目录
- 摘要
- Abstract
- 一、文献阅读
- 1.1 摘要
- 1.2 研究背景
- 1.3 论文方法
- 1.4 模块分析
- 1.5 网络规格
- 1.6 高效的端到端对象检测
- 1.7 mobile former模块代码
目录
- 摘要
- Abstract
- 一、文献阅读
- 1.1 摘要
- 1.2 研究背景
- 1.3 论文方法
- 1.4 模块分析
- 1.5 网络规格
- 1.6 高效的端到端对象检测
- 1.7 mobile former模块代码
摘要
Abstract
一、文献阅读
题目:Mobile-Former: Bridging MobileNet and Transformer
1.1 摘要
我们提出了 Mobile-Former,这是一种 MobileNet 和 Transformer 的并行设计,它们之间通过双向桥接结构进行通信。这种结构利用了 MobileNet 在局部处理方面的优势和 Transformer 在全局交互方面的优势。桥接结构实现了局部和全局特征的双向融合。与最近的 Vision Transformer 工作不同,Mobile-Former 中的 Transformer 包含非常少的可学习 token,这些 token 是随机初始化的,用于学习全局先验,从而实现低计算成本。结合我们提出的轻量级交叉注意力来模拟桥接,Mobile-Former 不仅计算效率高,而且具有更强的表征能力。在 ImageNet 分类任务中,它在从 25M 到 500M FLOPs 的低 FLOP 范围内优于 MobileNetV3。例如,在 294M FLOPs 时,Mobile-Former 达到了 77.9% 的 top-1 准确率,比 MobileNetV3 高出 1.3%,但计算量节省了 17%。当转移到目标检测时,在 RetinaNet 框架中 Mobile-Former 比 MobileNetV3 高出 8.6 AP。此外,我们通过在 DETR 中用 Mobile-Former 替换骨干网络、编码器和解码器,构建了一个高效的端到端检测器,比 DETR 高出 1.1 AP,但计算成本节省了 52%,参数减少了 36%。
1.2 研究背景
Mobile-Former的研究背景根植于对高效深度学习模型的不断追求,尤其是在移动和嵌入式视觉应用领域。传统的卷积神经网络(CNNs),如MobileNet系列,通过使用深度可分离卷积等技术,在局部特征提取上表现出色,但它们在捕捉图像全局上下文信息方面存在局限。另一方面,Transformer架构,尽管在处理全局依赖关系方面具有显著优势,但其计算成本较高,尤其是在视觉任务中,这限制了其在资源受限的设备上的应用。
随着移动设备和实时视觉系统的普及,对于能够在有限计算资源下运行的高效模型的需求日益增长。然而,现有的轻量级CNNs在处理复杂的视觉任务时,往往难以平衡计算效率和表示能力。例如,MobileNetV3虽然在低FLOPs范围内表现出色,但它在处理需要长距离依赖关系的任务时可能不够有效。与此同时,尽管Vision Transformer(ViT)等模型在大规模数据集上展现出了强大的性能,但它们在小规模数据集上的泛化能力较差,且计算成本较高,不适合部署在计算资源受限的环境中。
此外,早期尝试将CNN和Transformer结合的方法,如串联结构,并没有充分发挥两者的优势。这些方法通常将卷积和自注意力机制按顺序堆叠,可能导致全局特征的捕捉不足,或者在模型设计上缺乏灵活性,难以适应不同的计算预算和任务需求。
针对这些不足,Mobile-Former提出了一种创新的并行设计,通过一个双向桥接结构,实现了MobileNet的局部特征提取能力和Transformer的全局特征捕捉能力的有机结合。这种设计不仅提高了模型的表示能力,还显著降低了计算成本,使得Mobile-Former在低FLOPs范围内的性能超过了现有的轻量级CNNs和ViT变体。通过这种方式,Mobile-Former旨在解决现有方案在资源受限设备上部署时面临的挑战,同时为图像分类和目标检测等视觉任务提供了一种高效的解决方案。
