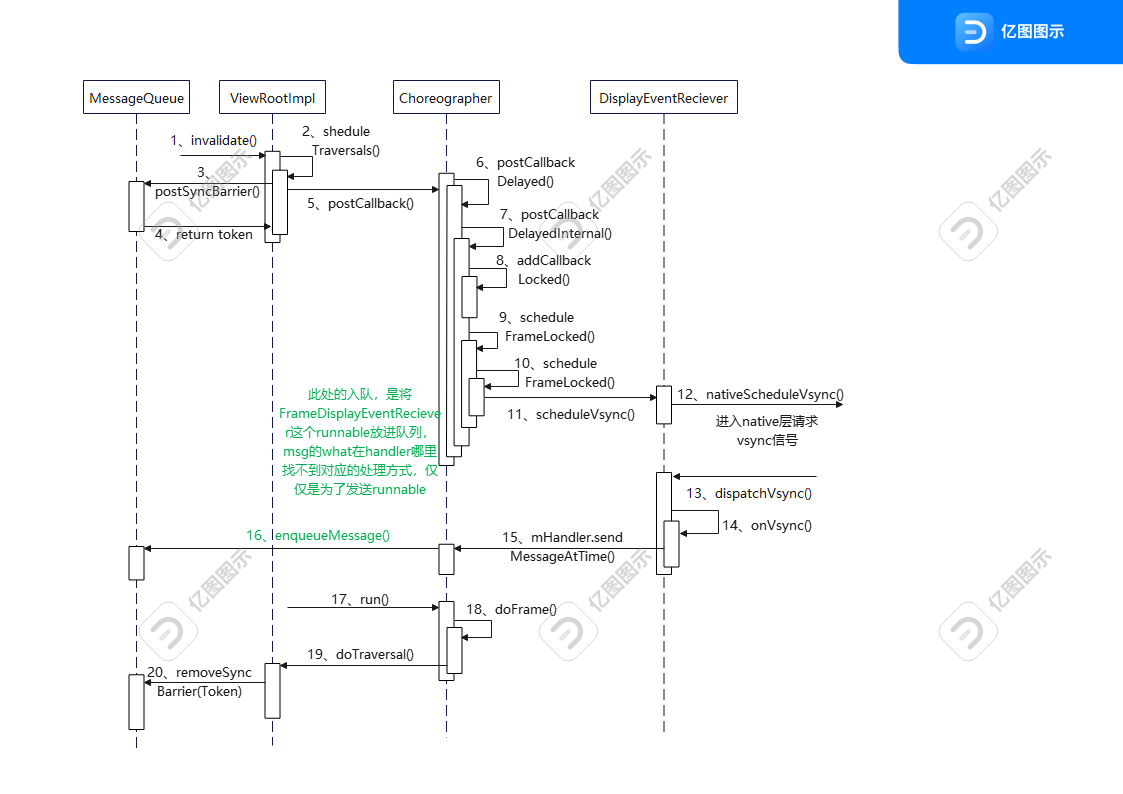
SQLAlchemy Unified Tutorial
SQLAlchemy 是 Python SQL工具包和ORM,它为应用程序开发人员提供了 SQL 的全部功能和灵活性。它提供了一整套企业级持久性模式,专为高效和高性能的数据库访问而设计。

SQLAlchemy呈现为两层API:Core和ORM, ORM构建在Core的基础上。
- Core是基础,提供了 数据库连接、查询、构造SQL语句等工具。
- ORM基于Core构建,提供对象关系映射(object relational mapping)。
建立连接–Engine
SQLAlchemy程序的开始都要创建Engine对象,用于连接数据库。
下面我们使用内存中的SQLite数据库,创建一个Engine对象。
from sqlalchemy import create_engine
engine = create_engine("sqlite+pysqlite:///:memory:", echo=True)
create_engine的参数是字符串,包含了数据库的连接信息。echo=True表示打印日志。
"sqlite+pysqlite:///:memory:"包含3个信息:
- sqlite: SQLite数据库
- pysqlite: DBAPI
- memory:内存数据库
使用事务和DBAPI
获取连接
Engine对象的唯一目的是提供与数据库的连接(Connection)。
from sqlalchemy import text
with engine.connect() as conn:
result = conn.execute(text("select 'hello world'"))
print(result.all())
在上面的示例中,上下文管理器提供了数据库连接,并在事务中构建了操作。
Python DBAPI 的默认行为包括事务始终在进行中;当释放连接范围时,将发出 ROLLBACK 以结束事务。事务不会自动提交;当我们想要提交数据时,我们通常需要调用 Connection.commit()。
commit
- commit as you go.
