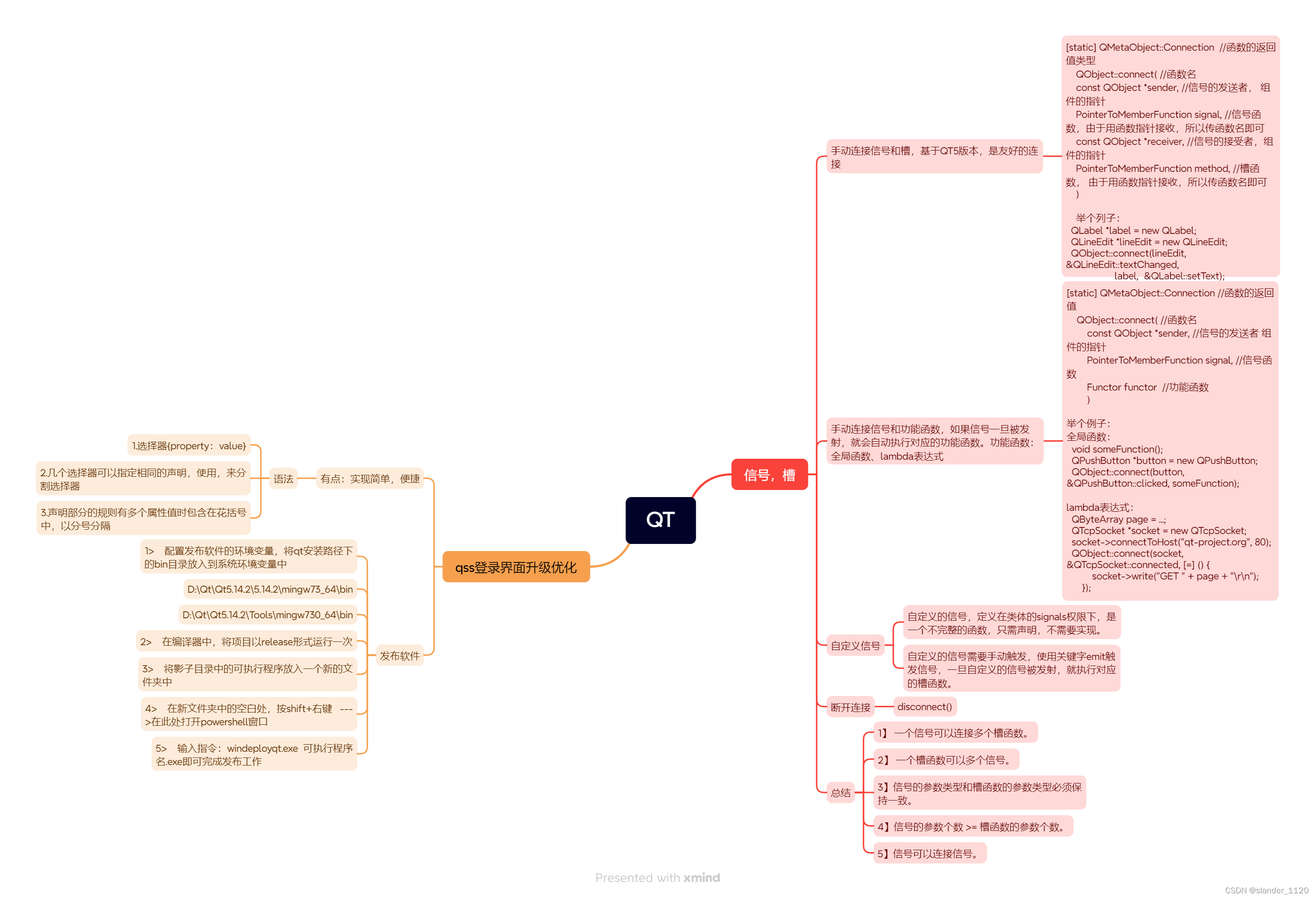
说明
发现对于异步(IO)还是太陌生了,熟悉一下。
内容
今天搞了一整天,感觉有一个long story to tell,但是不知道从何说起,哈哈。
异步(协程)需要保证链路上的所有环节都是异步(协程)的,任何一个环节没这么做都会导致整体的异步失效,退化为同步
以上大概是我能总结出的最核心的内容了。古早的时候(我还只是建模),我用python写了一个简单的规则引擎。这个引擎需要从各个库表(都是mysql)中读取一个客户的n个维度信息,然后用规则引擎给出判断。最初是用多个(大概20+)同步查询来逐个的完成数据获取,然后就必然的越来越慢,一个客户要一分钟才能完成数据准备。后来和当时的架构小哥商量了下,决定用asyncio + aiomysql来做,结果还是不错的,大概2~3秒不到就搞好了。而且机器使用资源没有多,反而是更少了,当时真是觉得惊艳。
在开发过程中,很多时候就是因为一连串的async def ,然后有任何一个环节没有async就会失败,所以很头痛,这也是印象深刻的地方。
总体上,IO并发用好了还是非常惊人的。究其原因,同步方式是比较自然的程序书写方式,有很多包已经为CPU密集型应用做了超多的应用。
客户端并发
首先我还是想排除掉多线程的方法,按道理讲协程的效率一定会高很多。虽然多线程用法看起来更容易理解,但我想还是用协程吧。
下面的几个函数分为三层:最底下的是json_query_worker,它是真正发起并发请求的异步函数,上面一层是json_player,它负责把多个异步任务进行封装和发布,然后回收任务结果。json_player的定义本身更像是place holder,他们只有被asyncio.run触发时(或者用run_until_complete)才会真正执行。make_json_task_list是更上一层,将用户端的请求,按照格式进行准备。
import asyncio
import aiohttp
import json
async def json_query_worker(task_id = None , url = None , json_params = None, time_out = 60, semaphore = None):
try:
async with semaphore:
async with aiohttp.ClientSession() as session:
async with session.post(url, json = json_params, timeout=aiohttp.ClientTimeout(total=time_out)) as response:
res = await response.text()
return {task_id: json.loads(res)}
except Exception as e:
# Return a dictionary with the error message
print(e)
return {task_id:'error'}
async def json_player(task_list , concurrent = 3):
semaphore = asyncio.Semaphore(concurrent) # 并发限制
tasks = [asyncio.ensure_future(json_query_worker(**x, semaphore = semaphore)) for x in task_list]
return await asyncio.gather(*tasks)
# 根据 url 和 params 构造任务请求列表 - tuple_list = [(url,params)]
# 模式A: 面向相同的url, 参数列表需要分为批次
def make_json_task_list(url = None, params_list = None):
task_list = []
for i in range(len(params_list)):
tem_dict = {}
tem_dict['task_id'] = 'task_' + str(i).zfill(5)
tem_dict['url'] = url
tem_dict['json_params'] = params_list[i]
task_list.append(tem_dict)
return task_list
例如,假设要发起的请求是一个url+一个param(dict)来完成的,构造参数列表来模拟需要执行的多个请求,然后输入请求的url和param列表,然后通过make_json_task_list生成任务列表,最后通过asyncio.run来发起真正的并发。
