1.湖仓一体
数据湖仓是 Flink 流批一体发挥重要作用的场景,使用 Flink + Paimon + starRocks 来构建湖仓一体数据分析.
Apache Paimon 是一个专为实时数据处理而设计的湖表格式,它最大的亮点是使用了 LSM Tree 技术。与 Hudi 相比,Paimon 在更新插入(Upsert)操作上速度快了4倍,查询扫描(Scan)速度也提高了10倍。这意味着它能提供更快的响应速度,同时降低数据入湖的成本,并且让开发者用起来更高效。Paimon 社区十分活跃,很多产品都在迅速与其兼容,这让它的生态系统发展得比其他湖库表格式更快、更全面。
StarRocks 是一款高性能分析型数据仓库,使用向量化、MPP 架构、CBO、智能物化视图、可实时更新的列式存储引擎等技术实现多维、实时、高并发的数据分析。StarRocks 既支持从各类实时和离线的数据源高效导入数据,也支持直接分析数据湖上各种格式的数据。StarRocks 兼容 MySQL 协议,可使用 MySQL 客户端和常用 BI 工具对接。同时 StarRocks 具备水平扩展,高可用、高可靠、易运维等特性。广泛应用于实时数仓、OLAP 报表、数据湖分析等场景。

Flink + Paimon + StarRocks 流式湖仓方案将 3 个产品做了非常紧密的结合,首先使用 Flink 流批一体计算引擎将数仓以 Paimon 格式在湖上构建,使用 Flink 完成数仓 ODS 到 DWD 层,DWS 和 ADS 的计算。通过使用 StarRocks 对各层数仓做统一的 OLAP 查询和 ADS 层在线分析。基于 Paimon 可以实现高吞吐入湖;基于 Flink 可以实现全链路的流批一体计算,基于 StarRocks 可以实现高性能的 OLAP 查询,所以整个链路从实时性、时效性、成本几个方面都可以取得比较好的平衡。
使用 StarRocks 统一管理数据湖和数据仓库,将高并发和实时性要求很高的业务放在 StarRocks 中分析,也可以使用 External Catalog 和外部表进行数据湖上的分析。StarRocks 从 3.1 版本开始支持 Paimon Catalog。
Paimon Catalog 是一种 External Catalog。通过 Paimon Catalog,您不需要执行数据导入就可以直接查询 Apache Paimon 里的数据。
在数据湖仓场景下,使用 Flink 可以完成复杂的数据拼接以及聚合计算,并且达到很高的实时性的要求。另外,实时链路在使用的过程中不可避免的会因为一些数据延迟等问题导致会有数据修正和数据回溯的需求。Flink 流批一体的特性能够让用户方便的使用与实时链路一样的作业代码,高效地完成数据修正和数据回溯的需求。
2.演示架构
通过flink-cdc 监听MySQL Binlog数据同步到Paimon ODS层,然后进行DWD数据清洗宽表打通,再到DWS层进行多维度汇总聚合,最后同ADS层进行数据呈现.其中用到streamPark进行作业编排.
2.1 组件使用版本
- flink1.18.1
- paimon0.8
- fink-cdc3.1
- streamPark2.1.4
- starRocks3.1
安装方式请自行安装
2.2 场景说明
在mysql创建3张表:用户表users,订单表orders,商品表products,订单详情表order_details
分析3个指标: 用户的总购买金额 产品的销售数量 用户的平均订单金额
在执行下面操作前,确保mysql,flink,streamPark,starRocks已经启动.
