参考:
Qwen2 阿里最强开源大模型(Qwen2-7B)本地部署、API调用和WebUI对话机器人-CSDN博客
本地快速安装运行史上最强开源LLaMa3大模型 - 廖雪峰的官方网站 (liaoxuefeng.com)
1.下载网站
1.https://www.hugging-face.org/
2.https://hf-mirror.com/models
3.首页 · 魔搭社区 (modelscope.cn)
2.下载模型版本
2.1 例如Qwen2-7B,有多种版本,完整度:Qwen2-7B>Qwen2-7B-Instruct>Qwen2-7B-Instruct-GGUF,可根据显卡与显存的情况进行选择,笔者笔记本3060显卡选择了Qwen2-7B-Instruct-GGUF版本,
2.2 下载了其q5-m版本的模型,可以看到若干GGUF文件,其中,q越大说明模型质量越高,同时文件也更大,我们选择q5,直接点击下载按钮,把这个模型文件下载到本地

3.模型导入ollama
下载到本地的模型文件不能直接导入到Ollama,需要编写一个配置文件,随便起个名字,如config.txt,配置文件内容如下:
FROM ./qwen2-7b-instruct-q5_k_m.gguf
TEMPLATE """{{- if .System }}
<|im_start|>system {{ .System }}<|im_end|>
{{- end }}
<|im_start|>user
{{ .Prompt }}<|im_end|>
<|im_start|>assistant
"""
SYSTEM """"""
PARAMETER stop <|im_start|>
