本文将以LLaVa源码为例,解析如何使用Trainer训练/微调一个VLM。
- 1. 参数解析
- ModelArguments
- DataArguments
- TrainingArguments
- 2. 加载模型
- 3. 加载数据
- 4. 创建Trainer开始训练
1. 参数解析
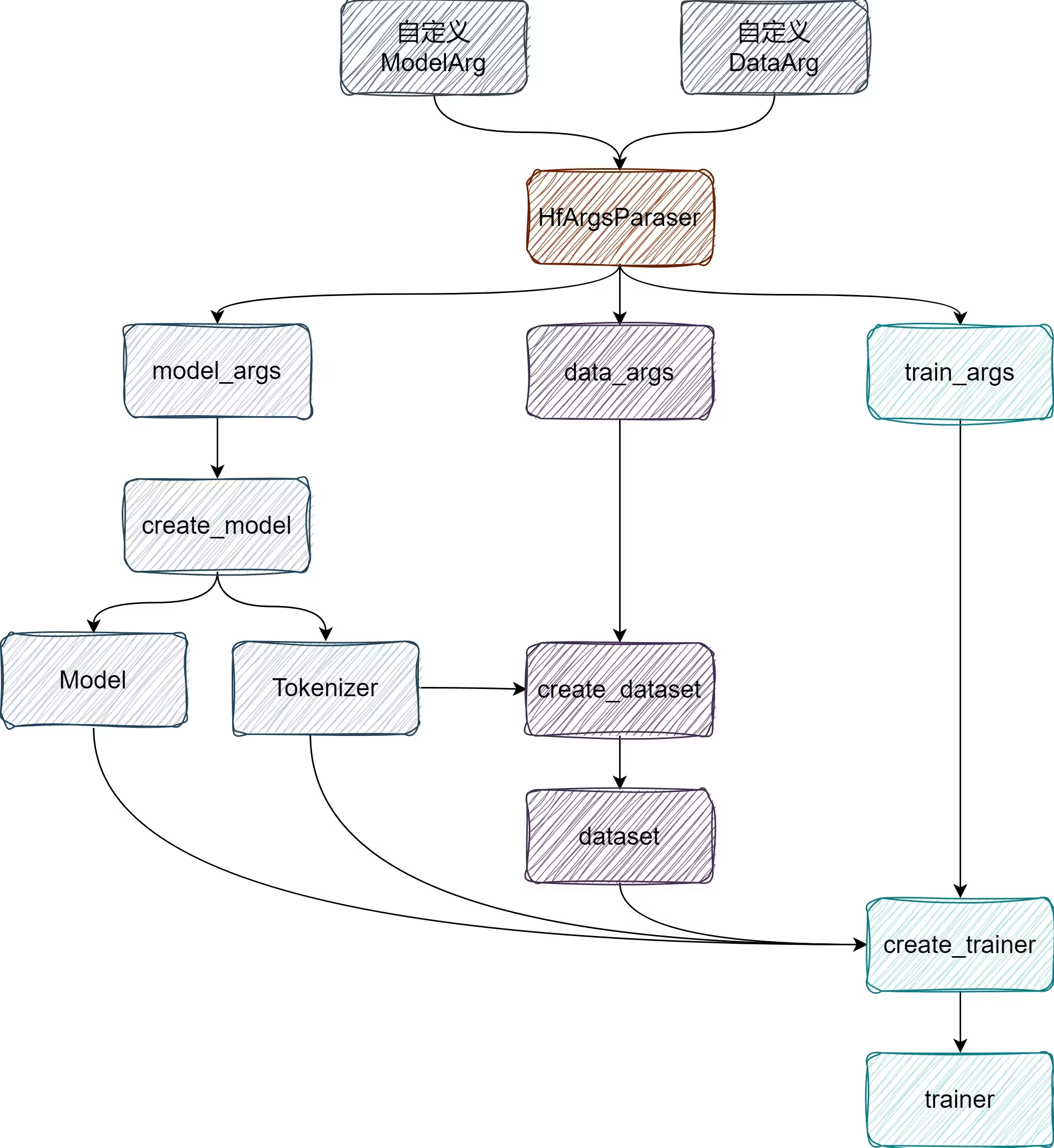
VLM 和 LLM 相关训练框架都会引入 ModelArguments、DataArguments、TrainingArguments、GeneratingArguments 并通过 Transformer.HfArgumentParser 进行整合,然后再用parse_args_into_dataclasses()方法解析成 hf 的标准形式model_args, data_args, training_args,实现了两行代码处理训练全程的参数问题。这些命令行参数会从.sh的Shell 代码文件中导入。
from typing import Optional
from dataclasses import dataclass, field
import transformers
...