步骤一:准备演示数据
- 在MySQL中执行以下命令,创建数据表。
use emp;
-- 用户表
CREATE TABLE users (
user_id BIGINT AUTO_INCREMENT PRIMARY KEY COMMENT '用户ID,主键',
user_name VARCHAR(50) NOT NULL COMMENT '用户名',
email VARCHAR(100) NOT NULL COMMENT '邮箱',
registration_date DATE NOT NULL COMMENT '注册日期',
PRIMARY KEY (`user_id`) USING BTREE
) COMMENT '用户表';
INSERT INTO users (user_id, user_name, email, registration_date) VALUES (1, '张山', 'alice@example.com', '2023-01-15');
INSERT INTO users (user_id, user_name, email, registration_date) VALUES (2, '李四', 'bob@example.com', '2023-02-20');
INSERT INTO users (user_id, user_name, email, registration_date) VALUES (3, '刘博', 'charlie@example.com', '2023-03-10');
-- 订单表
CREATE TABLE orders (
order_id bigint AUTO_INCREMENT PRIMARY KEY COMMENT '订单ID,主键',
user_id INT NOT NULL COMMENT '用户ID,外键,关联到users表',
order_date DATE NOT NULL COMMENT '订单日期',
total_amount DECIMAL(10, 2) NOT NULL COMMENT '订单总金额',
PRIMARY KEY (`order_id`) USING BTREE
) COMMENT '订单表';
-- 演示数据
INSERT INTO orders (user_id, order_date, total_amount) VALUES
(1, '2023-04-01', 150.00),
(2, '2023-04-05', 200.00),
(3, '2023-04-10', 250.00),
(1, '2023-04-15', 300.00);
-- 商品表
CREATE TABLE products (
product_id bigint AUTO_INCREMENT PRIMARY KEY COMMENT '产品ID,主键',
product_name VARCHAR(100) NOT NULL COMMENT '产品名',
price DECIMAL(10, 2) NOT NULL COMMENT '产品价格',
PRIMARY KEY (`product_id`) USING BTREE
) COMMENT '产品表';
-- 演示数据
INSERT INTO products (product_name, price) VALUES
('笔记本', 50.00),
('手表', 75.00),
('耳机', 100.00);
-- 订单详情表
CREATE TABLE order_details (
order_detail_id bigint AUTO_INCREMENT PRIMARY KEY COMMENT '订单详情ID,主键',