1.3 论文方法
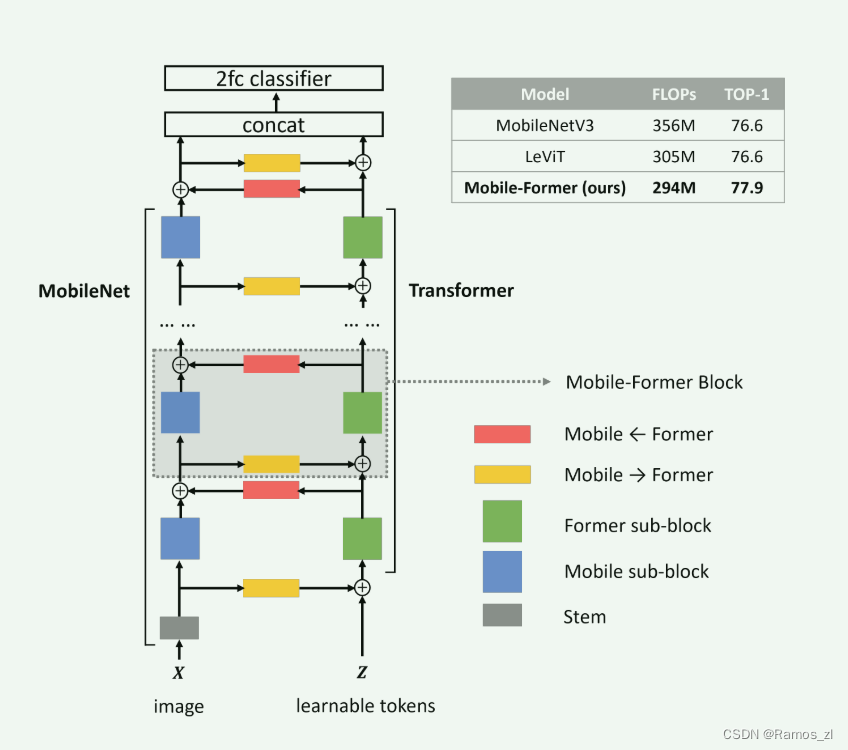
并行结构:Mobile-Former将MobileNet和Transformer进行并行化,并通过双向交叉注意力连接它们(见图1)。Mobile(指MobileNet)接收一张图片作为输入(X ∈ RHW×3),并应用倒置瓶颈块来提取局部特征。Former(指Transformer)接收可学习的参数(或称为token)作为输入,表示为Z ∈ RM×d,其中M和d分别是token的数量和维度。这些token是随机初始化的。与视觉Transformer(ViT)不同,在ViT中,token线性地映射局部图像块,而在Former中,token的数量显著更少(在本文中M ≤ 6),每个token代表了图像的一个全局先验。这导致计算成本大幅降低。
低成本双向桥接:Mobile和Former通过一个双向桥接进行通信,在这里局部特征和全局特征以双向的方式进行融合。这两个方向分别表示为Mobile→Former和Mobile←Former。我们提出了一个轻量级的交叉注意力机制来模拟这一过程,在该机制中,为了节省计算量,从Mobile一侧移除了投影(WQ, WK, WV),但在Former一侧则保留了这些投影。交叉注意力是在Mobile的瓶颈处计算的,即在通道数较低的地方。具体来说,从局部特征图X到全局token Z的轻量级交叉注意力计算如下:
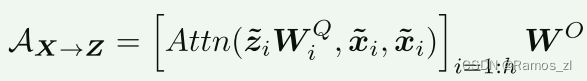
-
注意力机制:使用标准的注意力函数Attn(Q, K, V),其中Q是Query(查询),K是Key(键),V是Value(值)。
-
多头注意力:将局部特征X和全局token Z分割成多个头部(h heads),对于第i个头,计算其对应的轻量级交叉注意力。
-
投影矩阵:在Mobile→Former方向上,移除了键和值的投影矩阵(WK和WV),只保留了查询的投影矩阵WQi,以减少计算量。
-
计算:对于Mobile→Former,交叉注意力AX→Z是从局部特征X到全局token Z的,计算方式是将每个头部的注意力分数进行拼接和组合。
-
瓶颈处的计算:由于在Mobile的瓶颈处通道数较低,因此在这里执行交叉注意力的计算可以进一步降低计算成本。
1.4 模块分析
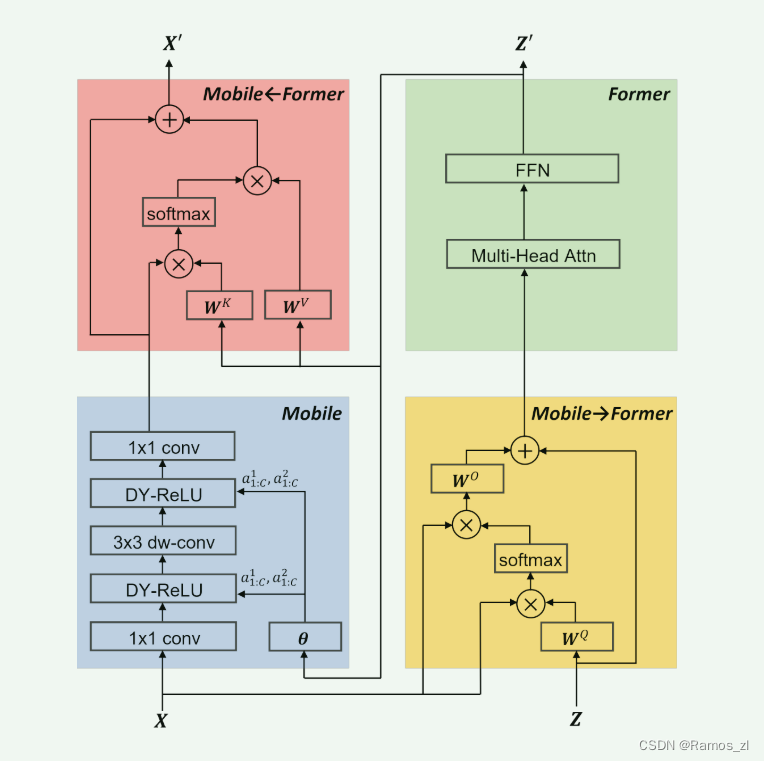
Mobile-Former块:Mobile-Former 由堆叠的 Mobile-Former 块组成(见图 1)。 每个块有四个支柱:Mobile 子块、Former 子块和双向交叉注意力 Mobile←Former 和 Mobile→Former(如图 3 所示)。
输入和输出:Mobile-Former块有两个输入:(a) 本地特征图X ∈ RHW×C,它在高度H和宽度W上具有C个通道;(b) 全局token Z ∈ RM×d,其中M和d分别是token的数量和维度。注意,所有块中的M和d都是相同的。Mobile-Former块输出更新后的本地特征图X’和全局token Z’,这些将作为下一个块的输入。
Mobile子块:如图3所示,Mobile子块以特征图X作为输入,其输出被用作Mobile←Former的输入。它与文献中的倒置瓶颈块略有不同,区别在于将ReLU替换为动态ReLU作为激活函数。与原始的动态ReLU不同,原始的动态ReLU是通过在平均池化特征上应用两层MLP(多层感知机)层来生成参数的,而我们通过在Former的第一个全局token输出z’1上应用两层MLP(图中的θ)来节省平均池化步骤。请注意,对于所有块,深度卷积的核大小都是3×3。
