这里triton.cdiv(M, META['BLOCK_SIZE_M']) * triton.cdiv(N, META['BLOCK_SIZE_N']),所以grid的形状是一维的。
观察函数内部

pid = tl.program_id(axis=0),因为grid是一维的,所以这里就是总块数,我们假设实际A*B=C,
A,B形状是574*574,块形状是64*64,这样一共有81块,pid就是0~80,
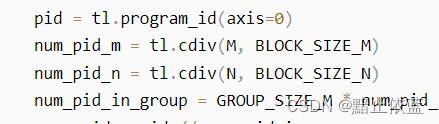
这里用574/64=9,所以num_pid_m和num_pid_n都是81
num_pid_in_group = GROUP_SIZE_M * num_pid_n,算的是一个组有多少块,这里假设是3*9,所以一组27块。
group_id = pid // num_pid_in_group算组id,当前pid//27就得到所在组id,比如30//27=1,说明30块在组1
first_pid_m = group_id * GROUP_SIZE_M,每一组的第一个块在结果矩阵中是第几行。
因为数据不一定能整除,最后一个组可能少,所以有
group_size_m = min(num_pid_m - first_pid_m, GROUP_SIZE_M)pid_m = first_pid_m + (pid % group_size_m)
pid_n = (pid % num_pid_in_group) // group_size_m这两行做映射,是关于pid和结果矩阵中块位置的映射,
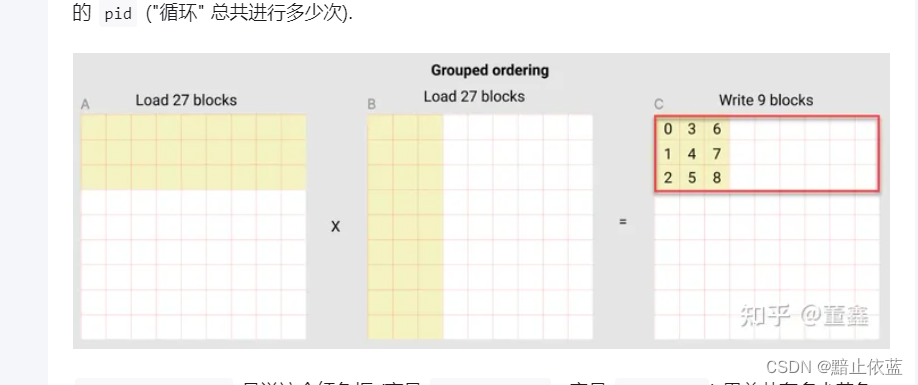
行坐标=组号*每组行数+pid%每组行数,pid%3知,pid三个三个一排,也就是算的当前pid在当前组里相对是第几行,比如如果是4,4%3=1,可知pid=4在当前组第一行(0,1,2),那么组号*每组行数就可以相对整组位移,最终可以知道pid和c矩阵中行位置的映射
列坐标=pid%每组总数//每组行数,pid%每组总数可知当前组顺序是第几块,也就是27块中的第几块,比如pid%4就会得到4,然后4//=1就知道在第几列了,
