文章目录
- 前言
- 一、Radix tree简介
- 二、Operations
- 2.1 Lookup
- 2.2 Insertion
- 2.3 Deletion
- 三、Linux内核API
- 3.1 初始化
- 3.2 radix_tree_insert/delete
- 3.3 radix_tree_preload
- 3.4 radix_tree_lookup
- 3.5 radix_tree_tag_set
- 3.6 radix_tree_tagged
- 四、address_space
- 4.1 简介
- 4.2 相应数据结构关系图
- 五、XArray
- 参考资料
前言
对于长整型数据的映射,如何解决Hash冲突和Hash表大小的设计是一个问题。
radix树就是针对这种稀疏的长整型数据查找,能快速且节省空间地完成映射。借助于Radix树,我们可以实现对于长整型数据类型的路由。
利用radix树可以根据一个长整型(比如一个长ID)快速查找到其对应的对象指针。这比用hash映射来的简单,也更节省空间,使用hash映射hash函数难以设计,不恰当的hash函数可能增大冲突,或浪费空间。
radix tree是一种多叉搜索树,树的叶子结点是实际的数据条目。每个结点有一个固定的指针指向子结点(每个指针称为槽slot,n为划分的基的大小)
一、Radix tree简介
在计算机科学中,基数树(也称为基数字典树、紧凑前缀树或压缩字典树)是一种表示经过空间优化的字典树(前缀树)的数据结构,其中每个只有一个子节点的节点与其父节点合并。结果是每个内部节点的子节点数最多为基数r,其中r = 2^x,其中x是大于等于1的整数。与普通树不同,边缘可以用元素序列或单个元素标记。这使得基数树对于小型集合(特别是字符串较长的情况)和共享长前缀的字符串集合更加高效。
与普通树不同(在普通树中,整个键从开头到不等点进行全面比较),在每个节点上,键是按照一块一块的比特进行比较,其中每块的比特数量是基数树的基数r。当r为2时,基数树是二叉的(即比较该节点的键的1比特部分),这最小化了稀疏性,但代价是最大化了字典树的深度,即最大化了键中非分叉的比特字符串的融合。当r ≥ 4是2的幂时,基数树是r叉树,这减小了基数树的深度,但可能会增加稀疏性。
作为优化,边缘标签可以通过使用两个指针指向字符串的第一个和最后一个元素来以常量大小存储。请注意,尽管本文中的示例将字符串表示为字符序列,但字符串元素的类型可以任意选择;例如,在使用多字节字符编码或Unicode时,可以将字符串元素选择为字符串表示的位或字节。
基数树在实际应用中具有广泛的用途,特别是在处理大量字符串集合时,它能够提供高效的存储和检索操作。

基数树适用于构建键可以表示为字符串的关联数组。它们在IP路由的领域中具有特定的应用,其中包含大范围的值并排除少数例外情况的能力特别适用于IP地址的分层组织。它们还用于信息检索中的文本文档的倒排索引。
二、Operations
基数树支持插入、删除和搜索操作。插入操作将一个新的字符串添加到字典树中,同时尽量减少存储的数据量。删除操作从字典树中移除一个字符串。搜索操作包括(但不一定限于)精确查找、查找前驱、查找后继以及查找所有具有特定前缀的字符串。所有这些操作的时间复杂度都是O(k),其中k是集合中所有字符串的最大长度,长度以字典树的基数(radix)表示的比特数量来衡量。
