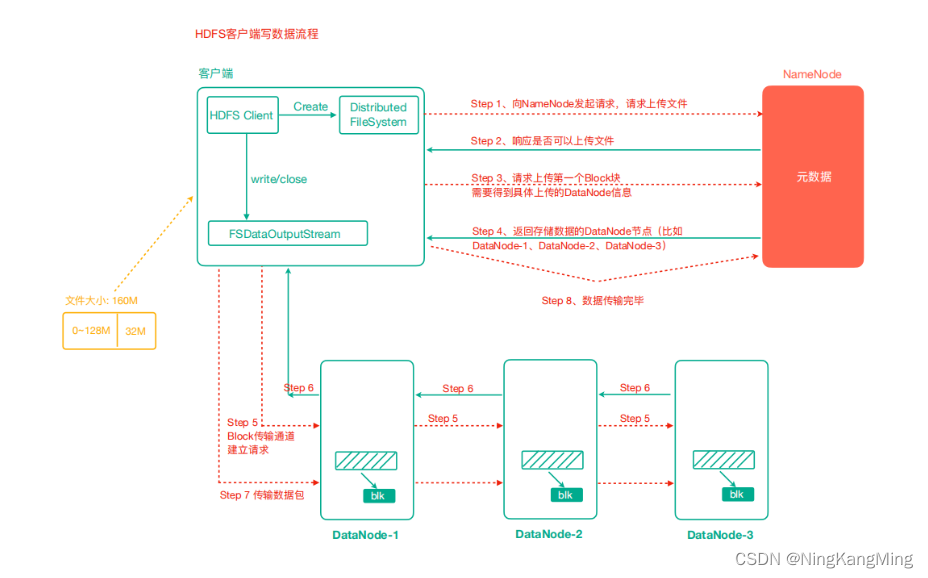
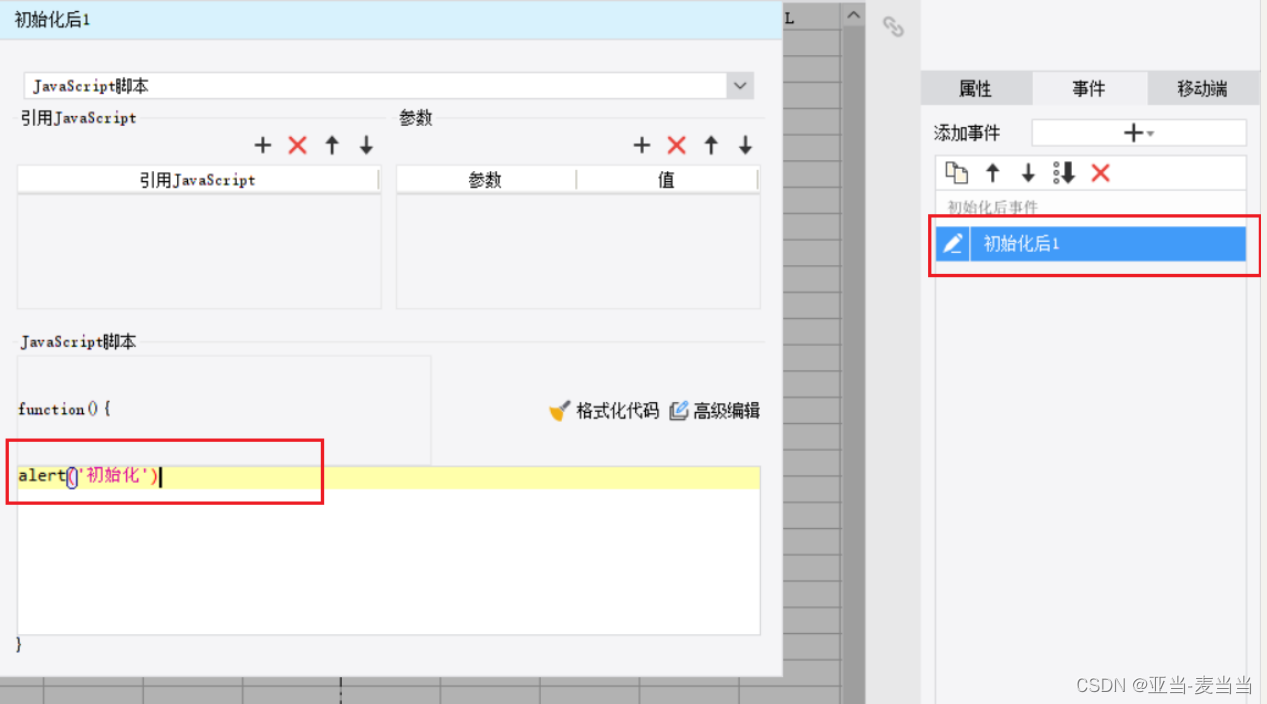
循环队列是一种线性数据结构,其操作表现基于 FIFO(First In First Out,先进先出)原则并且队尾被连接在队首以形成一个循环。
这种结构克服了普通队列在元素入队和出队时需要移动大量元素的缺点。
在循环队列中,当元素到达队列尾部时,下一个元素会循环回到队列的开头。
基本概念
- 队列:队列是一种特殊的线性表,只允许在表的前端(front)进行删除操作,而在表的后端(rear)进行插入操作。队列中没有元素时,称为空队列。
- 循环队列:为了充分利用向量空间,克服“假溢出”的现象,将队列存储空间的最后一个位置绕到第一个位置,形成逻辑上的环状空间,供队列循环使用。
循环队列的实现
循环队列通常使用数组来实现,并设置两个指针:front(队首指针)和rear(队尾指针)。它们分别指向队列的第一个元素和最后一个元素的下一个位置。
- 初始化:设置
front = 0和rear = -1(或rear = 0,但此时队列为空,所以最好使用-1表示没有元素)。 - 入队(enqueue):
- 如果队列已满(
(rear + 1) % size == front),则无法添加新元素。 - 否则,将元素添加到
rear所指向的位置,并将rear向后移动一位((rear + 1) % size)。
- 如果队列已满(
- 出队(dequeue):
- 如果队列为空(
front == rear),则无法删除元素。 - 否则,从
front所指向的位置删除元素,并将front向后移动一位((front + 1) % size)。
- 如果队列为空(
- 判断队列是否为空:
front == rear - 判断队列是否已满:
(rear + 1) % size == front(注意这里使用取模运算来处理循环)
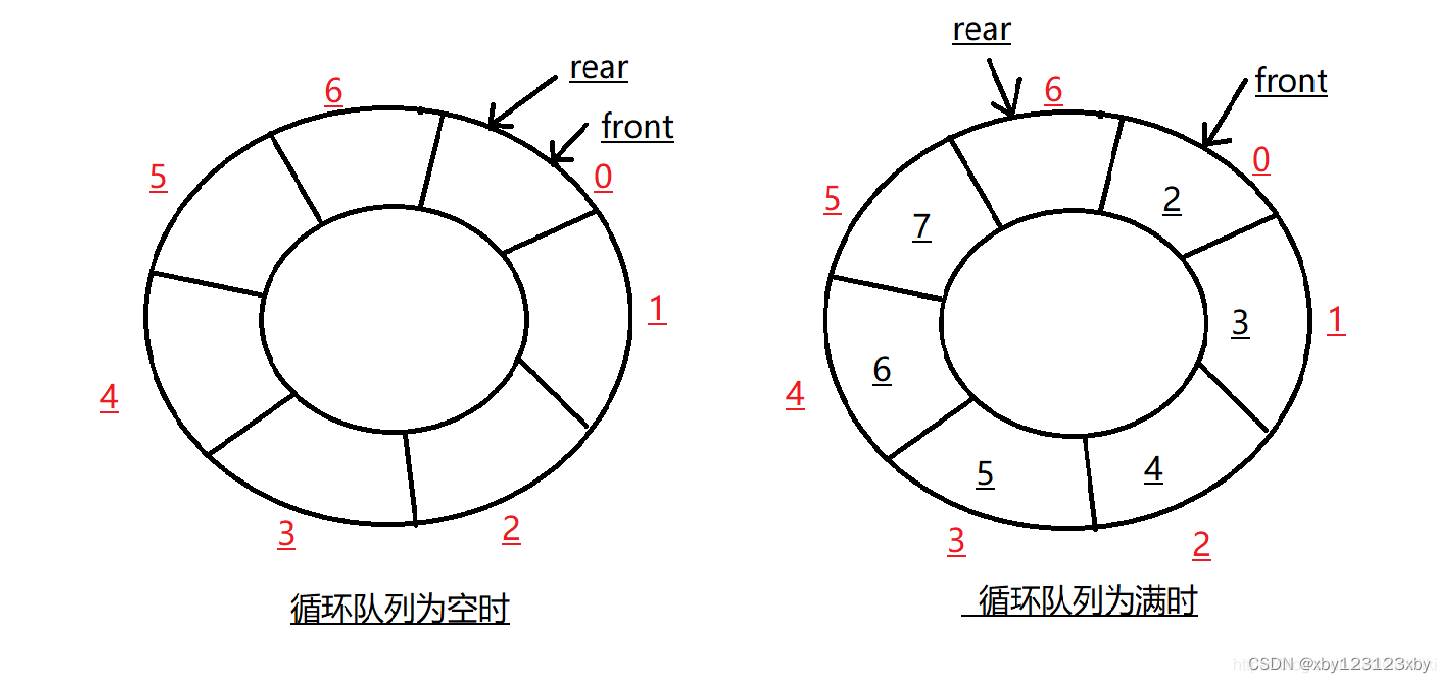
示例
假设有一个循环队列的容量为5,初始时front = 0,rear = -1。当依次入队元素1, 2, 3, 4, 5后,front = 0,rear = 4。如果再入队一个元素6,则rear会变为0(因为(4 + 1) % 5 = 0),此时front和rear再次相等,但队列并没有满,因为它们是循环的。
优点
- 循环队列克服了假溢出的现象,能够更充分地利用存储空间。
- 通过取模运算,可以快速定位队首和队尾的位置,实现高效的入队和出队操作。
注意事项
- 在计算队列长度时,需要使用
(rear - front + capacity) % capacity(如果rear < front)或(rear - front + 1)(如果rear >= front)来确保得到正确的长度。 - 当
front和rear相等时,需要根据队列的初始化情况来判断队列是为空还是满。一种常见的做法是在入队时检查是否已满,在出队时检查是否为空。
让我们看看代码吧~~~
public class Queue {
private int[] elements;//用于存储队列元素的数组。
