0、概要
原理大致介绍了一下,后续会不断精进改的更加详细,然后就是代码可以对自己的数据集进行一个训练,还会不断完善,相应其他代码可以私信我。
一、论文内容总结
摘要:人们普遍认为,深度网络成功需要数千样本,在本文中,提出一种网络和训练方法,它使用大量数据增强来有效使用现存的样本,我们的体系结构由一个捕获上下文的收缩路径和能够实现精确定位的对称扩展路径组成。我们证明出这个网络可以使用少量图像进行端到端训练,并且在ISBI挑战赛上优先于先前的最佳方法(滑动窗口卷积)。并且我们的网络速度很快。
1介绍
目前卷积神经网络的具体用途是用在分类任务上,其中对图像的输出是一个单一的类标签。然而,在许多视觉任务中,特别是在生物医学图像处理中,所期望的输出应该包括定位(每个像素都应该分配一个类标签),另外,医学图像数目不是很多。因此,ciresan等人,在一个滑动窗口设置中训练一个网络,通过在每个像素周围提供一个局部区域(补丁)来预测每个像素的类标签,这个网络可以本地化,并且在当时效果还可以,但是这个网络的也有缺陷,很慢,每个网络必须在每个补丁单独运行,而且由于重叠的补丁,会有很多多余的预测,并且补丁的大小,也决定了预测的这个像素点所结合的上下文或者说是感受野的大小,而这个补丁不能太大也不能太小。所以这就是这个网络所存在问题。
而我们的网络,建立了一个更好的网络,所谓的全卷积网络,我们修改和扩展了这种体系结构,使它可以在很少的训练图像下,产生更精确的分割,网络结构如下图所示。
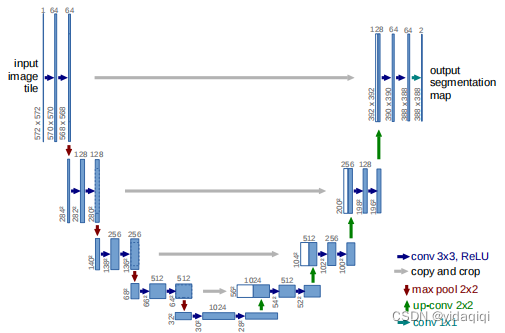
主要思想如下(1)编码器-解码器架构(Encoder-Decoder Structure):U-Net采用了经典的编码器-解码器设计。编码器部分通过一系列的卷积和池化操作对输入图像进行下采样,目的是提取出越来越抽象的特征表示。解码器部分则通过上采样操作(例如转置卷积)逐步将这些特征映射回原始输入的空间维度,以便进行像素级别的预测。
(2)跳跃连接:它允许将编码器路径中的特征图与相应解码器层的特征进行合并。具体来说,在每个上采样步骤之后,会将对应编码器层的输出与解码器的输出拼接在一起。这样做的目的是保留局部的精细结构信息,有助于恢复分割结果中的细节,因为编码器的早期层包含更多空间信息但语义信息较少。
(3)对称性:U-Net的结构在视觉上呈现为“U”形,体现了其编码器和解码器的对称性。这种对称不仅体现在网络结构上,也反映在处理图像信息的方式中,从特征提取到细节恢复的完整流程。
(4)端到端学习与像素级预测:U-Net能够直接在每个像素上进行类别预测,实现了端到端的学习,这对于图像分割任务尤为重要。网络的输出与输入图像大小相同,每个像素都有一个类别标签,适用于精确的图像分割任务。
(5)轻量级和高效性:
2、网络结构
从上图能很清晰的清楚结构,结果十分简单。
3、训练
利用输入图像及其相应的分割图,利用随机梯度下降来训练网络,由于当时还未有填充的卷积,因此输出图像比输入图像小了一个恒定的边界宽度。后边的一些解释大家可以代码过程,这里介绍起来不是很清楚。
4、数据增强
当只有少量的训练样本可用的时候,数据增强对于教会网络所需的不变性和鲁棒性是非常重要的,对于显微镜图像,我们主要需要位移和旋转不变性,以及对变形和灰度值变化的鲁棒性,而训练样本的随机弹性变形时训练一个很少标注图像的分割网络的观念概念。因此我们采用了相应的方法进行了数据增强。
二、代码结构+解释
一、工程文件中有一个文件夹叫model,里面含有两个文件夹,一个是unet_model,另一个是unet_parts,这两个用来定义模型结构。
(1)unet_parts.py 主要包含常用的一些块
""" Parts of the U-Net model """
"""https://github.com/milesial/Pytorch-UNet/blob/master/unet/unet_parts.py"""
import torch
import torch.nn as nn
import torch.nn.functional as F
# 导入torch相关库
class DoubleConv(nn.Module): # 继承pytorch中的nn.Moudle类,该类用于构建神经网络中的双卷积块,利用两次连续的卷积操作增强特征表示能力,
"""(convolution => [BN] => ReLU) * 2"""
def __init__(self, in_channels, out_channels): # 初始化参数,设置输入特征图参数和输出而整体参数
super().__init__() # 调用父类的初始化方法,继承父类必要步骤
self.double_conv = nn.Sequential(
nn.Conv2d(in_channels, out_channels, kernel_size=3, padding=1), # padding=1来保持输出尺寸和输入相同
nn.BatchNorm2d(out_channels), # 批量归一化层(BN),加速训练过程,提高模型的稳定性和泛化能力。这里针对的是 out_channels 个通道。
nn.ReLU(inplace=True), # 应用ReLU激活函数,非线性地增加网络的表达能力
nn.Conv2d(out_channels, out_channels, kernel_size=3, padding=1),
nn.BatchNorm2d(out_channels),
nn.ReLU(inplace=True)
)
def forward(self, x):
return self.double_conv(x) # 返回处理后的输出章
# 旨在通过连续的卷积和非线性提取更高级别的特征表示
class Down(nn.Module): # 下采样模块
"""Downscaling with maxpool then double conv"""
def __init__(self, in_channels, out_channels):
super().__init__()
self.maxpool_conv = nn.Sequential(
nn.MaxPool2d(2), # 最大池化层
DoubleConv(in_channels, out_channels) # 卷积或者是下采样
)
def forward(self, x):
return self.maxpool_conv(x)
class Up(nn.Module): # 上采样模块
"""Upscaling then double conv"""
def __init__(self, in_channels, out_channels, bilinear=True): # 初始化参数,选择上采样方式(双线性插值或转置卷积)、定义内部组件。这里选用的是双线性插值来进行上采样
