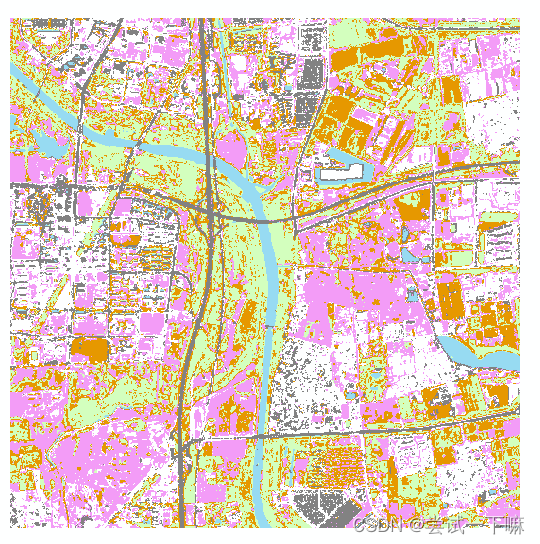
在遥感影像上人工制作分类数据集
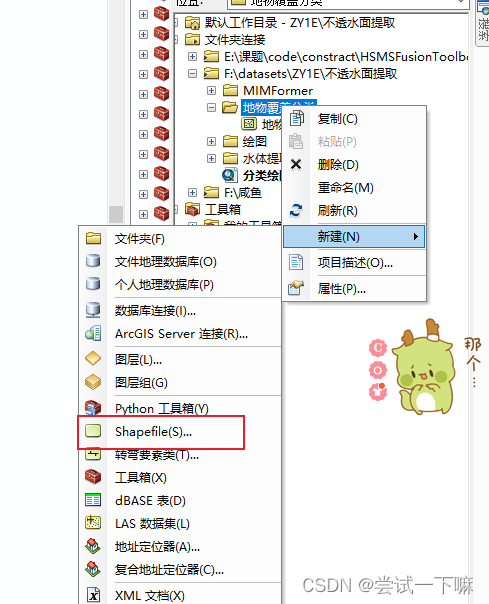
1.新建shp文件
地理坐标系保持和影像一致,面类型
2.打开属性表
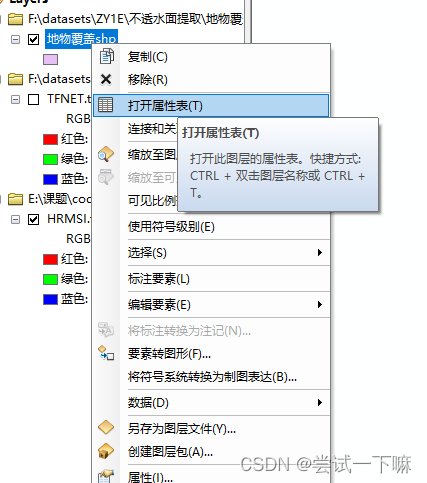
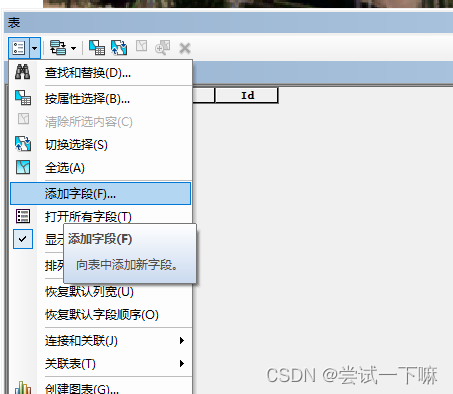
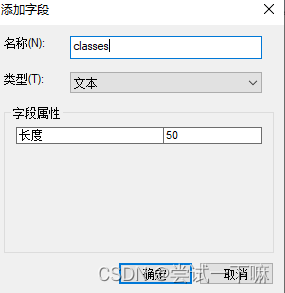
3.添加字段
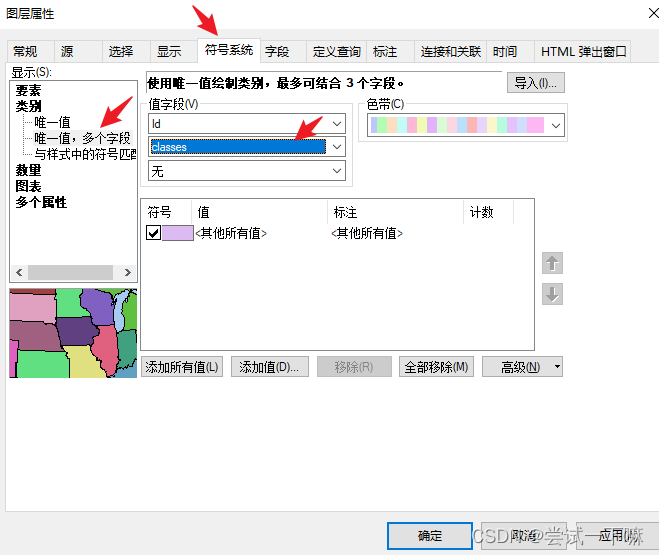
这里分类6类,点击添加值添加
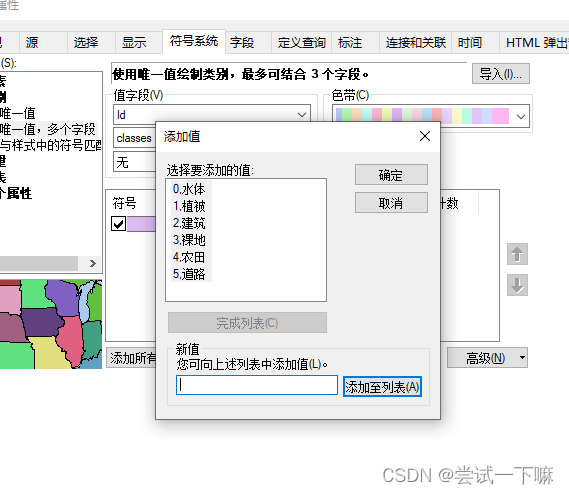
添加完毕
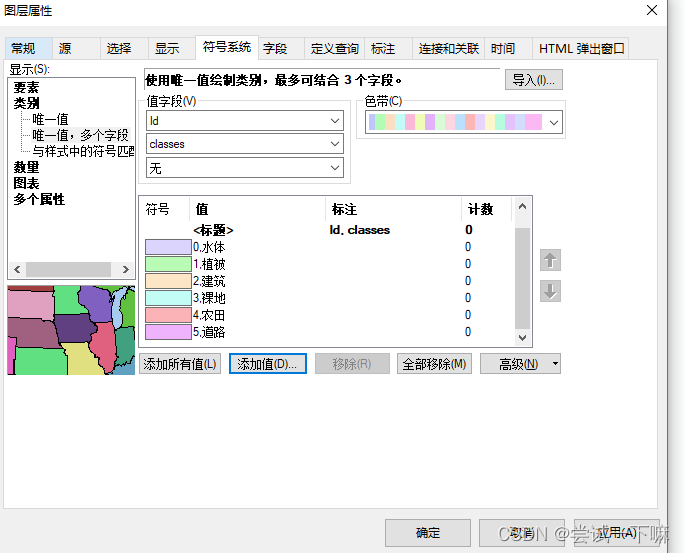
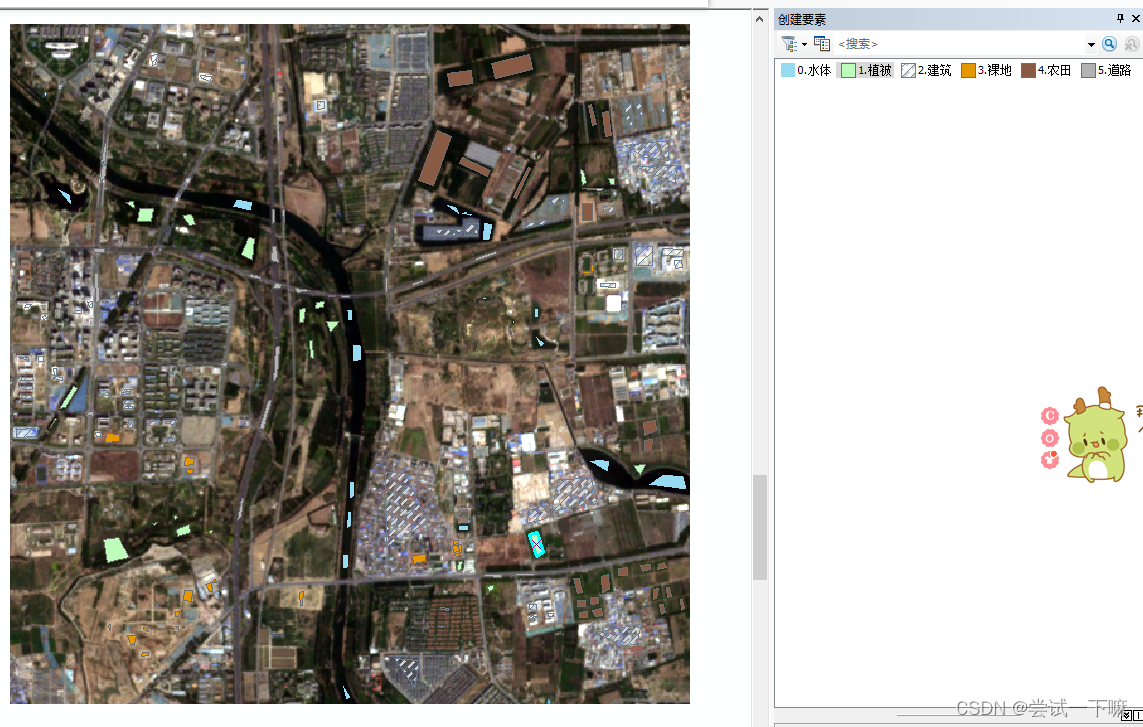
开始人工选地物类型,制作数据集
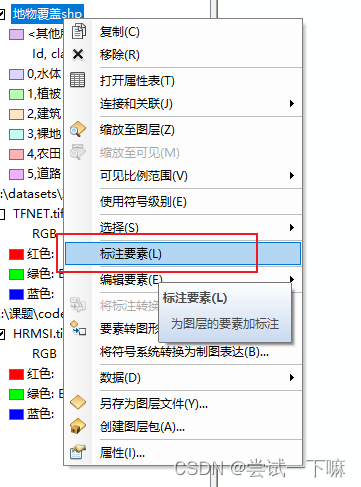

开始标注,标注的时候可以借助谷歌地图来看
标记足够多的样本
打开面转栅格工具
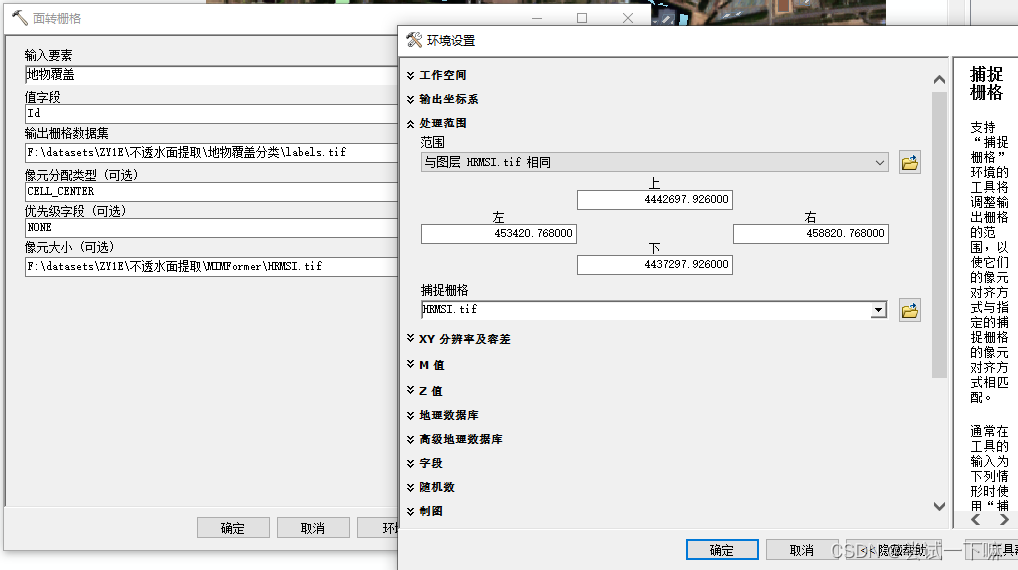
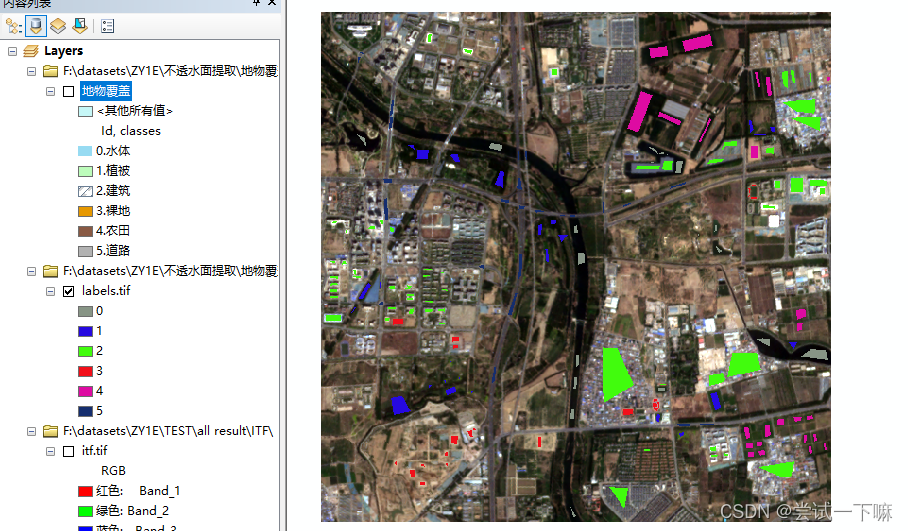
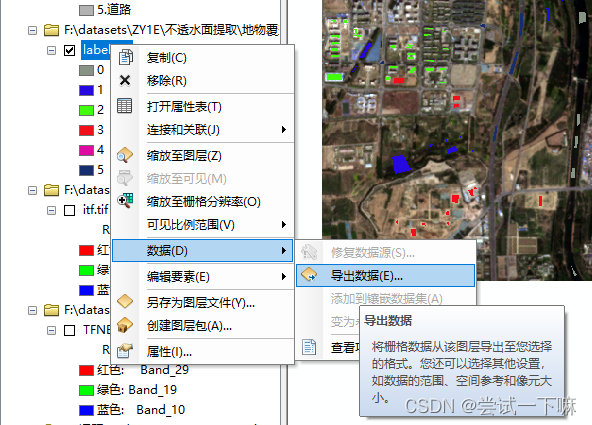
设置nodata值为15
采用python+gdal库制作数据集
import csv
import numpy as np
import rasterio
import pandas as pd
def readTif(fileName):
try:
dataset = rasterio.open(fileName)
return dataset
except rasterio.errors.RasterioIOError:
print(f"文件 {fileName} 无法打开")
return None
num_bands = 8
csv_head_name = [f'Band{i}' for i in range(1, num_bands + 1)] + ['Label', 'LabelName']
labels_name = {0: "水体", 1: "植被",2: "建筑",3: "裸地",4: "农田",5: "道路"}
ori_dataset = readTif(orgin_path)
label_dataset = readTif(sample_path)
if ori_dataset is not None and label_dataset is not None:
label_matri = label_dataset.read(1)
