2024金地杯数学建模B题和金地杯数学建模D题32页论文和代码已完成,代码为B题D题全部问题的代码,论文包括摘要、问题重述、问题分析、模型假设、符号说明、模型的建立和求解(问题1模型的建立和求解、问题2模型的建立和求解、问题3模型的建立和求解、问题4模型的建立和求解、问题5模型的建立和求解)、模型的评价等等
完整代码和成品完整论文获取:↓↓↓↓↓
https://www.yuque.com/u42168770/qv6z0d/yb7pug63c2xyo412
摘要
本文针对土壤采样工作中的路径优化和任务分配问题,建立了一系列数学模型,并使用多种优化算法进行求解,以期在有限的时间和资源条件下,高效完成大量采样点的采样任务。首先,通过WGS-84参考椭球和墨卡托投影,将采样点的经纬度坐标转换为平面坐标,便于后续的建模和计算。其次,针对单日多点的采样路径优化问题,建立了TSP模型,并使用动态规划算法和遗传算法进行求解,得到了最优或近似最优的采样路径。再次,针对多日采样任务的分配问题,引入了k-means聚类算法和遗传算法,将采样点合理划分为若干个簇,并在每个簇内求解TSP问题,得到了每天的最优采样路径。接着,为了进一步优化任务分配,平衡每天的工作量,建立了整数规划模型,并使用分支定界法进行求解,得到了在工作时间约束下的最优任务分配方案。最后,考虑到实际道路网络和交通状况对采样效率的影响,利用第三方地图服务的路径规划API,获取了更加准确的距离和时间数据,并在此基础上建立了更加贴近实际的TSP模型,得到了考虑实际路况的最优采样路径。
在问题1的求解过程中,(后略,见完整版本)
在问题2的求解过程中,(后略,见完整版本)
在问题3的求解过程中,(后略,见完整版本)
在问题4的求解过程中,(后略,见完整版本)
关键词:土壤采样 路径优化 任务分配 旅行商问题 k-means聚类 遗传算法 整数规划

问题重述
土壤普查是确保国家粮食安全的基础工作之一。通过对耕地、园地、林地、草地等农用地和部分未利用地的土壤普查,可以全面对土壤进行“体检”,摸清土壤质量家底,准确掌握土壤资源情况,这对于保障粮食生产和守牢耕地红线至关重要。然而,面对偏远复杂的地理环境,如何在有限的时间与资源条件下,高效完成多个地点的土壤采样工作,成为一个亟待解决的问题。
现有XX地区成立土壤普查办公室,根据上级部门设定的土壤普查点位安排一个工作组进行土壤采样工作。办公室需要提前对工作组每天的土壤采样工作进行路径和任务规划。按照正常工作流程和进度,工作组的工作时间仅包括在点位工作的时间和点位之间切换路上通行的时间,但不考虑工作组从驻地到第一个点位和当天离开最后一个点位回到驻地的时间,即当天来第一个工作点位之前和最后一个工作点位之后的通行时间不算在内。
附件1记录了XX地区需要进行土壤采样的点位信息,包括各个点位的经度、纬度信息和完成此点位工作所需的时间。请根据这些数据建立数学模型解决下面的问题。
\1. 假设办公室为工作组某一天安排的任务是序号为:31、44、61、83、100、115、147、158这8个点位的采样,同时假设工作组在所有点位之间可以按照直线通行,速度为20千米/小时。请根据附件1的信息,给出工作组这一天的最优路径(采样点的顺序),计算出完成当天工作最短的时间。
\2. 采用就近原则,以每天工作8个点位为基准,将附件1所有点位进行划分。按照此划分方案,同时假设工作组在所有点位之间可以按照直线通行,速度为20千米/小时。请根据附件1的信息,给出每一天的点位最优路径,及相应的工作时间,并对所有的最优路径工作时间求取最大值和最小值。
