文章目录
- 一、需求
- 二、爬取阶段
- 1.使用requests进行请求获取网页内容
- 2.使用selenium模拟人操作浏览器获取网页内容
- (1)环境配置
- (2) 源码
- 3.使用phantomjs模拟人操作浏览器获取网页内容
浅浅记录一下自己在做一个比赛数据处理过程中的遇到的一些问题。
一、需求
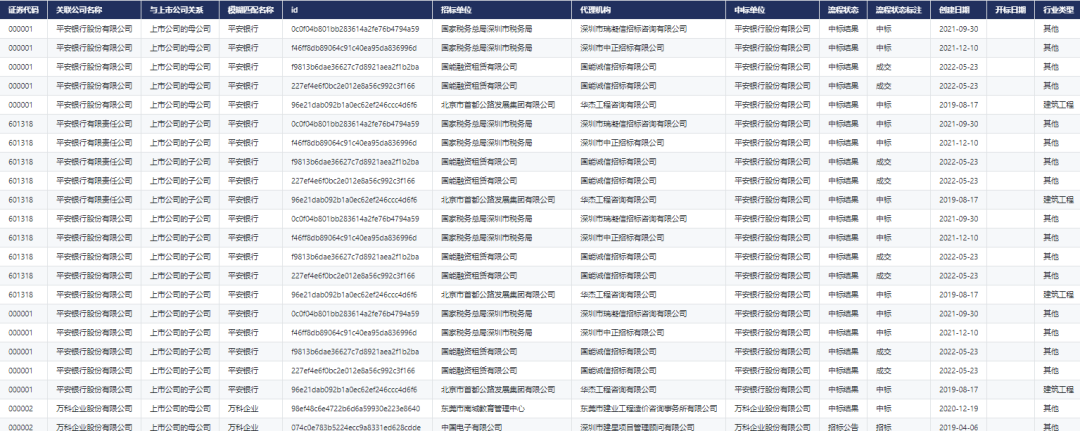
首先数据的格式是长下面图片这样的,左边是网站链接,右边是网站分类的标签,然后我要做的工作就是访问每个网站将网站的文本爬取下放在每个链接后边。

二、爬取阶段
下面就是我的尝试过程了😂
1.使用requests进行请求获取网页内容
import requests
from fake_useragent import UserAgent
def completionUrl(url):
'''对url进行补全'''
if "http" in url:
return url
else:
url = f"http://" + url.strip('"')
return url
def getContent(url):
'''获取网页源代码'''
# 对url进行补全
url = completionUrl(url)
# 发送请求获取网页内容
# 设置随机useragent简单防爬
headers = {"User-Agent": UserAgent().random}
try:
resp = requests.get(url=url, headers=headers, verify=False)
# print(resp.encoding) # 查看返回内容的编码 针对对应的特殊编码进行解码
if resp.encoding == "ISO-8859-1":
# 解决ISO-8859-1编码问题
html = resp.text.encode('ISO-8859-1').decode(requests.utils.get_encodings_from_content(resp.text)[0])
# print(html)
else:
html = resp.text
print(f"url:{url} html:{html}")
return html
# 处理网站请求失败的情况
except Exception as e:
# print(f"ERROR of {url}",e)
html = "网站请求失败"
print(f"url:{url} html:{html}")
return html
if __name__ == '__main__':
url = "www.baidu.com"
content = getContent(url)
在使用requests发请求获取网页内容的时候发现,就是很多网站有针对requests请求的反爬机制。导致很多网站的数据无法获取,这个时候我就想到了模拟人的行为操作浏览器获取数据,虽然使用selenium可能也有部分网站会有反爬,但是情况应该比使用requests要好很多。
2.使用selenium模拟人操作浏览器获取网页内容
(1)环境配置
具体步骤可以参考博客microsoft edge驱动器下载以及使用
在使用selenium进行爬取之前,先要下载好相应的浏览器驱动。我用的是edge浏览器,所以我就下载edge浏览器的驱动。
根据你edge浏览器的版本,下载对应版本的驱动,可以看到我edge浏览器的版本号是109.0.1518.55。

