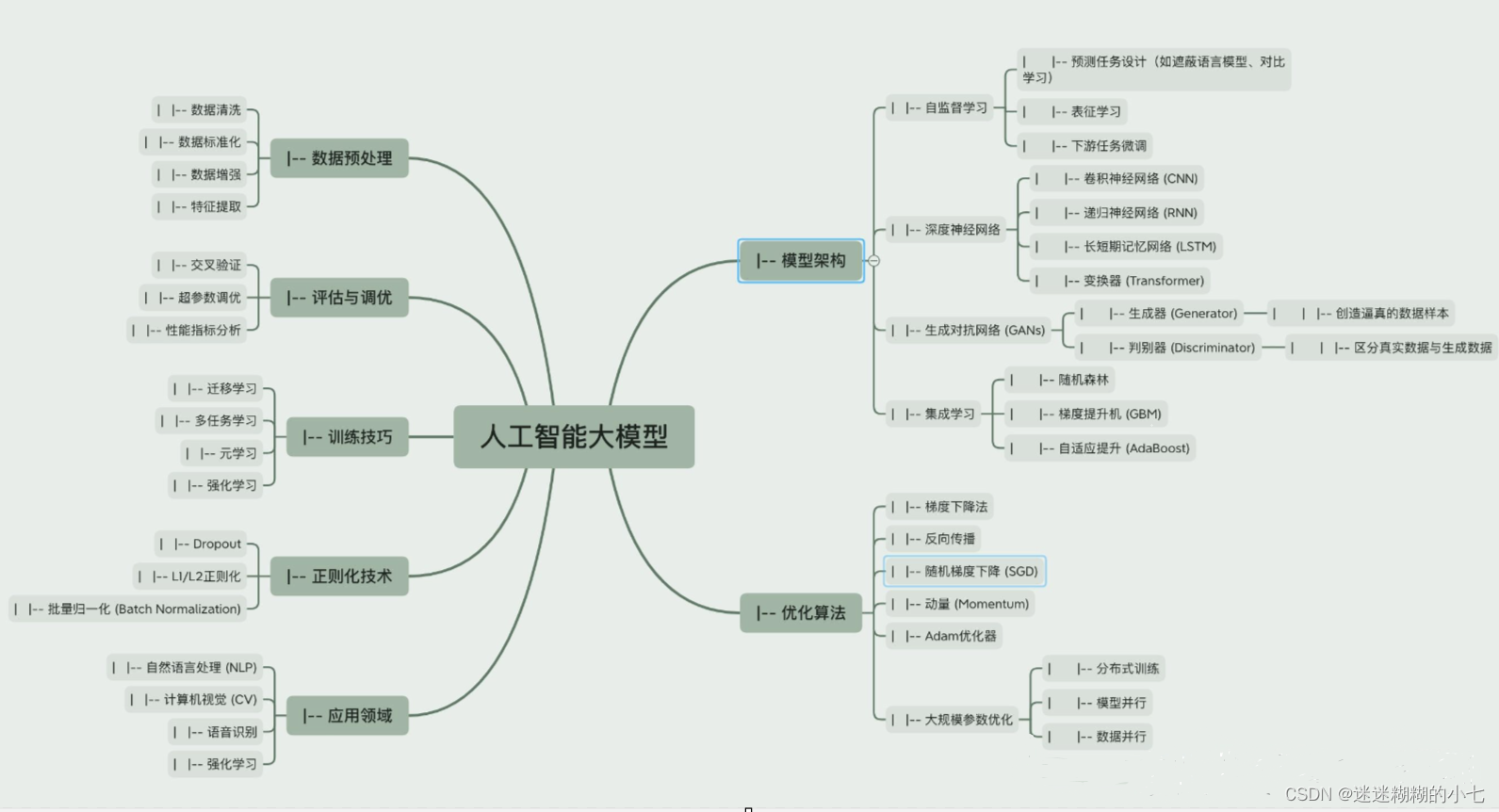
一、安装Hadoop
安装hadoop参考此文,关键点是安装JDK和Hadoop的配置,为避免引用文章变收费,我把关键信息摘录如下:
jdk安装和配置就不说了(我本机安装了1.8/15/17/21,以17为主),hadoop安装过程:
1.设置SSH免密
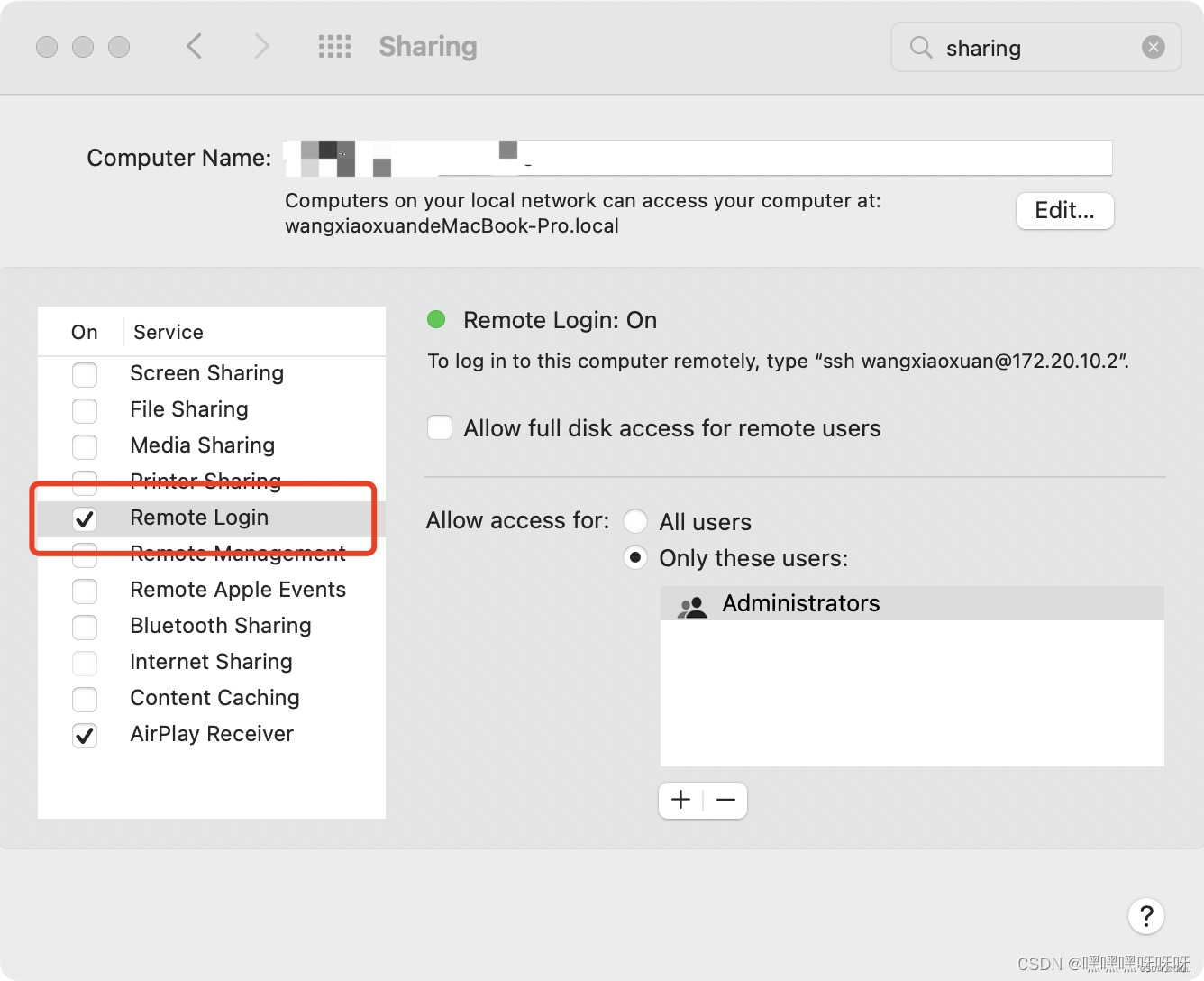
1. 打开系统偏好设置,在输入框输入sharing(共享),勾选”远程连接“:
2.打开终端,依次输入如下命令:
ssh-keygen -t rsa -P '' -f ~/.ssh/id_rsa
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
chmod 0600 ~/.ssh/id_rsa.pub3.输入【ssh localhost】验证,无需输入密码则成功
2.下载并解压hadoop安装包
到官网下载需要的版本,我下载的是3.3.6,然后解压到用户下自己用户名的目录下:
3.修改配置文件
(1)vim ~/.zprofile(路径修改为自己安装包的路径)
# Hadoop
export HADOOP_HOME=/Users/wangxiaoxuan/hadoop-3.3.6/
export HADOOP_INSTALL=$HADOOP_HOME
export HADOOP_MAPRED_HOME=$HADOOP_HOME
export HADOOP_COMMON_HOME=$HADOOP_HOME
export HADOOP_HDFS_HOME=$HADOOP_HOME export YARN_HOME=$HADOOP_HOME
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export PATH=$PATH:$HADOOP_HOME/sbin:$HADOOP_HOME/bin
export HADOOP_OPTS="-Djava.library.path=$HADOOP_HOME/lib/nativ"输入【source ~/.zprofile】使内容生效
(2)cd /Users/wangxiaoxuan/hadoop-3.3.6/etc/hadoop
vim hadoop-env.sh