2.1 Lookup
查找操作用于确定字典树中是否存在某个字符串。大多数操作在处理特定任务时会以某种方式修改这种方法。例如,字符串终止的节点可能非常重要。此操作类似于字典树,只是某些边缘会消耗多个元素。如下图所示:

2.2 Insertion
要插入一个字符串,我们在树中搜索直到无法再继续前进为止。此时,我们要么添加一个新的外向边,标记为输入字符串中剩余的所有元素,要么如果已经存在一个与剩余输入字符串共享前缀的外向边,我们将其分割为两个边(第一个边标记为公共前缀)并继续进行。这个分割步骤确保没有节点的子节点数量超过可能的字符串元素数量。
下面展示了几种插入的情况,但可能还有其他情况。注意,r表示根节点。假设边缘可以用空字符串标记以在必要时终止字符串,并且根节点没有传入边。(上述描述的查找算法在使用空字符串边缘时无法正常工作。)
(1)Insert ‘water’ at the root

(2)Insert ‘slower’ while keeping ‘slow’

(3)Insert ‘test’ which is a prefix of ‘tester’

(4)Insert ‘team’ while splitting ‘test’ and creating a new edge label ‘st’

(5)Insert ‘toast’ while splitting ‘te’ and moving previous strings a level lower

2.3 Deletion
要从树中删除字符串x,我们首先找到表示x的叶节点。然后,假设x存在,我们移除相应的叶节点。如果叶节点的父节点只有另一个子节点,那么将该子节点的传入标签附加到父节点的传入标签中,并移除该子节点。
三、Linux内核API
内核包含了一些用于实现有用数据结构的库例程。其中包括两种类型的树:基数树和红黑树。
Linux基数树是一种机制,可以将(指针)值与(长)整数键关联起来。从存储效率和查找速度上来说,它是相当高效的。此外,Linux内核中的基数树具有一些由内核特定需求驱动的特性,包括能够为特定条目关联标签的能力。
基数树也是不平衡的,换句话说,在树的不同分支之间,可能有任意数目的高度差。树本身由两种不同的数据结构组成,还需要另一种数据结构来表示叶,其中包含了有用的数据。
下面简单示意图显示了Linux基数树中的一个叶节点。该节点包含多个槽位,每个槽位可以包含指向树创建者感兴趣的某个内容的指针。空槽位包含一个空指针。这些树相当宽广- 在3.10.0内核中,每个基数树节点有64个槽位。槽位由(长)整数键的一部分进行索引。如果最高键值小于64,则可以用单个节点表示整个树。然而,通常使用的键集较大-否则,可以使用简单的数组。
Linux的radix树每个节点有64个slot,与数据类型long对应,也就是key。
由于RADIX_TREE_MAP_SHIFT通常定义为6,这使得每个数组有64项。
#define RADIX_TREE_MAP_SHIFT (CONFIG_BASE_SMALL ? 4 : 6)
