🌈 个人主页:danci_
🔥 系列专栏:《设计模式》《MYSQL》
💪🏻 制定明确可量化的目标,坚持默默的做事。
✨欢迎加入探索MYSQL索引数据结构之旅✨
👋 大家好!文本学习研究InnoDb索引数据结构和算法,从而弄明白为什么添加索引之后查询速度会有质的提升。
👋 无论您是刚接触MySQL的初学者,还是希望深入优化性能的资深开发者,这篇文章都将为您揭开MySQL索引的神秘面纱,让您掌握其中的奥秘,进而提升数据库操作的效率和精度。快来一起探索吧!
🚀 前几天一位朋友跟我聊他面试的一问题:“为数据库表添加索引为何提高查询性能?”。
💪 这个问题让我深思,所以把部分思考分享出来。欢迎大家评论讨论和互相学习。
1. 什么是索引?
2.InnoDB的数据结构是什么?为什么选这个数据结构?
目录
一、索引
1.1 什么是索引?
1.2 索引类型及应用场景
二、索引数据结构
2.1 数据结构
2.2 普通二叉树
2.3 平衡二叉树
2.4 b-tree
2.5 b+tree
一、索引
1.1 什么是索引?
我经常问面试者,什么是索引?如果是你该怎么回答?先给出自己的答案,再用三个10原则提问自己。
三个10原则:
10分钟之后再思考一下自己刚刚的回答是否满意,
10小时之后再思考一下自己刚刚的回答是否满意,
10天之后再思考一下自己刚刚的回答是否满意,
停几分钟思考一下。
定义:索引是为提升查询速度的排好序的数据结构。
是数据结构应该好理解,
思考:为什么是排好序的?
1.2 索引类型及应用场景
| 索引类型 | 描述 | 应用场景 |
| 普通索引 | 定义:基本的索引类型,它没有任何限制,唯一任务就是加快系统对数据的访问速度 特点:允许重复值、允许为空 创建语句:create index `索引名称` on 表名(列名 排序规则) using 使用的数据结构; | |
| 唯一索引 | 定义:与普通索引类似,不同的是创建唯一性索引的目的1是为了提高访问速度,2是为了避免数据出现重复 特点:数据不重复 创建语句:create union index `索引名称` on 表名(列名 排序规则) using 使用的数据结构; | 为提升查询速度的同时又要保证数据的唯一性时 |
| 主键索引 | 定义:主键索引是一种特殊的唯一索引 特点:不允许值重复,不允许值为空 创建语句:不能用create index来创建,是用primary key 来创建 | mysql中任何一张都有主键索引,如果创建表时没有指定字段为主键,mysql会自动创建一个隐藏的主键索引。 |
| 空间索引 | 定义:空间索引是对空间数据类型的字段建立的索引,使用 SPATIAL 关键字进行扩展 特点:NOT NULL,地理空间数据类型 创建语句:索引类型换成spatial即可 | 空间索引用于地理空间数据类型 GEOMETRY。在平时的工作中很少用到(我是从来没用过)。 |
| 全文索引 | 定义:全文索引主要用来查找文本中的关键字,只能在 CHAR、VARCHAR 或 TEXT 类型的列上创建。在 MySQL 中只有 MyISAM 存储引擎支持全文索引 特点:允许重复值和空值,只能用于创建 char,varchar,text 类型的列 创建语句:CREATE FULLTEXT INDEX `索引名称` ON 表名(列名); | 用于全文检索时。 但是如果业务中明确需要全文检索,或者需要根据关键词搜索出匹配的内容,那用 ES 就比较好。 |