order_id INT NOT NULL COMMENT '订单ID,外键,关联到orders表',
product_id INT NOT NULL COMMENT '产品ID,外键,关联到products表',
quantity INT NOT NULL COMMENT '购买数量',
subtotal DECIMAL(10, 2) NOT NULL COMMENT '小计金额(quantity * price)',
PRIMARY KEY (`order_detail_id`) USING BTREE
) COMMENT '订单详情表';
-- 演示数据
INSERT INTO order_details (order_id, product_id, quantity, subtotal) VALUES
(1, 1, 2, 100.00),
(1, 2, 1, 50.00),
(2, 1, 1, 50.00),
(2, 3, 2, 150.00),
(3, 2, 2, 150.00),
(3, 3, 1, 100.00),
(4, 3, 3, 300.00);
步骤二:mysql数据同步paimon
确保mysql已经开启binlog
1.编写flink-cdc同步任务,在flink-cdc的创建job文件夹,然后在里面创建mysql-to-paimon.yml
source:
type: mysql
name: MySQL Source
hostname: 192.168.1.72
port: 3306
username: root
password: dory@2022
tables: emp.users,emp.products,emp.order_details,emp.orders
server-id: 5401-5404
sink:
type: paimon
name: Paimon Sink
catalog.properties.metastore: filesystem
catalog.properties.warehouse: /opt/software/paimon
pipeline:
name: MySQL to Paimon Pipeline
parallelism: 1
- 在 flink-cdc的lib文件夹下添加:
flink-cdc-pipeline-connector-mysql-3.1.0.jar
flink-cdc-pipeline-connector-paimon-3.1.0.jar
mysql-connector-java-8.0.27.jar - 在保证flink集群启动的情况下,进行启动flink-cdc
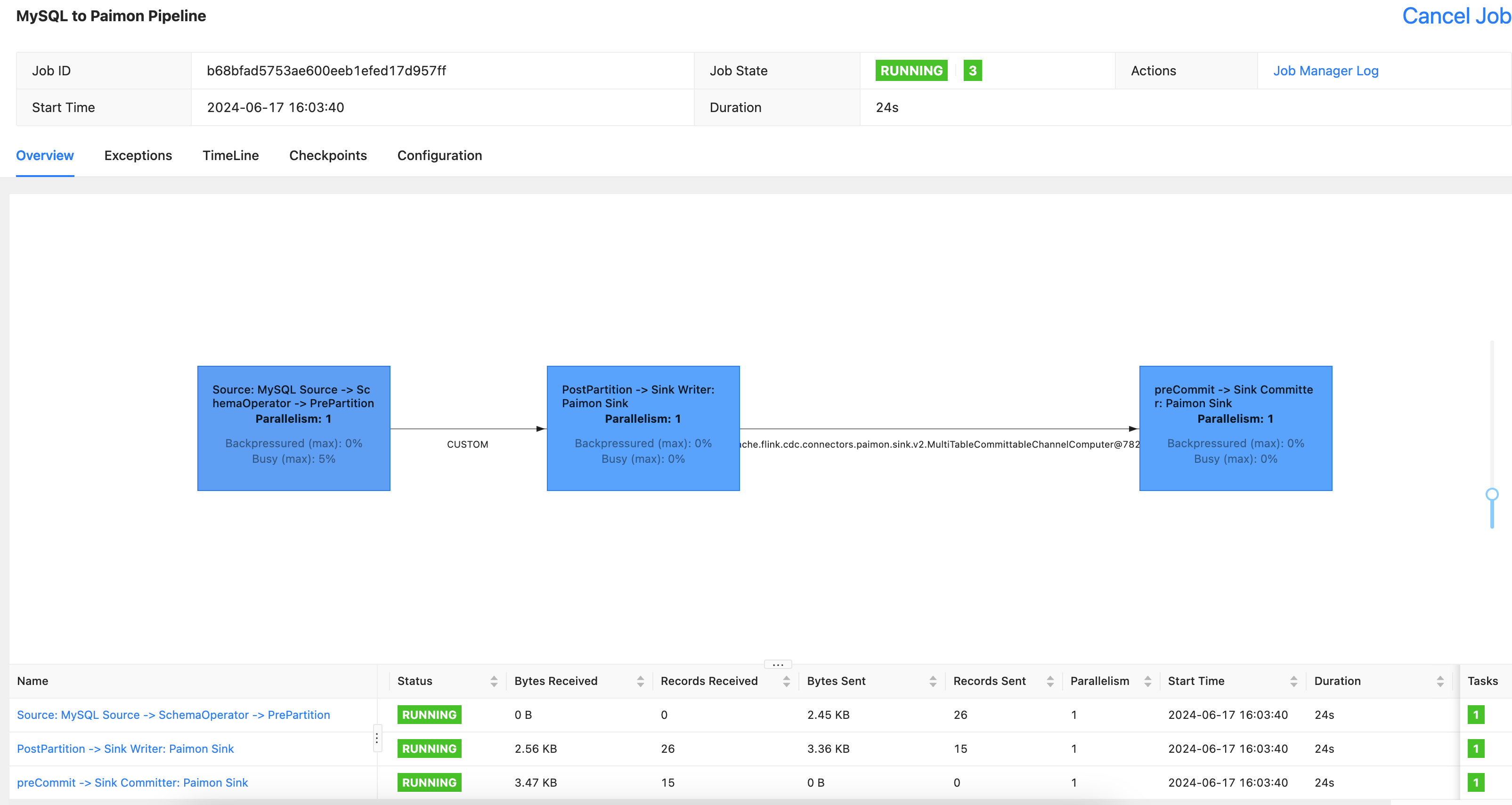
./bin/flink-cdc.sh job/mysql-to-paimom.yaml --jar lib/mysql-connector-java-8.0.27.jar
# 执行成功会出现jobid
Pipeline has been submitted to cluster.
Job ID: b68bfad5753ae600eeb1efed17d957ff
Job Description: MySQL to Paimon Pipeline
4.来到flink工作台进行查询任务
5.在服务器上查看同步文件信息
cd /opt/software/paimon/
cd emp.db/
ls
#显示已经同步过来
order_details orders products users
已经完成ODS层数据同步.