params_list = [{f't{i}': i} for i in range(30)]
import time
tick1 = time.time()
some_task_list = make_json_task_list('http://localhost:8000/async_thread_test/', params_list =params_list)
# 使用 asyncio.run() 运行协程
res = asyncio.run(json_player(some_task_list, concurrent=30))
tick2 = time.time()
print(tick2-tick1)
服务端并发
因为我构造了大量的微服务,一些微服务之间是有依赖的。例如本次的实验,我需要向deepseek进行请求,我先构造了服务A,该服务是以单核方式启动的,做了一层封装,以便使用标准的url+param方式提交请求。
from openai import OpenAI
DeepSeekHandler_path = r'/deepseek/'
class DeepSeekHandler(tornado.web.RequestHandler):
def post(self):
request_body = self.request.body
some_dict = json.loads(request_body)
api_key = some_dict['api_key']
model = some_dict['model']
messages = some_dict['messages']
client = OpenAI(api_key=api_key, base_url="https://api.deepseek.com/v1")
response = client.chat.completions.create(
model=model,
messages=messages)
res_content = response.choices[0].message.content
msg_dict = {}
msg_dict['content'] = res_content
self.write(json.dumps(msg_dict))
DeepSeekHandler_tuple = (DeepSeekHandler_path,DeepSeekHandler)
app_list.append(DeepSeekHandler_tuple)
然后在这里,我对服务进行调用。在客户端以asyncrun方式并发请求,然后我发现结果是串行的。原因有两个:一方面是接口本身是以同步方式创建的,另一方面服务器启动的时候只有单核。
结论: 在请求-返回的数据链中,只要有一个是同步的(deepseek),那么整个请求就是同步的。
我相信如果服务器开多核了,那么速度会按n被增长,但是这样是极其不经济的(但以前有一些服务还真可能就是这么干的)。同时也说明了使用异步,在IO方面可以给系统带来多大的提升。
所以接下来,在保持单核启动不变的情况(因为该服务就是进行api转发,根本不应该消耗cpu),修改服务为异步形式
import time
from concurrent.futures.thread import ThreadPoolExecutor
from tornado import gen, web, ioloop
from tornado.concurrent import run_on_executor
# 在http的层面异步
ADeepSeekHandler_path = r'/a_deepseek/'
class ADeepSeekHandler(web.RequestHandler):
executor = ThreadPoolExecutor(max_workers=1000)
@run_on_executor
def make_a_deepseek_request(self, url = None, api_key = None,model = None, messages = None):
print("adeepseek...start")
# for json -返回的就是json,不解开
client = OpenAI(api_key=api_key, base_url=url)
response = client.chat.completions.create(
model=model,
messages=messages)
res_content = response.choices[0].message.content
print("adeepseek...end")
return res_content
@gen.coroutine
def post(self):
request_body = self.request.body