\3. 如果工作组每天工作一般为8小时,由于土壤采样的具体地点处于耕地、草地和林地等偏远位置,允许工作时间最多延长至8.5个小时。判断问题2中所给的方案是否存在工作组每天工作时间超过限时或工作时间不均衡的现象。如果取消每天8个点位数的限制,在工作时限内请给出均衡化的方案,使得尽快完成土壤采样工作。
\4. 假设办公室为工作组某一天安排的任务是序号为:31、44、61、83、100、115、147、158这8个点位的采样,同时假设工作组在所有点位之间,采用专车通行的方案。请根据附件1的信息和电子地图提供的行车距离和时间,给出工作组这一天的最优路径(采样点的顺序),计算出完成当天工作最短的时间。
问题分析
问题一分析
对于某天需要采样8个点位的任务,可以使用旅行商问题(TSP)进行优化,目标是找到最短的路径覆盖所有点位。可以采用动态规划、贪心算法或元启发式算法等方法求解。在计算路径长度时,可以利用点位坐标信息和假设的直线通行速度进行计算。
首先,对于这个8个点位的采样任务,可以将其建模为一个标准的旅行商问题(TSP)。TSP问题的目标是找到一条最短的路径,覆盖所有给定的点位,并最终返回起点。对于这个问题,可以将各个采样点位视为TSP问题中的城市节点,目标就是找到一条最短的路径,串联完成所有8个点位的采样工作。
在求解TSP问题时,可以采用多种优化算法。比如动态规划算法,通过构建子问题并自底向上地求解,可以得到全局最优解。贪心算法则是每一步都选择当前看起来最好的选择,尽管不能保证得到全局最优解,但计算复杂度相对较低。此外,还可以尝试一些元启发式算法,如模拟退火算法、遗传算法等,通过模拟自然界的某些过程,在一定程度上逼近全局最优解。
在计算路径长度时,可以利用附件1提供的点位坐标信息,假设工作组可以按照直线路径在各个点位之间进行通行,并以每小时20公里的速度行驶。根据这些信息,就可以计算出完成8个采样点的最短路径和对应的工作时间。
问题二分析
针对全部点位的采样任务划分,可以采用聚类算法,例如k-means算法,将所有点位划分为若干天的工作任务,每天8个点位。在此基础上,对每个工作日的路径进行优化,得到最优路径及其对应的工作时间。通过分析所有最优路径的最大值和最小值,可以评估工作量的均衡性。
对于全部160个采样点位的任务规划,我们可以采用聚类算法将它们划分为若干天的工作任务,每天安排8个点位进行采样。其中,k-means算法是一种常用的聚类算法,它可以将样本划分为k个簇,使得每个样本都分配到离它最近的簇中心。在这里,我们可以将160个采样点位视为样本,将它们划分为若干个簇,每个簇就代表一天的工作任务。
在完成任务划分之后,我们还需要对每个工作日的路径进行优化,以找到最短的采样路径。这里仍然可以利用TSP问题的求解方法,为每个工作日的8个采样点找到最优路径。通过计算各个工作日最优路径的长度,我们就可以得到完成全部采样任务所需的最大工作时间和最小工作时间。
通过分析这些最大值和最小值,我们就可以评估工作量的均衡性。如果最大值和最小值相差很大,说明工作量分配存在不平衡的情况。这时,我们可以适当调整任务划分的方式,例如采用更复杂的聚类算法,或者手动调整某些工作日的点位安排,以期达到更加均衡的工作量分配。
问题三分析
根据工作时间限制,如果原方案存在超时或工作时间不均衡的情况,可以放宽每天工作点位的限制,采用更加灵活的任务分配策略。可以采用启发式算法,如遗传算法或模拟退火算法,在满足时间限制的情况下,尽量平衡每天的工作量,最大限度地提高工作效率。