PARAMETER stop <|im_end|>第一行FROM "..."指定了模型文件路径,需要修改为实际路径,后面的模板内容是网上复制的,无需改动。
然后,使用以下命令导入模型:
ollama create Qwen2-7B -f ./config.txtQwen2-7B是我们给模型起的名字,成功导入后可以用list命令查看:
ollama list
NAME ID SIZE MODIFIED
Qwen2-7B:latest c2b042a8d66d 5.4 GB 13 minutes ago
wangshenzhi/llama3-8b-chinese-chat-ollama-q8:latest 6739fd08efd6 8.5 GB 11 hours ago
D:\LLMTest\qwen2-7b-instruct>4.使用ollama运行模型
可以下载多个模型,给每个模型写一个配置文件(仅需修改路径),导入时起不同的名字,我们就可以用Ollama方便地运行各种模型。
4.1命令行运行模型
使用Ollama的run命令可以直接运行模型。我们输入命令ollama run Qwen2-7B:
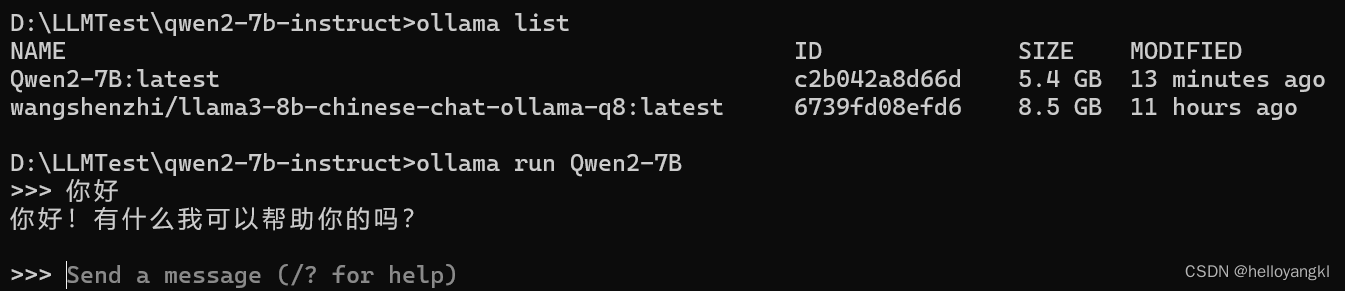
出现>>>提示符时就可以输入问题与模型交互。输入/exit退出。
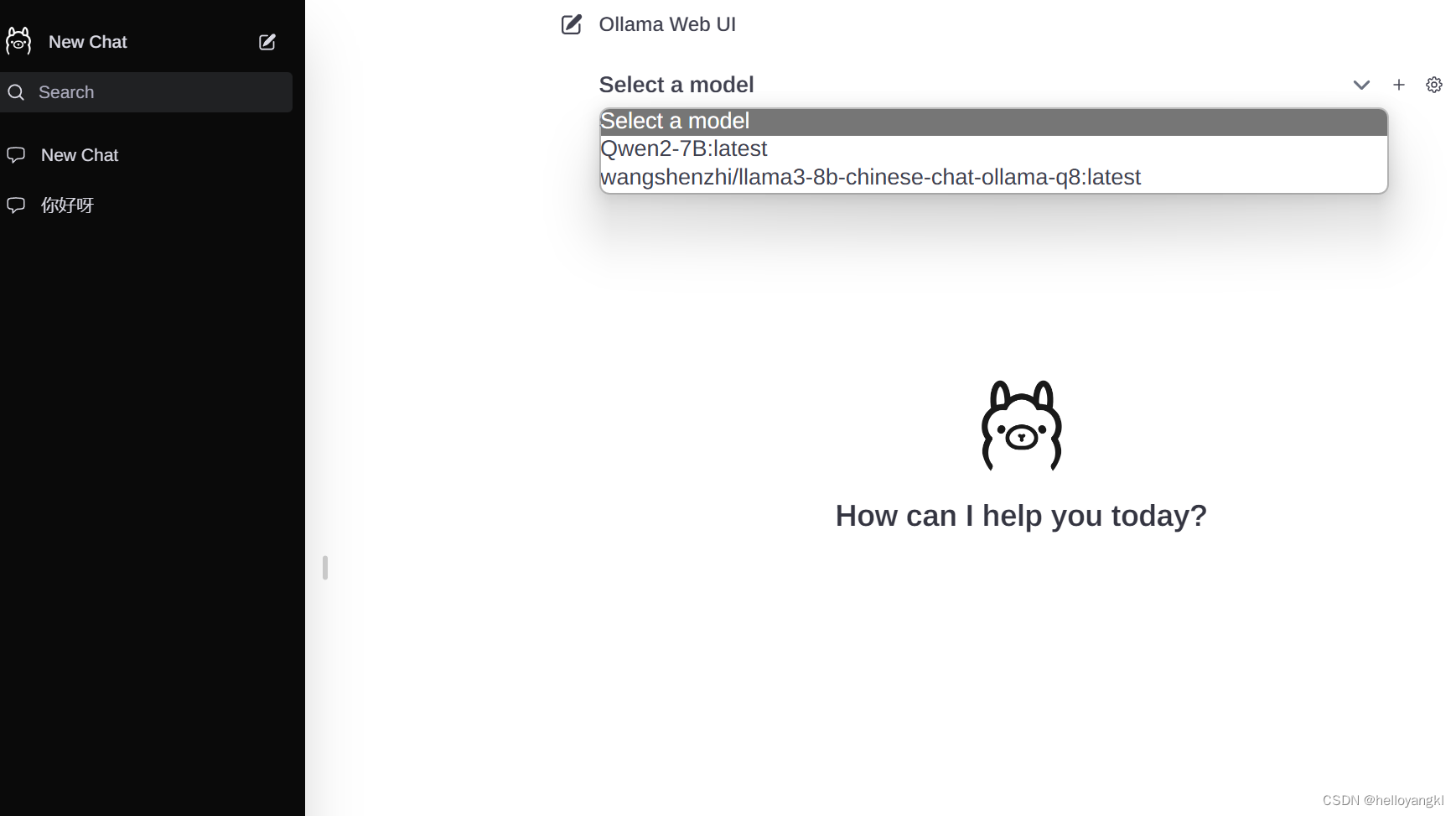
4.2 使用ollama-webui运行模型
1.下载ollama-webui:
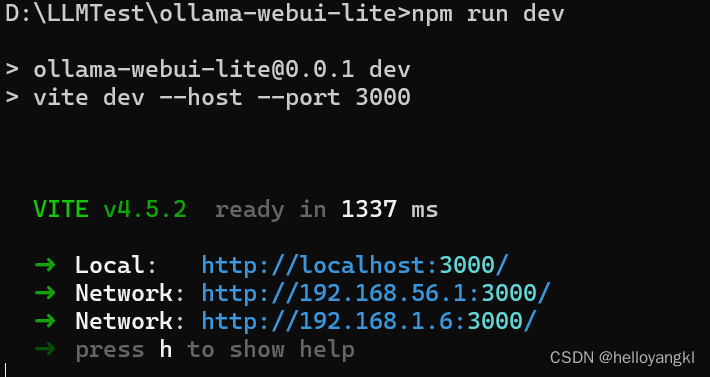
2.加载依赖: npm install
3.开启运行:npm run dev
4.测试: