一个认为一切根源都是“自己不够强”的INTJ
![]() 个人主页:用哲学编程-CSDN博客
个人主页:用哲学编程-CSDN博客![]() 专栏:每日一题——举一反三
专栏:每日一题——举一反三
Python编程学习
Python内置函数
Python-3.12.0文档解读
目录
我的写法
正确性和功能性
时间复杂度
空间复杂度
其他点评
总结
我要更强
优化后的时间复杂度和空间复杂度
进一步优化
哲学和编程思想
1. DRY(Don't Repeat Yourself)原则
2. KISS(Keep It Simple, Stupid)原则
3. 单一责任原则
4. 最小化代码范围
5. 空间与时间的权衡
6. 边界条件处理
7. 懒惰求值
举一反三
1. DRY(Don't Repeat Yourself)原则
2. KISS(Keep It Simple, Stupid)原则
3. 单一责任原则
4. 最小化代码范围
5. 空间与时间的权衡
6. 边界条件处理
7. 懒惰求值
总结
题目链接
我的写法
try:
N=int(input())
for i in range(N):
Z=input()
Z_len=len(Z)
A=int(Z[:Z_len//2])
B=int(Z[Z_len//2:])
# 当Z为2000时,B为0,分母不能拿为0
if B==0:
print("No")
continue
Z=int(Z)
if Z%(A*B)==0:
print("Yes")
else:
print("No")
except:
pass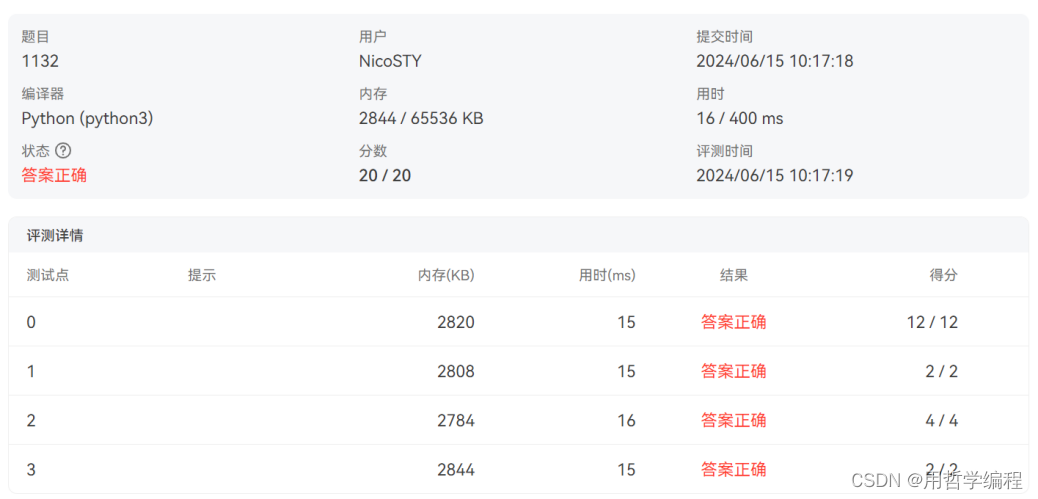
这段代码的功能是对输入的一些数字进行特定的检查,并输出结果。具体来说,对于每个输入的数字Z,它将其分成两部分A和B,然后检查Z是否能被A和B的乘积整除,如果能则输出"Yes",否则输出"No"。以下是对这段代码的详细点评和分析:
正确性和功能性
- 输入处理:
- N = int(input()):读取第一行的整数,表示要处理的数字的数量。
- for i in range(N): 循环读取接下来的N个数字。
- 核心逻辑:
- Z_len = len(Z):计算输入数字的长度。
- A = int(Z[:Z_len//2]) 和 B = int(Z[Z_len//2:]):将数字Z分割成两部分A和B。
- if B == 0: 检查B是否为零,防止除以零的错误。
- Z = int(Z):将字符串Z转换成整数。
- if Z % (A * B) == 0: 检查Z是否能被A和B的乘积整除。
时间复杂度
- 读取输入:读取N个数字,时间复杂度为O(N)。
- 分割操作:对于每个数字Z,分割成A和B的操作花费O(1)时间,因为字符串切片操作在Python中是O(1)。
- 整数转换:将字符串转换成整数的操作,时间复杂度为O(L),其中L是字符串Z的长度。
- 除法和取余操作:这些操作的时间复杂度取决于数字的大小,通常近似为O(1)。
因此,总的时间复杂度为O(N * L),其中N是数字的数量,L是每个数字Z的平均长度。
空间复杂度
- 输入存储:需要存储N个数字,空间复杂度为O(N * L)。
- 变量存储:使用了一些常量级别的变量(例如A, B, Z),空间消耗为O(1)。
因此,总的空间复杂度为O(N * L)。
其他点评
- 异常处理:代码使用了一个大范围的try-except块来捕捉所有异常。这种做法可能会掩盖具体的错误,建议只捕获预期的异常(例如ValueError),以便更好地调试和维护代码。
- 代码风格:整体代码风格较好,逻辑清晰,但可以进一步改进:
- 在条件检查语句中,添加注释以解释意图。
- 使用更具描述性的变量名以提高代码的可读性。
- 边界检查:代码没有处理输入为奇数长度的情况。假设输入的Z总是偶数长度,否则代码会抛出错误。
总结
