面向过程编程 ( Procedure-Oriented Programming , POP ) : 是一种关注于解决问题步骤或过程的编程范式 .
面向过程编程核心思想 : 将复杂问题分解为一系列简单 , 可执行的步骤 ( 即过程或函数 ) ,
并按照特定的顺序依次执行这些步骤 , 直到问题得到解决 .
每个步骤 ( 过程或函数 ) 接受输入数据 , 执行特定操作 , 并产生输出结果 .
过程或函数可以接受参数 , 并可以返回值供其他过程或函数使用 .
面向过程编程主要特点 :
* 1. 顺序执行 : 程序按照预定的步骤顺序执行 .
* 2. 模块化 : 程序被分解为多个独立的函数或过程 , 每个函数或过程执行特定的任务 .
模块化提高了代码的可读性 , 可维护性和重用性 .
* 3. 数据和过程分离 : 数据和过程是分开的 .
* 4. 数据通过参数传递给过程 , 并在过程中被处理 . 过程本身不包含数据 , 只包含处理数据的逻辑 .
* 5. 控制流 : 程序的控制流 ( 即执行顺序 ) 通过流程控制语句 ( 如条件语句 , 循环语句等 ) 来管理 .
这些结构确保程序能够按照我们设计的逻辑来执行 .
总结 : 面向过程编程使用函数来组织代码 , 并通过函数调用和参数传递来实现数据在函数之间的传递 .
它强调问题的分解和步骤的执行顺序 , 而忽略了数据和对象之间的关系 , 只适用于解决那些可以明确划分为一系列步骤的问题 .
然而 , 随着问题复杂性的增加 , 面向过程编程的代码可能变得难以维护和扩展 , 缺乏对数据和行为的封装 , 容易导致代码的重复和耦合 .
在处理更复杂的项目和系统时 , 面向对象编程可能是一个更好的选择 ,
因为它强调将数据和对数据的操作封装在对象中 , 并通过对象之间的交互来实现程序的功能 .
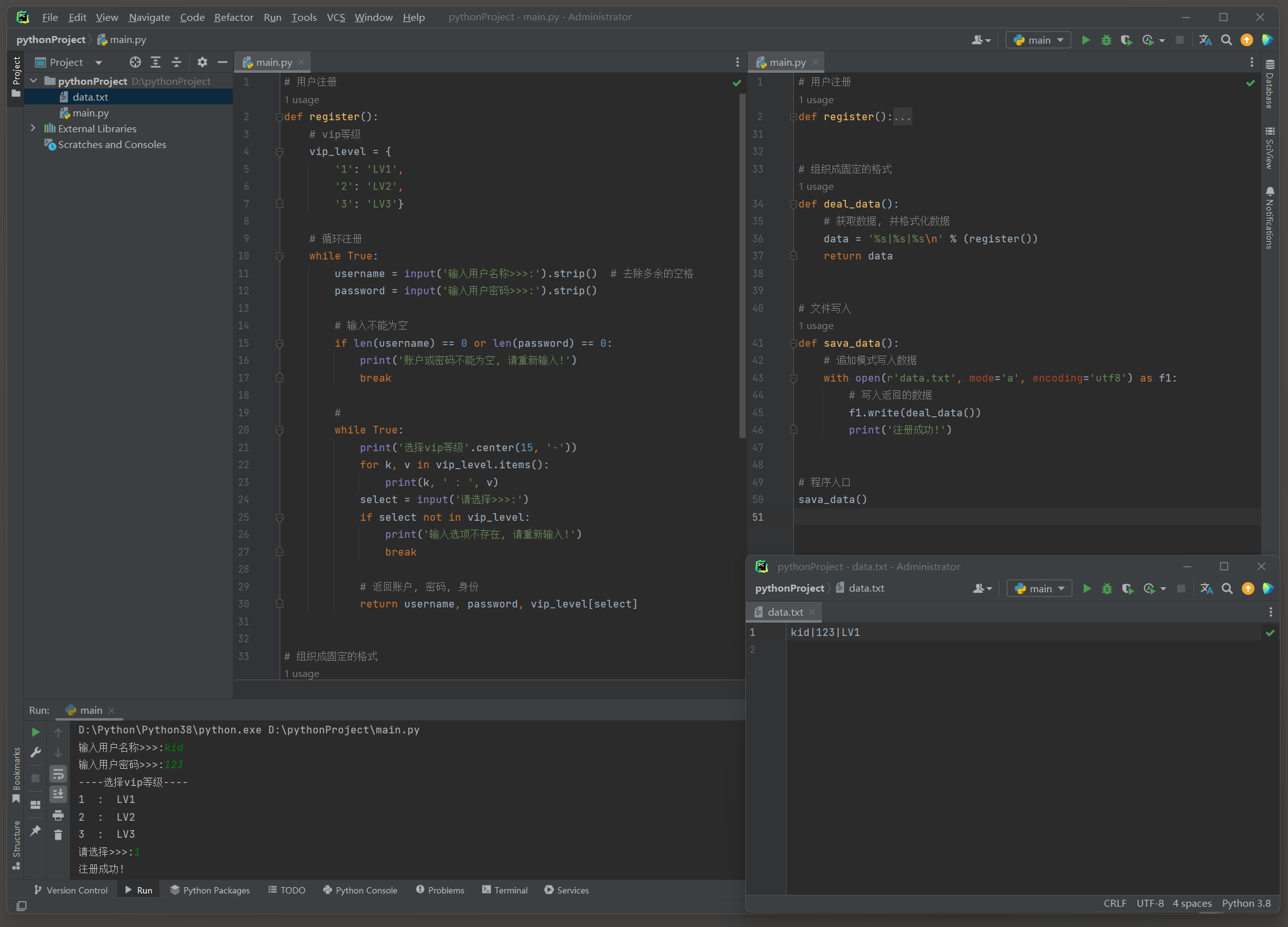
例如 , 需要设计一个注册程序员 , 对这个程序进行分析 , 可分解为以下三步骤 :
* 1. 获取用户名和密码
* 2. 组织成固定的格式
* 3. 文件操作写入文件
def register ( ) :
vip_level = {
'1' : 'LV1' ,
'2' : 'LV2' ,