在前两个小问中,我们假设每天的工作任务都是8个采样点。但是,如果根据实际情况,发现这种固定的任务分配存在超时或工作时间不均衡的问题,那么我们就需要采用更加灵活的方式来规划任务。
具体来说,我们可以放宽每天工作点位的限制,允许工作组在8小时工作时间内,自主安排每天的采样任务。为了解决这个问题,我们可以尝试一些启发式算法,如遗传算法和模拟退火算法。
遗传算法模拟自然界生物进化的过程,通过选择、交叉和变异等操作,不断优化解决方案。我们可以将每天的采样任务视为一个"个体",通过遗传算法的迭代,找到在满足时间限制的情况下,各天工作量最为均衡的方案。
模拟退火算法则模拟金属退火的过程,通过逐步降低"温度"的方式,最终收敛到全局最优解。我们可以将每天的采样任务视为一个"状态",通过模拟退火的过程,找到在满足时间限制的情况下,各天工作量最为均衡的方案。
这两种启发式算法都具有一定的随机性,能够在一定程度上逼近全局最优解。采用这种方式,不仅可以满足每天8.5小时的工作时间限制,而且还能尽量平衡各天的工作量,提高整体的工作效率。
问题四分析
对于采用专车通行的情况,可以利用百度、高德或腾讯等地图API提供的驾车路线规划服务,获取点位之间的实际行驶距离和时间。然后再次采用TSP问题的求解方法,得到最优路径及其对应的工作时间。这种方法可以更加准确地反映实际路况对工作效率的影响。
在前面的小问中,我们假设工作组可以按照直线路径在各个采样点之间进行通行。但实际情况下,由于地理环境的复杂性,工作组更可能需要使用专车在采样点之间进行通行。为了更加准确地反映这种情况下的工作效率,我们可以利用百度、高德或腾讯等地图API提供的驾车路线规划服务。
这些地图API可以根据实际的道路网络和地理环境,给出工作组在两个采样点之间的实际行驶距离和时间。我们可以将这些信息作为输入,再次采用TSP问题的求解方法,找到完成8个采样点的最优路径及其对应的工作时间。
与前面直线路径的假设相比,这种方法可以更加准确地反映实际路况对工作效率的影响。比如,某些采样点可能位于偏远的山区或林区,实际的道路状况和行驶时间可能与直线距离有较大差异。利用地图API提供的信息,我们就可以更好地评估完成采样任务的实际时间成本。
此外,这种方法还可以为办公室提供更加详细的工作规划方案。不仅可以给出最优采样路径,还可以预测完成全部任务所需的总时间,从而为人力、车辆等资源的调配提供依据。这有助于提高整体工作的组织效率和协调性。
模型假设
在将经纬度坐标转换为笛卡尔坐标系下的x-y坐标时,论文假设使用WGS-84参考椭球作为基准,并采用墨卡托投影的方法进行转换,这种转换方式能够较好地保持方向角不变,适用于导航和地图制作等领域。
(后略,见完整版本)
符号说明
以下是论文中问题1到问题4的模型建立与求解过程中使用的符号及其说明:(后略,见完整版本)
以上是论文中问题1到问题4的模型建立与求解过程中使用的主要符号及其说明,以markdown表格的形式列出,符号使用LaTeX表示。这些符号涵盖了经纬度坐标转换、TSP问题、k-means聚类、遗传算法、整数规划等多个方面,对理解和求解问题起到了关键作用。
模型的建立与求解
问题一模型的建立与求解
基于WGS-84参考椭球的经纬度到笛卡尔坐标转换模型建立
使用墨卡托投影(Mercator Projection)将经纬度坐标转换为平面直角坐标系下的x-y坐标。墨卡托投影是一种圆柱等角投影,可以保持方向角不变,适用于导航和地图制作等领域。
-
计算中间变量:
- e = a 2 − b 2 a 2 e = \sqrt{\frac{a^2 - b^2}{a^2}} e=a2a2−b2: 第一偏心率