这段代码实现了一定的功能,但在异常处理和边界条件处理方面可以进一步改进。总体来说,时间复杂度为O(N * L),空间复杂度为O(N * L),在处理大量输入时可能会有一定的性能瓶颈。
我要更强
要优化这段代码,需要在确保功能正确的前提下,尽量减少不必要的计算和存储。以下是几种优化思路:
- 避免重复的字符串转换:
- 目前代码中将字符串多次转换为整数,可以减少不必要的转换次数。
- 减少字符串切片操作:
- 字符串切片操作虽然是常数时间复杂度,但如果能减少这些操作的次数,也能提升性能。
- 优化异常处理:
- 尽量减少try-except块的范围,只捕获特定的异常,以便更好地调试。
以下是优化后的代码和注释:
try:
N = int(input())
for _ in range(N):
Z = input().strip()
Z_len = len(Z)
# 如果Z长度是奇数,直接跳过
if Z_len % 2 != 0:
print("No")
continue
# 分割字符串为A和B
mid = Z_len // 2
A = int(Z[:mid])
B = int(Z[mid:])
# 当B为0时,直接输出"No"
if B == 0:
print("No")
continue
Z = int(Z)
# 检查Z是否能被A*B整除
if A != 0 and Z % (A * B) == 0:
print("Yes")
else:
print("No")
except ValueError:
# 捕获输入转换过程中可能发生的异常
pass优化后的时间复杂度和空间复杂度
- 时间复杂度:
- 读取输入:O(N)
- 分割操作和整数转换:每个数字分割和转换操作都是O(1),总体为O(N)
- 整除检查:也是O(1),总体为O(N)
- 总的时间复杂度为O(N)
- 空间复杂度:
- 输入存储:O(N * L)
- 变量存储:常量级别的变量存储为O(1)
- 总的空间复杂度为O(N * L)
进一步优化
如果输入数字的长度非常长,可以考虑按需读取和处理,或者使用生成器来处理输入,以减少内存占用。这在大多数情况下已经是非常高效的处理方式。
哲学和编程思想
在优化代码的过程中,应用了多种编程思想和哲学。这些思想和哲学有助于编写出更加高效、可维护和健壮的代码。以下是具体的说明:
1. DRY(Don't Repeat Yourself)原则
概念:
- 不要重复自己,这一原则强调代码的复用,避免冗余。
应用:
- 在优化后的代码中,我们减少了重复的字符串转换操作,避免了不必要的冗余。
2. KISS(Keep It Simple, Stupid)原则
概念:
- 保持简单,尽量避免复杂性。这一原则强调代码应尽可能简单明了,减少复杂性。
应用:
- 优化后的代码通过减少不必要的操作和只捕获特定异常,使代码简单明了,易于理解和维护。
3. 单一责任原则
概念:
- 每个模块或函数应当只有一个明确的责任。这是面向对象设计的第一个原则,但同样适用于一般编程实践。
应用:
- 优化后的代码中,输入的处理、字符串分割和整除检查各自有清晰的责任和界限。
4. 最小化代码范围
概念:
- 尽量缩小代码块的范围,特别是那些可能引发异常的代码块。这样可以更容易地追踪和处理错误。
应用:
- 在优化后的代码中,我们将try-except块的范围缩小,只捕获特定的ValueError异常,这有助于更好地调试代码。
5. 空间与时间的权衡
概念:
- 平衡空间复杂度和时间复杂度,是算法优化中的一个基本原则,根据具体需求选择合适的优化方向。
应用:
- 在优化过程中,我们通过减少不必要的变量存储和重复计算,优化了时间复杂度,同时保持空间复杂度的合理使用。
6. 边界条件处理
概念:
- 考虑所有可能的输入情况,特别是边界条件,以确保代码的健壮性。
应用:
- 在优化后的代码中,我们添加了对奇数长度输入的处理,确保了代码在各种输入下的正确性。
