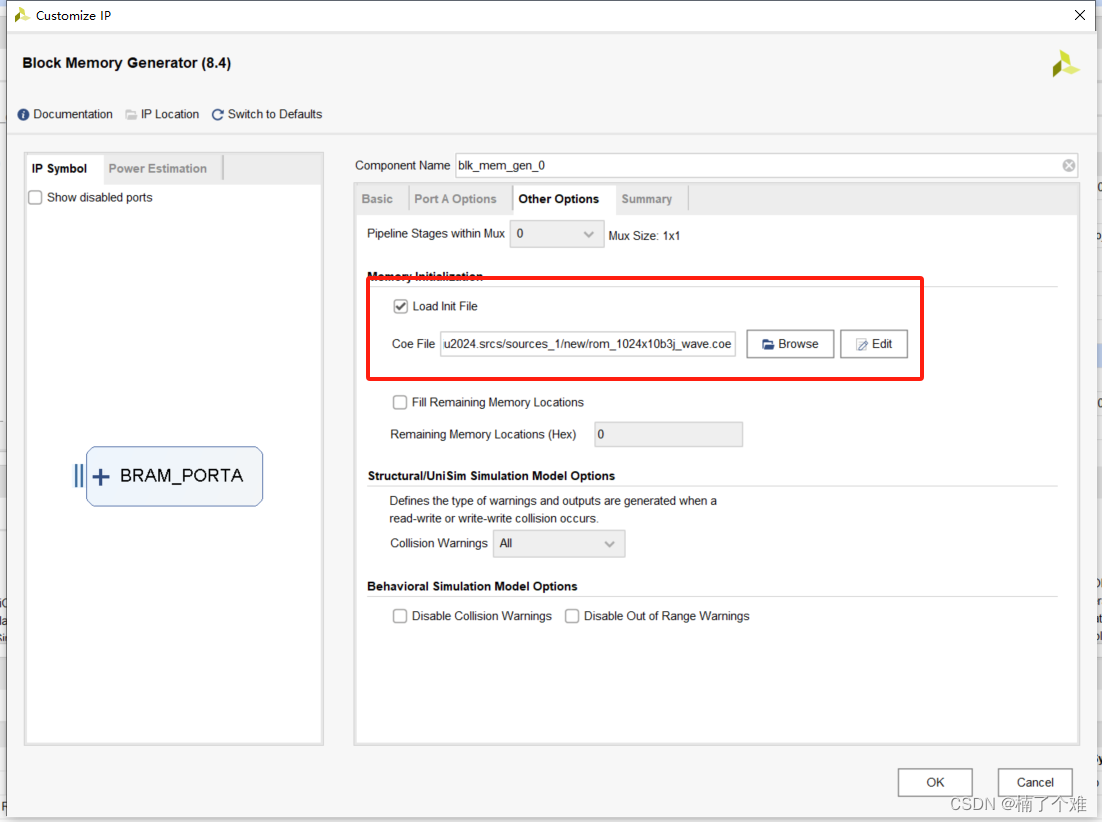
实战:使用RDD 计算学生成绩的总分与平均分
项目背景
本项目旨在利用 Apache Spark 的强大数据处理能力,对存储在 HDFS 上的学生成绩文件进行处理,计算每个学生的总分和平均分。
项目目标
- 读取存储在 HDFS 上的成绩文件。
- 计算每个学生的总分。
- 计算每个学生的平均分。
- 将结果输出到控制台和 HDFS 的指定目录。
实现步骤
-
环境准备
- 启动 Spark Shell 或设置 Spark 项目。
- 确保 HDFS 环境配置正确,可以访问数据。
-
数据准备
- 在本地创建成绩文件
scores.txt。 - 将文件上传到 HDFS 的
/scoresumavg/input目录。
- 在本地创建成绩文件
-
数据处理
- 使用 Spark 的
textFile方法读取 HDFS 上的成绩文件,生成 RDD。 - 将每行数据解析为学生姓名和成绩列表,并将成绩转换为整数类型。
- 使用 Spark 的
-
计算总分
- 使用
map将每行数据转换为多个键值对,其中键为学生姓名,值为成绩。 - 使用
reduceByKey方法对每个学生的成绩进行求和,得到总分。
- 使用
-
计算平均分
- 由于每行数据包含相同数量的成绩,可以直接将总分除以成绩数量得到平均分。
- 使用
map方法对每个学生的总分应用平均分计算公式。
-
结果输出
- 使用
collect方法将计算结果收集到驱动程序,并打印到控制台。 - 使用
saveAsTextFile方法将结果保存到 HDFS 的/scoresumavg/output目录。
- 使用
技术要点
- 熟悉 Spark 的 RDD 操作,包括
textFile、map、reduceByKey、collect和saveAsTextFile。 - 理解 Spark 的行动(action)和转换(transformation)操作。
- 掌握如何在 Spark 中处理和转换数据。
遇到的问题与解决方案
-
问题:在处理大数据集时,
collect操作可能导致驱动程序内存不足。
解决方案:尽量避免使用collect,改用其他行动操作如saveAsTextFile。 -
问题:原始数据中可能存在格式错误或无效的成绩数据。
解决方案:在数据处理阶段添加数据验证和清洗步骤。
项目成果
- 成功实现了一个 Spark 应用程序,用于计算学生成绩的总分和平均分。
- 通过实战加深了对 Spark 数据处理流程的理解。
- 学会了如何在 Spark 中处理实际的大数据问题。
总结与反思
本项目通过实践加深了对 Apache Spark 的认识,特别是在数据处理和 RDD 操作方面。项目过程中遇到的问题和解决方案为未来处理类似任务提供了宝贵的经验。未来可以探索更高效的数据处理方法和优化 Spark 应用程序的性能。
后续建议
- 对项目进行性能优化,考虑使用 Spark 的更高级特性,如广播变量或累加器。
- 探索使用 Spark SQL 或 DataFrame API 来简化数据处理流程。
- 增加异常处理和日志记录,提高程序的健壮性和可维护性。