print('Trying Decode Json')
some_dict = json.loads(request_body)
# print(some_dict)
url = some_dict['url']
api_key = some_dict['api_key']
model = some_dict['model']
messages = some_dict['messages']
res = yield self.make_a_deepseek_request(url = url, api_key = api_key, model=model, messages = messages)
msg_dict = {}
msg_dict['content'] = res
self.write(json.dumps(msg_dict))
ADeepSee_tuple = (ADeepSeekHandler_path,ADeepSeekHandler)
app_list.append(ADeepSee_tuple)
这里我有点每太明白的是为啥还要引入ThreadPoolExecutor,没有再深入去研究,但是看起来是在引用应用协程。我试着把max_workers设置到了1000,后来实测的时候,发现其实毫无压力。可能在第一次会耗费一点cpu,可能就10%左右,不到5秒,后面的cpu耗用几乎都为0.

然后下面是一个真实测试,花了我大约4毛钱调接口。
单个接口的调用:问一个问题,这个问题的回复通常在13秒±3秒。可以看到输入的token大约20,回复的大约200的样子。
import requests as req
some_dict = {}
some_dict['api_key'] = 'sk-xxx'
some_dict['model'] = "deepseek-chat"
some_dict['messages'] = [{'role':'user','content':'介绍三个北京必去的旅游景点。'}]
# 容器内
req.post('http://ty.orbitx.cn:24097/deepseek/',json=some_dict).json()
{'content': '北京作为中国的首都,拥有丰富的历史文化遗产和现代化的城市风貌,以下是三个必去的旅游景点:\n\n1. 故宫(The Forbidden City):故宫是明清两代的皇宫,也是世界上现存规模最大、保存最完整的木质结构古建筑群。它位于北京市中心,天安门广场北侧,是北京旅游的标志性景点之一。游客可以在这里欣赏到精美的古建筑艺术,了解中国古代皇室的生活和文化。\n\n2. 长城(The Great Wall):长城是中国古代伟大的军事防御工程,也是世界文化遗产之一。北京附近有多段长城可以游览,其中最著名的是八达岭长城和慕田峪长城。长城蜿蜒起伏,气势磅礴,是体验中国古代军事文化和壮丽自然风光的绝佳地点。\n\n3. 颐和园(The Summer Palace):颐和园是中国古典园林的代表之一,也是世界文化遗产。它位于北京西郊,是一座集山水园林和宫殿建筑于一体的大型皇家园林。颐和园以其精美的园林景观、丰富的历史文化内涵和宁静的自然环境吸引着众多游客。\n\n这三个景点不仅代表了北京的历史和文化,也是中国乃至世界的重要文化遗产,非常值得一游。'}
单个的异步请求,14.3秒
resp = req.post('http://xxx/a_deepseek/' , json = single_param).json()
{'content': '北京作为中国的首都,拥有丰富的历史文化遗产和现代化的城市风貌,以下是三个必去的旅游景点:\n\n1. 故宫(The Forbidden City):故宫是明清两代的皇宫,也是世界上现存规模最大、保存最完整的木质结构古建筑群。它位于北京市中心,占地约72万平方米,拥有超过9000间房间。故宫不仅是了解中国古代皇家生活和艺术的绝佳地点,也是联合国教科文组织认定的世界文化遗产。\n\n2. 长城(The Great Wall):长城是中国古代的军事防御工程,全长超过2万公里,其中最著名的部分位于北京附近,如八达岭长城、慕田峪长城等。长城蜿蜒起伏,雄伟壮观,是中国古代劳动人民智慧和勇气的象征,也是世界新七大奇迹之一。\n\n3. 颐和园(The Summer Palace):颐和园是中国清朝时期的皇家园林,以昆明湖和万寿山为基础,以杭州西湖为蓝本,汲取江南园林的设计手法而建成。颐和园集中国园林艺术之大成,是保存最完整的皇家行宫御苑,也是联合国教科文组织认定的世界文化遗产。\n\n这三个景点不仅代表了北京的历史和文化,也是中国乃至世界的重要文化遗产,是每一位来北京的游客都不容错过的。'}
直接从客户端发起并发请求,3条请求一共花了14.89s,所以是并发的。