步骤三: DWD数据清洗宽表打通
1.打开streamPark,进行开始编写flink sql

SET 'execution.checkpointing.max-concurrent-checkpoints' = '3';
SET 'table.exec.sink.upsert-materialize' = 'NONE';
SET 'execution.checkpointing.interval' = '10s';
SET 'execution.checkpointing.min-pause' = '10s';
-- 创建CATALOG
CREATE CATALOG paimon_catalog WITH (
'type' = 'paimon',
'warehouse' = 'file:/opt/software/paimon'
);
-- 切换CATALOG
USE CATALOG paimon_catalog;
create DATABASE IF NOT EXISTS emp;
-- 切换database
use emp;
-- 创建dwd_user_orders表
CREATE TABLE IF NOT EXISTS dwd_user_orders (
order_id bigint,
user_id bigint,
user_name STRING,
order_date date,
total_amount decimal,
PRIMARY KEY (order_id) NOT ENFORCED
);
-- 创建dwd_orders_products_details表
CREATE TABLE IF NOT EXISTS dwd_orders_products_details (
order_detail_id bigint,
order_id bigint,
product_id bigint,
product_name STRING,
price decimal,
quantity bigint,
subtotal decimal,
PRIMARY KEY (order_detail_id) NOT ENFORCED
);
INSERT INTO
dwd_user_orders
SELECT
