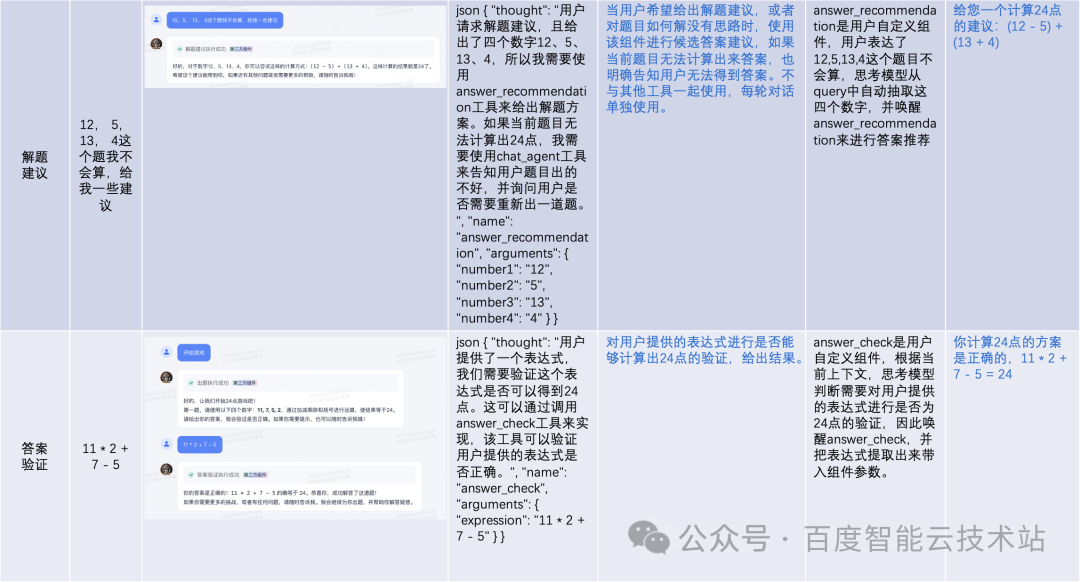
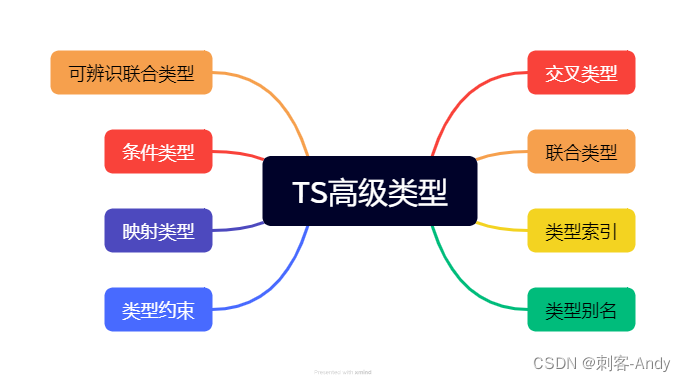
AlphaCodium 的代码生成方法
论文地址:https://arxiv.org/pdf/2401.08500.pdf
源码地址:https://github.com/codium-ai/alphacodium
研究要点包括
- **挑战:**现有的自然语言优化方法无法扩展 LLM 的代码生成能力
- **解决方案:**使用 "测试驱动、多阶段代码生成流程 "AlphaCodium 进行优化。
- **要点:**AlphaCodium 可以提高 GPT-4 生成代码的能力。
总之,AlphaCodium 这种独特的代码生成方法可以提高 LLM 在编程领域的性能。
顺便提一下,AlphaCodium 通过直接使用通用语言模型(如 GPT 和 DeepSeek)而无需额外训练,并应用专用流程,成功地大幅提高了代码生成性能。
这种方法可应用于各种语言模型,而无需额外的数据或计算成本高昂的训练阶段。
现有方法无法发挥 LLM 的代码生成潜力
最近的大规模语言模型(LLM)在为简单的编程任务生成代码方面表现出色。然而,现实世界中的编程要复杂得多,因此即使是最新的 LLM 也经常无法达到预期效果。
这是因为代码生成任务具有不同于自然语言处理的特殊挑战,自然语言的优化方法无法直接应用。
具体来说,他们面临以下挑战
- 不同的编程语言有不同的语法规则。
- 小错误造成语法错误。
- 难以正确处理特殊情况,如输入错误。
- 难以将自然语言描述的问题陈述转化为详细的代码。
- 难以满足时间计算和内存使用等非功能性要求
- 难以选择和实施适当的复杂数据结构和算法
- 在设计时很难意识到需要结合和使用多种规范
- 难以限制执行环境
迄今为止,代码生成一直采用 “自然语言任务优化方法”,随着任务变得越来越复杂,这种方法很容易导致错误。
因此,为了提高更复杂的编码任务的性能,人们研究了专门针对编码任务的优化方法。
现有研究
CodeContests 数据集的发布使我们能够对从竞技编程平台上收集到的解决更难编程问题的模型和方法进行评估。
在早先的 AlphaCode 研究中,大量的计算是通过微调进行的,这被认为是不切实际的。
CodeChain 还引入了一个新的推理框架。
阿尔法钠的具体流量。
AlphaCodium 代码生成过程分为两个主要阶段:"预处理阶段 "和 “迭代阶段”。