- e 1 = a 2 − b 2 b 2 e_1 = \sqrt{\frac{a^2 - b^2}{b^2}} e1=b2a2−b2: 第二偏心率
- V = 1 + ( e 1 2 ) cos 2 ( B ) V = \sqrt{1 + (e_1^2)\cos^2(B)} V=1+(e12)cos2(B)
- c = a 2 b c = \frac{a^2}{b} c=ba2
- M = c V 3 M = \frac{c}{V^3} M=V3c
- N = c V N = \frac{c}{V} N=Vc
- t = tan ( B ) t = \tan(B) t=tan(B)
- n = ( e 1 2 ) cos 2 ( B ) n = \sqrt{(e_1^2)\cos^2(B)} n=(e12)cos2(B)
- l = L − L 0 l = L - L_0 l=L−L0
-
(后略,见完整版本)
利用WGS-84参考椭球的几何特性,通过一系列公式将经纬度坐标转换为笛卡尔坐标系下的x-y坐标。这种转换为后续的优化计算提供了适当的数据输入。
问题1 TSP模型的分析与建立
对于问题1中的任务,即为工作组某一天安排采样8个点位(31、44、61、83、100、115、147、158),需要找到一条最短的路径完成所有采样工作。这可以建模为一个标准的旅行商问题(Traveling Salesman Problem,简称TSP)。
TSP是一个典型的组合优化问题,目标是找到一条经过所有给定城市且回到起点的最短路径。在这个问题中,我们可以将每个采样点位视为一个城市节点,工作组需要依次访问这8个节点,最终返回起点,目标是找到一条覆盖所有节点且总行程距离最短的路径。
TSP问题是一个NP-hard问题,对于规模较大的实例,要找到精确的全局最优解是非常困难的。因此,我们需要采用一些有效的近似算法来求解这个问题。在这里,我们可以尝试使用动态规划算法或者遗传算法来解决。
动态规划算法求解TSP问题
动态规划算法是一种自底向上的问题求解方法,它通过将大问题分解为更小的子问题,并通过动态地计算和保存子问题的最优解,最终得到原问题的最优解。对于TSP问题,动态规划算法可以通过以下步骤来求解:
-
定义状态:设 S ⊆ V , s ∈ S , i ∈ V − S S\subseteq V, s\in S, i\in V-S S⊆V,s∈S,i∈V−S,其中 V V V表示所有节点的集合。 d p [ S ] [ s ] dp[S][s] dp[S][s]表示当前已经访问了集合 S S S中的节点,且最后一个访问的节点是 s s s的情况下,从 s s s出发访问集合 V − S V-S V−S中剩余节点的最短距离。
-
状态转移方程:对于任意 S ⊆ V , s ∈ S , i ∈ V − S S\subseteq V, s\in S, i\in V-S S⊆V,s∈S,i∈V−S,有
d p [ S ] [ s ] = min i ∈ V − S { d p [ S − { i } ] [ i ] + d s i } dp[S][s] = \min_{i\in V-S} \{dp[S-\{i\}][i] + d_{si}\} dp[S][s]=i∈V−Smin{dp[S−{i}][i]+dsi}
其中 d s i d_{si} dsi表示节点 s s s到节点 i i i的距离。 -