#define RADIX_TREE_MAP_SIZE (1UL << RADIX_TREE_MAP_SHIFT)
struct radix_tree_node {
......
void __rcu *slots[RADIX_TREE_MAP_SIZE];
......
};
# cat /boot/config-3.10.0-693.el7.x86_64 | grep CONFIG_BASE_SMALL
CONFIG_BASE_SMALL=0
因此RADIX_TREE_MAP_SIZE = 2 ^ 6 = 64。

所以一棵更大的树可能看起来像这样:
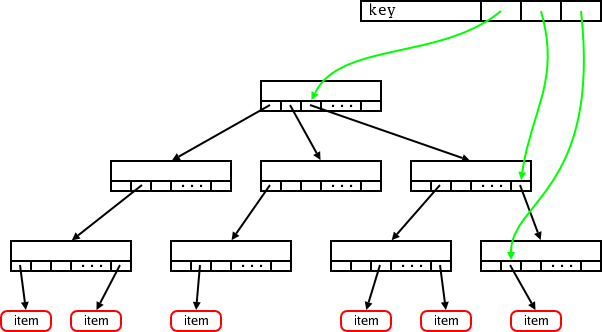
这棵树有三个层级。当内核查找特定键时,最高的六位将用于在根节点中找到相应的槽位。接下来的六位将索引中间节点中的槽位,最低的六位将指示包含指向实际值的指针的槽位。没有子节点的节点不会存在于树中,因此基数树可以为稀疏树提供高效的存储。
1. key[17:12] 索引根节点的slots[],从根节点的slots[key[17:12]]处找到第二层的对应节点;
2. key[11:6] 索引步骤1中找到节点的slots[],找到第三层的对应叶节点;
3. key[5:0] 索引步骤2中找到的叶节点的slots[],定位到要操作的目标item。
如果树中的没有索引大于63,那么树的深度就等于1,因为可能存在的64个叶子可以都放在第一层的节点中。不过,如果与索引131相应的新页的描述符肯定存放在页高速缓存中,那么树的深度就增加为2,这样基数树就可以查找多达4095个节点。
(1)
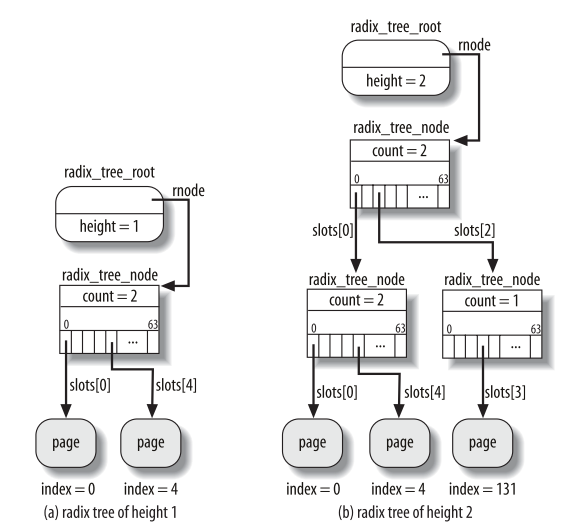
可以看到叶子结点是 struct page。
000010 000011 = 131
树高1
•根有64个插槽,可以为null,也可以为指向页面的指针
•查找地址X:
–移位低12位(页面内偏移)
–使用接下来的6位作为这些插槽的索引(2^6=64)
–如果指针非null,则转到子节点(页面)
–如果为null,则表示页面不存在

111111 111111 = 4095
下图是深度为3的基树:
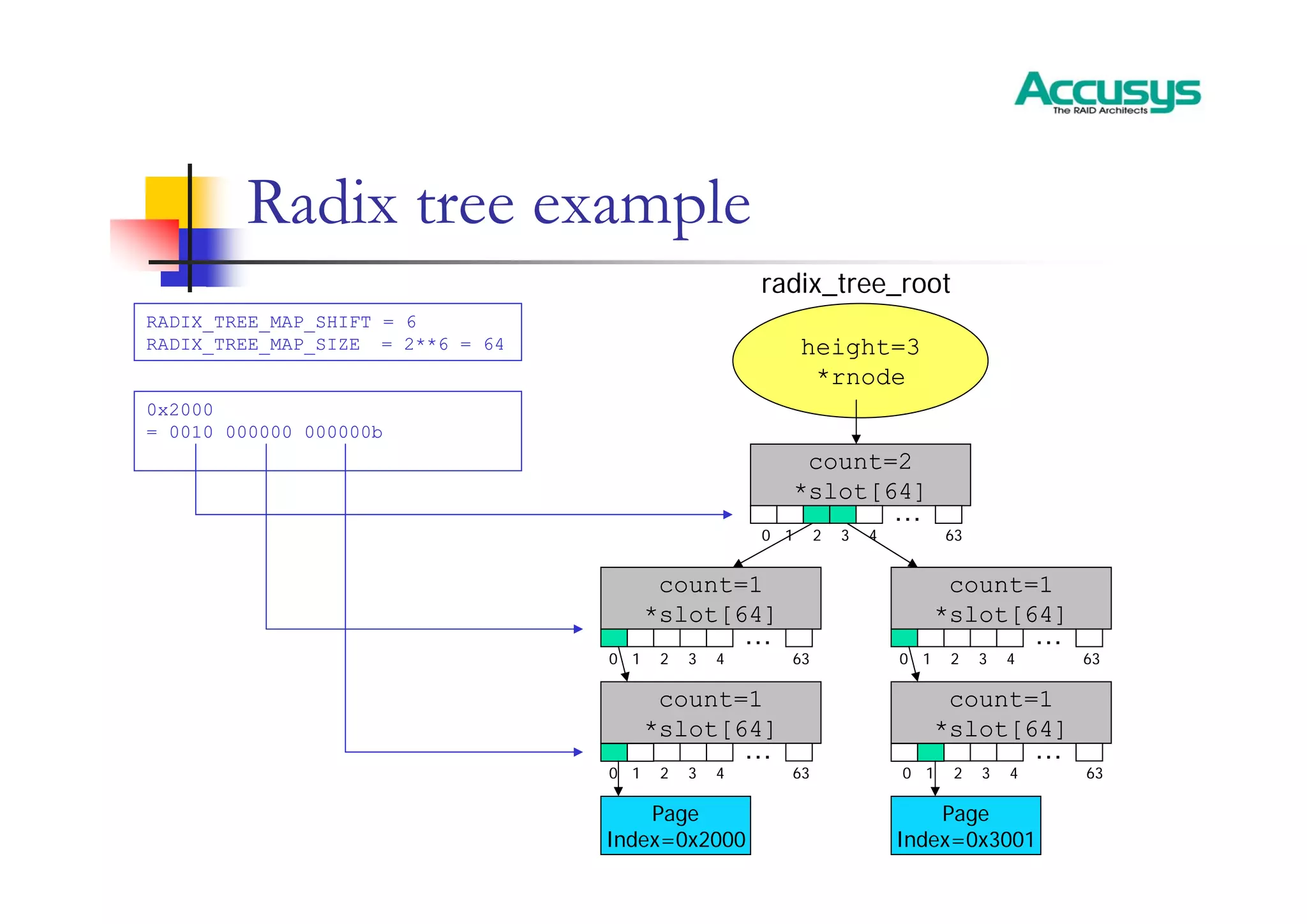
000011 000000 000001 = 0x3001
因为页缓存组织的是内存页,因而基数树的叶子是page结构的实例。
基数树最广泛的用途是在内存管理代码中。用于跟踪后备存储的address_space结构包含一个基数树,用于跟踪与该映射关联的核心页面。除此之外,该树还允许内存管理代码快速查找脏页或正在写回的页等功能。
Linux内核API文件路径:
linux-3.10/lib/radix-tree.c
linux-3.10/include/linux/radix-tree.h
3.1 初始化
与内核数据结构的典型情况一样,有两种模式用于声明和初始化基数树:
(1)
// linux-3.10/include/linux/radix-tree.h
/* root tags are stored in gfp_mask, shifted by __GFP_BITS_SHIFT */
struct radix_tree_root {
