_queue.size();
}
}
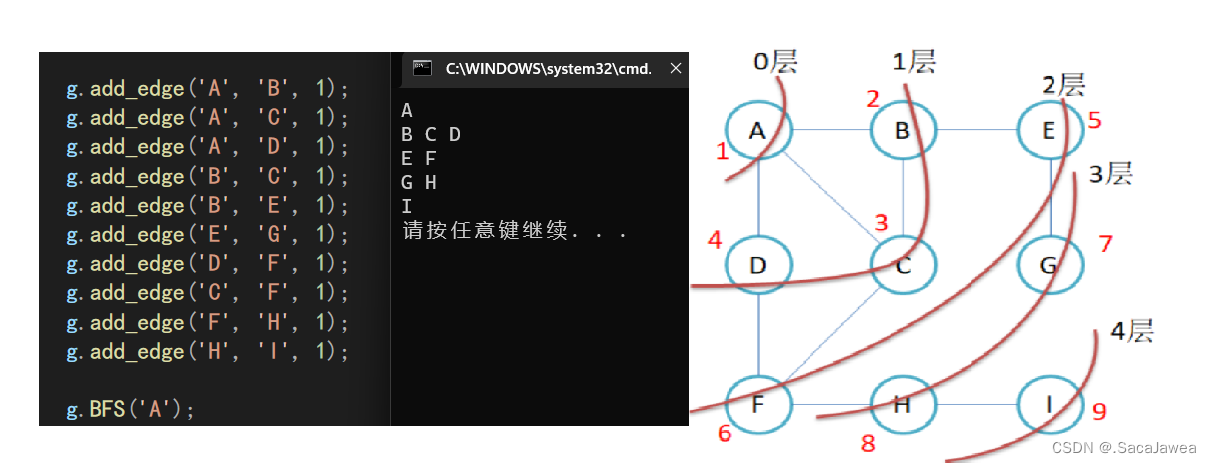
深度优先遍历(DFS)
这又有点像二叉树的前序遍历,它们的思想都是相同的:二叉树不断遍历子节点直到遇到根据才回溯,图的深度遍历就是不断遍历与当前顶点相连的节点,直到走到底无路可走。但是要注意的是,二叉树不会出现环路,但是图可以出现环路,所以深度优先也需要保存一个标记数组,记录访问过的顶点
与广度优先不同,深度优先需要不断的深入遍历节点,也就是将一条路径走到头,这样的特征使用栈结构。将起始顶点入栈,栈不为空,将栈顶元素出栈,将与其相连的其他顶点入栈,与队列不同,栈结构会先访问后入栈的元素,所以出栈时,得到的顶点是与当前遍历节点相连的一个节点,比如A出栈,B,C,D都会入栈,但是我们不会依次访问B,C,D而是只访问B,B将E入栈,程序再访问E…直到不能继续访问时,程序才会回溯,访问其他的顶点。当然了,这个过程也是要注意标记数组的修改,并且我们可以用天然的栈结构——函数栈帧,使用递归完成深度优先遍历
void _DFS(size_t cur_index, vector<bool>& visited)
{
// 对顶点的访问操作,这里直接打印
cout << _vertex[cur_index] << ' ';
// 查找与该顶点相连的顶点,并递归访问这些节点
for (size_t i = 0; i < _vertex.size(); ++i)
{
if (_matrix[cur_index][i] != MAX_W && visited[i] == false)
{
visited[i] = true;
// 顶点的递归访问,如果程序走到头了,将退回到上层递归函数
_DFS(i, visited);
}
}
}
void DFS(const V& v)
{
// 顶点的存在检查
size_t src_index = get_index(v);
if (src_index == -1)
{
return;
}
// 标记数组的创建,与起始点的修改
vector<bool> visited(_vertex.size(), false);
visited[src_index] = true;
// 子函数的调用
_DFS(src_index, visited);
}
程序运行结果,与上面图片的访问路径不同,因为深度优先遍历的路径不是唯一的
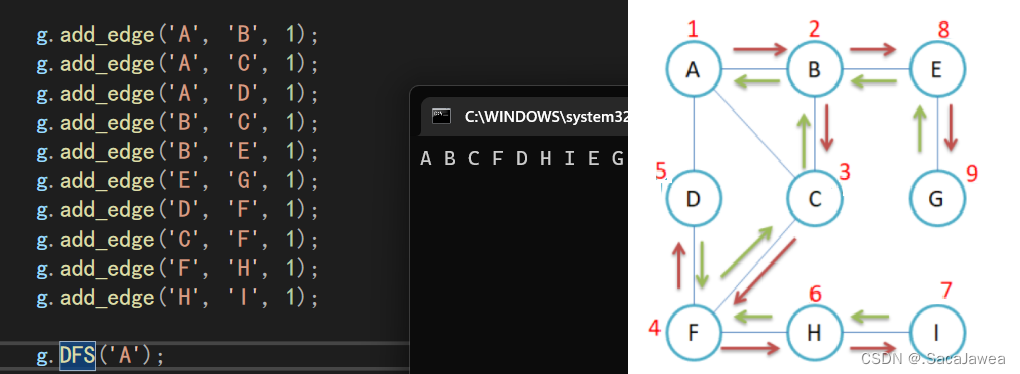
至此关于图的结构实现以及其基础算法的讲解结束



![[JavaWeb]HTML](https://img-blog.csdnimg.cn/f5e1d7dcd3f7460ca19d8d524c5ac9b5.png)




![[虾说IT]GIS与三高架构(一)什么是高性能](https://img-blog.csdnimg.cn/05c4711cc10044ba846bffa0c88609e5.png#pic_center)
![剑指 Offer 05. 替换空格 [C语言]](https://img-blog.csdnimg.cn/68bd8603db1d488e854e8a25f597e9f5.png)