最近,苹果展示了其人工智能底牌,推出了Apple Intelligence(重新定义AI),这是一套基础模型,将极大地改变苹果消费者使用其产品的方式。
虽然仍需在实际中证明自己,但它是一个强有力的演示,至少从普通用户的角度来看,在 UI/UX 级别的消费级 AI 方面,它与其竞争对手(主要是谷歌和微软)处于同一水平。
然而,昨天的演讲在某些方面也承认了失败,更重要的是,它可能背叛了苹果建立其品牌的基础之一——数据隐私,以至于马斯克已经威胁要禁止在他们的公司使用苹果产品。
Apple Intelligence 的精髓
如果用一句话来概括Apple Intelligence,那就是“令人印象深刻,但远非非凡,并且有不少值得讨论的漏洞。”
功能
首先,我们简单回顾一下它的主要功能,因为你可能已经了解其中的大部分内容。
苹果宣布了一系列由人工智能驱动的功能和更新,涵盖其整个产品线。iOS 18 将引入自定义表情符号创建功能(称为Genmoji),以便你可以根据文本描述生成全新的表情符号。

- 它将包括通过命令进行高级照片编辑、音频转录和 Safari 中的智能内容摘要,以及备受期待的 Siri 改进。但稍后我们会详细介绍我们最讨厌的对话式助手。
- 在笔记本电脑层面,macOS Sequoia 将利用 AI 增强写作工具和图像编辑,并具有改进的系统设置和新的游戏功能。
- 在 iPad 上,他们推出了一款新的计算器应用——这真的值得宣布吗?——先进的笔记记录功能和眼动追踪等辅助功能。
- iPad 还配备了最酷的 AI 增强功能之一:数学笔记。您可以使用 iPad 手写笔进行数学运算,底层 AI 会自动计算您写下的任何计算,甚至匹配您的手写风格。这绝对是一项“没人要求”的功能,但它在技术上仍然令人印象深刻。

现在我们来讨论 Apple Intelligence 的架构,这才是最有趣的部分。
架构
多年来,苹果一直非常热衷于不惜一切代价保护用户的隐私。然而,在处理大型语言模型 (LLM) 时,这是一个巨大的问题。
LLM 对设备的处理单元来说负担很重,并且对内存要求极高,尤其是在推理时,而推理是 Apple 的整个 AI 价值主张。
作为参考,一个只有70 亿个参数的非常小的语言模型,以今天的标准来看绝对是微不足道的,在标准 float16(2 字节)精度级别下却占用了惊人的14GB RAM。
在当今安卓机皇动不动就是12 GB 16GB的情况下,iPhone 还就只有 8GB ,例如 iPhone 15 系列,只有 8GB RAM,即使对于该型号来说也太少了。
不过,他们昨天展示的演示非常有趣,他们似乎已经完全致力于“设备上”范式,正如他们昨天所说,大多数大型语言模型 (LLM) 将在设备内部运行。
这很重要,因为这样,数据就不会离开你的 iPhone、iPad 或 Mac 来处理你的请求。但这有一个问题。
关于LLM的残酷事实
运行在“设备上”的模型必须非常小,因此不是最先进的。
考虑到兼容Apple Intelligence的智能手机仅为 iPhone 15 Pro 和 Max 机型,我们知道它们将只有 8 GB 的 RAM,不仅给机型本身(Apple Intelligence 涵盖了完整的机型系列)留下很小的空间,而且给它们的KY Cache也留下很小的空间。
KV Cache 是在推理过程中由 LLM 生成的,用于避免重复计算注意力机制激活。通俗地说,就是避免重复计算冗余数据。
这是使整个过程经济且易于计算的关键,但对于大序列来说,它有严重的内存限制考虑。
但是这些模型有多大?大小可以由参数数量或参数精度决定。
-
如果他们决定训练非常小的模型,考虑到 RAM 容量,它们的大小不能大于 30 亿个参数,就是这样。同样,我假设他们没有将模型存储在闪存中,因为他们没有明确提到这一点。考虑到这一点,模型不能大于 3B,甚至可能更小,因为 Apple不久前发布了 1B 范围内的 OpenELM 系列。
-