unsigned int height;
gfp_t gfp_mask;
struct radix_tree_node __rcu *rnode;
};
#define RADIX_TREE_INIT(mask) { \
.height = 0, \
.gfp_mask = (mask), \
.rnode = NULL, \
}
#define RADIX_TREE(name, mask) \
struct radix_tree_root name = RADIX_TREE_INIT(mask)
#include <linux/radix-tree.h>
RADIX_TREE(name, gfp_mask); /* Declare and initialize */
(2)
#define INIT_RADIX_TREE(root, mask) \
do { \
(root)->height = 0; \
(root)->gfp_mask = (mask); \
(root)->rnode = NULL; \
} while (0)
#include <linux/radix-tree.h>
struct radix_tree_root my_tree;
INIT_RADIX_TREE(my_tree, gfp_mask);
第一种形式声明并初始化了一个具有给定名称的基数树;第二种形式在运行时执行初始化。在任何情况下,都必须提供gfp_mask来告诉代码如何执行内存分配。如果基数树操作(尤其是插入操作)需要在原子上下文中执行,则给定的掩码应为GFP_ATOMIC。
3.2 radix_tree_insert/delete
// lib/radix-tree.c
/**
* radix_tree_insert - insert into a radix tree
* @root: radix tree root
* @index: index key
* @item: item to insert
*
* Insert an item into the radix tree at position @index.
*/
int radix_tree_insert(struct radix_tree_root *root,
unsigned long index, void *item)
调用radix_tree_insert()将导致给定的条目(与键关联)插入到给定的树中。此操作可能需要进行内存分配;如果分配失败,插入操作将失败,并且返回值将是-ENOMEM。代码将拒绝覆盖现有条目;如果树中已存在键,则radix_tree_insert()将返回-EEXIST。成功时,返回值为零。
/**
* radix_tree_delete - delete an item from a radix tree
* @root: radix tree root
* @index: index key
*
* Remove the item at @index from the radix tree rooted at @root.
*
* Returns the address of the deleted item, or NULL if it was not present.