data_matri = ori_dataset.read()
nodata_indices = np.where(label_matri != 15) # 获取所有非 nodata 的索引
# 准备数据
data = []
for i in range(nodata_indices[0].size):
row, col = nodata_indices[0][i], nodata_indices[1][i]
label = label_matri[row, col]
band_values = data_matri[:, row, col].tolist()
label_name = labels_name.get(label, 'Unknown')
band_values.extend([label, label_name])
data.append(band_values)
df = pd.DataFrame(data, columns=csv_head_name)
# 下采样多数类
g = df.groupby('LabelName')
df = g.apply(lambda x: x.sample(g.size().min())).reset_index(drop=True)
#首先将所有数据读取到一个Pandas DataFrame中。然后,使用DataFrame的groupby方法按标签进行分组,并应用sample函数对每个类别进行随机抽样,抽样数等于所有类别中样本最少的那个。这样做可以确保每个类别在最终数据集中有相同数量的样本,从而达到类别平衡。首先将所有数据读取到一个Pandas DataFrame中。
# 然后,使用DataFrame的groupby方法按标签进行分组,并应用sample函数对每个类别进行随机抽样,抽样数等于所有类别中样本最少的那个。这样做可以确保每个类别在最终数据集中有相同数量的样本,从而达到类别平衡。
# 写入 CSV
df.to_csv(csv_filename, index=False, encoding='utf_8_sig')
print(f"已将数据写入 CSV 文件: {csv_filename}")
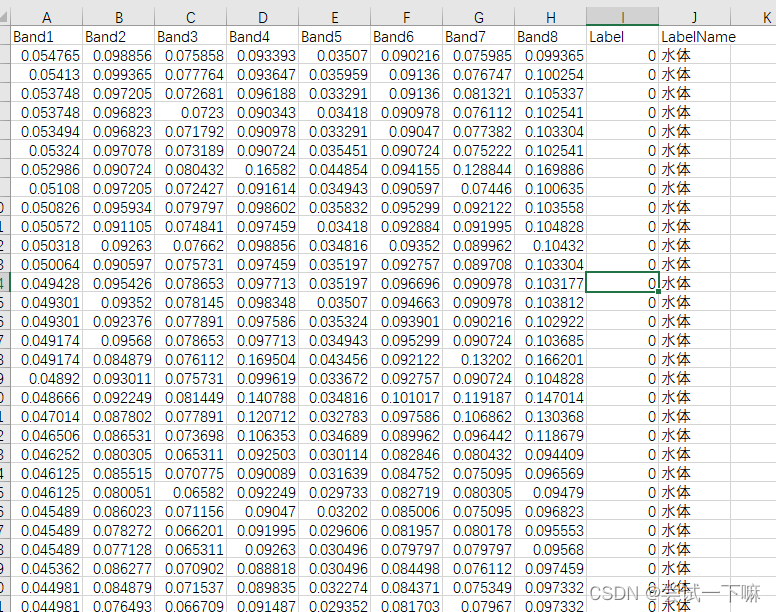
得到的表格如下
挑选分类模型
import pandas as pd
from sklearn.ensemble import RandomForestClassifier
from sklearn.svm import SVC
from sklearn.linear_model import LogisticRegression
from sklearn.neighbors import KNeighborsClassifier
from sklearn.model_selection import train_test_split, cross_val_score
from sklearn.metrics import confusion_matrix, accuracy_score
import numpy as np
# 读取CSV文件的路径
path = r"F:\datasets\ZY1E\不透水面提取\地物覆盖分类\labels.csv"
# 读取数据集
data = pd.read_csv(path)
# 划分数据与标签
x = data.iloc[:, 0:8] # 假设前8列是数据
y = data['Label'] # 标签在'Label'列
# 划分训练集和测试集
train_data, test_data, train_label, test_label = train_test_split(x, y, random_state=1, train_size=0.7, test_size=0.3)
# 创建各种模型
models = {
'Random Forest': RandomForestClassifier(n_estimators=100, bootstrap=True, max_features='sqrt'),
'SVM': SVC(kernel='linear', C=1, decision_function_shape='ovr'),
'Logistic Regression': LogisticRegression(max_iter=1000),
'KNN': KNeighborsClassifier(n_neighbors=5)
}
# 训练并评估模型
for name, model in models.items():
try:
model.fit(train_data, train_label.ravel()) # 训练模型
train_pred = model.predict(train_data)
test_pred = model.predict(test_data)
except Exception as e:
print(f"在模型 {name} 中发生错误: {str(e)}")
continue
print(f"\n{name}:")
print(" 训练集准确率:", accuracy_score(train_label, train_pred))
print(" 测试集准确率:", accuracy_score(test_label, test_pred))
print(" 交叉验证准确率:", np.mean(cross_val_score(model, x, y, cv=5)))
print(" 训练集混淆矩阵:\n", confusion_matrix(train_label, train_pred))
