paper:An Empirical Study of Training Self-Supervised Vision Transformers
official implementation:https://github.com/facebookresearch/moco-v3
出发点
本文并没有提出一种新的方法,而是对计算机视觉领域最近进展中的一个重要且基础的情况进行研究:即视觉Transformers(ViT)的自监督学习。尽管标准卷积网络的训练方法已经非常成熟和稳健,但ViT的训练方法尚未建立,尤其是在自监督学习场景中,训练变得更加具有挑战性。
解决了什么问题
论文解决了自监督学习中ViT训练的不稳定性问题。作者观察到,尽管在某些情况下训练结果看似不错,但实际上这种不稳定性会导致准确度下降,并且这种下降在没有更稳定对照组的情况下很难被察觉。论文通过实验揭示了这种不稳定性,并提出了改进稳定性的方法。
创新点
- 对ViT在自监督学习框架下的训练基础组件进行了深入研究,包括批量大小、学习率和优化器。
- 提出了一种简单的改进方法,即在ViT中冻结patch projection层,使用固定的随机patch projection来提高训练稳定性。
- 在多个自监督框架中对ViT进行了基准测试和消融研究,提供了不同架构设计的ViT结果,并探讨了其影响。
MoCo v3
本文提出了MoCo v3,它是对MoCo v1/2的增量改进版本,伪代码如Alg 1所示

具体来说,我们对同一张图片进行两次随机的数据增强,并取出两个crop。它们由两个编码器 \(f_k\) 和 \(f_k\) 进行编码,得到输出向量 \(q\) 和 \(k\),直觉上,\(q\) 的行为就像是一个“query”,而学习的目标是检索相应的“key”。这个过程表述为最小化一个对比损失函数,本文采用InfoNCE
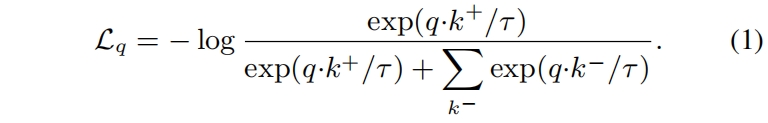
这里 \(k^+\) 是 \(f_k\) 对 \(q\) 同一张图片的输出,作为 \(q\) 的正样本,集和 \(\{k^-\}\) 由 \(f_k\) 对其它图片的输出组成,作为 \(q\) 的负样本,\(\tau\) 是 \(\ell_2\) 归一化的 \(q,k\) 的温度超参。
MoCo v3采用同一batch中那些自然共存的keys,作者放弃了memory queue,因为作者发现如果batch size足够大(例如4096)它的增益会变少。通过这种简化,式(1)中的对比损失可以通过几行代码实现:见Alg 1中的ctr(q, k)。本文采用了对称损失ctr(q1, k2) + ctr(q2, k1)。
编码器 \(f_q\) 由一个backbone(例如ResNet、ViT)、一个projection head以及一个额外的prediction head组成。编码器 \(f_k\) 由backbone和projection head组成,但没有prediction head。\(f_k\) 根据 \(f_q\) 的移动平均值进行更新,不包括prediction head。
作者用ResNet-50来测试了MoCo v3的精度,下表对比了ImageNet上的linear probing精度
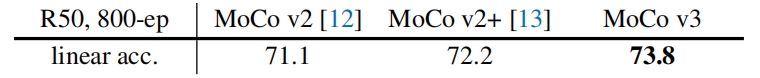
改进主要是因为额外的预测头和大批量(4096)训练。
Stability of Self-Supervised ViT Training
原则上,在contrastive/Siamese自监督框架中,可以直接用ViT主干替换ResNet主干。但在实践中,作者遇到的一个主要挑战是训练的不稳定性。
作者观察到,不稳定问题不能简单地用精度来反映。实际上,如实验结果展示的那样,训练是“相当好的”并且结果也不错,即使它可能是不稳定的。为了揭示这种不稳定性,作者在训练期间监测了KNN曲线。作者首先研究了基本要素如何影响稳定性,这些曲线表明,训练可以是“部分成功的”或者换句话说是“部分失败的”。然后又探索了一个可以提高稳定性的简单技巧,从而在各种情况下都提高了模型精度。
Empirical Observations on Basic Factors
Batch size
ViT模型本身的计算量就很大,因此大批量训练是大型ViT模型的理想解决方案。在最近的一些自监督方法中,大的batch也有利于模型的精度。图1展示了不同batch size下的训练曲线。
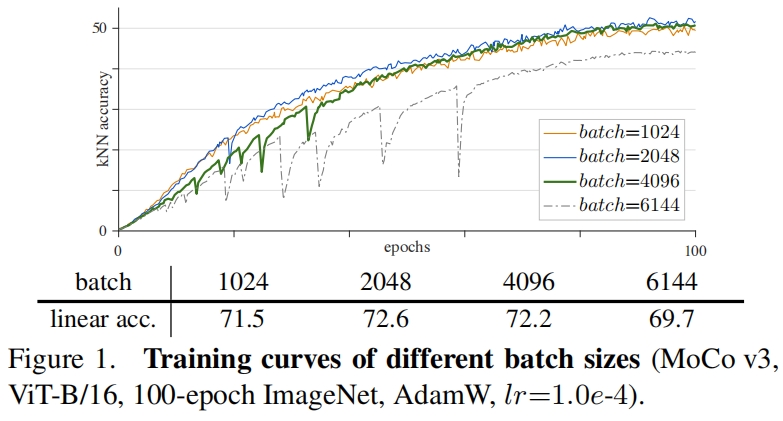