*/
void *radix_tree_delete(struct radix_tree_root *root, unsigned long index)
radix_tree_delete()从树中删除与键关联的条目,如果存在该条目,则返回指向该条目的指针。
3.3 radix_tree_preload
在某些情况下,无法将项目插入基数树可能是一个重大问题。为了避免这种情况,提供了一对专门的函数:
int radix_tree_preload(gfp_t gfp_mask);
void radix_tree_preload_end(void);
这个函数将尝试分配足够的内存(使用给定的gfp_mask),以确保下一次基数树插入不会失败。分配的结构存储在每个CPU的变量中,这意味着调用函数必须在调度或移动到另一个处理器之前执行插入操作。为此,当radix_tree_preload()成功时,它将返回并禁用抢占;调用者必须最终通过调用radix_tree_preload_end()来确保再次启用抢占。如果失败,将返回-ENOMEM,并且不会禁用抢占。
3.4 radix_tree_lookup
基数树的查找可以通过几种方式进行:
void *radix_tree_lookup(struct radix_tree_root *tree, unsigned long key);
void **radix_tree_lookup_slot(struct radix_tree_root *tree, unsigned long key);
unsigned int radix_tree_gang_lookup(struct radix_tree_root *root, void **results,
unsigned long first_index, unsigned int max_items);
最简单的形式是radix_tree_lookup(),它在树中查找键并返回关联的条目(如果失败则返回NULL)。相反,radix_tree_lookup_slot()将返回指向保存指向该条目的指针的槽位的指针。然后,调用者可以更改指针以将新的条目与键关联起来。然而,如果该条目不存在,radix_tree_lookup_slot()将不会为其创建一个槽位,因此此函数不能用作radix_tree_insert()的替代品。
最后,调用radix_tree_gang_lookup()将以从first_index开始的升序键值,在results中返回最多max_items个条目。返回的条目数量可能小于所请求的数量,但是短返回(非零)并不意味着树中没有更多值。
需要注意的是,基数树的所有函数都不会在内部执行任何形式的锁定。由调用者负责确保多个线程不会破坏树或陷入其他不愉快的竞态条件。目前,Nick Piggin正在流通一项补丁,该补丁将使用读-拷贝-更新(read-copy-update)来释放树节点;只要满足以下条件,此补丁将允许在没有锁定的情况下执行查找操作:(1)结果指针仅在原子上下文中使用,(2)调用代码避免创建自己的竞态条件。然而,目前还不清楚何时会合并该补丁。
3.5 radix_tree_tag_set
基数树代码支持一种称为"标签"的功能,可以在树中的项目上设置特定位。标签常用于标记脏页或正在写回的内存页面。与标签相关的API如下:
void *radix_tree_tag_set(struct radix_tree_root *tree, unsigned long key, int tag);
void *radix_tree_tag_clear(struct radix_tree_root *tree, unsigned long key, int tag);
int radix_tree_tag_get(struct radix_tree_root *tree, unsigned long key, int tag);
radix_tree_tag_set()将在由键索引的项目上设置给定的标签;试图在不存在的键上设置标签将导致错误。返回值将是带有标签的项目的指针。尽管标签看起来像是任意的整数,但当前的代码允许最多设置两个标签。使用除零或一以外的任何标签值将在某些不希望的地方默默地破坏内存;请自行注意。
可以使用radix_tree_tag_clear()删除标签;再次,返回值是(取消)标记的项目的指针。函数radix_tree_tag_get()将检查由键索引的项目是否设置了给定的标签;如果键不存在,则返回值为零;如果键存在但未设置标签,则返回值为-1;否则返回值为+1。然而,由于没有使用该函数的代码,它当前被注释掉了。
3.6 radix_tree_tagged
还有两个用于查询标签的函数:
int radix_tree_tagged(struct radix_tree_root *tree, int tag);
unsigned int radix_tree_gang_lookup_tag(struct radix_tree_root *tree, void **results,
unsigned long first_index, unsigned int max_items, int tag);
radix_tree_tagged()如果树中的任何项目具有给定的标签,则返回非零值。使用radix_tree_gang_lookup_tag()可以获取具有给定标签的项目列表。
我们可以注意到基数树 API 的另一个有趣方面:没有用于销毁基数树的函数。显然,假设基数树将永远存在。实际上,从基数树中删除所有项目将释放与之关联的所有内存,除了根节点,根节点可以按常规方式处理以进行清理。
四、address_space
4.1 简介
基数树最广泛的用途是在内存管理代码中。用于跟踪后备存储的address_space结构包含一个基数树,用于跟踪与该映射关联的核心页面。除此之外,该树还允许内存管理代码快速查找脏页或正在写回的页等功能。
从大量数据的集合(页缓存)中快速获取单个数据元素(页),Linux也采用了基数树这种结构来管理页缓存中包含的页。
在Linux内核中,struct address_space是用于管理文件系统中的文件页缓存(page cache)和内存映射文件的数据结构。
一个address_space管理了一个文件在内存中缓存的所有pages,这部分缓存也是页高速缓存。
大量子系统(文件系统、页交换、同步、缓存)都围绕地址空间的概念展开。因而,这
个概念可以认为是内核最根本的抽象机制之一,以重要性而论,该抽象可跻身于传统抽象如进程、文件之列。
struct address_space {
struct inode *host; /* owner: inode, block_device */
struct radix_tree_root page_tree; /* radix tree of all pages */
......