Former子块:Former子块是一个标准的Transformer块,包括多头注意力(Multi-Head Attention, MHA)和前馈网络(Feed-Forward Network, FFN)。在FFN中使用的扩展比率是2(而不是4)。我们遵循文献使用后层归一化(post layer normalization)。Former的处理位于Mobile→Former和Mobile←Former之间(见图3)。
- 多头注意力(MHA):这一部分允许模型在处理token时同时关注不同的位置,从而捕捉图像中的长距离依赖关系。
- 前馈网络(FFN):FFN通常包含两个线性变换,它们之间有一个激活函数。在Mobile-Former中,FFN的扩展比率设置为2,这意味着FFN的中间层的大小是输入层的两倍,而不是传统的四倍。这种设计有助于减少计算量,同时保持网络的表达能力。
- 后层归一化:在MHA和FFN之后,使用层归一化来稳定训练过程,并提高模型的泛化能力。这与Transformer架构中的常见做法一致。
- Former的处理位置:Former子块在Mobile→Former(局部特征到全局token的交叉注意力)和Mobile←Former(全局token到局部特征的交叉注意力)的计算之间进行处理。这意味着Former子块的输出将反馈到Mobile←Former,以进一步融合全局信息。
Mobile→Former:我们提出的轻量级交叉注意力(方程1)被用来将局部特征X融合到全局token Z中。与标准注意力机制相比,在局部特征X上的键(key)的投影矩阵WK和值(value)的投影矩阵WV被移除,以节省计算量(见图3)。
Mobile←Former:在这里,交叉注意力(方程2)的方向与Mobile→Former相反。它将全局token融合到局部特征中。局部特征作为查询(query),而全局token作为键(key)和值(value)。因此,我们保留了键WK和值WV的投影矩阵,但为了节省计算量,去除了查询WQ的投影矩阵,如图3所示。
计算复杂性:Mobile-Former块的四个组成部分具有不同的计算成本。给定一个大小为HW×C的输入特征图,以及M个全局token,每个token的维度为d,Mobile部分消耗的计算量最多,计算复杂度为O(HWC ^ 2)。Former和双向桥接的计算成本较低,消耗的总计算成本不到20%。具体来说,Former的自注意力和前馈网络(FFN)的计算复杂度为O(M ^ 2d + Md^2)。Mobile→Former和Mobile←Former的交叉注意力共享计算复杂度O(MHWC + MdC)。
1.5 网络规格
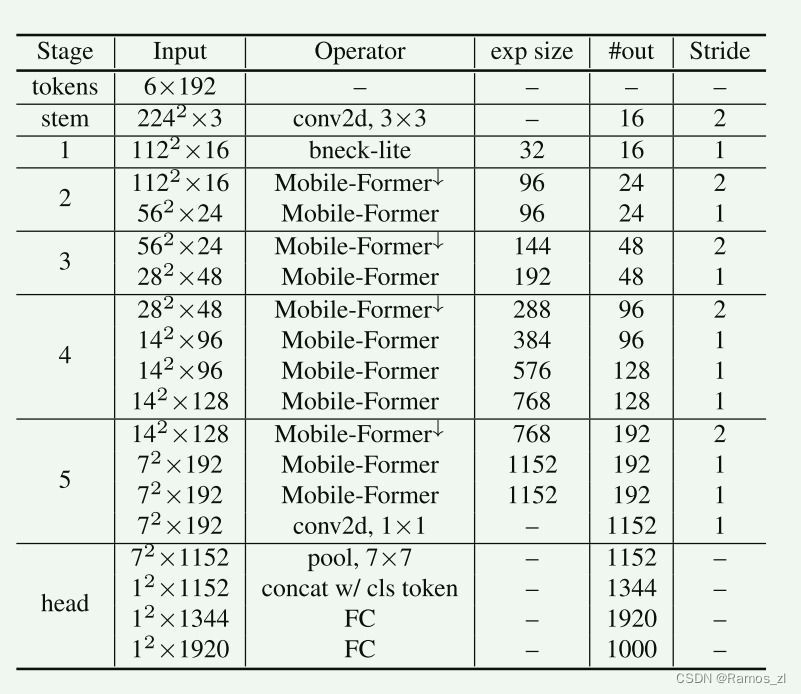
架构:表1展示了一个具有294M FLOPs的Mobile-Former架构,适用于224×224的图像尺寸,该架构堆叠了11个Mobile-Former块,这些块在不同的输入分辨率下工作。所有块都有六个维度为192的全局token。它以一个3×3的卷积作为起点,以及在第一阶段使用一个轻量级瓶颈块[18],该块通过堆叠一个3×3的深度卷积和一个逐点卷积来扩展然后压缩通道数。第2到第5阶段由Mobile-Former块组成。每个阶段通过一个称为Mobile-Former↓的下采样变种来处理下采样。分类头对局部特征应用平均池化,与第一个全局token连接,然后通过两个带有h-swish的全连接层。
1.6 高效的端到端对象检测
Mobile-Former可以很容易地用于目标检测的骨干网络和头部,提供了一个高效的端到端检测器。使用相同数量的目标查询(100个),它在性能上超越了DETR,但使用的FLOPs要低得多。
