几年前,我正在做一个业余项目。我想创建一个 Web 应用程序,推荐当地的特色景点,例如咖啡馆、书店或隐藏的酒吧。我的想法是在地图上显示用户触手可及的所有兴趣点。我的数据集中有数十万个点,我必须巧妙地过滤用户给定范围内的数据点。最简单的方法是计算用户与每个兴趣点之间的距离,并丢弃指定范围之外的所有点。尤其是对于像我这样的大数据集,这种方法通常会导致较长的处理时间。
当然,一定有更好的方法,因为响应时间在交互式应用程序中很重要。这时我遇到了数据结构 R 树。这些树用于快速空间访问和搜索。使用 R 树,我能够快速隔离靠近用户位置的兴趣点并将其显示在地图上。这使我的 Web 应用程序的响应时间大大提高——只需增加四行代码!
在本文中,我解释了什么是 R 树以及它们的工作原理。前两节以纽约市的街道树木为例进行了说明。第三节演示了如何在 Python 中使用此数据结构来加速地理空间数据处理程序。

NSDT工具推荐: Three.js AI纹理开发包 - YOLO合成数据生成器 - GLTF/GLB在线编辑 - 3D模型格式在线转换 - 可编程3D场景编辑器 - REVIT导出3D模型插件 - 3D模型语义搜索引擎 - Three.js虚拟轴心开发包 - 3D模型在线减面 - STL模型在线切割
1、分析纽约市的树木
假设我们被要求分析纽约市街区与树木健康状况之间是否存在相关性。纽约市开放数据门户提供了街道树木普查数据集,其中包括树种、直径、健康状况感知和每棵树的地理位置。
首先,我们要计算上东区的街道树木数量。下面的伪代码片段遍历数据集树木并检查树木是否位于 upper_east_side 边界内:
total_count, tree_count = 0, 0
for tree in trees:
total_count += 1
if upper_east_side.contains(tree):
tree_count += 1
print_results(num_tests=total_count, num_trees=tree_count)
>>> Total number of trees tested: 683,788
>>> Number of trees in Upper East Side: 8,807我们发现上东区大约有 9000 棵树。但是,为了达到这个目标,我们总共测试了 684000 棵树。下面的动画显示了我们测试的树木距离我们的目标街区有数英里远,因此很容易被忽略。但是,我们如何才能将远处的树木排除在昂贵的计算之外,以实现显着的性能提升?
我们几乎免费获得的一条信息是多边形的边界框(可以通过其节点的最小值和最大值确定)。此外,测试一个点是否落在矩形内很简单,只需要四个比较操作(该点必须大于或等于左下角,并且小于或等于右上角)。现在,假设 bounding_box 是一个数据集,其中包含上东区周围一个紧密矩形中的所有树木(在下一节中,我们将了解如何轻松获得这样的矩形)。考虑到这一点,得出:
total_count, tree_count = 0, 0
for tree in bounding_box:
total_count += 1
if upper_east_side.contains(tree):
tree_count += 1
print_results(num_tests=total_count, num_trees=tree_count)