with engine.connect() as conn:
conn.execute(text("CREATE TABLE some_table (x int, y int)"))
conn.execute(
text("INSERT INTO some_table (x, y) VALUES (:x, :y)"),
[{"x": 1, "y": 1}, {"x": 2, "y": 4}],
)
conn.commit()
- begin once:
另一种提交数据的方式,预先声明“连接”块是一个事务块。使用 Engine.begin() 方法来获取连接。
此方法既可以管理事务的范围 Connection ,又可以将所有内容包含在事务中,并在最后使用 COMMIT(假设区块成功)或 ROLLBACK,以防出现异常。这种样式称为 begin once:
with engine.begin() as conn:
conn.execute(
text("INSERT INTO some_table (x, y) VALUES (:x, :y)"),
[{"x": 6, "y": 8}, {"x": 9, "y": 10}],
)
begin once的风格通常是首选,因为它更简洁,并且预先表明了整个块的意图。但是,在本教程中,我们通常会使用“commit as you go”样式,因为它在演示方面更加灵活。
执行语句 基础
获取行
with engine.connect() as conn:
result = conn.execute(text("SELECT x, y FROM some_table"))
for row in result:
print(f"x: {row.x} y: {row.y}")
发送参数
with engine.connect() as conn:
result = conn.execute(text("SELECT x, y FROM some_table WHERE y > :y"), {"y": 2})
for row in result:
print(f"x: {row.x} y: {row.y}")
发送多个参数
(列表, 多次调用(executemany))
with engine.connect() as conn:
conn.execute(
text("INSERT INTO some_table (x, y) VALUES (:x, :y)"),
[{"x": 11, "y": 12}, {"x": 13, "y": 14}],
)
conn.commit()
使用ORM Session
使用 ORM 时,基本的事务/数据库交互对象称为Session .在现代 SQLAlchemy 中,此对象的使用方式与 Connection 非常相似,实际上,当使用Session时 ,它内部使用Connection对象。
from sqlalchemy.orm import Session
stmt = text("SELECT x, y FROM some_table WHERE y > :y ORDER BY x, y")
with Session(engine) as session:
result = session.execute(stmt, {"y": 6})
for row in result:
print(f"x: {row.x} y: {row.y}")
类似Connection, Session也有“commit as you go”的方式,使用Session.commit()提交数据。
with Session(engine) as session:
result = session.execute(
text("UPDATE some_table SET y=:y WHERE x=:x"),
[{"x": 9, "y": 11}, {"x": 13, "y": 15}],
)
session.commit()
使用数据库元数据
随着Engine 和 SQL 语句的结束,我们准备开始一些炼金术。SQLAlchemy Core 和 ORM 的核心元素是 SQL 表达式语言,它允许流畅、可组合的 SQL 查询构造。这些查询的基础是表示表和列等数据库概念的 Python 对象。这些对象统称为数据库元数据。
SQLAlchemy 中数据库元数据最常见的基础对象称为 MetaData 、 Table 和 Column。
Table
当我们使用关系数据库时,我们从中查询的数据库中的基本数据保存结构称为表。在 SQLAlchemy 中,数据库“表”最终由一个类似名称 Table 的 Python 对象表示。
我们总是从一个集合开始,该集合将作为我们放置表的位置, 即MetaData对象。此对象本质上是围绕 Python 字典的外观,该字典存储一系列键入其字符串名称的 Table 对象。
from sqlalchemy import MetaData
metadata_obj = MetaData()
然后我们创建Table对象。
该模型具有一个名为的 user_account 表,用于存储网站的用户,以及一个关联表 address ,用于存储 user_account 与表中的行关联的电子邮件地址。
当完全不使用 ORM 声明性模型时,我们直接构造每个 Table 对象,通常将每个对象分配给一个变量:
from sqlalchemy import Table, Column, Integer, String
user_table = Table(
"user_account",
metadata_obj,
Column("id", Integer, primary_key=True),
Column("name", String(30)),
Column("fullname", String),
)
当我们想引用数据库中 user_account 表时,我们将使用 user_table变量来引用它。
Table的组成:
我们发现,Table对象类似SQL CREATE TABLE语句的结构。它包含表的名称,列的名称和类型。
- Table:表
- Column:列,可通过table.c.列名 访问
user_table.c.name
user_table.c.keys()
简单约束
user_table表的第一个 Column 包含参数Column.primary_key,用于指示这应该 Column 是此表的主键。。主键通常是隐式声明的,由 PrimaryKeyConstraint构造,我们可以在 Table 对象上的 Table.primary_key 属性上看到它