param_list = [param1, param2, param3]
task_list = make_json_task_list('http://xxx/a_deepseek/', params_list=param_list)
res = asyncio.run(json_player(task_list, concurrent=30))
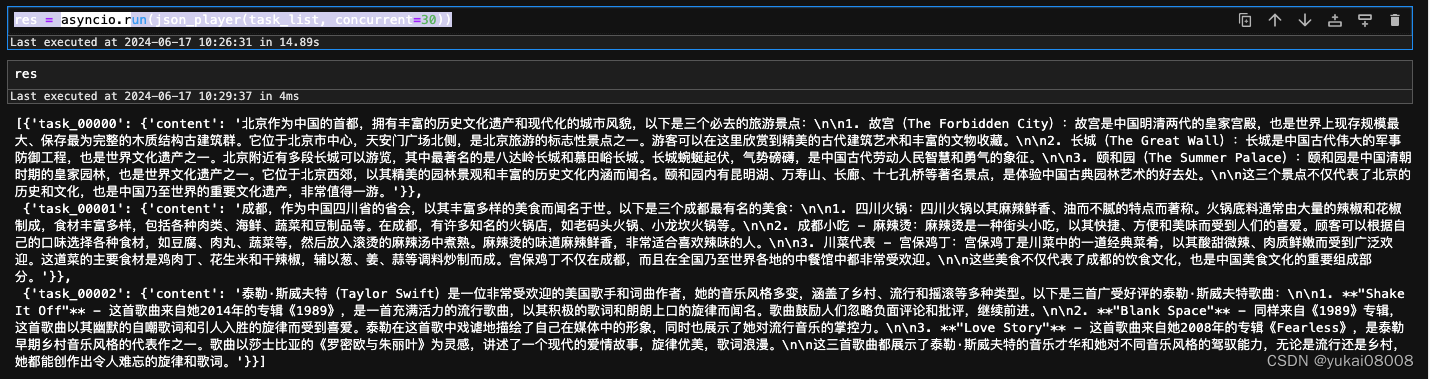
然后我之前还构造了另一个服务B,目的是屏蔽掉用户端对异步的感知,就像在调用一个接口。
对这个服务构造并发请求,外层的url是向tornado服务发起的并发,里面的url是每个请求需要执行的任务(url+param)。参数的构造多加了一层,最外层的url是本来客户端要请求的地址,里面的params对应请求需要的参数。
some_dict = {}
some_dict['url'] = 'http://xxx/a_deepseek/'
some_dict['params'] = {}
some_dict['params']['url'] = 'https://api.deepseek.com/v1'
some_dict['params']['api_key'] = 'xxx'
some_dict['params']['model'] = "deepseek-chat"
some_dict['params']['messages'] = [{'role':'user','content':'介绍三个北京必去的旅游景点。'}]
some_dict1 = {}
some_dict1['url'] = 'http://xxx/a_deepseek/'
some_dict1['params'] = {}
some_dict1['params']['url'] = 'https://api.deepseek.com/v1'
some_dict1['params']['api_key'] = 'xxx'
some_dict1['params']['model'] = "deepseek-chat"
some_dict1['params']['messages'] = [{'role':'user','content':"介绍三个成都最有名的美食。"}]
some_dict2 = {}
some_dict2['url'] = 'http://xxx/a_deepseek/'
some_dict2['params'] = {}
some_dict2['params']['url'] = 'https://api.deepseek.com/v1'
some_dict2['params']['api_key'] = 'xxx'
some_dict2['params']['model'] = "deepseek-chat"
some_dict2['params']['messages'] = [{'role':'user','content':"介绍三首泰勒斯威夫特好听的歌曲"}]
llm_param_list = [some_dict,some_dict1,some_dict2]
服务对应的部分如下,按照标准的url+params方式发起异步请求
# AsyncThreadMakeARequest -- ATMAR for json
ATMARHandler_path = r'/atmar/'
class ATMARHandler(web.RequestHandler):
executor = ThreadPoolExecutor(max_workers=1000)
@run_on_executor
def make_a_request(self, url = None, params = None ):
print("atmar...start")
# for json -返回的就是json,不解开
the_res = req.post(url, json = params).json()
print("atmar...end")
return the_res
@gen.coroutine
def post(self):
request_body = self.request.body
print('Trying Decode Json')
some_dict = json.loads(request_body)
print(some_dict)
url = some_dict['url']
params = some_dict['params']
res = yield self.make_a_request(url = url, params = params)
self.write(json.dumps(res))
ATMAR_tuple = (ATMARHandler_path,ATMARHandler)