Backbone-Head架构:我们在骨干网络和头部都使用了Mobile-Former块(见图4),它们拥有独立的token。骨干网络有六个全局token,而头部有100个对象查询,这些查询的生成方式与DETR[1]类似。与DETR在头部只有一个尺度(1/32或1/16)不同,Mobile-Former头部采用了多尺度(1/32,1/16,1/8),由于其计算效率,这些多尺度的FLOPs很低。上采样通过双线性插值实现,然后加上具有相同分辨率的来自骨干网络的特征输出。所有对象查询逐步在从粗糙到精细的不同尺度上细化它们的表示,节省了FPN[19]中手动按大小分配对象跨尺度的过程。我们遵循DETR,在头部使用预测FFN(前馈网络)和辅助损失进行训练。头部是从零开始训练的,而骨干网络是在使用ImageNet预训练的。我们的端到端Mobile-Former检测器在计算上是高效的。使用Mobile-Former-508M作为骨干网络和头部中有九个Mobile-Former块的E2EMF-508M的总成本是41.4G FLOPs,明显低于DETR(86G FLOPs)。但它的性能超过了DETR 1.1 AP(43.1 vs. 42.0 AP)。头部结构的细节列在附录A中(见表13)。

空间感知动态ReLU在骨干网络中的应用:我们将骨干网络中的动态ReLU从空间共享扩展到空间感知,通过涉及所有全局token来生成参数,而不仅仅是使用第一个token,因为这些token具有不同的空间焦点。让我们将空间共享动态ReLU的参数生成表示为θ = f(z1),其中z1是第一个全局token,f(·)由两个带有中间ReLU激活的MLP(多层感知机)层建模。相比之下,空间感知动态ReLU为特征图中的每个空间位置i生成参数θi,使用所有全局token {zj},如下所示:
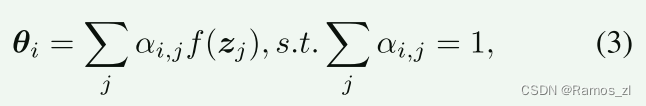
调整 head 中的位置嵌入:与在所有解码器层共享对象查询的位置嵌入的 DETR [1] 不同,随着每个块的特征图发生变化,我们细化了 head 中每个块之后的位置嵌入。 让我们将第 k 个块处的查询的特征和位置嵌入分别表示为 qf k 和 qp k。 它们的总和(qf k + qp k)用于计算对象查询和特征图之间的交叉注意力以及对象查询之间的自注意力,之后特征嵌入被更新为下一个块的输入 qf k+1 。 在这里,我们根据特征嵌入调整位置嵌入:

1.7 mobile former模块代码
class MobileFormer(nn.Module):
def __init__(
self,
block_args,
num_classes=1000,
img_size=224,
width_mult=1.,
in_chans=3,
stem_chs=16,
num_features=1280,
dw_conv='dw',
kernel_size=(3,3),
cnn_exp=(6,4),
group_num=1,
se_flag=[2,0,2,0],
hyper_token_id=0,
hyper_reduction_ratio=4,
token_dim=128,
token_num=6,
cls_token_num=1,
last_act='relu',
last_exp=6,
gbr_type='mlp',
gbr_dynamic=[False, False, False],
gbr_norm='post',
gbr_ffn=False,
gbr_before_skip=False,
gbr_drop=[0.0, 0.0],
mlp_token_exp=4,
drop_rate=0.,
drop_path_rate=0.,
cnn_drop_path_rate=0.,
attn_num_heads = 2,
remove_proj_local=True,
):
super(MobileFormer, self).__init__()
cnn_drop_path_rate = drop_path_rate
mdiv = 8 if width_mult > 1.01 else 4