export JAVA_HOME="/Library/Java/JavaVirtualMachines/jdk-1.8.jdk/Contents/Home"(3)vim core-site.xml,将标签<configuration></configuration>中内容替换如下,路径需换成自己的路径
<configuration>
<property>
<name>hadoop.tmp.dir</name>
<value>/Users/wangxiaoxuan/hdfs/tmp/</value>
</property>
<property>
<name>fs.default.name</name>
<value>hdfs://127.0.0.1:9000</value>
</property>
</configuration>(4)vim hdfs-site.xml,将标签<configuration></configuration>中内容替换如下,路径需换成自己的路径
<property>
<name>dfs.data.dir</name>
<value>/Users/wangxiaoxuan/hdfs/namenode</value>
</property>
<property>
<name>dfs.data.dir</name>
<value>/Users/wangxiaoxuan/hdfs/datanode</value>
</property>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
</configuration>(5)vim mapred-site.xml,将标签<configuration></configuration>中内容替换如下,无需更改路径
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>(6)vim yarn-site.xml,将标签<configuration></configuration>中内容替换如下,无需更改路径
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>127.0.0.1</value>
</property>
<property>
<name>yarn.acl.enable</name>
<value>0</value>
</property>
<property>
<name>yarn.nodemanager.env-whitelist</name>
<value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PERPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOME</value>
</property>
</configuration>4.运行
执行【hdfs namenode -format】 如果报错,需要先执行【stop-all.sh】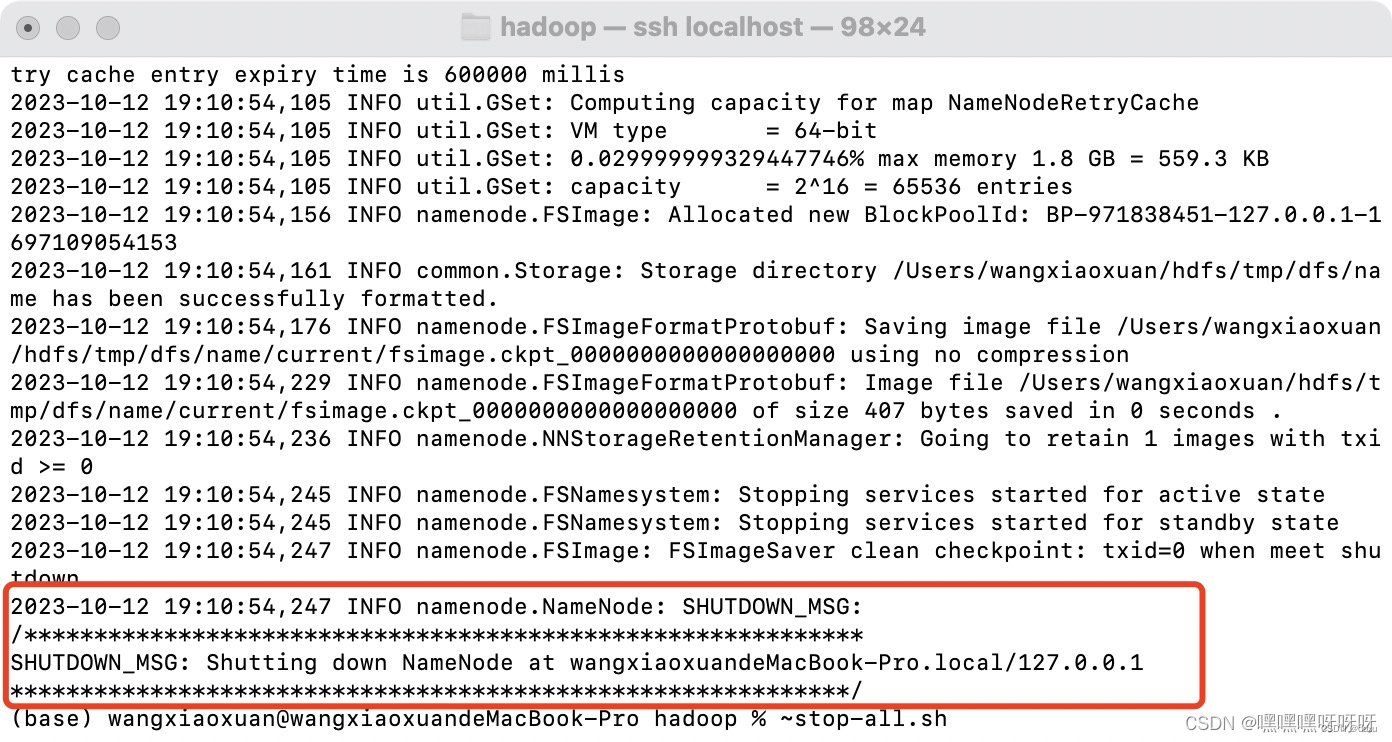
执行【start-all.sh】,查看resourcemanager 和nodemanagers是否启动成功

执行【jps】可查看进程

5.验证
在浏览器中输入http://localhost:9870/
显示如下:

二、安装HBase
参考了此文
1.下载安装包,我下载的是2.6.0,解压
2.配置
(1)vim conf/hbase-site.xml 去配置hbase.rootdir,来选择HBase将数据写到哪个目录
<configuration>
<property>
<name>hbase.rootdir</name>
<value>hdfs://localhost:9000/hbase</value>
</property>
<property>
<name>hbase.cluster.distributed</name>
<value>true</value>
</property>
<property>
<name>hbase.unsafe.stream.capability.enforce</name>
<value>false</value>
</property>
</configuration>hbase.rootdir:该参数制定了HReion服务器的位置,即数据存放的位置。主要端口号要和Hadoop相应配置一致。
hbase.cluster.distributed:HBase的运行模式。false是单机模式,true是分布式模式。若为false, HBase和Zookeeper会运行在同一个JVM里面,默认为false。
3.启动HBase
cd /users/shuaizai/hbase/hbase-2.3.0/bin,执行start-hbase.sh