super().__init__()
# if bilinear, use the normal convolutions to reduce the number of channels
if bilinear:
self.up = nn.Upsample(scale_factor=2, mode='bilinear', align_corners=True)# 缩放因子为2,模式是对齐角落的选项
else:
self.up = nn.ConvTranspose2d(in_channels // 2, in_channels // 2, kernel_size=2, stride=2)
self.conv = DoubleConv(in_channels, out_channels) # 用于进一步处理上采样后的特征
def forward(self, x1, x2): # 上采样、尺寸调整以及特征融合
x1 = self.up(x1) # 上采样特征图
# input is CHW
# 计算x1和x2在高度和宽度上的插值
diffY = torch.tensor([x2.size()[2] - x1.size()[2]])
diffX = torch.tensor([x2.size()[3] - x1.size()[3]])
x1 = F.pad(x1, [diffX // 2, diffX - diffX // 2,
diffY // 2, diffY - diffY // 2]) # 对x1进行填充
x = torch.cat([x2, x1], dim=1) # 沿着维度进行拼接,实现特征融合
return self.conv(x)
class OutConv(nn.Module):
def __init__(self, in_channels, out_channels):
super(OutConv, self).__init__()
self.conv = nn.Conv2d(in_channels, out_channels, kernel_size=1) # 1*1卷积核降维
def forward(self, x):
return self.conv(x)(2)unet的网络结构,这里相对于原版的有一些更改的地方,代码也很简单
""" Full assembly of the parts to form the complete network """
"""Refer https://github.com/milesial/Pytorch-UNet/blob/master/unet/unet_model.py"""
import torch.nn as nn
import torch.nn.functional as F
from unet_parts import *
# 导入相关库
# 定义了一个完整的U-Net模型
class UNet(nn.Module):
def __init__(self, n_channels, n_classes, bilinear=True):
super(UNet, self).__init__()
self.n_channels = n_channels
self.n_classes = n_classes
self.bilinear = bilinear
self.inc = DoubleConv(n_channels, 64)
self.down1 = Down(64, 128)
self.down2 = Down(128, 256)
self.down3 = Down(256, 512)
self.down4 = Down(512, 512)
self.up1 = Up(1024, 256, bilinear)
self.up2 = Up(512, 128, bilinear)
self.up3 = Up(256, 64, bilinear)
self.up4 = Up(128, 64, bilinear)
self.outc = OutConv(64, n_classes)
def forward(self, x):
x1 = self.inc(x)
x2 = self.down1(x1)
x3 = self.down2(x2)
x4 = self.down3(x3)
x5 = self.down4(x4)
x = self.up1(x5, x4)
x = self.up2(x, x3)
x = self.up3(x, x2)
x = self.up4(x, x1)
logits = self.outc(x)
return logits
if __name__ == '__main__':
net = UNet(n_channels=3, n_classes=1)
print(net)二、数据集设定以及图像增强代码
第一个文件夹主要是对数据集进行处理的一个脚本,第二个就是数据集的一个样式或者说规则,在训练过程中,主要相关的代码就是utils中的dataset.py这个脚本,主要作用是根据data路径,然后对数据集进行预处理,翻转这些操作,代码如下所示
import torch
import cv2
import os
import glob
from torch.utils.data import Dataset
import random
class ISBI_Loader(Dataset):
def __init__(self, data_path):
# 初始化函数,读取所有data_path下的图片
self.data_path = data_path
self.imgs_path = glob.glob(os.path.join(data_path, 'Training_Images/*.jpg')) # 查找指定路径下的所有JPEG图片文件
# 表示在data_path路径下的Training_Images文件夹中寻找扩展名为.jpg的所有文件,glob.glob函数会遍历这个路径并且返回一个包含所有匹配文件路径的列表
def augment(self, image, flipCode):
# 使用cv2.flip进行数据增强,filpCode为1水平翻转,0垂直翻转,-1水平+垂直翻转
flip = cv2.flip(image, flipCode)
return flip
def __getitem__(self, index):
# 根据index读取图片
image_path = self.imgs_path[index]
# 根据image_path生成label_path
label_path = image_path.replace('Training_Images', 'Training_Labels')
label_path = label_path.replace('.jpg', '.png') # todo 更新标签文件的逻辑