边界条件:当 ∣ S ∣ = 1 |S| = 1 ∣S∣=1时, d p [ S ] [ s ] = 0 dp[S][s] = 0 dp[S][s]=0。
-
最优解:最终的最优解为 min s ∈ V { d p [ V ] [ s ] + d s 1 } \min_{s\in V} \{dp[V][s] + d_{s1}\} mins∈V{dp[V][s]+ds1},其中 d s 1 d_{s1} ds1表示从最后一个节点回到起点的距离。
下面给出这个动态规划算法的具体步骤:
-
初始化:对于任意 S ⊆ V , s ∈ S S\subseteq V, s\in S S⊆V,s∈S,设 d p [ S ] [ s ] = ∞ dp[S][s] = \infty dp[S][s]=∞。当 ∣ S ∣ = 1 |S| = 1 ∣S∣=1时, d p [ S ] [ s ] = 0 dp[S][s] = 0 dp[S][s]=0。
-
状态转移:对于每个 ∣ S ∣ = 2 , 3 , … , ∣ V ∣ |S| = 2, 3, \dots, |V| ∣S∣=2,3,…,∣V∣,遍历所有的 S ⊆ V , s ∈ S , i ∈ V − S S\subseteq V, s\in S, i\in V-S S⊆V,s∈S,i∈V−S,计算 d p [ S ] [ s ] = min i ∈ V − S { d p [ S − { i } ] [ i ] + d s i } dp[S][s] = \min_{i\in V-S} \{dp[S-\{i\}][i] + d_{si}\} dp[S][s]=mini∈V−S{dp[S−{i}][i]+dsi}。
-
最优解计算:遍历所有的 s ∈ V s\in V s∈V,计算 min s ∈ V { d p [ V ] [ s ] + d s 1 } \min_{s\in V} \{dp[V][s] + d_{s1}\} mins∈V{dp[V][s]+ds1},得到最终的最优解。
上述动态规划算法的数学公式如下:
(后略,见完整版本)
通过上述动态规划算法,我们可以得到完成8个采样点的最优路径及其对应的最短工作时间。具体步骤如下:
-
根据附件1提供的点位坐标信息,计算任意两个点位之间的直线距离 d i j d_{ij} dij。
-
初始化 d p dp dp数组,其中 d p [ S ] [ s ] = ∞ dp[S][s] = \infty dp[S][s]=∞,当 ∣ S ∣ = 1 |S| = 1 ∣S∣=1时, d p [ S ] [ s ] = 0 dp[S][s] = 0 dp[S][s]=0。
-
对于 ∣ S ∣ = 2 , 3 , … , 8 |S| = 2, 3, \dots, 8 ∣S∣=2,3,…,8,遍历所有的 S ⊆ { 31 , 44 , 61 , 83 , 100 , 115 , 147 , 158 } , s ∈ S , i ∈ { 31 , 44 , 61 , 83 , 100 , 115 , 147 , 158 } − S S\subseteq \{31, 44, 61, 83, 100, 115, 147, 158\}, s\in S, i\in \{31, 44, 61, 83, 100, 115, 147, 158\}-S S⊆{31,44,61,83,100,115,147,158},s∈S,i∈{31,44,61,83,100,115,147,158}−S,计算 d p [ S ] [ s ] = min i ∈ { 31 , 44 , 