启动完成后通过jps命令检查HBase进程:
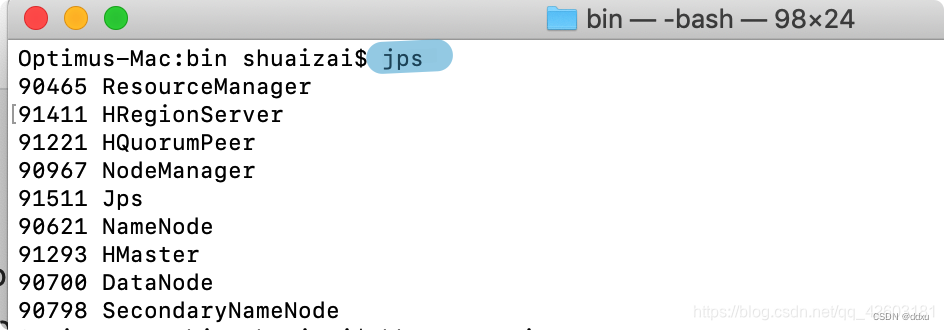
启动成功后可以看到几个正在运行的Java进程,包括Hadoop(DataNode、NameNode)、Zookeeper(HQuorumPeer)和HBase(HMaster、HRegionServer)。
可以打开http://localhost:16010/master-status 查看
4.操作
- 进入HBase交互式界面
hbase shell,status命令查看HBase集群运行状态,list命令列出HBase库中的表:

create 'student','Sname','Ssex','Sage','Sdept','course'
5.退出
- 关闭HBase
先退出exit,然后输入stop-abase.sh
三、Flume
参考此文,我用的brew,之前没有安装homebrew,安装后再用brew install flume安装的Flume。
不知道是网络问题还是什么原因,我安装下载了差不多一天,占用空间快2G才安装完成,中间失败好几次,重复执行就好了。
1.配置环境变量
vim ~/.bash_profile ,路径修改为自己的flume安装路径:
export FLUME_HOME=/usr/local/Cellar/flume/1.11.0/libexec
export FLUME_CONF_DIR=$FLUME_HOME/conf
export PATH=$FLUME_HOME/bin:$PATHsource ~/.bash_profile 使配置生效
2.配置flume-env.sh
cd /opt/homebrew/Cellar/flume/1.9.0_1/libexec/conf
cp flume-env.sh.template flume-env.sh
vim flume-env.shexport JAVA_HOME=/Library/Java/JavaVirtualMachines/jdk-17.jdk/Contents/Home
export JAVA_OPTS="-Xms100m -Xmx2000m -Dcom.sun.management.jmxremote"
根据自己jdk情况修改配置即可
执行 flume-ng version查看版本号。

安装完成