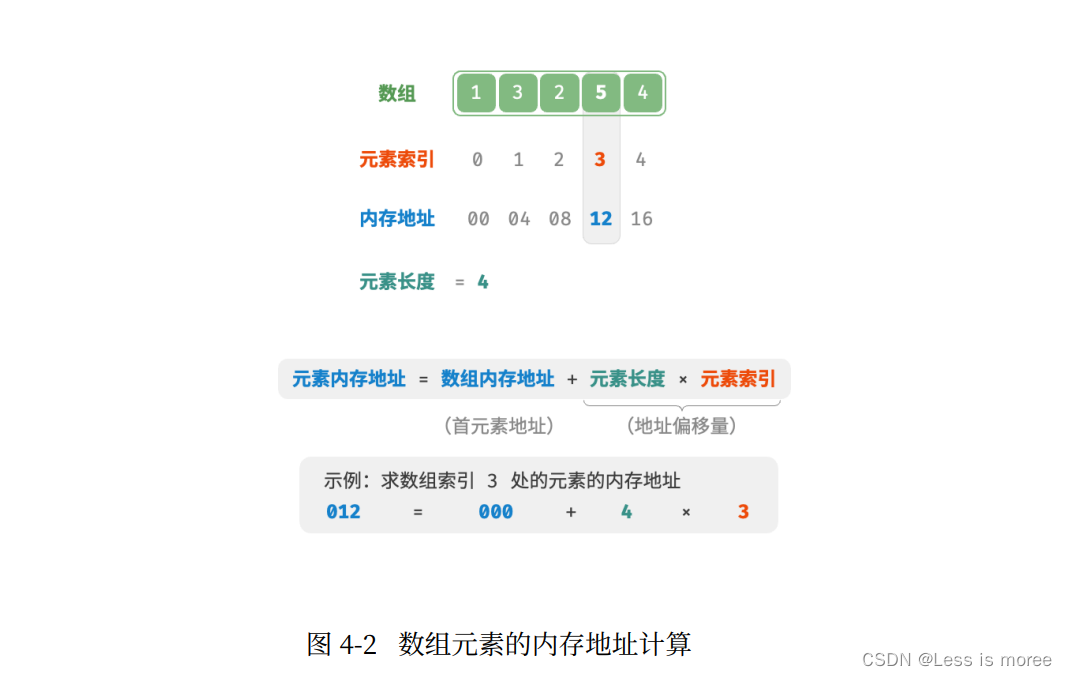
In this post we'll go into the concept of supervised learning, the requirements for machines to learn, and the process of learning and enhancing prediction accuracy.
在这篇文章中,我们将深入探讨监督学习的概念、机器学习的要求以及学习和提高预测准确性的过程。
What is Supervised Learning 什么是监督学习
When it comes to machine learning, there are primarily four types:
在机器学习领域,主要有四种类型:
- Supervised Machine Learning 监督学习
- Unsupervised Machine Learning 非监督学习
- Semi-Supervised Machine Learning 半监督学习
- Reinforcement Learning 强化学习
Supervised machine learning refers to the process of training a machine using labeled data. Labeled data can consist of numeric or string values. For example, imagine that you have photos of animals, such as cats and dogs. To train your machine to recognize the animal, you’ll need to “label” or indicate the name of the animal alongside each animal image. The machine will then learn to pick up similar patterns in photos and predict the appropriate label.
监督机器学习是指使用标记数据进行机器训练的过程。标记数据可以包括数值或字符串值。例如,假设你有一些动物的照片,如猫和狗。为了训练你的机器识别这些动物,你需要“标记”或指示每张照片旁边的动物名称。然后,机器将学习在照片中识别相似的模式并预测适当的标签。
Machine Learning 机器学习
Machine Learning is a term that refers to the process that a machine undergoes so that it can produce predictions. As mentioned, a machine can identify a cat in a photo even if it has never seen this particular cat. But how?
机器学习是一个术语,指的是机器经历的过程,以便它能够产生预测。如上所述,机器即使在以前从未见过这只特定的猫,也能在照片中识别出猫。但是这是怎么做到的呢?
Through training of course, which involves a recursive process that improves output (or prediction) accuracy. In supervised machine learning, we teach the machine to identify things based on the labeled data we give it.
当然是通过训练,训练涉及一个递归过程,用于提高输出(或预测)的准确性。在监督机器学习中,我们根据提供的标记数据教机器识别事物。
Today, you see and interact with trained machines everywhere. Netflix, YouTube, TikTok, and most services implement some kind of algorithm that uses your data (which was collected from you) to learn about you so it can give you things you like. That's why you spend endless hours scrolling.
如今,你随处可见训练过的机器,并与它们互动。Netflix、YouTube、TikTok 和大多数服务都实现了某种算法,这些算法使用你的数据(从你那里收集而来)来了解你,以便为你提供你喜欢的内容。这就是为什么你会花上无数个小时滚动浏览的原因。
The more data you give these services, the more they learn about you. Some of them even know you more than you know yourself.