上图左侧为预处理阶段,右侧为迭代阶段。
预处理阶段
**在预处理阶段,对自然语言中指定的问题进行分析和推理。**具体来说,需要执行以下流程
- 从问题陈述中提取目标、输入、输出、规则和约束条件,并由人工智能逐项列出
- 根据对问题文本的理解,生成多个候选答案代码
- 对生成的答案代码进行排序并选出最佳代码
- 对选定的答案代码进行验证测试。
- 分析验证测试的结果并创建额外的测试用例
这意味着,预处理阶段使用自然语言处理来分析问题,生成和选择初始候选解决方案代码,并准备测试用例供迭代阶段使用。
下面是一个给定问题陈述的示例,其中包括任务目标、输入、输出、规则和限制等信息。

然后从上述问题陈述中提取信息,并由人工智能以要点形式总结如下

迭代阶段
**在迭代阶段,对预处理阶段生成的求解代码进行改进。**具体来说,要重复以下循环。
- 在预处理阶段选择的答案代码被用作初始代码。
- 在 "公共测试 "中测试初始代码。
- 分析测试结果,修改和改进代码
- 重新测试改进后的代码,如果结果有所改善,则予以采用
- 通过 "更多人工智能生成的测试 "进一步迭代改进
- 重新测试改进后的代码,如果结果有所改善,则予以采用
这意味着,在迭代阶段,代码会被实际执行,并利用测试结果作为反馈,逐步完善解决方案代码。除了现有的测试数据集,测试还利用了人工智能生成的额外测试集,从而实现了高度全面的验证。
代码生成任务的技术
在使用 AlphaCodium 生成代码时,以下描述的技术更为有效
- 使用 YAML 格式的结构化输出。
- 列表形式的语义推理
- 模块化代码生成
- 通过双重验证进行软决策。
- 留有余地,避免直接提问
- 测试锚
这些方法被认为不仅广泛适用于本研究,也适用于使用 LLM 的代码生成任务。
下面将依次介绍每种技术。
使用 YAML 格式的结构化输出
在设计提示时要求以 YAML 格式输出,可以系统地表示复杂的任务,大大减少提示工程的工作量。

作者认为,YAML 格式比 JSON 格式更合适,特别是在代码生成任务中。
生成的代码通常包含单引号、双引号和特殊字符,但在 JSON 中很难有效地放置这些字符。另一方面,在 YAML 中,只要遵守适当的缩进,块标量格式就可以正确地表示任意文本和代码。
YAML 格式所需的标记也比 JSON 少,因为它不需要像 JSON 那样的大括号、引号和转义字符。

这将降低成本,缩短推理时间,提高质量。
列表形式的语义推理
当要求人们对一个问题进行推理时,将输出结果以项目符号的形式呈现会取得更好的效果。这是因为项目要点能促使法律硕士更深入地理解问题,并改进输出结果。
模块化代码生成
指导他们生成代码时,不要只生成一个函数,而是将代码详细拆分成多个函数,这样生成的代码质量高,错误少。
通过双重验证进行软决策
通过提供一个额外步骤,要求学习者重新生成生成的输出结果并进行必要的修改,鼓励学习者进行 “批判性推理”。
他们认为,这比直接要求回答 "是或否 "的问题更有效。
留有余地,避免直接提问
就复杂问题直接提问往往会产生错误的答案。因此,采用的流程是从较简单的任务中逐步积累数据。该公司表示,重要的是要避免不可逆转的决定,并为探索和代码迭代留出空间。
测试锚
由于一些人工智能生成的测试可能是不正确的,因此它们被用作在公共测试集中验证过的测试的锚点,以防止对代码进行不正确的修改。
效果
实验细节
为了测试所提方法的有效性,我们在竞赛编程问题数据集 CodeContests 上进行了实验。
与直接提示输入法相比,本实验评估了 AlphaCodium 在多大程度上提高了 LLM 代码生成性能。
此外,还将 AlphaCodium 的性能与之前的研究 AlphaCode 和 CodeChain 进行了对比评估。
数据集
本研究使用竞赛编程问题数据集CodeContests来评估 AlphaCodium 的性能。
CodeContests 数据集的主要特点是
- 由从竞赛编程平台收集的问题组成。
- 冗长复杂的自然语言问题描述。
- 每个问题可提供约 200 个私人输入/输出测试。
- 它包含 10 000 个训练数据、107 个验证数据和 165 个测试数据(本研究不使用训练集,只使用验证集和测试集)。
如上所述,CodeContests 是一个很好的基准,它由现实而具有挑战性的问题组成,侧重于竞赛编程。
结果
如前所述,本研究进行了两项实验
- 直接提示输入与 AlphaCodium
- 以前对阿尔法钠的研究
让我们依次来看看它们。
直接提示输入与 AlphaCodium
每个问题生成五个代码,然后比较正确答案的百分比(pass@5)。
结果如下(METHOD 一栏中的 “直接”= 直接提示输入)。

