目录
一、引言
二、CUDA显存超出(CUDA out of memory)
2.1 概述
2.2 解决方案
2.3 代码示例
2.4 查看显存
三、总结
一、引言
这里的Transformers指的是huggingface开发的大模型库,为huggingface上数以万计的预训练大模型提供预测、训练等服务。
🤗 Transformers 提供了数以千计的预训练模型,支持 100 多种语言的文本分类、信息抽取、问答、摘要、翻译、文本生成。它的宗旨是让最先进的 NLP 技术人人易用。
🤗 Transformers 提供了便于快速下载和使用的API,让你可以把预训练模型用在给定文本、在你的数据集上微调然后通过 model hub 与社区共享。同时,每个定义的 Python 模块均完全独立,方便修改和快速研究实验。
🤗 Transformers 支持三个最热门的深度学习库: Jax, PyTorch 以及 TensorFlow — 并与之无缝整合。你可以直接使用一个框架训练你的模型然后用另一个加载和推理。
本文重点介绍torch.cuda.OutOfMemoryError: CUDA out of memory的解决方案。
二、CUDA显存超出(CUDA out of memory)
2.1 概述
采用GPU进行大模型训练及推理,在初期遇到最多的错误就是CUDA out of memory,主要意味着你的模型在训练或运行过程中尝试分配的GPU内存超出了可用部分,简称“爆显存”
2.2 解决方案
解决这个问题有几种策略:
- 多卡分配:在AutoModelForCausalLM加载预训练模型时,加入device_map="auto",自动分配可用显存。
- 设置可见显存:在python文件外部加入CUDA_VISIBLE_DEVICES=1,2,指定特定的显卡。
重要!单台机器如果有的显卡占满,有的显卡空着。加入device_map="auto",仍然会出现爆显存的情况。主要因为device_map="auto"会将模型分配到满显存的卡上。
解决:通过CUDA_VISIBLE_DEVICES=1,2指定显存充足的卡,避开显存不足的卡。
- 模型量化:如果显卡资源有限,无法进行多卡分配,需要采用量化方法降低显存占用。
- 模型精度:qwen、baichuan2等模型出厂精度为float32,占用显存32G,需要在AutoModelForCausalLM内加入torch_dtype=torch.float16转换为16位,将显存降低为16G
2.3 代码示例
下面是一段glm-4-9b-chat、Qwen2-7B-Instruct、Baichuan2-7B-Chat通用的大模型推理测试代码:
命令行运行:CUDA_VISIBLE_DEVICES=1,2 python run_infer.py
from modelscope import snapshot_download
from transformers import AutoTokenizer, AutoModelForCausalLM,GenerationConfig
#model_dir = snapshot_download('ZhipuAI/glm-4-9b-chat')
#model_dir = snapshot_download('qwen/Qwen2-7B-Instruct')
model_dir = snapshot_download('baichuan-inc/Baichuan2-7B-Chat')
import torch
device = "auto" # the device to load the model onto