添加上述的 Argument Class
...
if __name__ == '__main__':
parser = transformers.HfArgumentParser((ModelArguments, DataArguments, TrainingArguments, GeneratingArguments))
model_args, data_args, training_args, generate_args = parser.parse_args_into_dataclasses()
print(model_args)
print(data_args)
print(training_args)
print(generate_args)
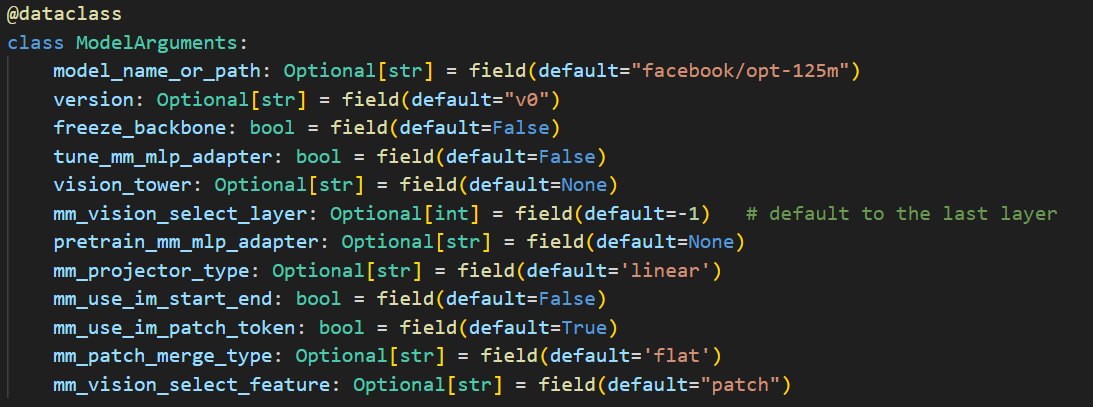
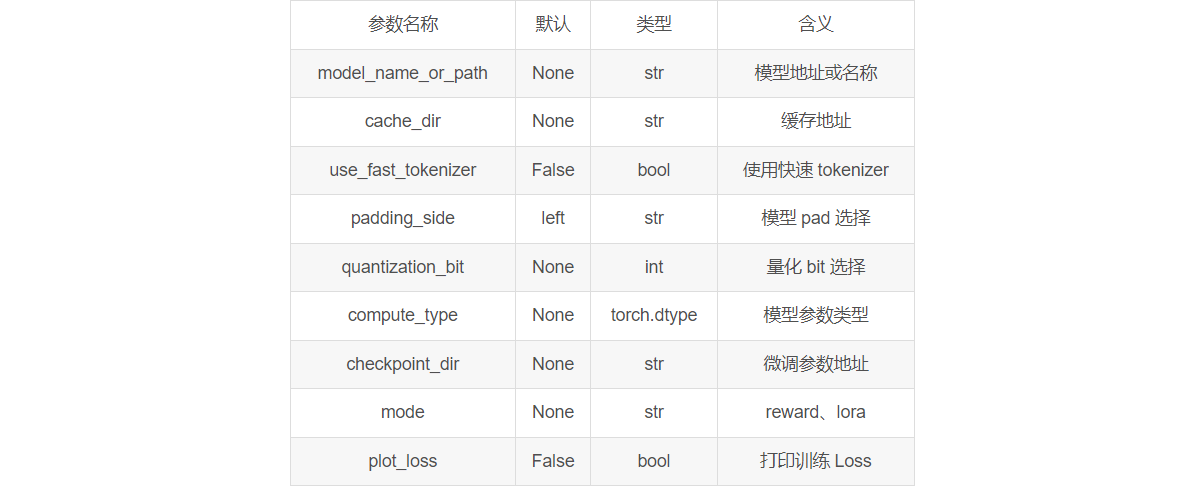
ModelArguments
ModelArguments 通常包含模型路径,以及一些架构上的参数。
DataArguments
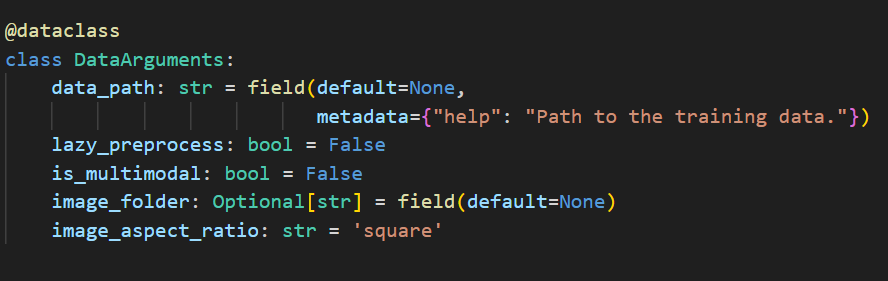
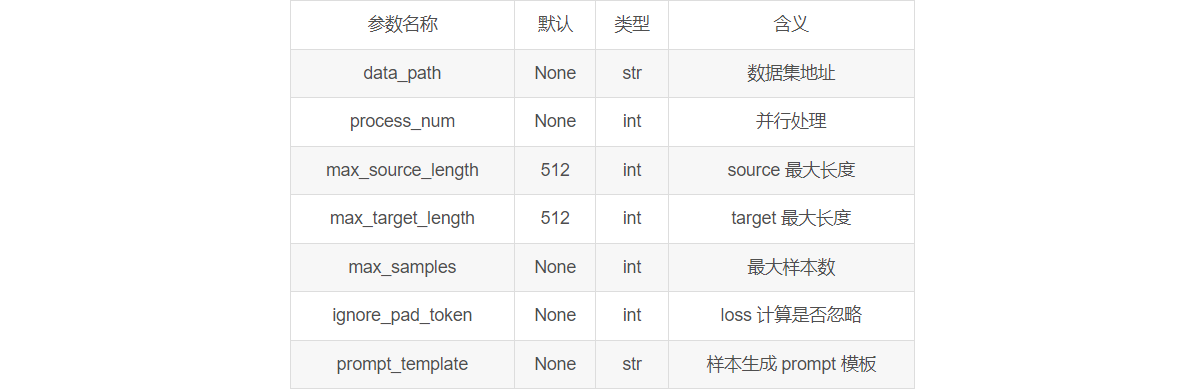
DataArguments 通常包含 数据路径,以及一些预处理参数。
TrainingArguments
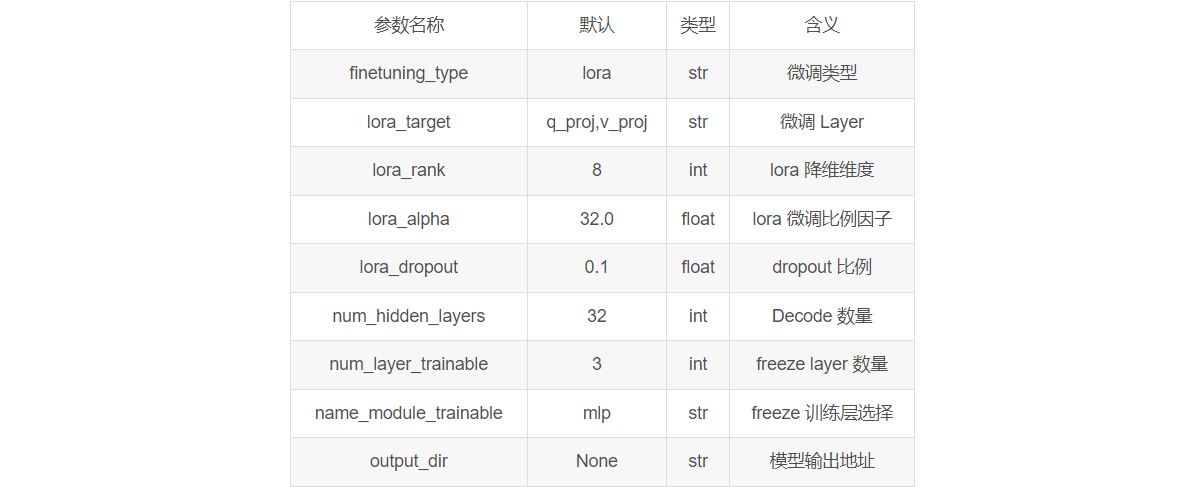
TrainingArguments 通常包含模型训练的一些必要参数,如优化器、学习率等参数。

2. 加载模型
对于我们不仅要加载 LLM 还需要加载 Image Encoder 和 Projector,因此我们可以直接写一个VLM Model(继承transformer库中的LLM)
model = LlavaLlamaForCausalLM.from_pretrained(
model_args.model_name_or_path,
cache_dir=training_args.cache_dir,
attn_implementation=attn_implementation,
torch_dtype=(torch.bfloat16 if training_args.bf16 else None),
**bnb_model_from_pretrained_args
)
LlavaLlamaForCausalLM 继承了LLM(transformer.LlamaForCausalLM)和 VLM抽象类(LlavaMetaForCausalLM),LlavaLlamaForCausalLM中的Visual Modules是 LlavaLlamaModel 用于加载 Image Encoder 和 Projector。其多模态forward的流程就是,先对 image 和 text 计算 embedding,然后将其多模态的 tokens 拼接在一起送入LLM。
class LlavaLlamaForCausalLM(LlamaForCausalLM, LlavaMetaForCausalLM):
config_class = LlavaConfig
def __init__(self, config):
super(LlamaForCausalLM, self).__init__(config)
self.model = LlavaLlamaModel(config)
self.pretraining_tp = config.pretraining_tp
self.vocab_size = config.vocab_size
self.lm_head = nn.Linear(config.hidden_size, config.vocab_size, bias=False)
# Initialize weights and apply final processing
self.post_init()
def get_model(self):
return self.model
def forward(
self,
input_ids: torch.LongTensor = None,
attention_mask: Optional[torch.Tensor] = None,