二、索引数据结构
创建索引语法:CREATE 索引类型 INDEX 索引名称 ON 表名(列名 索引排序规则)USING 数据数据结构(eg: create unique index `idx_test_col1` on test(col1 asc )using btree)
用Navicat工具可以很直观看到 using 后面除了btree 还有hash(本次不讨论hash)
直接给结论:树的高度决定IO的次数,IO次数越少,查询速度越快。
2.1 数据结构
btree是一种树结构,树有如下数据结构:
- 普通二叉树
- 平衡二叉树
- b-tree
- b+tree
树的特点:左子节点小于等于父节点,右子节点大于等于父节点。
所以左子节点一定小于等于右子节点,所以可以说所有子节点,多左到右是排好序的。
2.2 普通二叉树
假设用普通二叉树来做为索引的存储结构,假设表的主键是int的自增主键,那么随便数据的插入,根据树的特点,边子节点大于等于父节点,那么普能二叉树结构构建的索引树最终的形态会像一个键表,如下图:
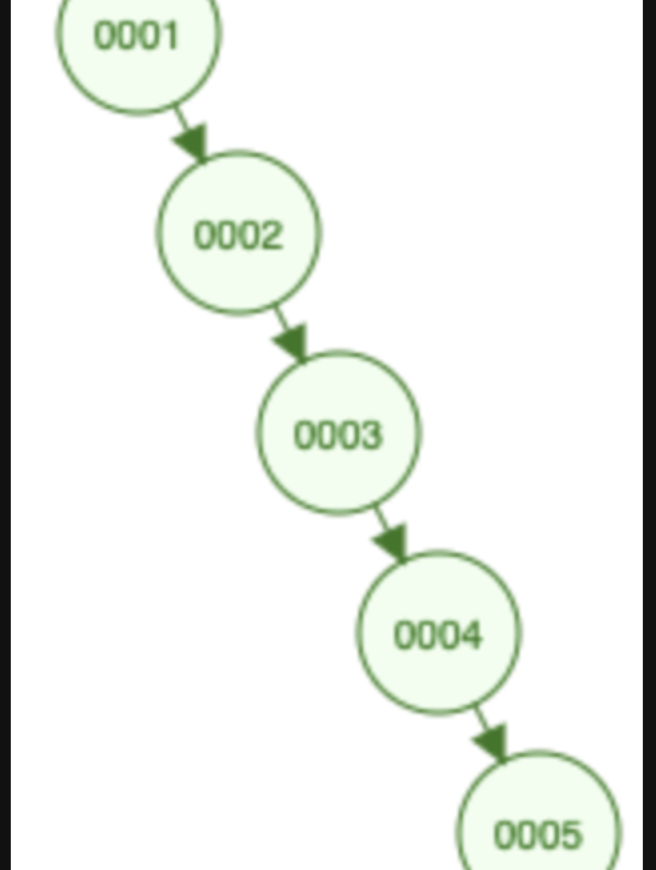
成了一个链表,根据链表的特点(链表可以看这个 ),如果有100万条数据,那么树的高度就有100万,很显示是不合适的。
2.3 平衡二叉树
平衡二叉树特点看这个,高度计算:h = log2(N+1),h约等于20,说明最坏的情况要做20次IO才能找到想要的数据。一次查询要走20次IO,如果同一时间内有100次查询就是2000次IO,搞不好服务就挂了,所以也不合适。
2.4 b-tree
结构如下图:

从图中可以看出(B-tree详解可参考)
- 每个节点存放的索引信息是不重复的
- 索引信息不重复,那么索引信息和数据信息就放在一起的,所以每个节点能放的索引信息就变没多少。
mysql默认的一叶数据大小为16kb,假如表每行的数据为1kb,那个每个节点只能放16个索引信息,假设表有100万条数据,16 * 16 * 16 * 16 * 16 = 1048576,树高度也有5
看似树的高度大大减少了,如上图,如果是范围查询,跨数据叶查询,若查小于等小5的数据,如果先找到0000,0001,0002,要找到0004必须要回到父节点再到0004节点,对于100万条数据的树结构,很有可能要回很多个父节点。实际的IO次数是5的倍数。所以也不合适。
由此B+ tree出现
2.5 b+tree
结构如下:

从图中可以看出(B+Tree详解可参考)
- 叶子中包含所有非叶子节点的信息(则非叶子节点能存放更多的索引信息)
- 叶子节点有一个箭头指向另一个叶子节点
在mysql中使用B+Tree来作为索引的存储结构还做了修改
叶子间的箭头是双向指向的,则对于跨数据叶的范围查询就不用返回到父点再找到另一个数据叶的数据了,相对物B- tree大大减少了IO次数。
非叶子节点只存放索引信息,数据信息全部存放到叶子节点中。
对于高度为3,B+tree能丰放多少呢(上篇计算过详见轻松上手MYSQL:优化MySQL慢查询,让数据库起飞)这里不再计算。
结论:非叶子节点能存放的索引信息越多,树的高度就越低,IO次数就越少,获取数据的速度就越快。