如果他们决定采用训练后量化的方法,就可以先训练一个非常大的模型,然后将其量化以适应较小的存储空间。例如,如果一个拥有120亿参数的模型将每个参数的精度从标准的16位降低到3.5位,那么模型的大小将从24 GB减少到仅7 GB。
训练后量化:这是一种优化技术,先训练一个大型模型,然后通过减少每个参数的精度来压缩模型大小。
参数精度:参数精度的位数越少,模型占用的内存就越少。标准的精度是16位,通过降低到3.5位,可以大幅减少模型的大小。
模型大小的变化:通过降低参数精度,一个原本需要24 GB内存的模型可以缩减到7 >GB,大大减少了内存需求。
训练后量化可能会对模型的效果产生一些影响,因为降低参数精度会导致一定的信息丢失。然而,现代量化技术已经非常成熟,能够在保持模型性能的同时大幅减小模型大小。因此,只要量化方法得当,模型性能的下降通常是可以接受的。具体效果取决于模型的复杂性和量化技术的应用
我猜他们上面两件事都做了。
我们知道他们将自己的模型与微软的 Phi-3 模型系列进行了比较,因此我们可以假设我们谈论的是类似大小的模型。然而,他们也在一篇博客文章中承认,设备上的模型(以及 KV Cache)被量化为 3.5 位。
总体而言,这很好地展示了如何在非常小的设备中处理 LLM。然而,有些请求超出了其当前设备上的模型所能提供的范围。
私有云计算
为此,他们还宣布了私有云计算(Private Cloud Compute),这是一种运行在Apple Silicon上的新型云解决方案,另一组AI模型——Apple Server家族将存储在其中。
这意味着设备将拥有一种算法来评估用户请求的复杂性,并在需要时将请求发送到这些服务器进行计算。换句话说,对于最复杂的请求,你的数据将以数字形式离开你的设备。
苹果知道,这对某些人来说是一个无法接受的问题。
因此,他们立即提到他们将如何让独立专家验证数据在离开设备时,苹果或任何其他第三方都无法访问这些数据。
但苹果最后还留下了一颗炸弹:OpenAI。
ChatGPT 接入你的iPhone和个人数据
对于一些甚至连Apple Server型号都无法处理的请求,苹果宣布 ChatGPT(准确地说是 GPT-4o 版本)将嵌入到 Siri 中,并通过许可系统提供,这意味着你将有机会决定是否将请求发送给 OpenAI。
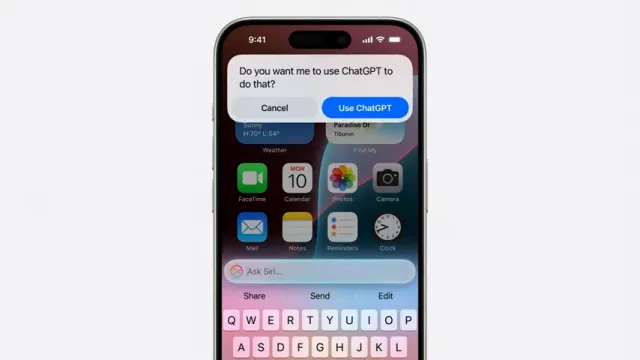
首先,这直接承认了他们的人工智能实践仍未成熟,因此他们的人工智能模型甚至还远远达不到 ChatGPT 所提供的水平。
这是显而易见的,因为他们知道 ChatGPT 的发布会引起争议。因此,他们的模型质量肯定落后了。
吐槽一下, 苹果这世界第一大公司,但他们在人工智能方面的努力却如此落后,确实令人嘘嘘
Apple 隐私的新时代
不要将本次发布的ChatGPT与你手机下载的ChatGPT APP混淆,
你当前的ChatGPT无法访问你的iPhone,但是当前发布的模型却可以。
苹果虽然说需要用户能够自己觉得数据是否发送给OpenAI, 而实际上,苹果是在分散媒体对数据确实会进入OpenAI服务器这一事实的注意力。
尽管苹果和OpenAI都保证这些数据不会用于训练未来的OpenAI模型,但这一声明现在依赖于两方的诚实,而不仅仅是一方的。
换句话说,苹果现在必须相信OpenAI会始终信守承诺。简而言之,这是苹果第一次必须将您的全部个人数据托付给第三方。
许多人认为,OpenAI未经许可就使用受版权保护的数据来训练其模型,这意味着很多人肯定不会信任这家人工智能公司。例如,埃隆·马斯克就声称他可以禁止在公司使用 iPhone。
国内能使用上吗
最近IPhone推送了更新,但是需要注意的是,本次更新并没有上ChatGPT的功能,而是需要等待一段时间。
大家最关心的问题,国内版本的应该不能够使用,大概率是接入的百度的文心一言。
不过如果只是单纯的想让你的苹果设备的Siri接入ChatGPT的话, 那么你现在就可以做到。
非常简单,通过快捷指令,访问ChatGPT API。
如果想要国内顺利访问的话,那么需要找一个国内能使用的API
具体的一键快捷指令和对应API的获取,可以私信我,我发给你。