o.order_id,o.user_id,u.user_name,o.order_date,o.total_amount
FROM orders o join users u ON o.user_id=u.user_id;
INSERT INTO
dwd_orders_products_details
SELECT
d.order_detail_id,d.order_id,d.product_id,p.product_name,p.price,d.quantity,d.subtotal
FROM order_details d join products p ON p.product_id=d.product_id;
发布启动任务

flink-web-ui查看任务
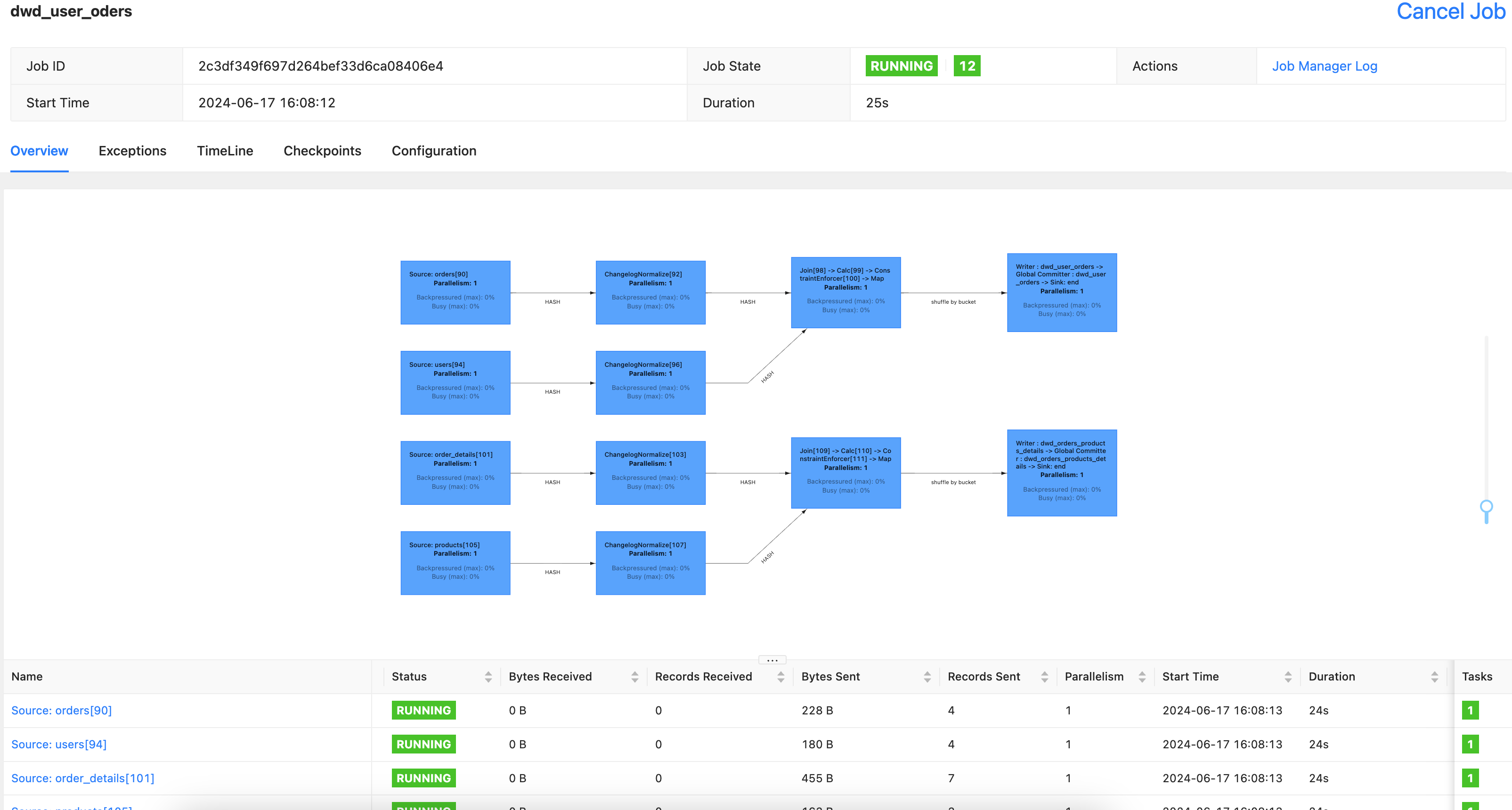
步骤三:进行维度分析
创建DWS层进行多维度汇总聚合,还是在streamPark编写DWS层任务
统计维度指标:
- 用户的总购买金额
- 产品的销售数量
- 订单的平均金额

SET 'execution.checkpointing.max-concurrent-checkpoints' = '3';
SET 'table.exec.sink.upsert-materialize' = 'NONE';
SET 'execution.checkpointing.interval' = '10s';
SET 'execution.checkpointing.min-pause' = '10s';
-- 创建CATALOG
CREATE CATALOG paimon_catalog WITH (
'type' = 'paimon',
'warehouse' = 'file:/opt/software/paimon'
);
-- 切换CATALOG
USE CATALOG paimon_catalog;
create DATABASE IF NOT EXISTS emp;
-- 切换database
use emp;
-- 创建用户的总购买金额表
CREATE TABLE IF NOT EXISTS dws_user_total_amount (
user_id bigint,
user_name STRING,
total_spent decimal,