tokenizer = AutoTokenizer.from_pretrained(model_dir,trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained(model_dir,device_map=device,trust_remote_code=True)
#model = AutoModelForCausalLM.from_pretrained(model_dir,device_map=device,trust_remote_code=True,torch_dtype=torch.float16) #设置精度为float16
model.generation_config = GenerationConfig.from_pretrained(model_dir)
print(model)
prompt = "详细介绍一下大语言模型"
messages = [
{"role": "system", "content": "你是一个智能助理."},
{"role": "user", "content": prompt}
]
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True
)
model_inputs = tokenizer([text], return_tensors="pt").to(model.device)
gen_kwargs = {"max_length": 512, "do_sample": True, "top_k": 1}
with torch.no_grad():
outputs = model.generate(**model_inputs, **gen_kwargs)
#print(tokenizer.decode(outputs[0],skip_special_tokens=True))
outputs = outputs[:, model_inputs['input_ids'].shape[1]:] #切除system、user等对话前缀
print(tokenizer.decode(outputs[0], skip_special_tokens=True))
重点的几个地方:
- 在run_infer.py运行时通过CUDA_VISIBLE_DEVICES=1,2指定显卡
- device = "auto"赋值device为自动
- model=AutoModelForCausalLM模型头内设置device_map=device,在卡1、2上自动分配
- model=AutoModelForCausalLM模型头内设置torch_dtype=torch.float16,将模型精度由32降低为16,以适应GPU计算
- model_inputs = tokenizer([text], return_tensors="pt").to(model.device),通过.to()指定分词器的显卡为model.device,这里model.device是一个变量,model实例化后分配的属性
2.4 查看显存
采用命令nvidia-smi查看显存
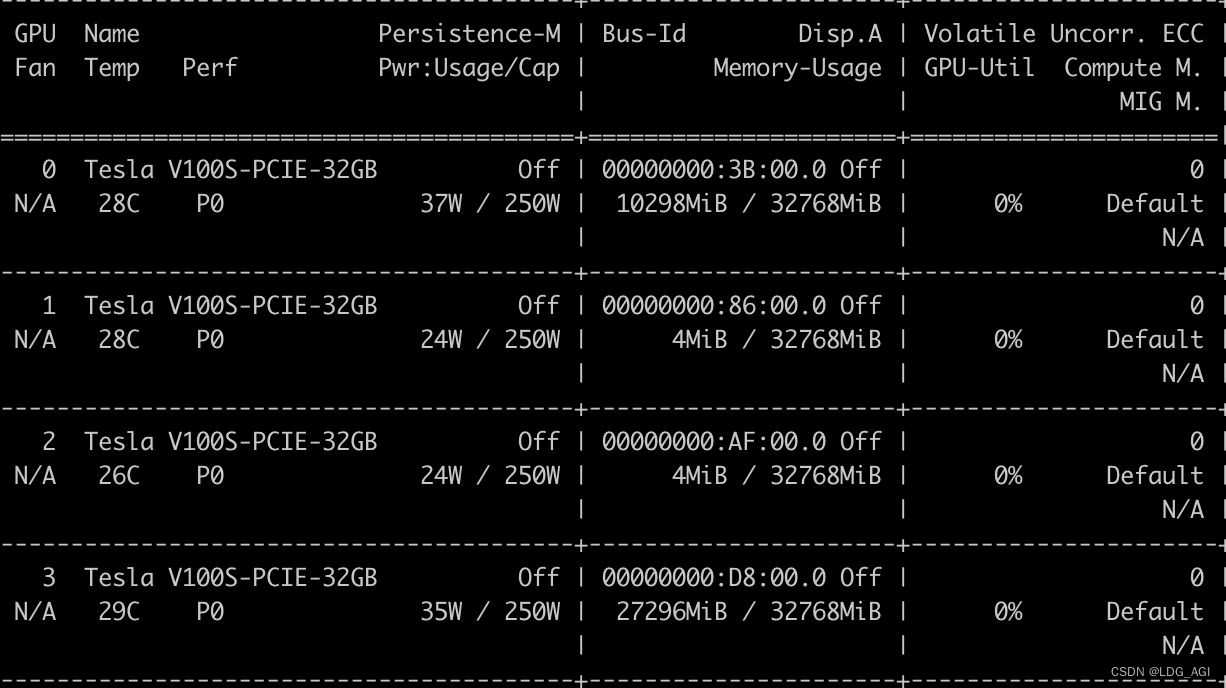
以上代码指定1、2显卡后,卡0、3无变化,卡1、2共计占用31.3G
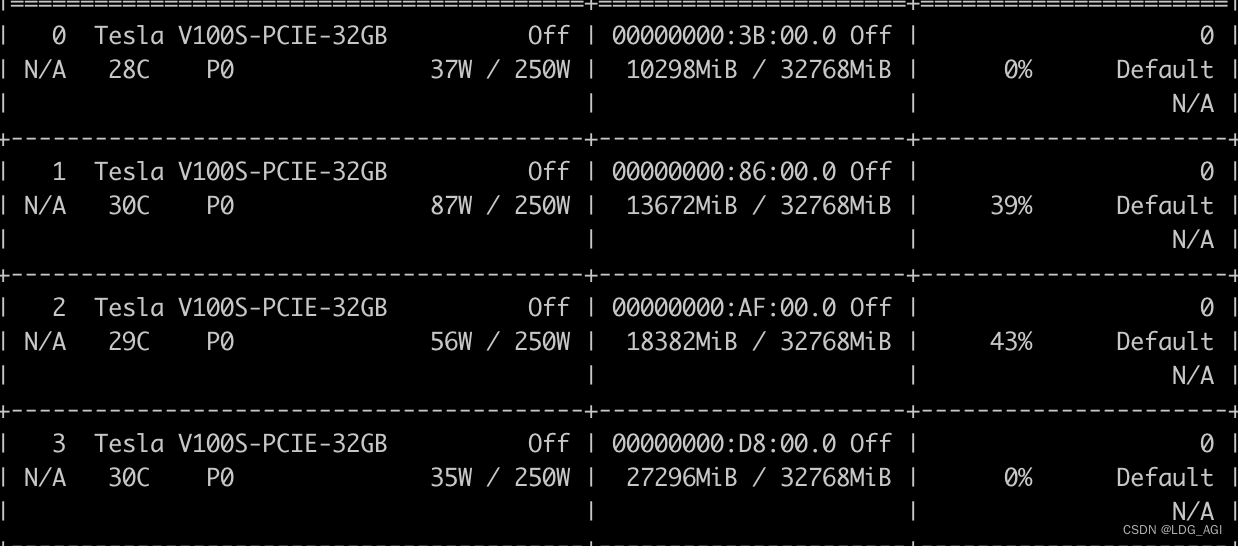
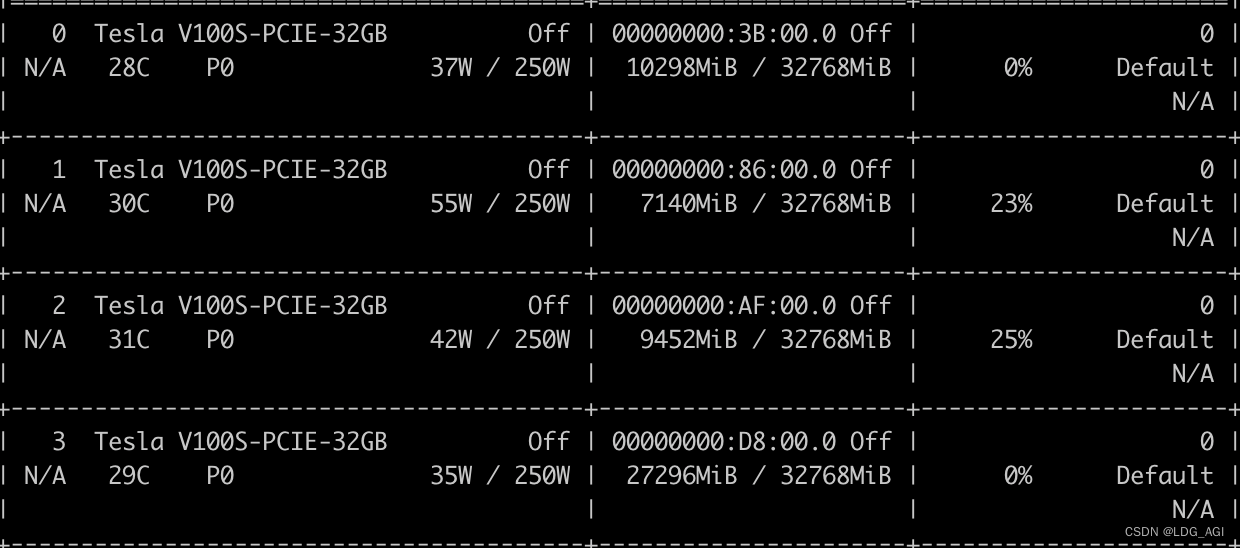