self.num_classes = num_classes
#global tokens
self.tokens = nn.Embedding(token_num, token_dim)
# Stem
self.stem = nn.Sequential(
nn.Conv2d(in_chans, stem_chs, 3, stride=2, padding=1, bias=False),
nn.BatchNorm2d(stem_chs),
nn.ReLU6(inplace=True)
)
input_channel = stem_chs
# blocks
layer_num = len(block_args)
inp_res = img_size * img_size // 4
layers = []
for idx, val in enumerate(block_args):
b, t, c, n, s, t2 = val # t2 for block2 the second expand
block = eval(b)
t = (t, t2)
output_channel = _make_divisible(c * width_mult, mdiv) if idx > 0 else _make_divisible(c * width_mult, 4)
drop_path_prob = drop_path_rate * (idx+1) / layer_num
cnn_drop_path_prob = cnn_drop_path_rate * (idx+1) / layer_num
layers.append(block(
input_channel,
output_channel,
s,
t,
dw_conv=dw_conv,
kernel_size=kernel_size,
group_num=group_num,
se_flag=se_flag,
hyper_token_id=hyper_token_id,
hyper_reduction_ratio=hyper_reduction_ratio,
token_dim=token_dim,
token_num=token_num,
inp_res=inp_res,
gbr_type=gbr_type,
gbr_dynamic=gbr_dynamic,
gbr_ffn=gbr_ffn,
gbr_before_skip=gbr_before_skip,
mlp_token_exp=mlp_token_exp,
norm_pos=gbr_norm,
drop_path_rate=drop_path_prob,
cnn_drop_path_rate=cnn_drop_path_prob,
attn_num_heads=attn_num_heads,
remove_proj_local=remove_proj_local,
))
input_channel = output_channel
if s == 2:
inp_res = inp_res // 4
for i in range(1, n):
layers.append(block(
input_channel,
output_channel,
1,
t,
dw_conv=dw_conv,
kernel_size=kernel_size,
group_num=group_num,
se_flag=se_flag,
hyper_token_id=hyper_token_id,
hyper_reduction_ratio=hyper_reduction_ratio,
token_dim=token_dim,
token_num=token_num,
inp_res=inp_res,
gbr_type=gbr_type,
gbr_dynamic=gbr_dynamic,
gbr_ffn=gbr_ffn,
gbr_before_skip=gbr_before_skip,
mlp_token_exp=mlp_token_exp,
norm_pos=gbr_norm,
drop_path_rate=drop_path_prob,
cnn_drop_path_rate=cnn_drop_path_prob,
attn_num_heads=attn_num_heads,
remove_proj_local=remove_proj_local,
))
input_channel = output_channel
self.features = nn.Sequential(*layers)
# last layer of local to global
self.local_global = Local2Global(
input_channel,
block_type = gbr_type,
token_dim=token_dim,
token_num=token_num,
inp_res=inp_res,
use_dynamic = gbr_dynamic[0],
norm_pos=gbr_norm,
drop_path_rate=drop_path_rate,
attn_num_heads=attn_num_heads
)
# classifer
self.classifier = MergeClassifier(
input_channel,
oup=num_features,
ch_exp=last_exp,
num_classes=num_classes,
drop_rate=drop_rate,
drop_branch=gbr_drop,
group_num=group_num,
token_dim=token_dim,
cls_token_num=cls_token_num,
last_act = last_act,
hyper_token_id=hyper_token_id,
hyper_reduction_ratio=hyper_reduction_ratio
)
#initialize
self._initialize_weights()
def _initialize_weights(self):
for m in self.modules():
if isinstance(m, nn.Conv2d):
n = m.kernel_size[0] * m.kernel_size[1] * m.out_channels
m.weight.data.normal_(0, math.sqrt(2. / n))
if m.bias is not None:
m.bias.data.zero_()
elif isinstance(m, nn.BatchNorm2d):
m.weight.data.fill_(1)
m.bias.data.zero_()
elif isinstance(m, nn.Linear):
n = m.weight.size(1)
m.weight.data.normal_(0, 0.01)
m.bias.data.zero_()
def forward(self, x):
# setup tokens
bs, _, _, _ = x.shape
z = self.tokens.weight
tokens = z[None].repeat(bs, 1, 1).clone()
tokens = tokens.permute(1, 0, 2)
# stem -> features -> classifier
x = self.stem(x)
x, tokens = self.features((x, tokens))
tokens, attn = self.local_global((x, tokens))
y = self.classifier((x, tokens))
return y