PRIMARY KEY (user_id) NOT ENFORCED
);
-- 创建产品的销售数量
CREATE TABLE IF NOT EXISTS dws_product_sales_quantity (
product_id bigint,
product_name STRING,
total_quantity BIGINT,
PRIMARY KEY (product_id) NOT ENFORCED
);
-- 创建订单的平均金额
CREATE TABLE IF NOT EXISTS dws_order_average_amount (
order_id bigint,
average_order_amount decimal,
PRIMARY KEY (order_id) NOT ENFORCED
);
-- 用户的总购买金额
INSERT INTO
dws_user_total_amount
SELECT user_id,user_name, sum(total_amount) AS total_spent
FROM dwd_user_orders
group by user_id,user_name;
-- 产品的销售数量
INSERT INTO
dws_product_sales_quantity
SELECT product_id,product_name,SUM(quantity) AS total_quantity
FROM dwd_orders_products_details
group by product_id,product_name;
-- 订单的平均金额
INSERT INTO
dws_order_average_amount
SELECT order_id,AVG(total_amount) AS average_order_amount
FROM dwd_user_orders
group by order_id;
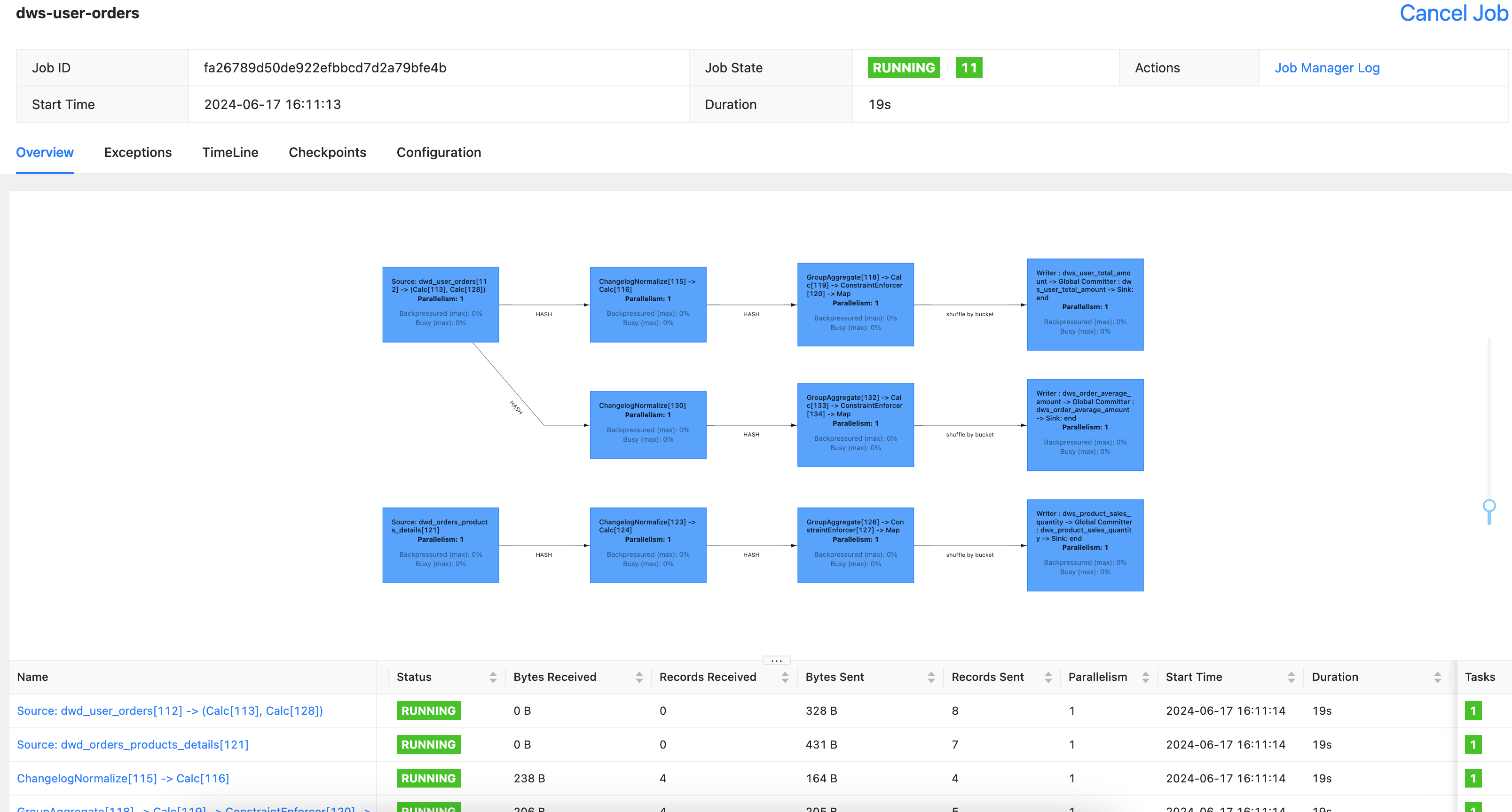
发布启动任务

flink-web-ui查看任务
步骤四:ADS查看维度结果数据
这里要使用starRocks进行查询paimon catalog数据表.在starRock 中paimon catalog是一种外部catalog.可以直接进行查询数据.
