一、研究背景
随着经济的发展和金融市场的不断完善,股票投资成为了人们重要的投资方式之一。汽车行业作为国民经济的重要支柱产业,其上市公司的股票表现备受关注。Fama-French 三因子模型是一种广泛应用于股票市场的资产定价模型,它考虑了市场风险、规模因素和价值因素对股票收益的影响。通过对汽车行业上市公司股票数据的分析,可以深入了解该行业的投资特征和风险状况,为投资者提供决策参考。
二、量化分析
接下来进行量化分析
数据是十家汽车行业上市公司在2012.1.1-2021.12.31期间每日的股票交易和Fama-French三因子的数据,十家上市公司分别是:
| 序号 | 股票代码 |
| 1 | 000550 |
| 2 | 000572 |
| 3 | 000625 |
| 4 | 000800 |
| 5 | 002594 |
| 6 | 600006 |
| 7 | 600104 |
| 8 | 600418 |
| 9 | 601238 |
| 10 | 601633 |
每个csv数据文件中均包含以下指标:
数据集和完整代码
| 变量 | 含义 | 变量 | 含义 |
| stkcd | 证券代码 | opnprc | 日开盘价 |
| year | 年 | hiprc | 日最高价 |
| month | 月 | loprc | 日最低价 |
| day | 日 | clsprc | 日收盘价 |
| trddt | 交易日期 | dnshr | 日个股交易量 |
| ret | 日个股回报率 | ||
| risk | 日市场风险溢价因子 | ||
| smb | 日市值因子 | ||
| hml | 日账面市值比因子 |
首先利用pandas读入所提供的股票数据,保存成DataFrame格式的变量,将日期列转换成Datetime格式,并设置成为DataFrame的index。计算每只股票数据中包含多少个交易日
读取数据集
# 调整读取方法,处理日期列
stock_data = {}
for path in file_paths:
# 读取CSV文件,制定分隔符为'\t'
df = pd.read_csv(path, delimiter='\t')
# 转换日期格式
df['trddt'] = pd.to_datetime(df['trddt'])
# 按日期排序
df = df.sort_values(by='trddt')
# 设置日期为索引
df.set_index('trddt', inplace=True)
# 存储处理后的DataFrame
stock_data[path.split('/')[-1].split('.')[0]] = df
# 显示每只股票包含的交易日数量
trading_days = {stock: len(data.index) for stock, data in stock_data.items()}
trading_days虽然所有股票都在同一时间段内被观察,但它们的交易日数量略有不同。 这可能是由于不同的市场假期、停牌、或是某些股票在该时间段内上市的时间不同所致。
接下来选择一支股票,绘制该只股票自2020年以来的K线图,并在K线图上添加30日均线
# 将日期列设为DataFrame的索引并按日期排序
df.set_index('date', inplace=True)
df.sort_index(inplace=True)
# 筛选自2020年以来的数据
stock_002594 = df.loc['2020':]
# 准备股票价格和交易量数据,用于绘图
stock_002594_mpf = stock_002594[['opnprc', 'hiprc', 'loprc', 'clsprc', 'dnshr']].copy()
stock_002594_mpf.columns = ['Open', 'High', 'Low', 'Close', 'Volume']
# 计算30日均线
stock_002594_mpf['30_MA'] = stock_002594_mpf['Close'].rolling(window=30).mean()
# 定义图表和坐标轴
fig, ax = plt.subplots(figsize=(16,8))
# 绘制收盘价
ax.plot(stock_002594_mpf.index, stock_002594_mpf['Close'], label='收盘价', color='black')
# 绘制30日均线
ax.plot(stock_002594_mpf.index, stock_002594_mpf['30_MA'], label='30日均线', color='blue')
# 设置标题和坐标轴标签
ax.set_xlabel('日期')
ax.set_ylabel('价格')
ax.set_title('股票002594价格与30日均线')
ax.legend()
# 设置x轴的日期格式
ax.xaxis.set_major_formatter(mdates.DateFormatter('%Y-%m'))
ax.xaxis.set_major_locator(mdates.MonthLocator())
# 旋转日期标签以便更好地显示
plt.xticks(rotation=45)
# 显示网格
plt.grid(visible=True)
# 显示图表
plt.show()
价格趋势:可以看到,股价在2020年至2021年间呈现出显著的上升趋势,尤其是在2020年中到2021年初,股价有一个大幅的上升期。 波动性:股价在上升期间也显示出一定的波动性,尤其是在大幅上升后,股价有过一些急剧的回调,但总体趋势依然向上。 30日均线:30日均线平滑了价格的日常波动,提供了一个关于股票短期趋势的更清晰视角。 在股价上升期,30日均线持续上升,并在大多数时间内位于日收盘价之下,这通常被视为上升趋势的确认。而在股价下跌期, 30日均线开始下降,并且在某些时段内位于日收盘价之上,可能表示一个短期内的下降趋势。 均线与价格的交叉:在图中,我们可以看到股价与30日均线
随后利用OLS回归计算10只股票在三个因子(risk, smb, hml)上的系数,即因子暴露。将10只股票在每个因子上的因子暴露按照从大到小排序并打分(分值从大到小依次为10、8、6、4、2),计算每只股票在三个因子上的加权得分(三个因子等权重)
# 对每个股票进行OLS回归
for stock, data in stock_data.items():
# 回归模型
X = data[['risk', 'smb', 'hml']]
y = data['ret']
X = sm.add_constant(X) # 添加常数项
model = sm.OLS(y, X).fit()
# 存储每个股票的因子暴露度
factor_exposures[stock] = model.params[1:] # 排除常数项
# 分配分数(10、8、6、4、2)
scores_mapping = {1: 10, 2: 8, 3: 6, 4: 4, 5: 2}
scores_df = ranked_exposures.applymap(lambda x: scores_mapping.get(x, 0))
# 计算每只股票的加权得分
scores_df['Total Score'] = scores_df.mean(axis=1)
# 结果
scores_df

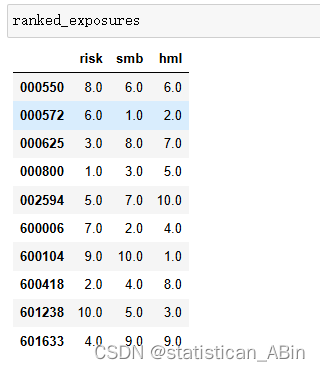
从给定的分数来看,股票000800和000572的总分最高,达到了6分,这可能意味着从这三个因子的角度看,它们的投资吸引力较高。而股票000550的总分最低,为0分,可能意味着从这些因素来看,它的投资吸引力较低。
三、小结
本研究成功地读取了十家汽车行业上市公司的股票数据,并将日期列转换为 Datetime 格式,设置为 DataFrame 的 index。经过排序后,计算出了每只股票数据中包含的交易日数量。根据题目要求,选择了对应序号的股票,并绘制了该只股票自 2020 年以来的 K 线图,并添加了 30 日均线。K 线图可以直观地展示股票价格的走势,而 30 日均线则可以帮助投资者判断股票的短期趋势。利用 OLS 回归计算了 10 只股票在三个因子(risk, smb, hml)上的系数,即因子暴露。通过对因子暴露的排序和打分,计算出了每只股票在三个因子上的加权得分。这些结果可以帮助投资者了解股票的风险特征和投资价值,为投资决策提供参考。
需要注意的是,以上结论仅基于题目要求和提供的数据,实际情况可能会有所不同。在进行股票投资时,投资者还需要综合考虑其他因素,如公司基本面、行业发展趋势、宏观经济环境等。
创作不易,希望大家多点赞关注评论!!!(类似代码或报告定制可以私信)