private int size;//当前队列中的元素数量
private int front; // 指向队列前端(即下一个出队元素)的索引
private int rear; // 指向队列后端(即下一个入队位置)的索引
//构造函数:初始化一个大小为8的数组
public Queue() {
elements = new int[8];
size = 0;//表示队列当前为空
front = 0;//表示队列的前端在数组的起始位置
rear = -1;//表示队列的后端还没有放置任何元素(即将要放置的第一个元素会在索引0处)
}
public void enqueue(int v) {
if (size == elements.length) {//检查队列是否已满(即 size 是否等于 elements 的长度)
//如果队列已满,则创建一个新的、容量是原来两倍的数组
int[] newElements = new int[elements.length * 2];
for (int i = 0; i < size; i++) {
newElements[i] = elements[(front + i) % elements.length];
}
elements = newElements;//将elements的引用更新为新创建的数组newElements
front = 0;
rear = size - 1;
}
rear = (rear + 1) % elements.length;
elements[rear] = v;
size++;
}
public int dequeue() {
if (empty()) {//检查队列是否为空(使用empty()方法)。如果队列为空,则抛出一个运行时异常。
throw new RuntimeException("Queue is empty");
}
int v = elements[front];//获取front所指向的元素的值,并将其存储在变量v中
front = (front + 1) % elements.length;//front指针以指向下一个元素
size--;
return v;
}
//如果size为0,则返回true;否则返回false
public boolean empty() {
return size == 0;
}
public int getSize() {
return size;
}
}我们把其中关键代码进行详细分析一下:
elements = newElements;//将elements的引用更新为新创建的数组newElements
front = 0;
rear = size - 1;elements = newElements; 这行代码是一个赋值操作,它将 newElements 数组的引用赋值给 elements 变量。这意味着从现在开始,elements 和 newElements 都指向同一个数组对象在内存中的位置。
这样做有几个重要的影响:
- 内存管理:原数组
elements(以及它之前指向的内存空间)不再被Queue类的任何成员变量引用。如果没有其他引用指向这个数组,那么它将成为垃圾回收(Garbage Collection)的目标,内存空间会被释放。 - 后续操作:之后对
