目录
一、Set简介
二、HashSet简介
2.1 简介
2.2 HashSet继承关系
三、源码分析
3.1 成员属性
3.2 构造方法
3.3 添加元素
3.3.1 add()方法
3.3.2 addAll()方法
3.4 删除元素
3.4.1 remove()方法
3.4.2 removeAll()方法
3.5 查询元素
3.5.1 contains()方法
3.5.2 containsAll方法
3.6 容量检查
四、HashSet的遍历方法
4.1 通过Iterator遍历HashSet
4.2 通过for-each遍历HashSet
五、HashSet示例
六、总结
一、Set简介
集合(Collection)和集合(Set)有什么区别?
集合,这个概念有点模糊。
- 广义上来讲,Java中的集合是指java.util包下面的容器类,包括和Collection及Map相关的所有类。
- 中义上来讲,我们一般说集合特指Java集合中的Collection相关的类,不包含Map相关的类。
- 狭义上来讲,数学上的集合是指不包含重复元素的容器,即集合中不存在两个相同的元素,在Java里面对应Set。
具体怎么来理解还是要看上下文环境。
比如,面试别人让你说下Java中的集合,这时候肯定是广义上的。
再比如,下面我们讲的把另一个集合中的元素全部添加到Set中,这时候就是中义上的。
HashSet是Set的一种实现方式,底层主要使用HashMap来确保元素不重复(所有的Set的实现类都是基于Map实现的)。
二、HashSet简介
2.1 简介
对于HashSet而言,它是基于HashMap来实现的,底层采用HashMap来保存元素。所以如果对HashMap比较熟悉,那么学习HashSet就会非常容易。
- HashSet 是一个 没有重复元素的集合 。
- 它是由HashMap实现的, 不保证元素的顺序 ,而且 HashSet允许使用 null 元素 。
- HashSet是 非同步的 。如果多个线程同时访问一个哈希 set,而其中至少一个线程修改了该 set,那么它必须 保持外部同步。这通常是通过对自然封装该 set 的对象执行同步操作来完成的。如果不存在这样的对象,则应该使用 Collections.synchronizedSet 方法来“包装” set。最好在创建时完成这一操作,以防止对该 set 进行意外的不同步访问:
Set s = Collections.synchronizedSet(new HashSet(...));HashSet通过iterator()返回的 迭代器是fail-fast的。
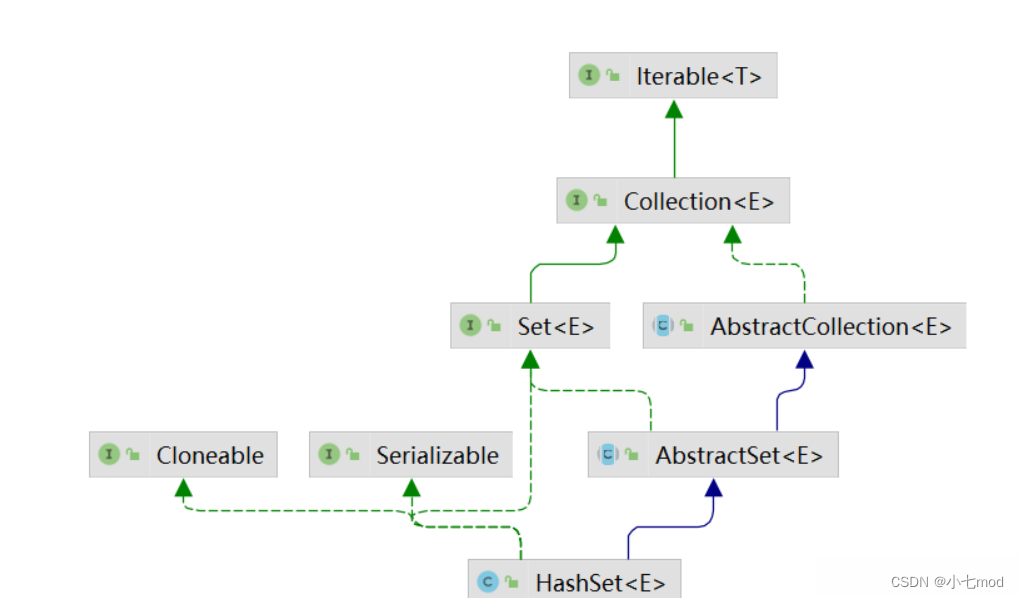
2.2 HashSet继承关系
HashSet定义:
public class HashSet<E>
extends AbstractSet<E>
implements Set<E>, Cloneable, java.io.Serializable针对类:HashSet继承AbstractSet抽象Set类。 针对接口:implements Set, Cloneable, java.io.Serializable,实现了Set Clonable Serializable接口。
继承图:
三、源码分析
3.1 成员属性
// 底层使用HashMap来保存HashSet的元素
private transient HashMap<E,Object> map;
// 由于Set只使用到了HashMap的key,所以此处定义一个静态的常量Object类,来充当HashMap的value
private static final Object PRESENT = new Object();看到这里就明白了,和我们前面说的一样,HashSet是用HashMap来保存数据,而主要使用到的就是HashMap的key。
看到 private static final Object PRESENT = new Object();不知道你有没有一点疑问呢。
这里使用一个静态的常量Object类来充当HashMap的value,既然这里map的value是没有意义的,为什么不直接使用null值来充当value呢?
比如写成这样子 private final Object PRESENT = null ;
我们都知道的是,Java首先将变量PRESENT分配在栈空间,而将new出来的Object分配到堆空间,这里的new Object()是占用堆内存的(一个空的Object对象占用8byte),而null值我们知道,是不会在堆空间分配内存的。
那么想一想这里为什么不使用null值。想到什么吗,看一个异常类 java.lang.NullPointerException,这绝对是Java程序员的一个噩梦,这是所有Java程序猿都会遇到的一个异常,你看到这个异常你以为很好解决,但是有些时候也不是那么容易解决,Java号称没有指针,但是处处碰到NullPointerException。所以啊,为了从根源上避免NullPointerException的出现,浪费8个byte又怎么样,在下面的代码中我再也不会写这样的代码了if (xxx == null) { … } else {….}。
3.2 构造方法
/**
* 使用HashMap的默认容量大小16和默认加载因子0.75初始化map,构造一个空HashSet
*/
public HashSet() {
map = new HashMap<E,Object>();
}
/**
* 构造一个指定Collection参数的HashSet,这里不仅仅是Set,只要实现Collection接口的容器都可以
*/
public HashSet(Collection<? extends E> c) {
map = new HashMap<E,Object>(Math. max((int) (c.size()/.75f) + 1, 16));
// 使用Collection实现的Iterator迭代器,将集合c的元素一个个加入HashSet中
addAll(c);
}
/**
* 使用指定的初始容量大小和加载因子初始化map,构造一个HashSet
*/
public HashSet(int initialCapacity, float loadFactor) {
map = new HashMap<E,Object>(initialCapacity, loadFactor);
}
/**
* 使用指定的初始容量大小和默认的加载因子0.75初始化map,构造一个HashSet
*/
public HashSet(int initialCapacity) {
map = new HashMap<E,Object>(initialCapacity);
}
/**
* 非public,主要是给LinkedHashSet使用的
* 不对外公开的一个构造方法(默认default修饰),底层构造的是LinkedHashMap,dummy只是一个标示参数,无具体意义
*/
HashSet(int initialCapacity, float loadFactor, boolean dummy) {
map = new LinkedHashMap<E,Object>(initialCapacity, loadFactor);
}
从构造方法可以很轻松的看出,HashSet的底层是一个HashMap,理解了HashMap后,这里没什么可说的。只有最后一个构造方法有写区别,这里构造的是LinkedHashMap,该方法不对外公开,意味着它只能被同一个包或者子类调用,实际上是提供给LinkedHashSet使用的,而第三个参数dummy是无意义的,只是为了区分其他构造方法。
3.3 添加元素
3.3.1 add()方法
直接调用HashMap的put()方法,把元素本身作为key,把PRESENT作为value,也就是这个map中所有的value都是一样的。
/**
* 利用HashMap的put方法实现add方法
*/
public boolean add(E e) {
return map.put(e, PRESENT)== null;
}其实HashSet就是利用HashMap来检查重复的,因为向HashSet中add元素的时候,实际就是调用的HashMap的put(),会将要加入Set的对象作为Key加入到HashMap中,而HashMap限制了Key不能有重复值。
3.3.2 addAll()方法
/**
* 添加一个集合到HashSet中,该方法在AbstractCollection中
*/
public boolean addAll(Collection<? extends E> c) {
boolean modified = false;
// 取得集合c迭代器Iterator
Iterator<? extends E> e = c.iterator();
// 遍历迭代器
while (e.hasNext()) {
// 将集合c的每个元素加入到HashSet中
if (add(e.next()))
modified = true;
}
return modified;
}
3.4 删除元素
3.4.1 remove()方法
直接调用HashMap的remove()方法,注意map的remove返回是删除元素的value,而Set的remove返回的是boolean类型。
这里要检查一下,如果是null的话说明没有该元素,如果不是null肯定等于PRESENT。
/**
* 利用HashMap的remove方法实现remove方法
*/
public boolean remove(Object o) {
return map.remove(o)==PRESENT;
}3.4.2 removeAll()方法
/**
* 删除指定集合c中的所有元素,该方法在AbstractSet中
*/
public boolean removeAll(Collection<?> c) {
boolean modified = false;
// 判断当前HashSet元素个数和指定集合c的元素个数,目的是减少遍历次数
if (size() > c.size()) {
// 如果当前HashSet元素多,则遍历集合c,将集合c中的元素一个个删除
for (Iterator<?> i = c.iterator(); i.hasNext(); )
modified |= remove(i.next());
} else {
// 如果集合c元素多,则遍历当前HashSet,将集合c中包含的元素一个个删除
for (Iterator<?> i = iterator(); i.hasNext(); ) {
if (c.contains(i.next())) {
i.remove();
modified = true;
}
}
}
return modified;
}
3.5 查询元素
Set没有get()方法,因为Set的get()似乎没有意义,不像List那样可以按index获取元素。
Set只有查询一个元素是否存在的方法。
3.5.1 contains()方法
这里只要一个检查元素是否存在的方法contains(),直接调用map的containsKey()方法。
/**
* 利用HashMap的containsKey方法实现contains方法
*/
public boolean contains(Object o) {