你向这些服务提供的数据越多,它们对你的了解就越多。有些服务甚至比你自己更了解你。
Supervised vs Unsupervised 监督与非监督
Think of it like this: 像这样思考
As humans, we recognize a cat as a cat because we have been taught what a cat looks like by our parents and teachers. They basically "supervised" us and "labeled" our data. However, when we classify good and bad friends, we rely on our personal experiences and observations to achieve this. Similarly, machines can learn through supervised learning, where they are taught to recognize specific images, or through unsupervised learning, where they make their own judgments based on the data provided to them.
作为人类,我们能够识别猫是因为我们的父母和老师教给我们猫长什么样。他们基本上“监督”我们并“标记”了我们的数据。然而,当我们区分好朋友和坏朋友时,我们依赖的是自己的经历和观察来实现这一点。同样地,机器可以通过监督学习来学习识别特定的图像,或者通过非监督学习,根据提供给它们的数据自行做出判断。
Compared to us, the learning process of a machine is different but it was inspired by our brains. To train computers, we'll mostly use statistical algorithms like Linear Regression, Decision Trees (DTs), and K-nearest neighbours (KNNs).
与我们相比,机器的学习过程是不同的,但它受到我们大脑的启发。为了训练计算机,我们主要使用统计算法,如线性回归、决策树(DTs)和K最近邻(KNNs)。
An algorithm is a sequence of operations that is typically used by computers to find the correct solution to a problem (or identify that there are no correct solutions).
算法是一系列操作的序列,通常由计算机使用,以找到问题的正确解决方案(或确定没有正确的解决方案)。
5 things you'll need to train your model
训练模型所需的5件事情
Understand the problem 理解问题
First, you'll need to understand the problem that you're trying to solve. Usually, we can use machine learning to answer a broad range of questions, things like:
首先,你需要理解你试图解决的问题。通常,我们可以使用机器学习来回答广泛的问题,例如:
- Can we accurately predict diseases in patients? 我们能否准确预测患者的疾病?
- Can we predict the price of houses? 我们能预测房价吗?
It's important to understand the question we're trying to answer. Let's take the first question from the list above:
了解我们试图回答的问题很重要。让我们从上面的列表中取第一个问题:
"Can we accurately predict diseases in patients?" 我们能否准确预测患者的疾病?
We can rephrase this question to: 我们可以将这个问题重新表述为:
"Is it possible to utilize historical patient data such as age, gender, blood pressure, cholesterol, and medical conditions to predict the likelihood of a new patient developing a disease?"
“是否可以利用历史患者数据,如年龄、性别、血压、胆固醇和医疗状况,来预测新患者患病的可能性?”
The answer is: Yes. This is known as a classification problem, where the input data is used to predict the patient’s potential to develop a new disease based on a list of predetermined categories.
答案是:可以。这被称为分类问题,其中输入数据用于根据预定类别的列表预测患者患新疾病的潜在性。
Get and prepare the data 获取并准备数据
Imagine you buy a textbook for a math class, and all the papers are blank. Or better yet, imagine the papers include random information, not related to the topic or even unrecognizable characters. Would you be able to learn anything? Of course not. You'll need organized information. Similarly, we'll need to prepare our data before we can use it.
想象一下,你买了一本数学课的教科书,但所有的纸张都是空白的。或者更好的是,想象一下这些纸张包含随机信息,与主题无关,甚至是无法识别的字符。你能学到东西吗?当然不能。你需要有组织的信息。同样地,在使用数据之前,我们需要先准备数据。
The quality of your data will determine the quality of your predictions.
您数据的质量将决定您预测的质量。
So, the next step is to get the data. It could be located in many places, like:
所以,下一步是获取数据。数据可能位于许多地方,比如:
- Hospital internal database (SQL) 医院内部数据库(SQL)
- Publicly available information (Web Scraping) 公开可获取的信息(网络爬虫)
- Public health records (JSON) 公共卫生记录(JSON)
As you can see, the data could be in multiple locations and in many shapes and formats. As long as the data is relevant to our problem, we can make use of it.
如您所见,数据可能位于多个位置,且有多种形状和格式。只要数据与我们的问题相关,我们就可以利用它。
Data Wrangling is the process of working with raw data and converting it into a usable form.
数据整理(Data Wrangling)是处理原始数据并将其转换为可用形式的过程。
Explore and analyze the data 探索和分析数据
Now that we're working with clean data, it's important to take a closer look and perform what is referred to as Explanatory Data Analysis (EDA) to find patterns and summarize the main characteristics. For example, to understand the distribution of our dataset we can calculate the mean, median, and range of our age variable. We can also analyze the correlation between disease and gender by calculating the percentage of a disease for a specific gender.