'3' : 'LV3' }
while True :
username = input ( '输入用户名称>>>:' ) . strip( )
password = input ( '输入用户密码>>>:' ) . strip( )
if len ( username) == 0 or len ( password) == 0 :
print ( '账户或密码不能为空, 请重新输入!' )
break
while True :
print ( '选择vip等级' . center( 15 , '-' ) )
for k, v in vip_level. items( ) :
print ( k, ' : ' , v)
select = input ( '请选择>>>:' )
if select not in vip_level:
print ( '输入选项不存在, 请重新输入!' )
break
return username, password, vip_level[ select]
def deal_data ( ) :
data = '%s|%s|%s\n' % ( register( ) )
return data
def sava_data ( ) :
with open ( r'data.txt' , mode= 'a' , encoding= 'utf8' ) as f1:
f1. write( deal_data( ) )
print ( '注册成功!' )
sava_data( )
面向对象 ( Object-Oriented , 简称OO ) : 是一种软件开发方法 , 它将现实世界的事物抽象为 '对象' , 通过类和对象等概念来设计软件结构 .
面向对象的方法使软件开发更加符合人类的思维方式 , 提高了软件的可重用性 , 可维护性和可扩展性 .
面向对象编程 ( Object-Oriented Programming , 简称OOP ) : 是面向对象方法的具体实现 .
在面向对象编程中 , 开发者定义类 ( Class ) 作为对象的模板 , 类描述了对象的状态 ( 属性或数据成员 ) 和行为 ( 方法或函数成员 ) .
对象则是根据类创建的实例 , 它拥有类的所有属性和方法 .