>>> Total number of trees tested: 10,768
>>> Number of trees in Upper East Side: 8,807动画右侧显示我们现在只测试潜在候选者。这些是与多边形紧邻的树,即落在其边界框内的点。通过忽略远处的树,我们能够将测试次数从 684k 减少到 11k — 减少了 60 倍!在下一节中,我们将看到 R 树正是利用了这个想法。
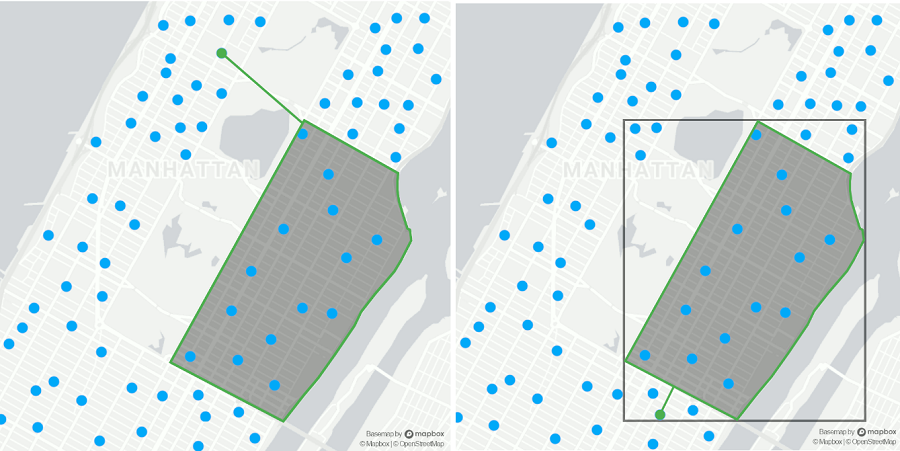
(左)纽约市的所有树木都经过测试 | (右)仅测试上东区边界框内的树木
2、用于空间搜索的数据结构
R 树是一种基于树的数据结构,用于高效地创建空间索引。R 树通常用于快速空间查询或加速最近邻搜索 [1]。一种常见的用例可能是存储兴趣点(例如餐馆、加油站、街道等)的空间信息。借助 R 树,可以快速检索距离某个位置一定距离内的所有兴趣点。作为回报,这些结果可以显示在地图或导航系统中。
R 树的基本思想很简单:树的叶节点保存空间数据,而分支节点对应于包含其所有子节点的最小边界框。通过这种结构,R 树将空间划分为矩形,随着树的增长,矩形会变得更加细化。下面的示例说明了这一点:
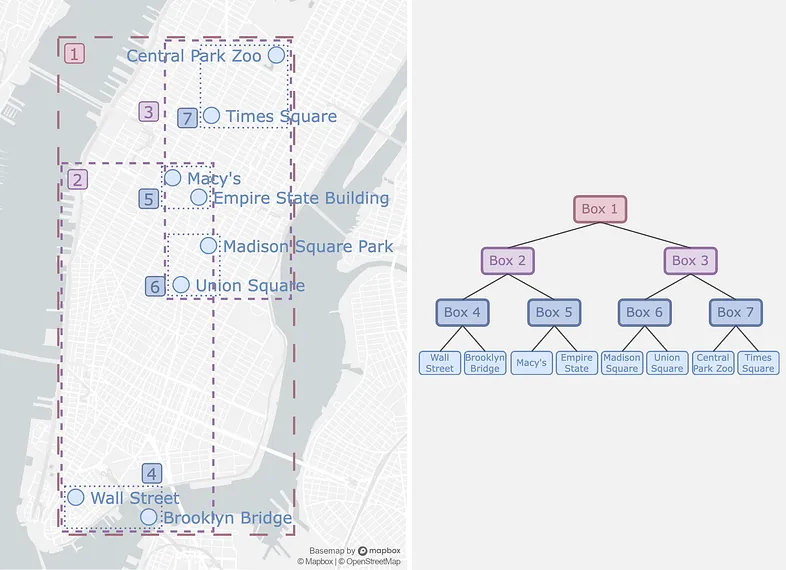
(左)R 树将曼哈顿划分为多个矩形 (右)相应的树结构
查询 R 树中的矩形,即我们想要检索此搜索窗口中包含的所有数据。请记住,每个非叶节点都对应一个包含其所有子节点的边界框。要完成搜索查询,我们只需沿着树的分支行进,并沿着与给定矩形相交的路径行进,直到到达叶节点。这些叶节点(因此我们的数据点)包含在搜索矩形中并满足查询。下面的动画演示了我们可以通过忽略不符合搜索条件的整个分支来大大减少搜索操作的数量。
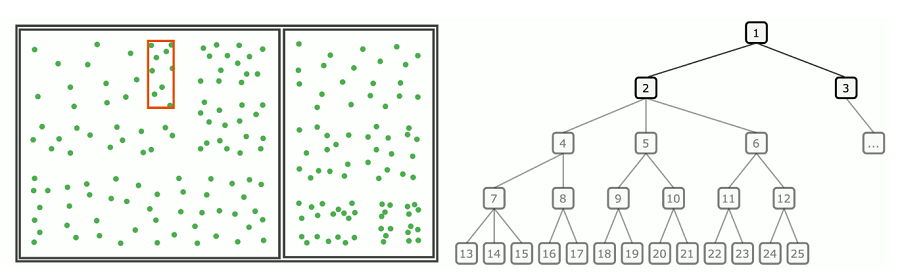
(左)与搜索矩形(红色)不相交的边界框(黑色)被迭代忽略 (右)
3、Python 中的 R 树
Python 包 Rtree 提供了 R 树数据结构的实现,并附带许多方便的功能,例如最近邻搜索、交集搜索或多维索引。
我们可以方便地使用 Python 的包管理器 pip 安装该包:
pip install Rtree3.1 基础知识
在处理点或多边形等几何图形之前,我们先介绍一下 Rtree 包的基本用法:
from rtree import index
idx = index.Index()
bbox_0 = (0.0, 0.0, 1.0, 1.0) # (left, bottom, right, top)
bbox_1 = (3.0, 3.0, 6.0, 6.0)
idx.insert(0, bbox_0)
idx.insert(1, bbox_1)索引模块帮助我们构建空间索引。此索引通过插入对象的边界框自动建立。边界框通过指定其左、下、右和上坐标来定义。请注意,我们将边界框与标识符一起插入(在上面的示例中为 0 和 1)。ID 将帮助我们在执行查询时识别边界框:
search_window = (-1.0, -1.0, 2.0, 2.0) # ex. 1
list(idx.intersection(search_window))
>>> [0]
search_window = (4.0, 4.0, 5.0, 5.0) # ex. 2