保证starRock正常启动.安装方式参考:https://www.cnblogs.com/freeweb/p/18137023
DBeaver连接上starRocks

查询对应维度数据
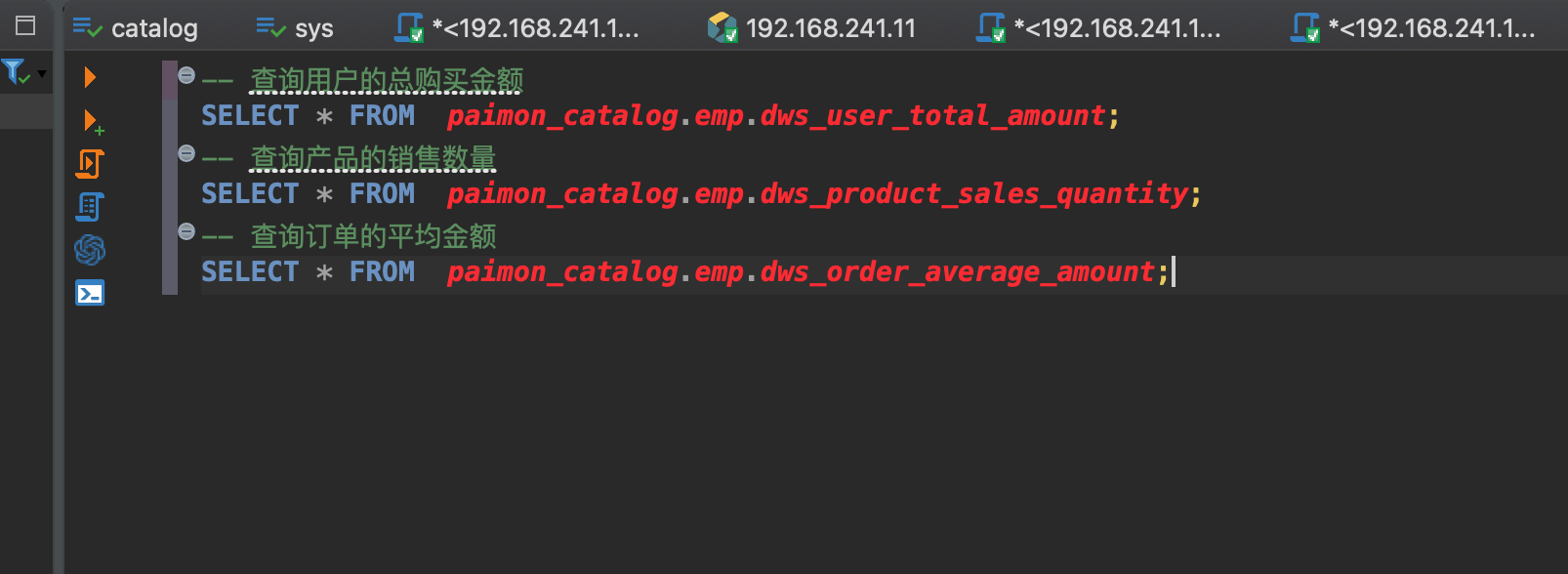
-- 查询用户的总购买金额
SELECT * FROM paimon_catalog.emp.dws_user_total_amount;
-- 结果
user_id|user_name|total_spent|
-------+---------+-----------+
1|张山 | 450|
2|李四 | 200|
3|刘博 | 250|
-- 查询产品的销售数量
SELECT * FROM paimon_catalog.emp.dws_product_sales_quantity;
-- 结果
product_id|product_name|total_quantity|
----------+------------+--------------+
1|笔记本 | 3|
2|手表 | 3|
3|耳机 | 6|
-- 查询订单的平均金额
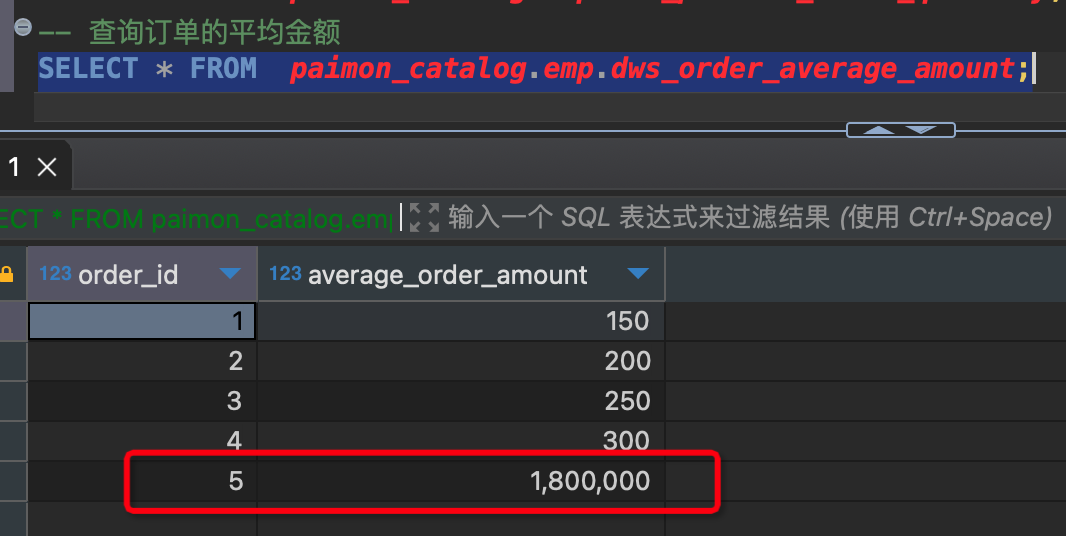
SELECT * FROM paimon_catalog.emp.dws_order_average_amount;
-- 结果
order_id|average_order_amount|
--------+--------------------+
1| 150|
2| 200|
3| 250|
4| 300|