position_ids: Optional[torch.LongTensor] = None,
past_key_values: Optional[List[torch.FloatTensor]] = None,
inputs_embeds: Optional[torch.FloatTensor] = None,
labels: Optional[torch.LongTensor] = None,
use_cache: Optional[bool] = None,
output_attentions: Optional[bool] = None,
output_hidden_states: Optional[bool] = None,
images: Optional[torch.FloatTensor] = None,
image_sizes: Optional[List[List[int]]] = None,
return_dict: Optional[bool] = None,
) -> Union[Tuple, CausalLMOutputWithPast]:
if inputs_embeds is None:
(
input_ids,
position_ids,
attention_mask,
past_key_values,
inputs_embeds,
labels
) = self.prepare_inputs_labels_for_multimodal(
input_ids,
position_ids,
attention_mask,
past_key_values,
labels,
images,
image_sizes
)
return super().forward(
input_ids=input_ids,
attention_mask=attention_mask,
position_ids=position_ids,
past_key_values=past_key_values,
inputs_embeds=inputs_embeds,
labels=labels,
use_cache=use_cache,
output_attentions=output_attentions,
output_hidden_states=output_hidden_states,
return_dict=return_dict
)
@torch.no_grad()
def generate(
self,
inputs: Optional[torch.Tensor] = None,
images: Optional[torch.Tensor] = None,
image_sizes: Optional[torch.Tensor] = None,
**kwargs,
) -> Union[GenerateOutput, torch.LongTensor]:
position_ids = kwargs.pop("position_ids", None)
attention_mask = kwargs.pop("attention_mask", None)
if "inputs_embeds" in kwargs:
raise NotImplementedError("`inputs_embeds` is not supported")
if images is not None:
(
inputs,
position_ids,
attention_mask,
_,
inputs_embeds,
_
) = self.prepare_inputs_labels_for_multimodal(
inputs,
position_ids,
attention_mask,
None,
None,
images,
image_sizes=image_sizes
)
else:
inputs_embeds = self.get_model().embed_tokens(inputs)
return super().generate(
position_ids=position_ids,
attention_mask=attention_mask,
inputs_embeds=inputs_embeds,
**kwargs
)
def prepare_inputs_for_generation(self, input_ids, past_key_values=None,