print(" 测试集混淆矩阵:\n", confusion_matrix(test_label, test_pred))
得到输出结果
Random Forest:
训练集准确率: 1.0
测试集准确率: 0.9258809234507898
交叉验证准确率: 0.9128402004972545
训练集混淆矩阵:
[[319 0 0 0 0 0]
[ 0 314 0 0 0 0]
[ 0 0 304 0 0 0]
[ 0 0 0 332 0 0]
[ 0 0 0 0 334 0]
[ 0 0 0 0 0 316]]
测试集混淆矩阵:
[[138 0 0 0 0 0]
[ 0 139 1 0 3 0]
[ 0 0 138 1 1 13]
[ 0 0 1 123 0 1]
[ 0 17 0 2 104 0]
[ 0 0 18 3 0 120]]
SVM:
训练集准确率: 0.7634184471078687
测试集准确率: 0.7800729040097205
交叉验证准确率: 0.7629439059737013
训练集混淆矩阵:
[[317 0 0 0 0 2]
[ 0 233 0 1 78 2]
[ 0 1 186 55 1 61]
[ 0 3 18 241 19 51]
[ 0 81 0 15 223 15]
[ 4 0 41 6 0 265]]
测试集混淆矩阵:
[[138 0 0 0 0 0]
[ 0 108 0 1 34 0]
[ 0 1 98 30 0 24]
[ 0 2 2 102 8 11]
[ 0 34 0 6 78 5]
[ 1 0 20 2 0 118]]
Logistic Regression:
训练集准确率: 0.7535174570088587
测试集准确率: 0.7533414337788579
交叉验证准确率: 0.7654939970483826
训练集混淆矩阵:
[[319 0 0 0 0 0]
[ 1 192 0 1 118 2]
[ 0 1 180 58 1 64]
[ 0 0 20 243 18 51]
[ 0 59 0 15 247 13]
[ 12 0 32 7 0 265]]
测试集混淆矩阵:
[[138 0 0 0 0 0]
[ 0 82 0 1 60 0]
[ 0 1 98 29 0 25]
[ 0 0 5 100 9 11]
[ 0 26 0 6 86 5]
[ 4 0 20 1 0 116]]
KNN:
训练集准确率: 0.9322563835330901
测试集准确率: 0.9015795868772782
交叉验证准确率: 0.90445468203635
训练集混淆矩阵:
[[318 0 0 0 0 1]
[ 0 292 1 0 21 0]
[ 0 0 255 20 1 28]
[ 0 0 0 326 0 6]
[ 0 25 0 1 308 0]
[ 0 0 20 6 0 290]]
测试集混淆矩阵:
[[137 0 0 0 0 1]