当batch size为1k和2k时曲线相当平滑,linear probing准确率分别为71.5%和72.6%。在这个范围内,由于有更多的负样本,更大的batch size提高了精度。4k的曲线变得明显的不稳定,它的linear probing精度为72.2%,尽管和2k的精度相比只有轻微的下降,但它的精度受到了不稳定性的影响。6k的曲线就更差了,作者假设是训练部分重启了,跳出了局部最优,然后寻找一个新的轨迹。因此训练不会发散,但精度取决于重启的效果。当这种部分的失败发生了,仍然能够得到一个还不错的结果(69.7%),但这对于研究是有害的:和那些容易发现的灾难性的失败不同,这种小的退化可能会被忽略。
Learning rate
作者研究了学习率的影响,如图2所示。学习率越小,训练越稳定,但可能会导致欠拟合。如图2所示,学习率lr=0.5e-4比lr=1.0e-4的精度低了1.8%(70.4% vs. 72.2%)。当学习率变大时,训练会变得不稳定,当lr=1.5e-4时曲线有更多的抖动,精度也降低了。

Optimizer
默认情况下,训练ViT采用AdamW优化器,但最近的自监督方法都采用LARS优化器进行large-batch的训练。图3作者研究了LAMB优化器,它是LARS的AdamW版本。
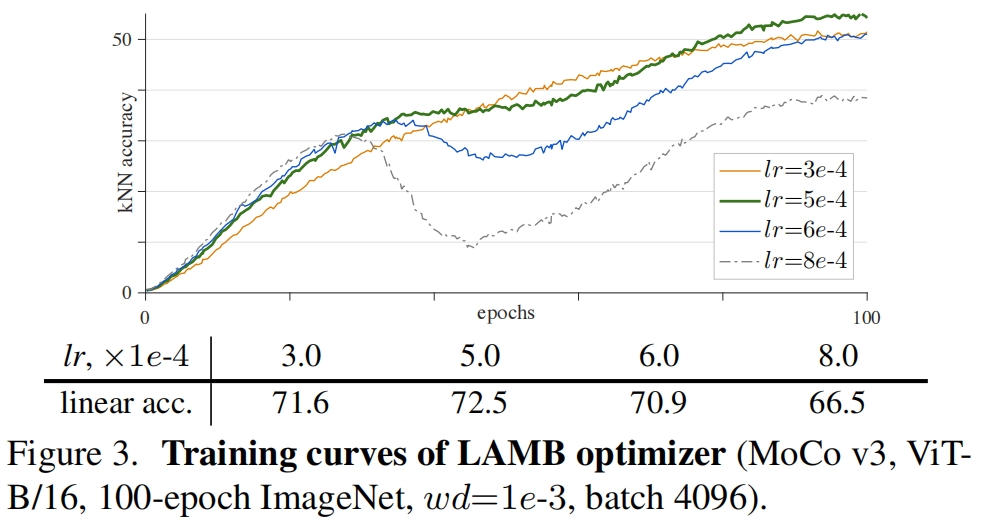
如图3所示,当学习率合适时(lr=5e-4),LAMB的精度比AdamW稍好(72.5%)。但当lr大于最优值时精度迅速下降,有趣的是,训练曲线仍然是平滑的,但在中间部分开始逐渐下降。由于对lr较为敏感当网络结构不同时,LAMB需要额外的lr search,因此作者在本文中还是采用AdamW。
A Trick for Improving Stability

如图4所示,作者发现训练过程中梯度的突然变化会导致训练曲线的下降。通过比较所有层的梯度,作者发现梯度的峰值发生到第一层(patch projection),并通过若干迭代后传递到网络后面的层。因此作者探索了冻结patch projection层,即随机初始化后,就通过stop-gradient不再更新权重了。
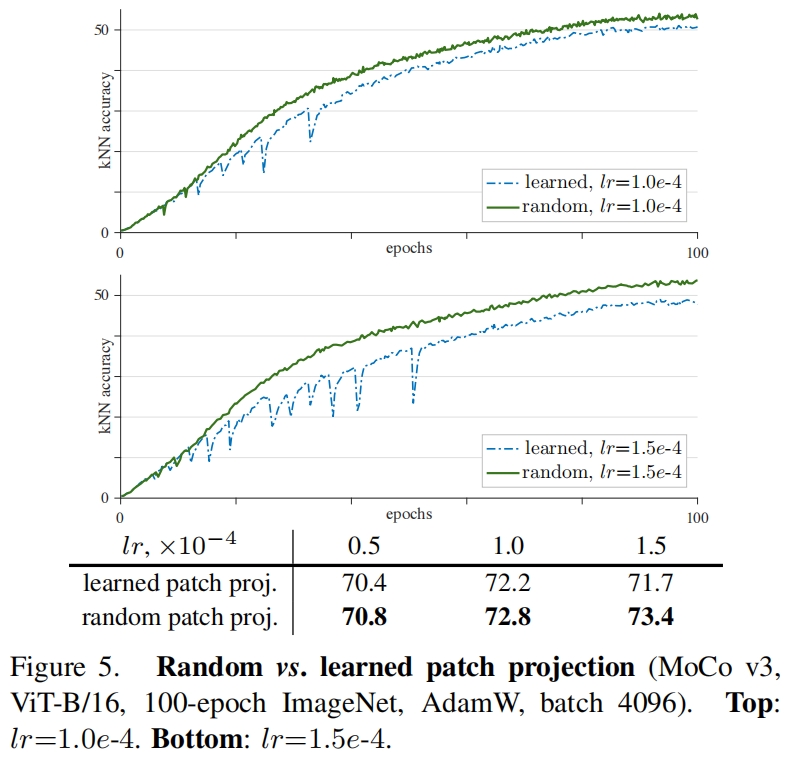
图5展示了patch projection的参数可学习和随机初始化并冻结两种情况的结果,可以看到random patch projection稳定了训练,训练曲线更加平滑。这种稳定性对精度也有帮助,当lr=1.5e-4时,精度提高了1.7%达到了73.4%。这一实验证明了训练的不稳定性是影响精度的一个主要问题。
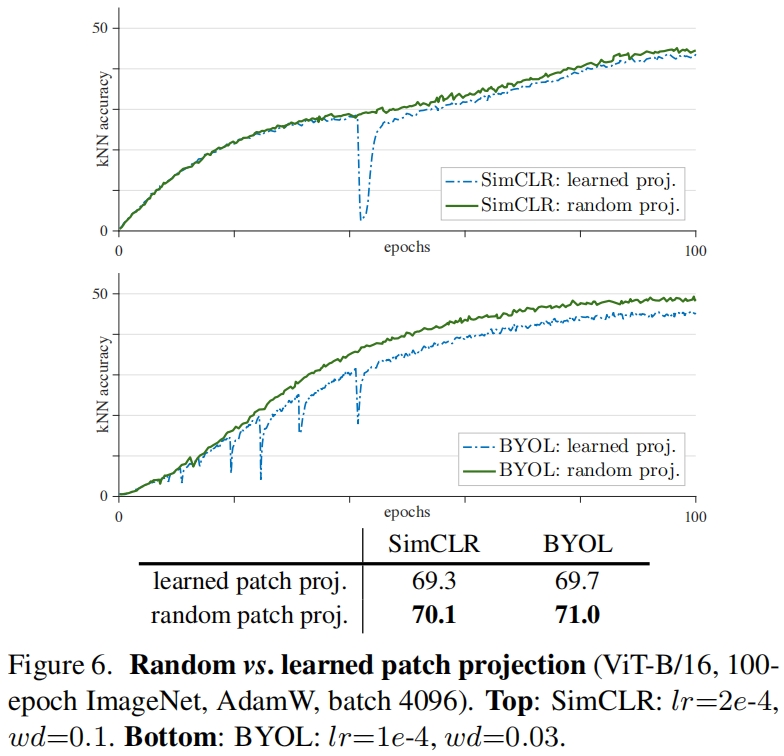
此外,作者还发现其它自监督方法可能也是不稳定的。图6展示了SimCLR和BYOL使用ViT的训练曲线,随机patch projection提高了两者的稳定性,精度也分别提高了0.8%和1.3%。SwAV也存在不稳定性,但当它不稳定时损失会发散(NaN),当使用一个较大的学习率并用random patch projection可以帮助SwAV收敛,并在使用最大的稳定学习率时将精度从65.8%提升到66.4%。总之,这一技巧在所有自监督框架中都是有效的。
实验结果
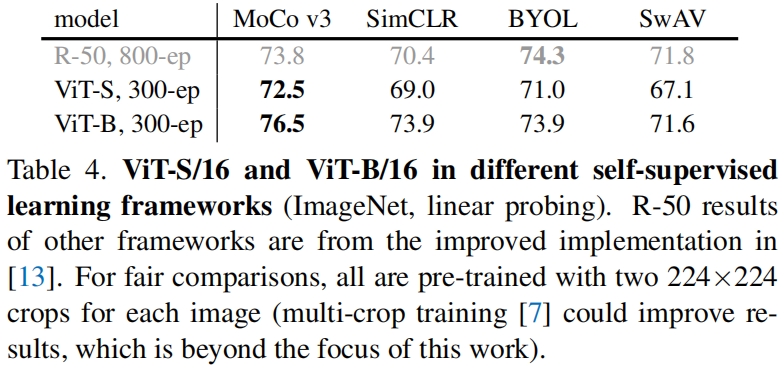
表4展示了不同四种不同的自监督框架使用ViT的性能对比,为了公平比较,每个框架的wd和lr都是单独搜索出来的,可以看到MoCo v3的效果是最好的。
下面是一些消融实验的结果
位置编码sin-cos的效果最好

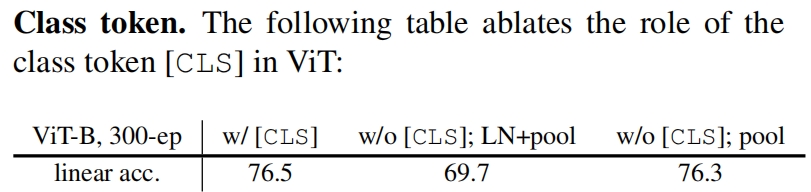
当不用class token精度从76.5%下降到了69.7%,ViT在最后一个block的后面额外有一个LN层,如果把这层LN也去掉,精度又涨到了76.3%。
ViT中没有BN,只在MLP head中有BN,去掉BN时必须将batch size设为2048否则模型不收敛,此时精度下降了2.1%,这表明BN对于对比学习 不是必要的,但可以提升精度。

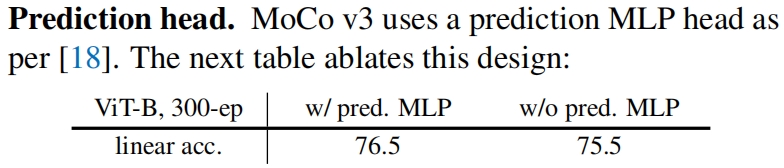
去掉prediction head会导致性能轻微的下降,表明预测头不是必须的。
动量m=0.99时精度最高,m=0类似SimCLR的做法(加上prediction head并停止keys上的梯度传播),使用动量编码器精度提升了2.2%。