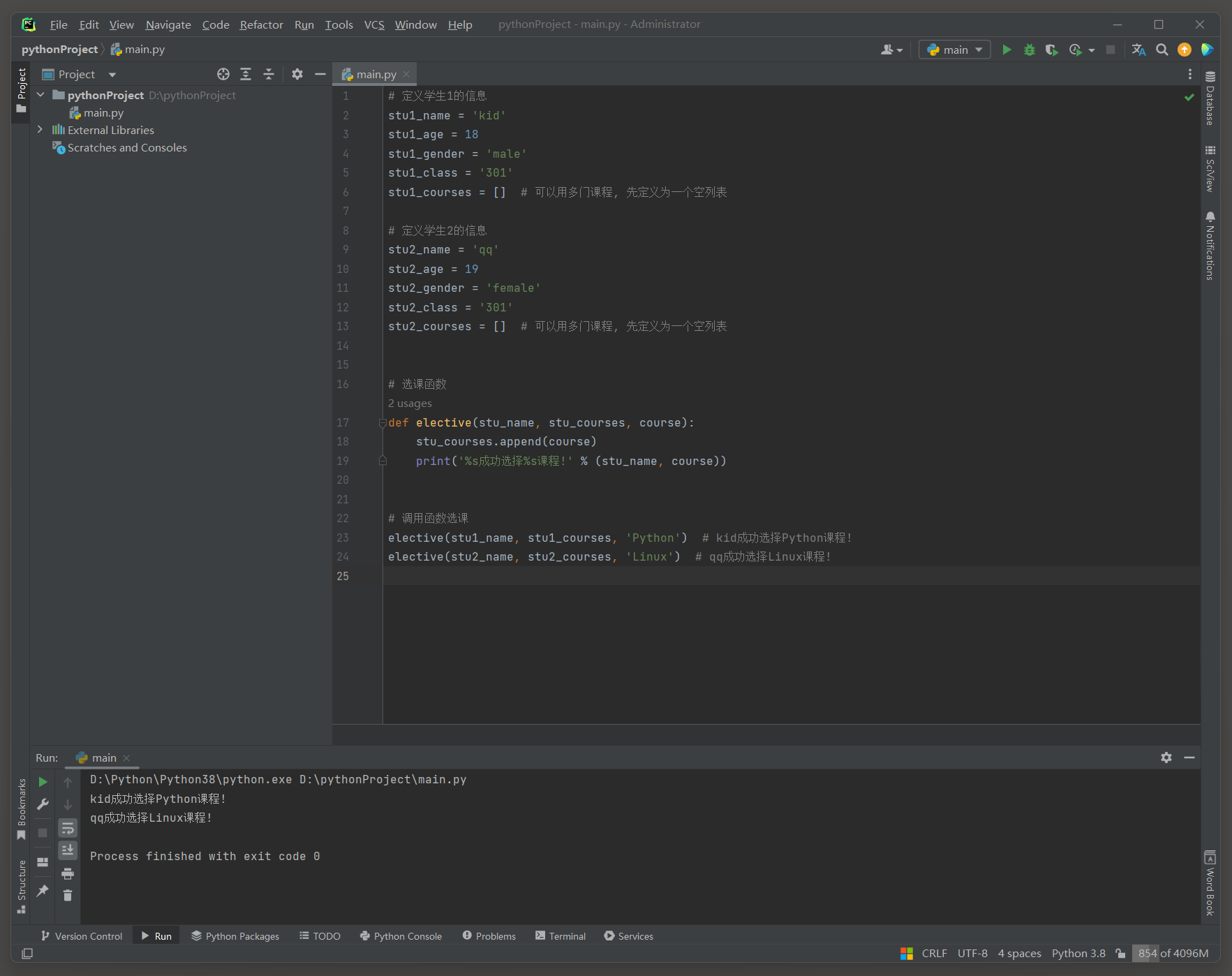
学生选课系统 Version 1.0 ( 数据与功能是分离的 )
1. 定义一个课程列表存放课程 ( Python , Linux ) .
2. 定义两个学生信息 ( 名称 , 年龄 , 性别 , 班级 , 课程 ) .
3. 在定义一个选课函数 , 需要打印选课信息 .
现在我们写的程序是由数据和功能组成 : 先定义一系列的数据 , 然后再定义一系列的功能 ( 函数 ) 来对数据进行操作 .
stu1_name = 'kid'
stu1_age = 18
stu1_gender = 'male'
stu1_class = '301'
stu1_courses = [ ]
stu2_name = 'qq'
stu2_age = 19
stu2_gender = 'female'
stu2_class = '301'
stu2_courses = [ ]
def elective ( stu_name, stu_courses, course) :
stu_courses. append( course)
print ( '%s成功选择%s课程!' % ( stu_name, course) )
elective( stu1_name, stu1_courses, 'Python' )
elective( stu2_name, stu2_courses, 'Linux' )
这个例子 , 用于展示如何在Python中处理学生信息和选课功能 .
然而 , 随着数据量的增加 , 硬编码的方式 ( 如直接定义变量stu1_name , stu2_name等 ) 存储用户的信息 , 往后会变得难以维护 .