[ 0 128 1 3 11 0]
[ 0 0 127 5 1 20]
[ 0 0 0 123 0 2]
[ 0 19 0 1 103 0]
[ 0 0 13 3 1 124]]
Process finished with exit code 0
选择随机森林模型建模分类
import pandas as pd
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import train_test_split, cross_val_score
import pickle
from sklearn.metrics import confusion_matrix
import numpy as np
# 读取CSV文件的路径
# 1.读取数据集
data = pd.read_csv(path)
# 2.划分数据与标签
x = data.iloc[:, 0:8] # 假设前8列是数据
y = data['Label'] # 假设标签在'Label'列
# 3.划分训练集和测试集
train_data, test_data, train_label, test_label = train_test_split(x, y, random_state=1, train_size=0.7, test_size=0.3)
# 4.创建随机森林模型并训练
classifier = RandomForestClassifier(n_estimators=100, bootstrap=True, max_features='sqrt')
classifier.fit(train_data, train_label.ravel()) # ravel函数拉伸到一维
# 5.计算准确率
print("训练集准确率:", classifier.score(train_data, train_label))
print("测试集准确率:", classifier.score(test_data, test_label))
# 6.交叉验证
scores = cross_val_score(classifier, x, y, cv=5) # 5折交叉验证
print("平均交叉验证准确率:", np.mean(scores))
# 7.特征重要性
feature_importances = pd.Series(classifier.feature_importances_, index=x.columns)
print("特征重要性:\n", feature_importances.sort_values(ascending=False))
# 8.混淆矩阵
train_pred = classifier.predict(train_data)
test_pred = classifier.predict(test_data)