结果表明,在使用 GPT-4 时,AlphaCodium 在验证集上的正确率从 19% 提高到 44%(提高了 2.3 倍)。
其他模型,如 GPT-3.5 和 DeepSeek,也显示出持续和显著的改进。
…先前的研究与 AlphaCodium 的对比
与之前一样,每个问题生成五个代码,然后比较正确答案的百分比(pass@5)。
结果如下
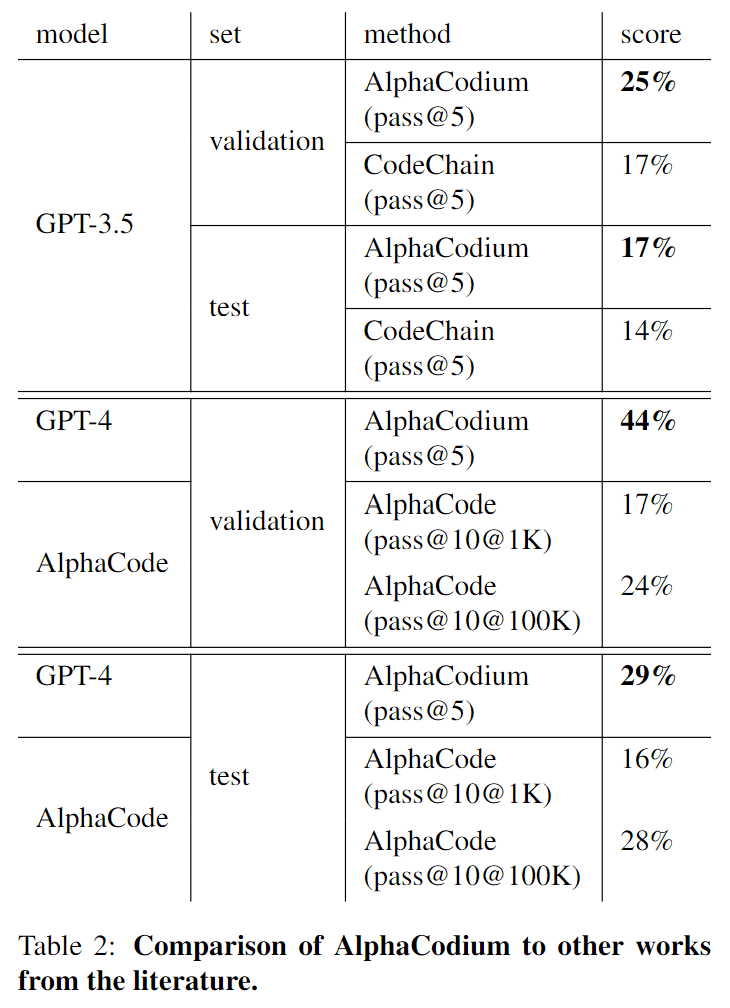
结果表明,在使用相同的 GPT-3.5 模型时,AlphaCodium 的性能比 CodeChain 更好。
顺便提一下,AlphaCode 涉及微调和大量计算,而 AlphaCodium 则使用 LLM,无需训练。不过,我们可以看到,AlphaCodium 仍能实现与 AlphaCode 相同甚至更好的性能,而计算复杂度却不到 AlphaCode 的万分之一。
AlphaCodium 大大提高了 LLM 代码生成的性能
本文介绍了对 AlphaCodium 的研究,这是一种专门针对竞赛编程问题的新代码生成方法
这是一项重要的研究,表明 LLM 的代码生成性能有了显著提高。
本研究的局限性包括以下三点。
- 该方法专门针对竞赛编程问题,需要在实际开发中加以应用。
- 不仅希望在 CodeContests 上进行验证,还希望在其他数据集上进行验证
- 该方法专门用于代码生成,对其他任务的适用性尚不清楚。