inputs_embeds=None, **kwargs):
images = kwargs.pop("images", None)
image_sizes = kwargs.pop("image_sizes", None)
inputs = super().prepare_inputs_for_generation(
input_ids, past_key_values=past_key_values, inputs_embeds=inputs_embeds, **kwargs
)
if images is not None:
inputs['images'] = images
if image_sizes is not None:
inputs['image_sizes'] = image_sizes
return inputs
另外,我们还需要加载Tokenizer,并设置其词表:
tokenizer = transformers.AutoTokenizer.from_pretrained(
model_args.model_name_or_path,
cache_dir=training_args.cache_dir,
model_max_length=training_args.model_max_length,
padding_side="right",
use_fast=False,
)
3. 加载数据
在开始构造Trainer勋训练之前,我们还需要创建dataset和data collator:
def make_supervised_data_module(tokenizer: transformers.PreTrainedTokenizer,
data_args) -> Dict:
"""Make dataset and collator for supervised fine-tuning."""
train_dataset = LazySupervisedDataset(tokenizer=tokenizer,
data_path=data_args.data_path,
data_args=data_args)
data_collator = DataCollatorForSupervisedDataset(tokenizer=tokenizer)
return dict(train_dataset=train_dataset,
eval_dataset=None,
data_collator=data_collator)
4. 创建Trainer开始训练
trainer = LLaVATrainer(model=model,
tokenizer=tokenizer,
args=training_args,
**data_module)
trainer.train()
trainer.save_state()
构造VLM的Trainer,继承Trainer,重写_get_train_sampler、create_optimizer、_save_checkpoint、_save即可。
class LLaVATrainer(Trainer):
def _get_train_sampler(self) -> Optional[torch.utils.data.Sampler]:
if self.train_dataset is None or not has_length(self.train_dataset):
return None
if self.args.group_by_modality_length:
lengths = self.train_dataset.modality_lengths
return LengthGroupedSampler(
self.args.train_batch_size,
world_size=self.args.world_size * self.args.gradient_accumulation_steps,
lengths=lengths,
group_by_modality=True,
)
else:
return super()._get_train_sampler()
def create_optimizer(self):
"""
Setup the optimizer.