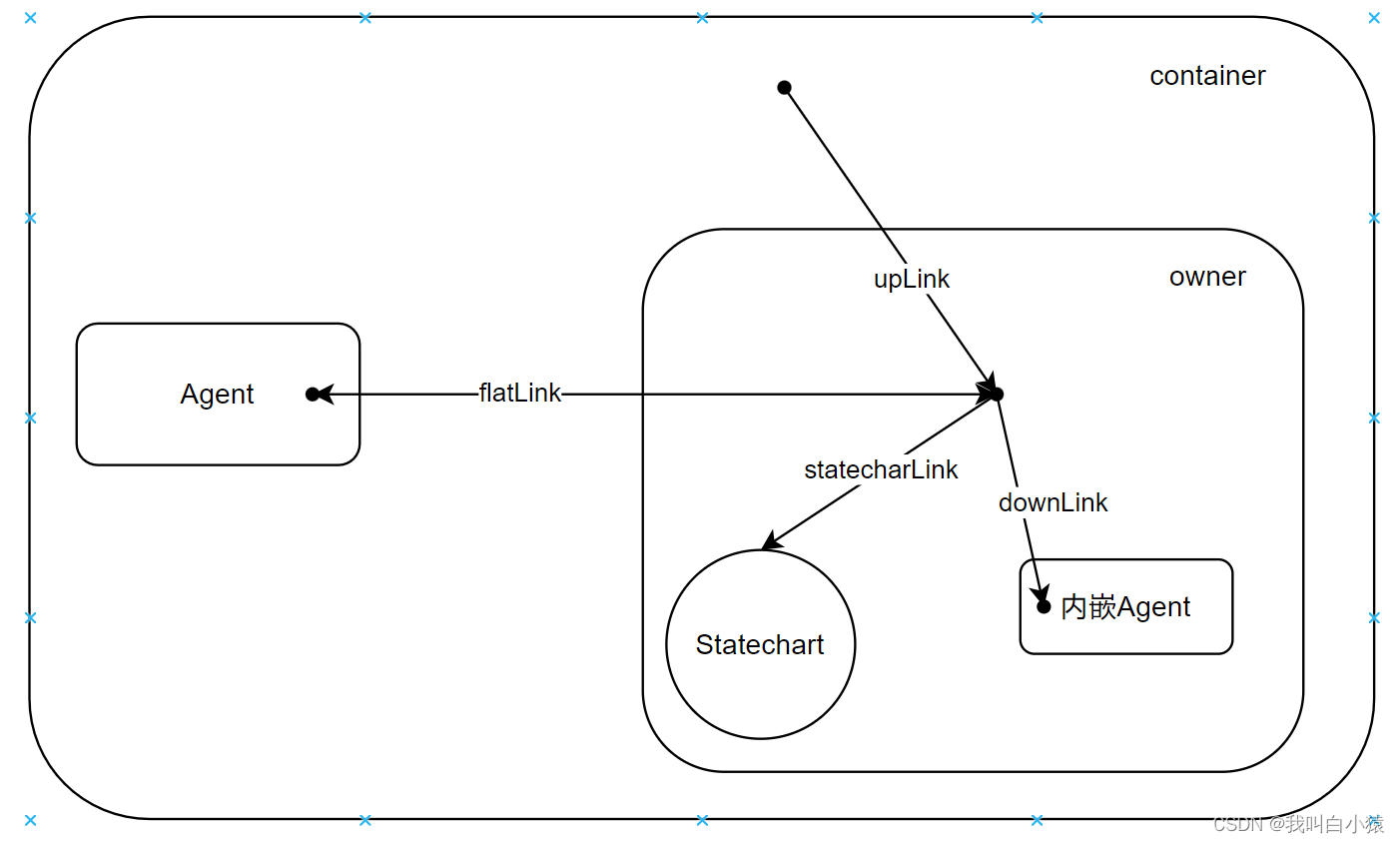
所以pid的对应关系就和上图的一样的顺序对应。
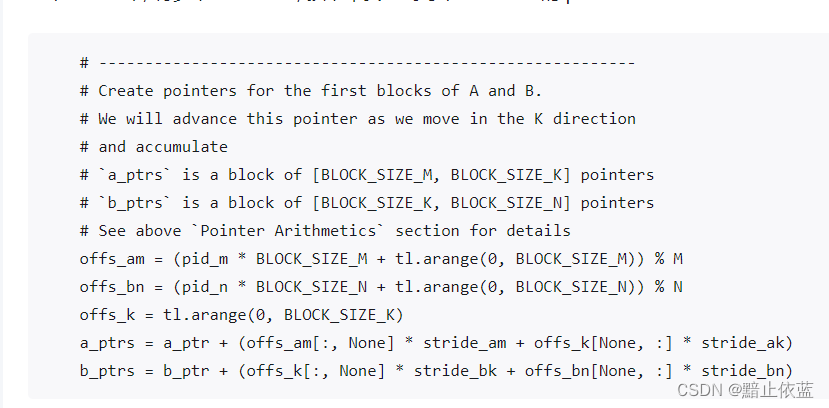
这里比如想要计算块pid=4,那么就需要拿到A的第一行和B的第一行,
这里各自会得到一个二维矩阵,里面的指针值就是所指向的元素位置,这里只是第一块

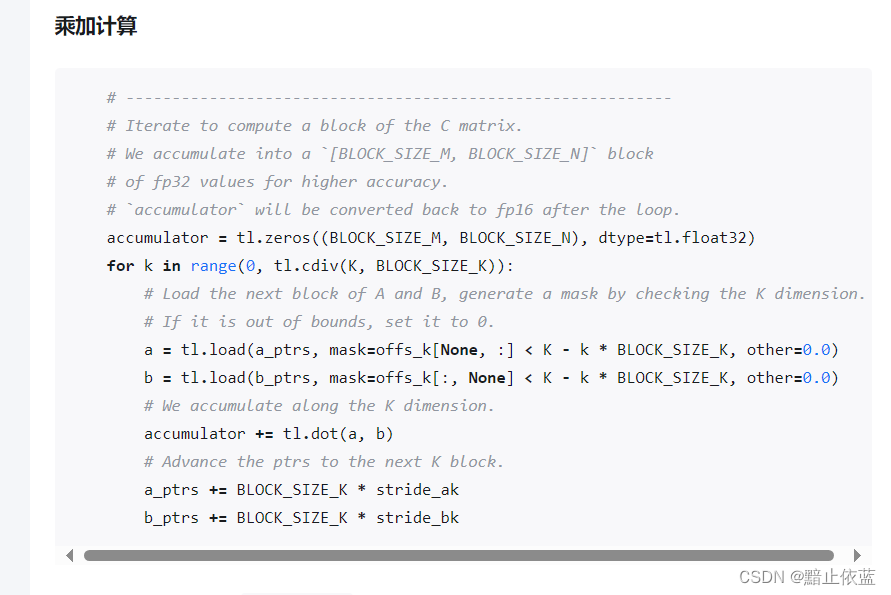
这里就好理解了,就是A矩阵从列迭代,B从行迭代,

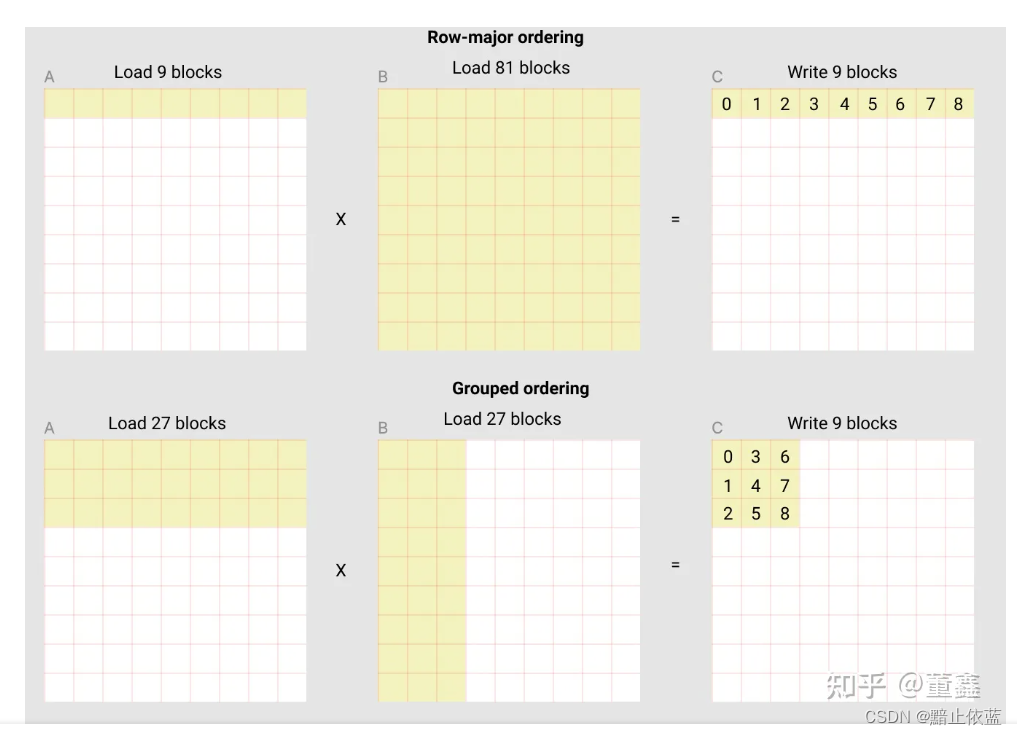
不同的顺序,所要求的缓存中所需要的空间不一样,下面这一种在缓存受限的情况下要好。





![[数据集][目标检测]减速区域检测数据集VOC+YOLO格式1654张1类别](https://img-blog.csdnimg.cn/direct/bde4fdd8db7d4bfe86e36b8ea23afcbd.png)