61 , 83 , 100 , 115 , 147 , 158 } − S { d p [ S − { i } ] [ i ] + d s i } dp[S][s] = \min_{i\in \{31, 44, 61, 83, 100, 115, 147, 158\}-S} \{dp[S-\{i\}][i] + d_{si}\} dp[S][s]=mini∈{31,44,61,83,100,115,147,158}−S{dp[S−{i}][i]+dsi}。
-
遍历所有的 s ∈ { 31 , 44 , 61 , 83 , 100 , 115 , 147 , 158 } s\in \{31, 44, 61, 83, 100, 115, 147, 158\} s∈{31,44,61,83,100,115,147,158},计算 min s ∈ { 31 , 44 , 61 , 83 , 100 , 115 , 147 , 158 } { d p [ { 31 , 44 , 61 , 83 , 100 , 115 , 147 , 158 } ] [ s ] + d s 1 } \min_{s\in \{31, 44, 61, 83, 100, 115, 147, 158\}} \{dp[\{31, 44, 61, 83, 100, 115, 147, 158\}][s] + d_{s1}\} mins∈{31,44,61,83,100,115,147,158}{dp[{31,44,61,83,100,115,147,158}][s]+ds1},得到最终的最优解。
通过这个动态规划算法,我们可以得到完成8个采样点的最优路径及其对应的最短工作时间。这个方法具有以下优点:
对于规模较大的问题,这个动态规划算法的时间复杂度可能会变得较高。在这种情况下,我们可以尝试一些其他的近似算法,如贪心算法、模拟退火算法、遗传算法等,以求得一个较优的解。
遗传算法求解TSP问题
由于TSP问题是一个NP-hard问题,对于规模较大的实例,要找到精确的全局最优解是非常困难的。因此,我们可以采用一种启发式算法 - 遗传算法(Genetic Algorithm,简称GA)来求解这个问题。遗传算法模拟自然界生物进化的过程,通过选择、交叉和变异等操作,不断优化解决方案,最终逼近全局最优解。
遗传算法模型建立:
-
个体表示:
在遗传算法中,每个个体代表一个解决方案。对于TSP问题,我们可以使用整数编码的方式来表示一个解,即使用一个长度为n的整数排列来表示n个城市的访问顺序。例如,[3 1 4 2]表示先访问第3个城市,然后是第1个城市,第4个城市,最后是第2个城市。 -
初始种群:
遗传算法首先需要生成一个初始种群,包含NIND个个体。我们可以使用随机生成的方法来初始化种群,即对每个个体的访问顺序进行随机排列。 -
适应度函数:
适应度函数用于评估每个个体的优劣程度。对于TSP问题,我们可以将个体的适应度定义为路径长度的倒数,即:
f ( x ) = 1 L ( x ) f(x) = \frac{1}{L(x)} f(x)=L(x)1
其中 L ( x ) L(x) L(x)表示个体 x x x所代表的路径的总长度。这样,路径长度越短的个体,其适应度就越高。 -
选择操作:
选择操作用于从当前种群中挑选出适应度较高的个体,以参与后续的交叉和变异操作。我们可以使用轮盘赌selection的方法进行选择,即个体被选中的概率与其适应度成正比。轮盘赌selection的公式如下:
P ( x ) = f ( x ) ∑ i = 1 N f ( x i ) P(x) = \frac{f(x)}{\sum_{i=1}^{N}f(x_i)} P(x)=∑i=1Nf(xi)f(x)
其中 P ( x ) P(x) P(x)表示个体 x x x被选中的概率, f ( x ) f(x) f(x)表示个体 x x x的适应度, N N N为种群大小。 -
交叉操作:
交叉操作用于通过父代个体的信息产生新的子代个体。对于TSP问题,我们可以使用Order Crossover(OX)算子进行交叉。OX算子可以保留父代个体中的相对顺序信息,从而产生新的有效解。OX算子的具体步骤如下:- 从父代个体1中随机选择两个位置,记为 i i i和 j j j,其中 i < j i<j i<j。
- 将父代个体1中位置 i i i到 j j j之间的基因片段复制到子代个体中的相应位置。
- 从父代个体2中,按照原有顺序选择未出现在子代个体中的基因片段,填充到子代个体的剩余位置。
-
变异操作:
变异操作用于在子代个体中引入随机扰动,增加解空间的多样性,防止陷入局部最优。对于TSP问题,我们可以使用Swap Mutation算子进行变异,即随机选择两个城市,并交换它们在个体中的位置。Swap Mutation的公式如下:
x i ′ = { x j , if i = k x k , if i = j x i , otherwise x'_i = \begin{cases} x_j, & \text{if } i = k \\ x_k, & \text{if } i = j \\ x_i, & \text{otherwise} \end{cases} xi′=⎩ ⎨ ⎧xj,xk,xi,if i=kif i=jotherwise
其中 x i , x j , x k x_i,x_j,x_k xi,xj,xk分别表示被选中进行交换的三个基因位置的值, x i ′ x'_i xi′表示变异后的新值。 -
(后略,见完整版本)
通过反复执行上述操作,遗传算法可以不断优化解,最终找到一个相对较优的TSP问题解。
通过上述遗传算法的步骤,我们可以不断优化解,最终找到问题1中工作组完成8个采样点的最优路径及其对应的最短工作时间。这种方法相比于动态规划,可以更好地应对规模较大的TSP问题实例。
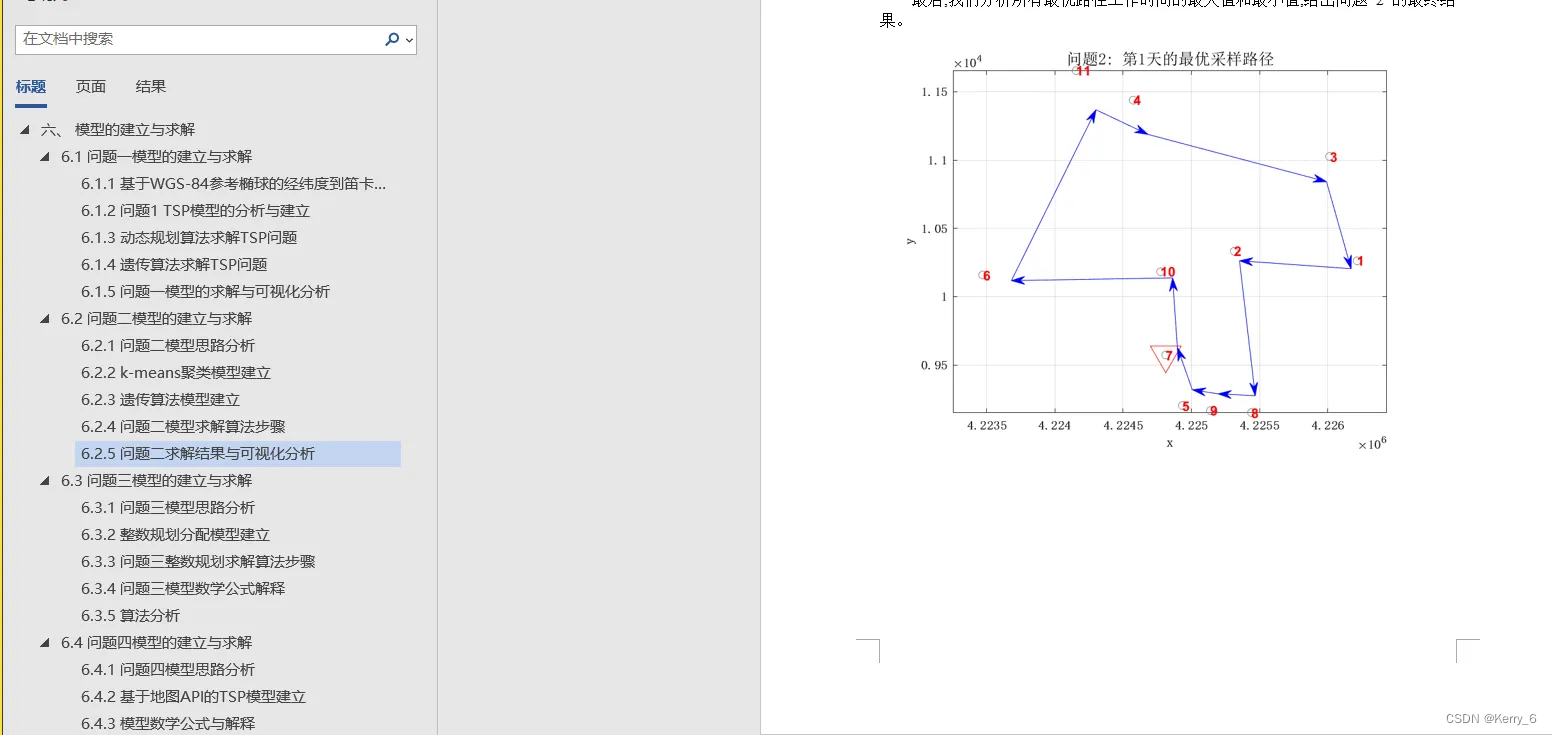
问题一模型的求解与可视化分析

(后略,见完整版本)
模型的评价与推广
各个模型的优缺点及其推广如下:
问题1模型的评价与推广
优点:
- 将TSP问题转化为标准的数学模型,并使用动态规划算法和遗传算法进行求解,能够有效地找到最优或近似最优的路径,为实际工作提供了可行的方案。
- 通过引入WGS-84参考椭球和墨卡托投影,将经纬度坐标转换为平面坐标,便于计算点位之间的直线距离,简化了模型的复杂度。
缺点:
- 模型假设工作组在各个点位之间可以按照直线距离通行,而实际情况中可能存在地形、道路等限制因素,导致模型与实际情况存在一定的偏差。
- 动态规划算法的时间复杂度较高,当问题规模较大时,求解时间可能会较长。
推广:
- 可以考虑将模型扩展到多个工作组同时工作的情况,通过合理分配任务和协调路径,进一步提高工作效率。
- 可以将模型应用于其他类似的路径优化问题,如物流配送、旅游路线规划等,通过合理安排路径,降低成本,提高效益。
完整代码和成品完整论文获取:↓↓↓↓↓
https://www.yuque.com/u42168770/qv6z0d/yb7pug63c2xyo412