# 生成对应标签图像的路径
# 读取训练图片和标签图片
# print(image_path)
# print(label_path)
image = cv2.imread(image_path) # 读进来后就是numpy数组了
label = cv2.imread(label_path)
image = cv2.resize(image, (512, 512))
label = cv2.resize(label, (512, 512), interpolation=cv2.INTER_NEAREST)
# 对于label的图像处理时候,明确采用最近邻插值方法来处理尺寸变化,确保标签图像在缩放过程中类别标签不发生模糊,保持其原有的清晰界限。
# 将数据转为单通道的图片
image = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY) # BGR转成二值图
label = cv2.cvtColor(label, cv2.COLOR_BGR2GRAY)
# 处理标签,将像素值为255的改为1
if label.max() > 1:
label = label / 255
# 随机进行数据增强,为2时不做处理,即
flipCode = random.choice([-1, 0, 1, 2])
if flipCode != 2:
image = self.augment(image, flipCode)
label = self.augment(label, flipCode)
image = image.reshape(1, image.shape[0], image.shape[1])
label = label.reshape(1, label.shape[0], label.shape[1])
return image, label
def __len__(self):
# 返回训练集大小
return len(self.imgs_path)
if __name__ == "__main__":
isbi_dataset = ISBI_Loader("data/train/")
print("数据个数:", len(isbi_dataset))
train_loader = torch.utils.data.DataLoader(dataset=isbi_dataset,
batch_size=2,
shuffle=True)
for image, label in train_loader:
print(image.shape)三、训练代码
这部分就是训练的一整个过程。大
from model.unet_model import UNet
from utils.dataset import ISBI_Loader
from torch import optim
import torch.nn as nn
import torch
from tqdm import tqdm
def train_net(net, device, data_path, epochs=40, batch_size=1, lr=0.00001):
# 加载训练集
isbi_dataset = ISBI_Loader(data_path)
per_epoch_num = len(isbi_dataset) / batch_size
train_loader = torch.utils.data.DataLoader(dataset=isbi_dataset,
batch_size=batch_size,
shuffle=True)
# 定义RMSprop算法
optimizer = optim.RMSprop(net.parameters(), lr=lr, weight_decay=1e-8, momentum=0.9)
# 定义Loss算法
criterion = nn.BCEWithLogitsLoss()
# best_loss统计,初始化为正无穷
best_loss = float('inf')
# 训练epochs次
with tqdm(total=epochs*per_epoch_num) as pbar:
for epoch in range(epochs):
# 训练模式
net.train()
# 按照batch_size开始训练
for image, label in train_loader:
optimizer.zero_grad()
# 将数据拷贝到device中
image = image.to(device=device, dtype=torch.float32)
label = label.to(device=device, dtype=torch.float32)
# 使用网络参数,输出预测结果
pred = net(image)
# 计算loss
loss = criterion(pred, label)
# print('{}/{}:Loss/train'.format(epoch + 1, epochs), loss.item())
# 保存loss值最小的网络参数
if loss < best_loss:
best_loss = loss
torch.save(net.state_dict(), 'best_model.pth')
# 更新参数
loss.backward()
optimizer.step()
pbar.update(1)
if __name__ == "__main__":
# 选择设备,有cuda用cuda,没有就用cpu
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
# 加载网络,图片单通道1,分类为1。
net = UNet(n_channels=1, n_classes=1) # todo edit input_channels n_classes
# 将网络拷贝到deivce中
net.to(device=device)
# 指定训练集地址,开始训练
data_path = r"D:\新建文件夹 (3)\VOCdevkit3000\VOCdevkit\VOC2007\data" # todo 修改为你本地的数据集位置
train_net(net, device, data_path, epochs=50, batch_size=4)
四、总结
大致可能有些粗劣的介绍了U-Net的相关原理,以及代码,给出的代码可以训练,如果有需要完整工程文件的可以私信我。有错误的地方希望批评指正,感谢感谢


![[Qt的学习日常]--常用控件2](https://img-blog.csdnimg.cn/direct/605bb5ecd58c41a39ebdf56e74854a3b.png)