既然我们现在处理的是干净的数据,重要的是要仔细查看并进行所谓的解释性数据分析(EDA),以查找模式并总结主要特征。例如,为了了解数据集的分布,我们可以计算年龄变量的平均值、中位数和范围。我们还可以通过计算特定性别的疾病百分比来分析疾病与性别之间的相关性。
The most common programming languages used to perform EDA, and data analysis are: Python and R. Popular libraries for Python include: matplotlib, seaborn, numpy, and others.
用于执行EDA和数据分析的最常见的编程语言是:Python和R。Python中流行的库包括:matplotlib、seaborn、numpy等。
We will not go into technical details in this post, but some common analyses done during the EDA phase include:
本文不会深入探讨技术细节,但在EDA阶段通常会进行的一些常见分析包括:
- Data Distribution 数据分布
- Dataset Structure 数据集结构
- Handle Missing Values and Outliers 处理缺失值和异常值
- Determine Correlations 确定相关性
- Evaluate Assumptions 评估假设
- Visualize by Plotting 通过绘图进行可视化
- Identify Patterns 识别模式
- Understand the Relevancy of External Data 理解外部数据的相关性
Choose a suitable algorithm 选择合适的算法
As we've seen earlier, we have a classification problem. We can therefore build model candidates using common classification algorithms and then compare outputs to choose the most accurate.
正如我们之前所见,我们面临的是一个分类问题。因此,我们可以使用常见的分类算法构建模型候选者,然后比较输出结果以选择最准确的模型。
For this example, I'm going to use two algorithms popular for solving classification problems:
对于这个例子,我将使用两种流行的分类问题解决算法:
- Random Forest 随机森林
- Support Vector Machine (SVM) 支持向量机(SVM)
Train, test, and refine 训练、测试和调优
Using Python and scikit-learn (a machine learning library for Python), we can determine the accuracy of both algorithms given our dataset. We'll train the model by giving it a piece of the data.
使用Python和scikit-learn(Python的机器学习库),我们可以根据我们的数据集确定两种算法的准确性。我们将通过提供一部分数据来训练模型。
While we can use all of the data in our dataset to train the model, we'll be splitting the data into two parts. Commonly, it is an 80/20 split, meaning 80% of our data will go to training, and the remaining 20% will be used for testing. This is done to prevent overfitting. The topic of overfitting was discussed in this article.
虽然我们可以使用数据集中的所有数据来训练模型,但我们会将数据分成两部分。通常,这是80/20的分割,意味着80%的数据用于训练,剩余的20%用于测试。这是为了防止过拟合。过拟合的主题在本文中已有讨论。
# ... Previous code omitted for brevity
# Split the data into training and testing sets
X_train, X_test, y_train, y_test = train_test_split(X_encoded, y, test_size=0.2, random_state=42)The output is as shown below: 输出如下:
# ... Previous code omitted for brevity
print("SVM Accuracy:", svm_accuracy)
print("Random Forest Accuracy:", rf_accuracy)
SVM Accuracy: 0.2857142857142857
Random Forest Accuracy: 0.8571428571428571Looking at SVM vs. Random Forest accuracy results, we'll choose Random Forest since it has an accuracy of 85% vs. just 28% for SVM.
查看SVM与随机森林的准确率结果,我们将选择随机森林,因为它的准确率为85%,而SVM的准确率仅为28%。
Accuracy refers to the ability of the model to correctly classify the disease given a set of testing data.
准确率指的是模型在给定的测试数据集下正确分类疾病的能力。
Obviously, you can try other algorithms until you're satisfied with the outputs based on your criteria and the problem you're trying to solve.
显然,你可以尝试其他算法,直到你对根据你的标准和你试图解决的问题所得到的输出感到满意为止。
The above is essentially what goes into the Supervised Machine Learning process. It's important to highlight that this is an iterative process and does not end after training. We need to deploy the model and acquire feedback from stakeholders which could lead to model refinement based on new data and other factors.
以上基本上就是监督机器学习过程的内容。需要强调的是,这是一个迭代过程,并不会在训练后结束。我们需要部署模型并从利益相关者那里获取反馈,这可能会基于新数据和其他因素导致模型细化。
Conclusion 总结
Thanks for reading! In this post, we covered what supervised machine learning is, what machines need to learn, how they learn, and how they improve. We also covered important steps such as Data Wrangling and EDA that are absolutely crucial in the prediction accuracy and relevancy of your model.
感谢阅读!在本文中,我们介绍了监督机器学习是什么,机器需要学习什么,它们如何学习,以及它们如何改进。我们还介绍了诸如数据预处理和探索性数据分析(EDA)等重要步骤,这些步骤在模型预测的准确性和相关性方面至关重要。






![[oeasy]python0021_宝剑镶宝石_爱之石中剑_批量替换_特殊字符_特殊颜色](https://img-blog.csdnimg.cn/img_convert/5ab7a24d6d220ad0300fe4ce7a5d1751.png)