print("训练集混淆矩阵:\n", confusion_matrix(train_label, train_pred))
print("测试集混淆矩阵:\n", confusion_matrix(test_label, test_pred))
# 9.保存模型
with open(SavePath, "wb") as file:
pickle.dump(classifier, file)
训练集准确率: 1.0
测试集准确率: 0.9149453219927096
平均交叉验证准确率: 0.9146590350072461
特征重要性:
Band8 0.177021
Band4 0.145268
Band5 0.139987
Band1 0.132925
Band7 0.125840
Band3 0.103912
Band2 0.093239
Band6 0.081808
dtype: float64
训练集混淆矩阵:
[[319 0 0 0 0 0]
[ 0 314 0 0 0 0]
[ 0 0 304 0 0 0]
[ 0 0 0 332 0 0]
[ 0 0 0 0 334 0]
[ 0 0 0 0 0 316]]
测试集混淆矩阵:
[[138 0 0 0 0 0]
[ 0 140 1 0 2 0]
[ 0 0 134 1 1 17]
[ 0 0 0 123 0 2]
[ 0 16 0 2 105 0]
[ 0 0 21 7 0 113]]
遥感图像预测
import numpy as np
import gdal
import pickle
#读取tif数据集
def readTif(fileName):
dataset = gdal.Open(fileName)
if dataset == None:
print(fileName+"文件无法打开")
return dataset
#保存tif文件函数
def writeTiff(im_data,im_geotrans,im_proj,path):
if 'int8' in im_data.dtype.name:
datatype = gdal.GDT_Byte
elif 'int16' in im_data.dtype.name:
datatype = gdal.GDT_UInt16
else:
datatype = gdal.GDT_Float32
if len(im_data.shape) == 3:
im_bands, im_height, im_width = im_data.shape
elif len(im_data.shape) == 2:
im_data = np.array([im_data])
im_bands, im_height, im_width = im_data.shape
#创建文件
driver = gdal.GetDriverByName("GTiff")