return map.containsKey(o);
}由于HashMap基于Hash表实现,Hash表实现的容器最重要的一点就是可以快速存取,那么HashSet对于contains方法,利用HashMap的containsKey方法,效率是非常之快的。这个方法也是HashSet最核心的卖点方法之一。
3.5.2 containsAll方法
/**
* 检查是否包含指定集合中所有元素,该方法在AbstractCollection中
*/
public boolean containsAll(Collection<?> c) {
// 取得集合c的迭代器Iterator
Iterator<?> e = c.iterator();
// 遍历迭代器,只要集合c中有一个元素不属于当前HashSet,则返回false
while (e.hasNext())
if (!contains(e.next()))
return false;
return true;
}3.6 容量检查
// 返回容器中数据的数量
public int size() {
return map.size();
}
// 容器是否为空
public boolean isEmpty() {
return map.isEmpty();
}
四、HashSet的遍历方法
4.1 通过Iterator遍历HashSet
第一步: 根据iterator()获取HashSet的迭代器。
第二步: 遍历迭代器获取各个元素 。
// 直接调用map的keySet的迭代器。返回的元素没有特定的顺序
public Iterator<E> iterator() {
return map.keySet().iterator();
}
// 假设set是HashSet对象
for(Iterator iterator = set.iterator(); iterator.hasNext(); ) {
iterator.next();
}4.2 通过for-each遍历HashSet
第一步: 根据toArray()获取HashSet的元素集合对应的数组。
第二步: 遍历数组,获取各个元素。
// 假设set是HashSet对象,并且set中元素是String类型
String[] arr = (String[])set.toArray(new String[0]);
for (String str : arr)
System.out.printf("for each : %s\n", str);五、HashSet示例
下面我们通过实例学习如何使用HashSet。
代码:
import java.util.Iterator;
import java.util.HashSet;
/*
* @desc HashSet常用API的使用。
*
* @author skywang
*/
public class HashSetTest {
public static void main(String[] args) {
// HashSet常用API
testHashSetAPIs() ;
}
/*
* HashSet除了iterator()和add()之外的其它常用API
*/
private static void testHashSetAPIs() {
// 新建HashSet
HashSet set = new HashSet();
// 将元素添加到Set中
set.add("a");
set.add("b");
set.add("c");
set.add("d");
set.add("e");
// 打印HashSet的实际大小
System.out.printf("size : %d\n", set.size());
// 判断HashSet是否包含某个值
System.out.printf("HashSet contains a :%s\n", set.contains("a"));
System.out.printf("HashSet contains g :%s\n", set.contains("g"));
// 删除HashSet中的“e”
set.remove("e");
// 将Set转换为数组
String[] arr = (String[])set.toArray(new String[0]);
for (String str:arr)
System.out.printf("for each : %s\n", str);
// 新建一个包含b、c、f的HashSet
HashSet otherset = new HashSet();
otherset.add("b");
otherset.add("c");
otherset.add("f");
// 克隆一个removeset,内容和set一模一样
HashSet removeset = (HashSet)set.clone();
// 删除“removeset中,属于otherSet的元素”
removeset.removeAll(otherset);
// 打印removeset
System.out.printf("removeset : %s\n", removeset);
// 克隆一个retainset,内容和set一模一样
HashSet retainset = (HashSet)set.clone();
// 保留“retainset中,属于otherSet的元素”
retainset.retainAll(otherset);
// 打印retainset
System.out.printf("retainset : %s\n", retainset);
// 遍历HashSet
for(Iterator iterator = set.iterator();iterator.hasNext();)
System.out.printf("iterator : %s\n", iterator.next());
// 清空HashSet
set.clear();
// 输出HashSet是否为空
System.out.printf("%s\n", set.isEmpty()?"set is empty":"set is not empty");
}
}
运行结果:
size : 5
HashSet contains a :true
HashSet contains g :false
for each : d
for each : b
for each : c
for each : a
removeset : [d, a]
retainset : [b, c]
iterator : d
iterator : b
iterator : c
iterator : a
set is empty六、总结
- HashSet内部使用HashMap的key存储元素,以此来保证元素不重复;
- HashSet是无序的,因为HashMap的key是无序的;
- HashSet中允许有一个null元素,因为HashMap允许key为null;
- HashSet是非线程安全的;
- HashSet是没有get()方法的;
参考链接:https://www.cnblogs.com/tong-yuan/p/HashSet.html