}
与地址空间所管理的区域之间的关联,是通过以下两个成员建立的:一个指向inode实例(类
型为struct inode)的指针指定了后备存储器,一个基数树的根(page_tree)列出了地址
空间中所有的物理内存页。
内核使用了基数树来管理与一个地址空间相关的所有页。
根据address_space的定义,我们很清楚radix_tree_root结构是每个基数树的的根结点:
/* root tags are stored in gfp_mask, shifted by __GFP_BITS_SHIFT */
struct radix_tree_root {
unsigned int height;
gfp_t gfp_mask;
struct radix_tree_node __rcu *rnode;
};
(1)height指定了树的高度,即根结点之下结点的层次数目。根据该信息和每个结点的项数,内
核可以快速计算给定树中数据项的最大数目。如果没有足够的空间容纳新数据,可以据此对
树进行扩展。
(2)gfp_mask指定了从哪个内存域分配内存。
(3)rnode是一个指针,指向树的第一个结点。该结点的数据类型是radix_tree_node。
基数树的结点基本上由以下数据结构表示:
#define RADIX_TREE_MAP_SHIFT (CONFIG_BASE_SMALL ? 4 : 6)
#define RADIX_TREE_MAP_SIZE (1UL << RADIX_TREE_MAP_SHIFT)
#define RADIX_TREE_MAP_MASK (RADIX_TREE_MAP_SIZE-1)
#define RADIX_TREE_TAG_LONGS \
((RADIX_TREE_MAP_SIZE + BITS_PER_LONG - 1) / BITS_PER_LONG)
struct radix_tree_node {
unsigned int height; /* Height from the bottom */
unsigned int count;
union {
struct radix_tree_node *parent; /* Used when ascending tree */
struct rcu_head rcu_head; /* Used when freeing node */
};
void __rcu *slots[RADIX_TREE_MAP_SIZE];
unsigned long tags[RADIX_TREE_MAX_TAGS][RADIX_TREE_TAG_LONGS];
};
(1)slots
是一个void指针的数组,根据结点所在的层次,指向数据或其他结点。
每个树结点都可以进一步指向64个结点(或叶子),根据radix_tree_node中的slots数组可以
推断。该定义的直接后果是,每个结点中的数组长度都只能为2的幂。另外,基数树结点的大小只能在编译时定义(当然,树中结点的最大数目可以在运行时修改)。
(2)count
保存了该结点中已经使用的数组项的数目。各数组项从头开始填充,未使用的项
为NULL指针。
(3)tags
包括地址空间和页树,但这些并不能让内核直接区分映射的干净页和脏页。在某些时候这种区分是本质性的,例如在将页回写到后备存储器、永久修改底层块设备上的数据时。早期的内核版本在address_space中提供了额外的链表,来列出脏页和干净页。原则上,内核当然可以扫描整个树,并过滤出具备适当状态的页,但这显然非常耗时。为此,基数树的每个结点都包含了额外的标记信息,用于指定结点中的每个页是否具有标记中指定的属性。例如,内核对带有脏页的结点使用了一个标记。在扫描脏页期间,没有该标记的结点即可跳过。这种方案是在简单、统一的数据结构(不需要显式的链表来保存不同状态的页)与快速搜索具备特定性质的页的方案之间的一个折中。
当前支持如下三种标记:
#define RADIX_TREE_MAX_TAGS 3
/*
* Radix-tree tags, for tagging dirty and writeback pages within the pagecache
* radix trees
*/
#define PAGECACHE_TAG_DIRTY 0
#define PAGECACHE_TAG_WRITEBACK 1
#define PAGECACHE_TAG_TOWRITE 2
(1)PAGECACHE_TAG_DIRTY:用于标记脏页,即已经被修改但尚未同步到存储介质上的页面。
(2)PAGECACHE_TAG_WRITEBACK:用于标记正在进行写回操作的页,即已经触发了将脏页写回到存储介质的操作,但尚未完成。
(3)PAGECACHE_TAG_TOWRITE:用于标记待写入页,即需要将脏页写回到存储介质的页面。
Tags是一个二维数组,RADIX_TREE_MAX_TAGS为3代表的是3种tag类型,RADIX_TREE_TAG_LONGS定义slot数占用的long类型长度个数。加入这个值为64,也就是3*64的数组,这样每一行代表一种tag的集合,假如tag[0]代表PAGE_CACHE_DIRTY,假如我们查到当前节点的tags[0]值为1,那么它的子树节点就存在PAGE_CACHE_DIRTY节点,在我们查找PG_dirty的页面时,就不用遍历整个树了,可以提高查找效率。
标记信息保存在一个二维数组中(tags),它是radix_tree_node的一部分。数组的第一维区分不同的标记,而第二维包含了足够数量的unsigned long,使得对该结点中可能组织的每个页,都能分配到一个比特位。
这些标签可以在页缓存的基数树中的节点上进行设置和查询,以便标记和跟踪页面的状态。通过使用这些标签,可以更有效地管理页缓存中的脏页和写回页,以提高文件系统的性能和数据一致性。
radix_tree_tag_set用于对一个特定的页设置一个标志:
void *radix_tree_tag_set(struct radix_tree_root *root,
unsigned long index, unsigned int tag);
内核在位串中操作对应的位置,并将该比特位设置为1。在完成后,将自上而下扫描树,更新所有结点中的信息。为查找所有具备特定标记的页,内核仍然必须扫描整个树,但该操作现在可以被加速,首先可以过滤出至少有一页设置了该标志的所有子树。另外,这个操作还可以进一步加速,内核实际上无须逐比特位检查,只需要检查存储该标记的unsigned long中,是否有某个不为0即可。
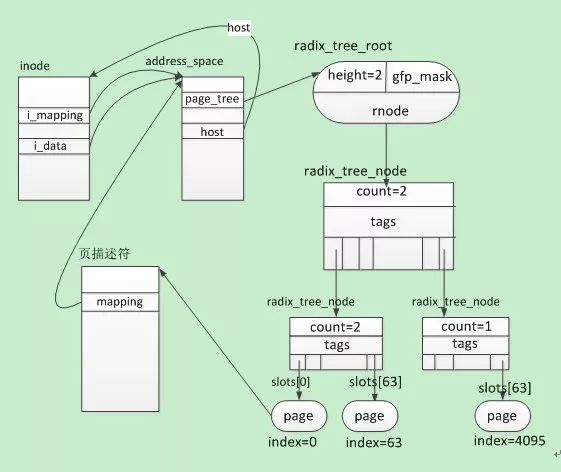
4.2 相应数据结构关系图
1、每个adrres_space对象对应一颗搜索树。他们之间的联系是通过address_space对象中的page_tree字段指向该address_space对象对应的基树。
struct address_space {
......
struct radix_tree_root page_tree; /* radix tree of all pages */
......
}
2、一个inode节点对应一个address_space对象,其中inode节点对象的i_mapping和i_data字段指向相应的 address_space对象,而address_space对象的host字段指向对应的inode节点对象。
struct inode {
......
struct address_space *i_mapping;
......
struct address_space i_data;
......
}
struct address_space {
struct inode *host; /* owner: inode, block_device */
......