app_list.append(ATMAR_tuple)
发起调用
tick1 = time.time()
some_task_list_1 = make_json_task_list('http://localhost:8000/atmar/', params_list =llm_param_list)
# 使用 asyncio.run() 运行协程
res = asyncio.run(json_player(some_task_list_1, concurrent=30))
tick2 = time.time()
print(tick2-tick1)
15.933489322662354

这说明了,只要链路上保证全部为异步,继续叠加异步调用,结果还是异步。当然传的次数越多,损耗会越大。主要的损耗来自序列化/反序列化的过程。
以并发300的速度发出300个请求,服务器的速度明显下降了,大约是原来的1/3~1/6, 所以估计每个账号至少可以并发30,最多并发50.
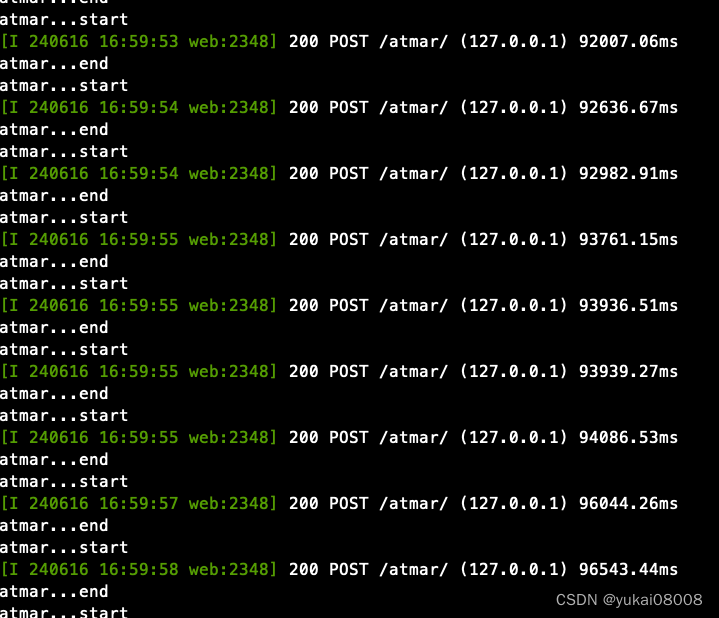
另两种tornado异步服务的搭建方式
反正看起来都是多线程,又有点协程的样子,不多研究了,体会一下就好
## 2 方式二:采用多线程+修饰器模式
import time
from concurrent.futures.thread import ThreadPoolExecutor
from tornado import gen, web, ioloop
from tornado.concurrent import run_on_executor
AsyncThread_testHandler_path = r'/async_thread_test/'
class AsyncThread_testHandler(web.RequestHandler):
executor = ThreadPoolExecutor(max_workers=1000)
@run_on_executor
def sleep(self):
print("休息1...start")
time.sleep(5)
print("休息1...end")
return 'ok'
@gen.coroutine
def post(self):
res = yield self.sleep()
self.write(json.dumps(res))
AsyncThread_test_tuple = (AsyncThread_testHandler_path,AsyncThread_testHandler)
app_list.append(AsyncThread_test_tuple)
看起来是断断续续的样子

另一种
executor = ThreadPoolExecutor(max_workers=30)
from tornado import gen, web, ioloop
# 方式三:采用ioloop,应该也就是协程方式
AsyncCoroutine_testHandler_path = r'/async_coroutine_test/'
class AsyncCoroutine_testHandler(web.RequestHandler):
def sleep(self):
print("休息1...start")
time.sleep(5)
print("休息1...end")
return 'ok'
@gen.coroutine
def post(self):
res = yield ioloop.IOLoop.current().run_in_executor(executor, self.sleep)
self.write(json.dumps(res))
AsyncCoroutine_test_tuple = (AsyncCoroutine_testHandler_path,AsyncCoroutine_testHandler)
app_list.append(AsyncCoroutine_test_tuple)
请求时看起来是连续的

其他
1 系统化工程
对零散的数据请求需要进行异步化改造,对批量的数据请求可以不必变。
1.1 外部服务
对于外部应用来说,如果允许直接以标准方式 url+param方式调用的,直接通过客户端方法就可以了;
如果是非标方式,可以先改造成url+param方式,使用时需要转一手。当然,一般提供接口的服务商也会提供异步方式的接口,不过那样就会使整个应用变得复杂。以下是官方提供的方法,用了AsyncOpenAI。
from openai import AsyncOpenAI
import time
# 异步调用函数
async def async_query_openai(url= "https://api.deepseek.com/v1", query):