We provide a reasonable default that works well. If you want to use something else, you can pass a tuple in the
Trainer's init through `optimizers`, or subclass and override this method in a subclass.
"""
if is_sagemaker_mp_enabled():
return super().create_optimizer()
opt_model = self.model
if self.optimizer is None:
decay_parameters = get_parameter_names(opt_model, ALL_LAYERNORM_LAYERS)
decay_parameters = [name for name in decay_parameters if "bias" not in name]
if self.args.mm_projector_lr is not None:
projector_parameters = [name for name, _ in opt_model.named_parameters() if "mm_projector" in name]
optimizer_grouped_parameters = [
{
"params": [
p for n, p in opt_model.named_parameters() if (n in decay_parameters and n not in projector_parameters and p.requires_grad)
],
"weight_decay": self.args.weight_decay,
},
{
"params": [
p for n, p in opt_model.named_parameters() if (n not in decay_parameters and n not in projector_parameters and p.requires_grad)
],
"weight_decay": 0.0,
},
{
"params": [
p for n, p in opt_model.named_parameters() if (n in decay_parameters and n in projector_parameters and p.requires_grad)
],
"weight_decay": self.args.weight_decay,
"lr": self.args.mm_projector_lr,
},
{
"params": [
p for n, p in opt_model.named_parameters() if (n not in decay_parameters and n in projector_parameters and p.requires_grad)
],
"weight_decay": 0.0,
"lr": self.args.mm_projector_lr,
},
]
else:
optimizer_grouped_parameters = [
{
"params": [
p for n, p in opt_model.named_parameters() if (n in decay_parameters and p.requires_grad)
],
"weight_decay": self.args.weight_decay,
},
{
"params": [
p for n, p in opt_model.named_parameters() if (n not in decay_parameters and p.requires_grad)
],
"weight_decay": 0.0,
},
]
optimizer_cls, optimizer_kwargs = Trainer.get_optimizer_cls_and_kwargs(self.args)
self.optimizer = optimizer_cls(optimizer_grouped_parameters, **optimizer_kwargs)
if optimizer_cls.__name__ == "Adam8bit":
import bitsandbytes
manager = bitsandbytes.optim.GlobalOptimManager.get_instance()
skipped = 0
for module in opt_model.modules():
if isinstance(module, nn.Embedding):
skipped += sum({p.data_ptr(): p.numel() for p in module.parameters()}.values())
logger.info(f"skipped {module}: {skipped/2**20}M params")
manager.register_module_override(module, "weight", {"optim_bits": 32})
logger.debug(f"bitsandbytes: will optimize {module} in fp32")
logger.info(f"skipped: {skipped/2**20}M params")
return self.optimizer
def _save_checkpoint(self, model, trial, metrics=None):
if getattr(self.args, 'tune_mm_mlp_adapter', False):
from transformers.trainer_utils import PREFIX_CHECKPOINT_DIR
checkpoint_folder = f"{PREFIX_CHECKPOINT_DIR}-{self.state.global_step}"
run_dir = self._get_output_dir(trial=trial)
output_dir = os.path.join(run_dir, checkpoint_folder)
# Only save Adapter
keys_to_match = ['mm_projector', 'vision_resampler']
if getattr(self.args, "use_im_start_end", False):
keys_to_match.extend(['embed_tokens', 'embed_in'])
weight_to_save = get_mm_adapter_state_maybe_zero_3(self.model.named_parameters(), keys_to_match)
if self.args.local_rank == 0 or self.args.local_rank == -1:
self.model.config.save_pretrained(output_dir)
torch.save(weight_to_save, os.path.join(output_dir, f'mm_projector.bin'))
else:
super(LLaVATrainer, self)._save_checkpoint(model, trial, metrics)
def _save(self, output_dir: Optional[str] = None, state_dict=None):
if getattr(self.args, 'tune_mm_mlp_adapter', False):
pass
else:
super(LLaVATrainer, self)._save(output_dir, state_dict)