dataset = driver.Create(path, int(im_width), int(im_height), int(im_bands), datatype)
if(dataset!= None):
dataset.SetGeoTransform(im_geotrans) #写入仿射变换参数
dataset.SetProjection(im_proj) #写入投影
for i in range(im_bands):
dataset.GetRasterBand(i+1).WriteArray(im_data[i])
del dataset
dataset = readTif(Landset_Path)
Tif_width = dataset.RasterXSize #栅格矩阵的列数
Tif_height = dataset.RasterYSize #栅格矩阵的行数
Tif_geotrans = dataset.GetGeoTransform()#获取仿射矩阵信息
Tif_proj = dataset.GetProjection()#获取投影信息
Landset_data = dataset.ReadAsArray(0,0,Tif_width,Tif_height)
#调用保存好的模型
#以读二进制的方式打开文件
file = open(RFpath, "rb")
#把模型从文件中读取出来
rf_model = pickle.load(file)
#关闭文件
file.close()
#用读入的模型进行预测
# 在与测试前要调整一下数据的格式
data = np.zeros((Landset_data.shape[0],Landset_data.shape[1]*Landset_data.shape[2]))
for i in range(Landset_data.shape[0]):
data[i] = Landset_data[i].flatten()
data = data.swapaxes(0,1)
# 对调整好格式的数据进行预测
pred = rf_model.predict(data)
print("Unique predictions:", np.unique(pred))
print("Max prediction:", np.max(pred))
print("Min prediction:", np.min(pred))
# 同样地,我们对预测好的数据调整为我们图像的格式
pred = pred.reshape(Landset_data.shape[1],Landset_data.shape[2])
pred = pred.astype(np.uint8)
# 将结果写到tif图像里
writeTiff(pred,Tif_geotrans,Tif_proj,SavePath)