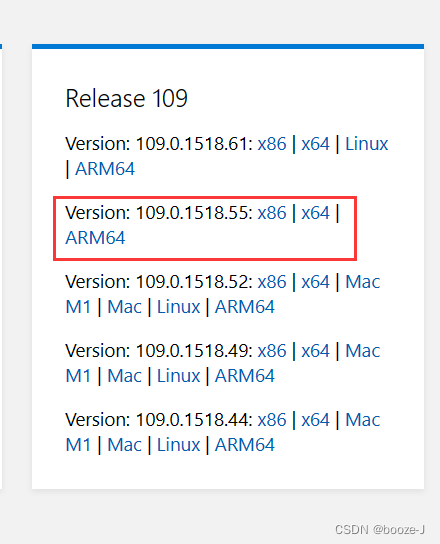
下载好了之后将msedgedriver.exe放置到你使用python环境中python.exe的同级目录下。
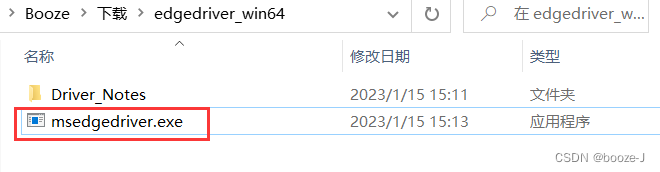
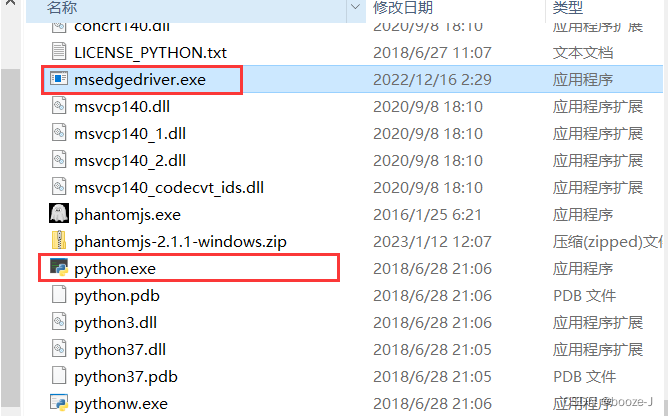
之后就是下载selenium包到你所用的环境即可。
(2) 源码
from selenium import webdriver
from fake_useragent import UserAgent
from selenium.webdriver.edge.options import Options
from selenium.webdriver.common.desired_capabilities import DesiredCapabilities
def completionUrl(url):
'''对url进行补全'''
if "http" in url:
return url
else:
url = f"http://" + url.strip('"')
return url
def driver():
'''获取浏览器驱动对象'''
# 准备好参数配置,将该参数传入Edge可以使其不弹出窗口 但是这个对selenium的版本要求较高,较低版本没有这个参数
opt = Options()
# opt.add_argument("--headless")
# opt.add_argument('--disable-gpu')
# # 设置随机user-agent 简单防爬
# opt.add_argument(f'user-agent={UserAgent().random}')
# 解决浏览器加载时间过长的问题
# opt.page_load_strategy = 'eager'
# driver = webdriver.Edge(options=opt)
driver = webdriver.Edge()
# 设置请求时间
driver.set_page_load_timeout(15)
return driver
def getHtmlBySelenium(url,driver):
'''使用浏览器驱动对象获取网页内容'''
# 对url进行补全
url = completionUrl(url)
html = driver.get(url)
# 获取网页源码
html = driver.execute_script("return document.documentElement.outerHTML")
return html
if __name__ == '__main__':
# 使用selenium模拟人操作浏览器获取网页内容
url = "www.baidu.com"
driver_ = driver()
html = getHtmlBySelenium(url,driver_)
print(f"html:{html}")
参考博客:
Selenium 等待与超时(一) - 知乎 (zhihu.com)
selenium之chrome浏览器设置userAgent和代理ip_夜阑卧听风吹雨,铁马冰河入梦来的博客-CSDN博客_selenium useragent
当我使用selenium之后还是发现了一些问题,每次使用edge浏览器爬取了差不多100个网址之后就不行了,后来怀疑是浏览器驱动的问题,换成了无头浏览器phantomjs。
3.使用phantomjs模拟人操作浏览器获取网页内容
安装使用可参考博客:
- phantomjs下载安装与使用_李汶峰的博客-CSDN博客_下载plantomjs
- Python爬虫:selenium使用chrome和PhantomJS实用参数_彭世瑜的博客-CSDN博客
但是phantomjs对selenium的版本有所要求,新版selenium不支持PhantomJS 要用老版本吗 · Issue #48 · sczhengyabin/Image-Downloader (github.com),需要安装指定的selenium版本才可以使用。
from selenium import webdriver
from fake_useragent import UserAgent
from selenium.webdriver.common.desired_capabilities import DesiredCapabilities
def completionUrl(url):
'''对url进行补全'''
if "http" in url:
return url
else:
url = f"http://" + url.strip('"')
return url
def driver():
'''获取浏览器驱动对象'''
dcap = dict(DesiredCapabilities.PHANTOMJS)
# 设置user-agent请求头
dcap["phantomjs.page.settings.userAgent"] = UserAgent().random
# 禁止加载图片
dcap["phantomjs.page.settings.loadImages"] = False
driver = webdriver.PhantomJS(desired_capabilities=dcap)
# 设置请求时间
driver.set_page_load_timeout(15)
return driver
def getHtmlBySelenium(url,driver):
'''使用浏览器驱动对象获取网页内容'''
# 对url进行补全
url = completionUrl(url)
html = driver.get(url)
# 获取网页源码
html = driver.execute_script("return document.documentElement.outerHTML")
return html
if __name__ == '__main__':
# 使用selenium模拟人操作浏览器获取网页内容
url = "www.baidu.com"
driver_ = driver()
html = getHtmlBySelenium(url,driver_)
print(f"html:{html}")
最后发现确实phantomjs浏览器驱动比edge浏览器驱动好用。







![剑指 Offer 03. 无重复字符的最长子串 [C语言]](https://img-blog.csdnimg.cn/2a7f8a0283f647039c01b7f74b67d470.png)

![一文读透JVM虚拟机结构[迭代中]](https://img-blog.csdnimg.cn/img_convert/f436dce071d1653571e2b9bd8a2bdd2e.webp?x-oss-process=image/format,png)