最典型的显式声明的约束是对应于数据库外键约束的 ForeignKeyConstraint 对象。当我们声明彼此相关的表时,SQLAlchemy 使用这些外键约束声明的存在,不仅使它们在 CREATE 语句中发出到数据库,而且还有助于构造 SQL 表达式。
仅涉及单个列的外键约束 通常通过 ForeignKey进行声明。
下面我们声明第二个表address,该表 将具有引用该 user 表的外键约束:
from sqlalchemy import ForeignKey
address_table = Table(
"address",
metadata_obj,
Column("id", Integer, primary_key=True),
Column("user_id", ForeignKey("user_account.id"), nullable=False),
Column("email_address", String, nullable=False),
)
向数据库发出 DDL
我们已经有了包含2个表的元数据对象,现在我们可以使用MetaData.create_all()方法将这些表发送到数据库。
metadata_obj.create_all(engine)
MetaData 对象还具有一个 MetaData.drop_all() 方法,该方法将以与CREATE相反的顺序发出 DROP 语句。
使用 ORM 声明性表单定义表元数据
使用 ORM 时, MetaData 集合仍然存在,但它本身与通常称为声明性基的仅 ORM 结构相关联。获取新的声明性库的最便捷方法是创建一个新类,该类对 SQLAlchemy DeclarativeBase 类进行子类化
from sqlalchemy.orm import DeclarativeBase
class Base(DeclarativeBase):
pass
上面的 Base 类就是我们所说的声明性基础。当我们创建作为 的 Base 子类的新类时,结合适当的类级指令,它们将在类创建时被建立为一个新的 ORM 映射类,每个类通常(但不限于)引用一个特定的 Table 对象。
声明映射类
建立 Base 类后,我们现在可以根据新类 User 和 Address 来定义 user_account 和 表 address 的 ORM 映射类。我们在下面说明最现代的声明形式,它由PEP 484类型注释驱动,使用特殊类型,该类型 Mapped 指示要映射为特定类型的属性:
from typing import List
from typing import Optional
from sqlalchemy.orm import Mapped
from sqlalchemy.orm import mapped_column
from sqlalchemy.orm import relationship
class User(Base):
__tablename__ = "user_account"
id: Mapped[int] = mapped_column(primary_key=True)
name: Mapped[str] = mapped_column(String(30))
fullname: Mapped[Optional[str]]
addresses: Mapped[List["Address"]] = relationship(back_populates="user")
def __repr__(self) -> str:
return f"User(id={self.id!r}, name={self.name!r}, fullname={self.fullname!r})"
class Address(Base):
__tablename__ = "address"
id: Mapped[int] = mapped_column(primary_key=True)
email_address: Mapped[str]
user_id = mapped_column(ForeignKey("user_account.id"))
user: Mapped[User] = relationship(back_populates="addresses")
def __repr__(self) -> str:
return f"Address(id={self.id!r}, email_address={self.email_address!r})"
从 ORM 映射向数据库发出 DDL
Base.metadata.create_all(engine)
Table Reflection
表反射是指通过读取数据库的当前状态来生成 Table 对象 和相关对象的过程。 (即上面操作的逆过程)
some_table = Table("some_table", metadata_obj, autoload_with=engine)
some_table
处理数据(CRUD) (Core的角度)
- INSERT
- SELECT
- UPDATE and DELETE
通过ORM处理数据
插入行
类的实例表示行:
squidward = User(name="squidward", fullname="Squidward Tentacles")
krabs = User(name="ehkrabs", fullname="Eugene H. Krabs")
向Session添加对象:
session = Session(engine)
session.add(squidward)
session.add(krabs)
此时,对象仍然在“挂起”状态,即它们尚未被发送到数据库。
Flushing
flush会向数据库发送SQL语句推送更改:
session.flush()
通常不需要手动调用session.flush(),因为 Session 更改具有自动刷新的行为。
自动生成的主键
squidward.id
krabs.id
从主键获取对象
some_squidward = session.get(User, 4)
some_squidward
提交
session.commit()
Update
sandy = session.execute(select(User).filter_by(name="sandy")).scalar_one()
sandy.fullname = "Sandy Squirrel"
当Session 发送flush时,将发出一个 UPDATE,用于更新数据库中的此值。
如前所述,在我们发出任何 SELECT 之前,会自动刷新。我们可以直接从此行查询列, 并返回更新后的值:
sandy_fullname = session.execute(select(User.fullname).where(User.id == 2)).scalar_one()
print(sandy_fullname)
Delete
patrick = session.get(User, 3)
session.delete(patrick)
Bulk / Multi Row INSERT, upsert, UPDATE and DELETE
https://docs.sqlalchemy.org/en/20/orm/queryguide/dml.html#orm-expression-update-delete
Rolling Back (回滚)
session.rollback() 会撤消所有未提交的更改。
关闭session
session.close()
ORM Related Objects
我们先回顾一下之前的relationship():
from sqlalchemy.orm import Mapped
from sqlalchemy.orm import relationship
class User(Base):
__tablename__ = "user_account"
# ... mapped_column() mappings
addresses: Mapped[List["Address"]] = relationship(back_populates="user")
class Address(Base):
__tablename__ = "address"
# ... mapped_column() mappings
user: Mapped["User"] = relationship(back_populates="addresses")
上面, User类有User.addresses属性 ,而 Address类有Address.user属性。 relationship() 与 Mapped一起用于检查映射到 Address和User 对象之间的表关系。由于表示表的 Table 对象具有 ForeignKeyConstraint 指称 user_account 表的对象, relationship()可以明确地确定从 User 类到 Address 类之间存在着一对多的关系; user_account 表中的一行可以包含address表中的多行(一个用户可以有多个邮箱地址)。
一对多关系自然对应于另一个方向上的多对一关系,在本例中为 Address.user 。上面在引用另一个名称的两个 relationship() 对象上配置的 relationship.back_populates 参数确定这两个 relationship() 构造中的每一个都应被视为相互互补;我们将在下一节中看到这是如何发挥作用的。
持久化和加载关系
果我们创建一个新 User 对象,我们可以注意到,当我们访问该 .addresses 元素时,有一个 Python 列表:
u1 = User(name="pkrabs", fullname="Pearl Krabs")
u1.addresses # []
使用list.append() 方法,我们可以添加一个 Address 对象:
a1 = Address(email_address="pearl.krabs@gmail.com")
u1.addresses.append(a1)
再看u1.addresses,发现已经添加成功了:
u1.addresses
# [Address(id=None, email_address='pearl.krabs@gmail.com')]
此外,u1也被a1关联了:
a1.user
# User(id=None, name='pkrabs', fullname='Pearl Krabs')
这种同步是由于我们在两个 relationship() 对象之间使用了参数 relationship.back_populates 。此参数命名另一个应发生互补属性赋值/列表突变的参数 relationship() 。它在另一个方向上同样有效,即如果我们创建另一个 Address 对象并赋值给其 Address.user 属性,它 Address 将成为该 User 对象 User.addresses 集合的一部分:
a2 = Address(email_address="pearl@aol.com", user=u1)
u1.addresses
# [Address(id=None, email_address='pearl.krabs@gmail.com'), Address(id=None, email_address='pearl@aol.com')]
Cascading Objects
当我们用Session.add() 添加User 对象时,相关 Address 对象也会被添加到该 Session 对象中:
session.add(u1)
u1 in session
a1 in session
a2 in session
# 3 True
上述行为,即 Session 接收到一个 User 对象,并沿着 User.addresses 关系找到相关 Address 对象,称为保存-更新级联(save-update cascade)。
这三个对象现在处于挂起状态;这意味着他们已准备好成为 INSERT 操作的对象,但尚未进行;这三个对象都尚未分配主键,此外, a1 和 a2 对象具有user_id属性,该属性引用的Column具有ForeignKeyConstraint (关于user_account.id) 的属性;这些也是 None, 因为对象尚未与实际数据库行关联:
print(u1.id)
print(a1.user_id)
# None None
当使用 Session 时,所有这些乏味的事情都会为我们处理:我们使用 Session.commit() 提交时,所有步骤都以正确的顺序调用,此外,新生成的 user_account 行主键被适当地应用于 address.user_id 列:
session.commit()
Loading Relationships
延迟加载…
在查询中使用关系
JOIN
print(select(Address.email_address).select_from(User).join(User.addresses))
print(select(Address.email_address).join_from(User, Address))
WHERE
https://docs.sqlalchemy.org/en/20/orm/queryguide/index.html