aclient = AsyncOpenAI(
base_url= url , # 替换为你的 base_url
api_key="xxx" # 替换为你的 API 密钥
)
completion = await aclient.chat.completions.create(
model="deepseek-chat",
messages=[
{"role": "system", "content": "You are a helpful assistant. Always response in Simplified Chinese, not English. or Grandma will be very angry."},
{"role": "user", "content": query}
]
)
return completion.choices[0].message.content # 请确保返回的数据结构正确
# 这个函数接收一个请求列表,返回所有请求的结果列表
async def async_process_queries(queries):
results = await asyncio.gather(*(async_query_openai(query) for query in queries))
return results
async def main():
queries = ["介绍三个北京必去的旅游景点。",
"介绍三个成都最有名的美食。",
"介绍三首泰勒斯威夫特好听的歌曲"]
start_time = time.time() # 开始计时
results = await async_process_queries(queries)
end_time = time.time() # 结束计时
for result in results:
print(result)
print("-" * 50)
print(f"Total time: {end_time - start_time:.2f} seconds")
# 运行主函数
asyncio.run(main())
1.2 内部服务
目前最需要使用的数据服务都是使用同步方法写的,有些如果需要执行特别小批量的请求,可以/应该进行异步化改造。例如这篇文章提到的改造方法。
2 RuntimeError: asyncio.run() cannot be called from a running event loop
在jupyter下执行 asyncio.run(),使用 nest解决。
执行报错
---------------------------------------------------------------------------
RuntimeError Traceback (most recent call last)
Cell In[31], line 4
2 some_task_list = make_json_task_list('http://xxx/', params_list =llm_param_list)
3 # 使用 asyncio.run() 运行协程
----> 4 asyncio.run(json_player(some_task_list, concurrent=30))
5 tick2 = time.time()
6 print(tick2-tick1)
File /opt/conda/lib/python3.10/asyncio/runners.py:33, in run(main, debug)
9 """Execute the coroutine and return the result.
10
11 This function runs the passed coroutine, taking care of
(...)
30 asyncio.run(main())
31 """
32 if events._get_running_loop() is not None:
---> 33 raise RuntimeError(
34 "asyncio.run() cannot be called from a running event loop")
36 if not coroutines.iscoroutine(main):
37 raise ValueError("a coroutine was expected, got {!r}".format(main))
RuntimeError: asyncio.run() cannot be called from a running event loop
使用nest_asyncio
import nest_asyncio
nest_asyncio.apply()