elements的任何操作(如添加、删除或访问元素)都会在新数组上进行,而不是在原来的小数组上。 - 引用更新:由于
front和rear指针是相对于elements数组来计算的,所以在更新elements引用后,你需要相应地更新front的值(在你的例子中,它被设置为0),以确保后续操作正确。rear的值在复制元素后已经是正确的(即size - 1),因为它指向的是新数组中最后一个元素的下一个位置。
rear = (rear + 1) % elements.length;
elements[rear] = v;
size++;这三行代码是队列实现中用于执行入队(enqueue)操作的关键部分,具体来说:
rear = (rear + 1) % elements.length;
这行代码是在更新队列的尾部(rear)指针。队列是一种先进先出(FIFO)的数据结构,新元素总是添加到队列的尾部。由于队列可能是一个循环队列,因此需要使用模运算(%)来确保rear的值在数组的有效索引范围内。如果rear加1后超出了数组的长度,模运算会将其“回绕”到数组的起始位置。
elements[rear] = v;
这行代码是将新元素v存储在数组的rear位置。这是队列中元素添加的实际操作,它将新元素放置在队列的尾部。
size++;
这行代码是增加队列的大小(size)。队列的大小表示队列中当前存储的元素数量。每当一个新元素被添加到队列时,队列的大小就应该增加1。
综上所述,这三行代码共同完成了队列的入队操作:更新尾部指针、在尾部添加新元素、并增加队列的大小。
public int dequeue() {
if (empty()) {//检查队列是否为空(使用empty()方法)。如果队列为空,则抛出一个运行时异常。
throw new RuntimeException("Queue is empty");
}
int v = elements[front];//获取front所指向的元素的值,并将其存储在变量v中
front = (front + 1) % elements.length;//front指针以指向下一个元素
size--;
return v;
}int v = elements[front];
这里,elements 是一个数组(通常用于存储队列中的元素),而 front 是一个变量(通常是一个索引),指向队列中的第一个元素。这行代码从 elements 数组中取出 front 索引处的元素值,并将其存储在变量 v 中。
front = (front + 1) % elements.length;
这行代码更新 front 指针以指向队列中的下一个元素。由于队列可能是循环的(即数组首尾相连),所以使用模运算 % 来确保 front 的值在数组的有效范围内。如果 front 已经指向数组的最后一个元素,则将其重置为数组的起始位置(索引为 0)。
size--
这行代码减少队列的 size 变量值,以反映队列中元素数量的减少。size 通常是一个变量,用于跟踪队列中当前元素的数量。
今天就先介绍这个了,我们下期见!