步骤五: 演示数据实时更新
在mysql表进行修改数据查询维度表数据是否发生计算结果变更
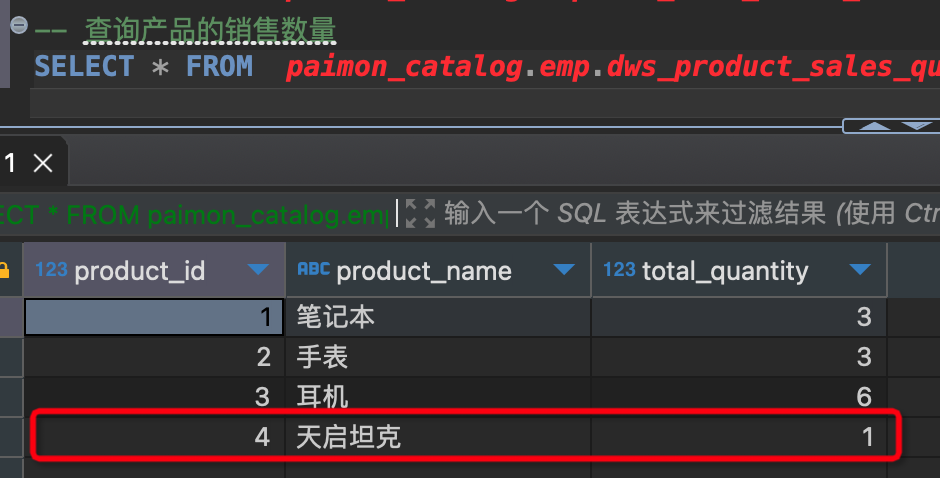
添加一条人员信息,产品信息,订单信息,订单详情信息,看维度表数据是否发生变化
- 在mysql中添加下面数据
INSERT INTO users (user_id, user_name, email, registration_date)
VALUES (4, '刘晓天', 'charlie@example.com', '2024-06-17');
INSERT INTO orders (order_id,user_id, order_date, total_amount) VALUES
(5,4, '2024-06-17', 1800000.00);
INSERT INTO products (product_id,product_name, price) VALUES
(4,'天启坦克', 1800000.00);
INSERT INTO order_details (order_id, product_id, quantity, subtotal) VALUES
(5, 4, 1, 1800000.00);
sleep 5s
- 查看维度分析结果,已经发生结果变化.
删除,修改mysql表同样会触发维度结果变化

![日本新入管法通过:2027年起实施[育成就劳]制度,新制度更适合外国劳工在日本工作和生活!](https://img-blog.csdnimg.cn/direct/b31318cbf74741ca98481e4551636e12.png)