7B的baichuan、qwen等模型出厂默认为float32,占用显存32G,对于V100的单卡,很容易爆显存。需要在AutoModelForCausalLM加入torch_dtype=torch.float16转换为16位,将显存降低为16G
model = AutoModelForCausalLM.from_pretrained(model_dir,device_map=device,trust_remote_code=True,torch_dtype=torch.float16)优化后:
三、总结
本人在调试推理代码过程中,由于未在model=AutoModelForCausalLM模型头内设置torch_dtype=torch.float16,将模型精度由32降低为16,导致总是CUDA out of memory。
- 开始是V100单卡32G尝试运行float32的baichuan2,报CUDA out of memory,
- 于是采用device_map="auto"多卡计算,未指定CUDA_VISIBLE_DEVICES=1,2,导致总去抢占卡0和3的资源报CUDA out of memory
- 最后在AutoModelForCausalLM内设置torch_dtype=torch.float16,将精度降为16位解决
踩这个坑主要是因为不知道不设置torch_dtype=torch.float16的情况下,model精度为32位。兜兜转转绕了一圈,了解了device_map="auto"的概念,又了解到device_map="auto"会去抢占资源,抢失败了也会CUDA out of memory,需要指定CUDA_VISIBLE_DEVICES=1,2。
如果您还有时间,可以看看我的其他文章:
《AI—工程篇》
AI智能体研发之路-工程篇(一):Docker助力AI智能体开发提效
AI智能体研发之路-工程篇(二):Dify智能体开发平台一键部署
AI智能体研发之路-工程篇(三):大模型推理服务框架Ollama一键部署
AI智能体研发之路-工程篇(四):大模型推理服务框架Xinference一键部署
AI智能体研发之路-工程篇(五):大模型推理服务框架LocalAI一键部署
《AI—模型篇》
AI智能体研发之路-模型篇(一):大模型训练框架LLaMA-Factory在国内网络环境下的安装、部署及使用
AI智能体研发之路-模型篇(二):DeepSeek-V2-Chat 训练与推理实战
AI智能体研发之路-模型篇(三):中文大模型开、闭源之争
AI智能体研发之路-模型篇(四):一文入门pytorch开发
AI智能体研发之路-模型篇(五):pytorch vs tensorflow框架DNN网络结构源码级对比
AI智能体研发之路-模型篇(六):【机器学习】基于tensorflow实现你的第一个DNN网络
AI智能体研发之路-模型篇(七):【机器学习】基于YOLOv10实现你的第一个视觉AI大模型
AI智能体研发之路-模型篇(八):【机器学习】Qwen1.5-14B-Chat大模型训练与推理实战
AI智能体研发之路-模型篇(九):【机器学习】GLM4-9B-Chat大模型/GLM-4V-9B多模态大模型概述、原理及推理实战
《AI—Transformers应用》
【AI大模型】Transformers大模型库(一):Tokenizer
【AI大模型】Transformers大模型库(二):AutoModelForCausalLM
【AI大模型】Transformers大模型库(三):特殊标记(special tokens)
【AI大模型】Transformers大模型库(四):AutoTokenizer
【AI大模型】Transformers大模型库(五):AutoModel、Model Head及查看模型结构