list(idx.intersection(search_window))
>>> [1]
search_window = (0.0, 0.0, 6.0, 6.0) # ex. 3
list(idx.intersection(search_window))
>>> [0, 1]
search_window = (1.01, 1.01, 2.0, 2.0) # ex. 4
list(idx.intersection(search_window))
>>> []查询给定矩形的索引,同样由其左、下、右和上坐标指定。交集方法的结果是搜索窗口内包含的对象的 ID(示例 1-3)。如果搜索窗口超出索引中的数据范围,则结果为空(示例 4)。类似地,我们使用最近方法来查找给定搜索窗口的 k 个最近对象:
k = 1
search_window = (1.01, 1.01, 2.0, 2.0)
list(idx.nearest(search_window, k))
>>> [0]3.2 使用点、线和多边形
在上一节中,我们了解了如何通过插入对象的边界框来构建索引。现在我们要继续使用点、线和多边形来表示这些对象。Shapely 包提供了一种在 Python 中处理此类几何图形的简单方法:
from shapely.geometry import Point, LineString, Polygon
point = Point(0, 0)
line = LineString([(1, 0), (2, 1)])
polygon = Polygon([(3, 0), (3, 1), (4, 1)])
idx = index.Index()
idx.insert(0, point.bounds) # bounds: (0.0, 0.0, 0.0, 0.0)
idx.insert(1, line.bounds) # bounds: (1.0, 0.0, 2.0, 1.0)
idx.insert(2, polygon.bounds) # bounds: (3.0, 0.0, 4.0, 1.0)上面,我们首先创建一个点、一条线和一个多边形。接下来,将这些对象的边界框插入到使用 ID 0、1 和 2 的索引中。现在我们查询索引以获取不同的搜索窗口:
search_window = (0.0, 0.0, 0.5, 0.5) # ex. 1
list(idx.intersection(search_window))
>>> [0]
search_window = (0.0, 0.0, 2.0, 1.0) # ex. 2
list(idx.intersection(search_window))
>>> [0, 1]
search_window = (0.0, 0.0, 4.0, 2.0) # ex. 3
list(idx.intersection(search_window))
>>> [0, 1, 2]
k = 1
search_window = (1.0, 0.0, 2.5, 1.5) # ex. 4
list(idx.nearest(search_window, k))
>>> [1]下图显示了几何形状和搜索窗口:
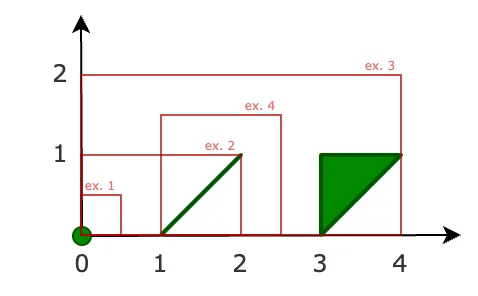
绿色:点、线和多边形。红色:搜索窗口
3.3 搜索上东区的所有树木