}
索引节点的i_mapping字段总是指向索引节点的数据页所有者的address_space对象,address_space对象的host字段指向其所有者的索引节点对象。
因此,如果页属于一个文件(保存在ext4文件系统中),那么页的所有者就是文件的索引节点,而且相应的address_space对象存放在VFS索引节点对象的i_data字段中。索引节点的i_mapping字段指向同一个索引节点的i_data字段,而address_space对象的host字段也只想索引节点。
3、一般情况下一个inode节点对象对应的文件或者是块设备都会包含多个页面的内容,所以一个inode对象对应多个page描述符。同一个文件拥有的所有page描述符都可以在该文件对应的基树中找到。
struct page {
/* First double word block */
......
struct address_space *mapping; /* If low bit clear, points to
* inode address_space, or NULL.
* If page mapped as anonymous
* memory, low bit is set, and
* it points to anon_vma object:
* see PAGE_MAPPING_ANON below.
......
mapping指定了页帧所在的地址空间address_space。地址空间用于将文件的内容(数据)与装载数据的内存区关联起来。通过一个小技巧,mapping不仅能够保存一个指针,而且还能包含一些额外的信息,用于判断页是否属于未关联到地址空间的某个匿名内存区。如果将mapping置为1,则该指针并不指向address_space的实例,而是指向另一个数据结构(anon_vma),该结构对实现匿名页的逆向映射很重要。对该指针的双重使用是可能的,因为address_space实例总是对齐到sizeof(long)。因此在Linux支持的所有计算机上,指向该实例的指针最低位总是0。该指针如果指向address_space实例,则可以直接使用。如果使用了技巧将最低位设置为1,内核可使用下列操作恢复来恢复指针:
anon_vma = (struct anon_vma *) (mapping -PAGE_MAPPING_ANON)
它们之间的关系如下图:
五、XArray
Linux 内核 于 内核主线 4.20 引入XArray 来代替 XArray,理由:
有时候,一个数据结构可能在其预期任务中表现不佳。然而,问题可能出现在其他地方,例如用于访问该数据结构的 API。Matthew Wilcox在2018年linux.conf.au Kernel miniconf期间的演讲中指出,在内核中古老而值得尊敬的基数树数据结构的情况下,后一种情况成立。他提出了一种对旧数据结构的新方法,称之为"XArray"。
他说,内核的基数树是一个很棒的数据结构,但使用它的用户比人们预期的要少得多。相反,各种内核子系统已经实现了自己的数据结构来解决相同的问题。他试图通过转换其中的一些子系统来解决这个问题,并发现这个任务比预期的要困难得多。他得出的结论是,基数树的 API 不好用,它不适合内核中的实际用例。
问题的一部分在于,在这种情况下,“树”这个术语很容易引起困惑。基数树并不像在数据结构教材中常见的经典树结构那样。例如,将项目添加到树中几十年来一直被称为“插入”,但是“插入”并不能真正描述基数树中发生的情况,特别是当具有给定键的项目已经存在时。基数树还支持用户认为很吓人的“异常条目”等概念,这仅仅是因为使用了这样的命名。
因此,Wilcox决定修复接口。他保持了现有的基数树数据结构不变;他说,它几乎没有什么问题。但是,描述其操作的隐喻已经从树变为了数组。它的行为很像一个自动调整大小的数组;从根本上说,它是一个由无符号长整型索引的指针值数组。这种观点更好地描述了该结构的实际使用方式。
基数树要求用户自己进行锁定;而XArray则默认自己处理锁定,简化了使用它的任务。"预加载"机制,允许用户在获取锁之前预分配内存,已被移除;它增加了接口的复杂性,但几乎没有真正的价值。
实际的XArray API被分为两个部分,即常规API和高级API。后者为调用者提供了更多的控制权;例如,它可以用于显式地管理锁定。这个API将在具有特殊需求的调用点使用;页面缓存就是其中一个需要的示例。常规API完全是在高级API之上实现的,因此它作为如何使用高级API的演示。
参考资料
https://en.wikipedia.org/wiki/Radix_tree
https://lwn.net/Articles/175432/
https://lwn.net/Articles/745073/
https://juejin.cn/post/6933244263241089037
https://www.cnblogs.com/Linux-tech/p/12961281.html
https://blog.csdn.net/JiMoKuangXiangQu/article/details/129490548
https://xie.infoq.cn/article/1c48f3cd7fda167c4194d1cc0
https://blog.csdn.net/Je930502/article/details/80294987