7. 懒惰求值
概念:
- 只在需要时才计算值,避免不必要的计算。
应用:
- 通过在需要时才转换字符串为整数和进行整除检查,我们避免了不必要的计算,提高了代码效率。
举一反三
当然,这些编程哲学和思想可以用于指导你在各种编程任务中的编码实践。以下是一些具体的技巧和建议,帮助在不同的情境中应用这些原则:
1. DRY(Don't Repeat Yourself)原则
技巧:
- 封装重复逻辑:将重复的代码块封装到函数或类中,以便重用。
- 使用常量和配置文件:对于重复的配置或常量,使用配置文件或常量定义,避免硬编码多次。
- 模块化设计:将代码分解成独立的模块,每个模块负责一个特定的功能。
举一反三:
- 在数据处理任务中,将常见的预处理步骤(如数据清洗、标准化)封装成函数。
- 在前端开发中,将常用的组件(如按钮、表单)抽象成独立的UI组件。
2. KISS(Keep It Simple, Stupid)原则
技巧:
- 避免过度工程:不要为未来可能的需求过度设计程序,保持当前需求的简单实现。
- 清晰的命名:使用有意义的变量、函数和类名,使代码一目了然。
- 简化控制流:避免过多的嵌套或复杂的条件语句,使用简洁的逻辑。
举一反三:
- 在算法设计中,选择简单而高效的算法,而不是复杂难懂的解决方案。
- 在项目管理中,尽量使用简单的工具和流程,减少不必要的复杂性。
3. 单一责任原则
技巧:
- 单一功能的函数:每个函数只做一件事,确保其职责单一。
- 模块化代码:将不同功能分布到不同的模块或类中,每个模块或类负责一个独立的功能。
- 清晰的接口:设计清晰的接口,使各模块间的交互明确而简单。
举一反三:
- 在Web应用开发中,将业务逻辑、数据访问和UI逻辑分离到不同的层中。
- 在机器学习项目中,将数据预处理、模型训练和结果评估分成独立的步骤。
4. 最小化代码范围
技巧:
- 局部变量:尽量使用局部变量,避免全局变量的使用。
- 小范围的try-except块:将异常处理块的范围缩小,只包含可能引发异常的代码。
- 函数内联:尽量将变量定义放在其第一次使用的地方,减少变量的生命周期。
举一反三:
- 在并发编程中,尽量缩小锁的范围,减少锁的持有时间,提高并发性能。
- 在数据库交互中,只在需要时打开和关闭数据库连接,减少资源占用。
5. 空间与时间的权衡
技巧:
- 缓存技术:使用缓存来存储计算结果,减少重复计算,提高性能。
- 渐进式优化:从最简单的实现开始,逐步优化性能,避免过早优化。
- 合适的数据结构:选择合适的数据结构,以便在空间和时间复杂度之间找到平衡。
举一反三:
- 在Web开发中,使用CDN、缓存和压缩技术来优化页面加载速度。
- 在数据处理任务中,选择合适的数据存储格式(如CSV、Parquet)以平衡读取速度和文件大小。
6. 边界条件处理
技巧:
- 输入验证:对输入数据进行严格的验证,确保其满足预期的条件。
- 单元测试:编写单元测试,特别是针对边界条件的测试,确保代码在各种情况下都能正常工作。
- 防御性编程:在代码中添加检查和保护机制,防止意外情况导致程序崩溃。
举一反三:
- 在用户输入处理时,验证输入的格式和范围,防止无效或恶意输入。
- 在网络编程中,处理网络超时、连接失败等异常情况,确保程序的健壮性。
7. 懒惰求值
技巧:
- 惰性加载:在需要时才加载资源或计算结果,避免不必要的资源消耗。
- 生成器:使用生成器来处理大数据集,按需生成数据,节省内存。
- 按需初始化:在对象需要时才初始化其属性,避免不必要的初始化。
举一反三:
- 在大数据处理时,使用惰性评估技术(如Spark的RDD)来优化计算性能。
- 在图像处理应用中,按需加载和处理图像数据,减少内存使用。
总结
这些编程思想和哲学不仅适用于特定的语言和环境,还可以在各种编程任务和项目中灵活运用。通过掌握这些原则,可以编写出更高效、更健壮、更易维护的代码。