我们终于拥有了提取上东区所有树木所需的一切!我们将在下面介绍一段代码片段,但完整版本可在此处找到。
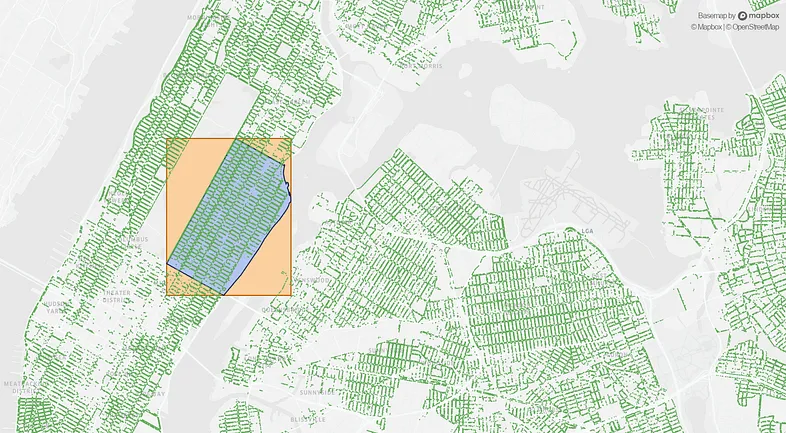
绿色:纽约市的树木。蓝色:上东区。橙色:上东区的边界框
首先,我们使用 GeoPandas 包加载所有必需的几何图形:
import geopandas as gpd
from rtree import index
df_trees = gpd.read_file('2015 Street Tree Census.geojson')
df_upper_east_side = gpd.read_file('upper_east_side.geojson')
geom_upper_east_side = df_upper_east_side.loc[0, 'geometry']接下来,我们创建一个包含纽约市所有树木的 R 树索引:
idx = index.Index()
for id, geom in zip(df_trees.index, df_trees.geometry):
idx.insert(id, geom.bounds)现在,我们生成一个潜在候选者列表,即上东区边界框内的所有树木:
search_window = geom_upper_east_side.bounds
potential = list(idx.intersection(search_window))最后,我们遍历所有潜在候选人,提取完全位于上东区的候选人:
trees = []
for tree in df_trees.loc[potential, 'geometry']:
if geom_upper_east_side.contains(tree):
trees.append(tree)
print_results(num_data=len(df_trees), num_tests=len(potential), num_trees=len(trees))
>>> Total number of trees in dataset: 683,788
>>> Total number of trees tested: 10,768
>>> Number of trees in Upper East Side: 8,8074、结束语
在本文中,我们了解了 R 树如何通过将底层空间划分为矩形来组织地理信息。这种结构使 R 树在空间查找方面非常快。在我们的纽约市街道树示例中,使用 R 树将操作数量减少了 60 倍。我们还了解了如何在 Python 中使用 R 树。在我们的示例中,仅用四行代码就实现了加速:初始化索引(1 行)、构建索引(2 行)以及使用交集函数查找附近的候选对象(1 行)。
那么为什么不到处都使用 R 树呢?虽然我们通过减少搜索操作数量来节省时间,但构建索引会浪费时间。对于后者,我们实际上必须遍历整个数据集。这使得 R 树不适用于只需要少量搜索的应用程序或索引经常更改的应用程序(因为树重新平衡)。
自 1984 年 Antonin Guttman 发明 R 树以来,R 树已经取得了长足的进步。如今,R 树已应用于各种应用,例如计算机图形学 、视频游戏 、交通控制系统 ,最突出的是空间数据管理数据库 。也许,你下一次进行地理空间数据分析时,R 树也会派上用场!
原文链接:用R树加速空间数据分析 - BimAnt