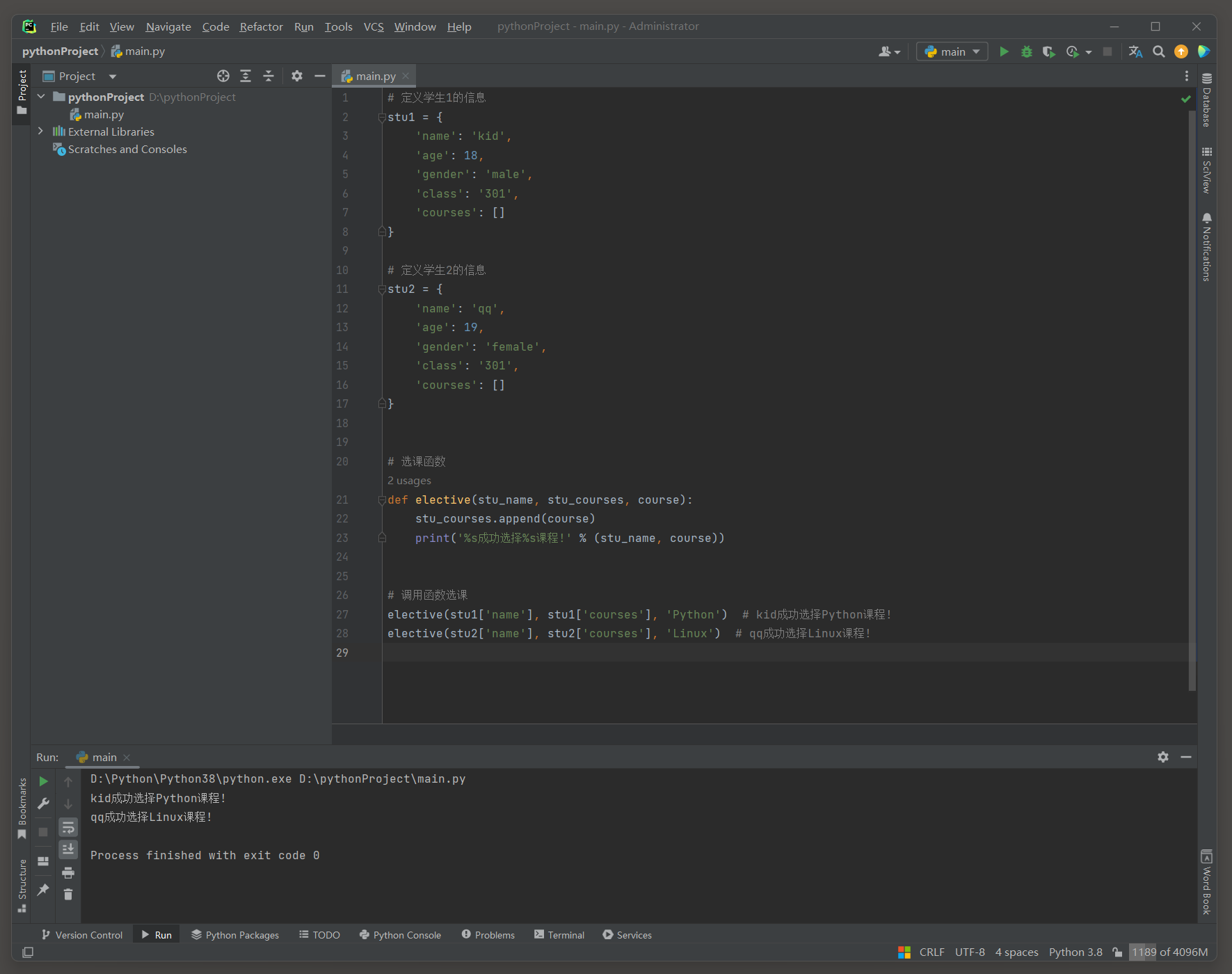
学生选课系统 Version 2 : ( 将学生信息存储在结构化的容器中 )
之前的数据存储存在的散乱的问题 .
改为使用字典存储学生信息 , 这样可以确保每个学生的信息都被组织在一个清晰 , 结构化的容器中 , 方便区分学生的信息 .
也可以直接通过学生的唯一标识符来快速定位并访问他们的信息 , 大大提高了信息检索的效率和准确性 .
例如 , 要查找学生kid的信息 , 可以直接通过stu1 [ 'key' ] 获取 , 无需在散乱的数据中搜索 .
stu1 = {
'name' : 'kid' ,
'age' : 18 ,
'gender' : 'male' ,
'class' : '301' ,
'courses' : [ ]
}
stu2 = {
'name' : 'qq' ,
'age' : 19 ,
'gender' : 'female' ,
'class' : '301' ,
'courses' : [ ]
}
def elective ( stu_name, stu_courses, course) :
stu_courses. append( course)
print ( '%s成功选择%s课程!' % ( stu_name, course) )
elective( stu1[ 'name' ] , stu1[ 'courses' ] , 'Python' )
elective( stu2[ 'name' ] , stu2[ 'courses' ] , 'Linux' )
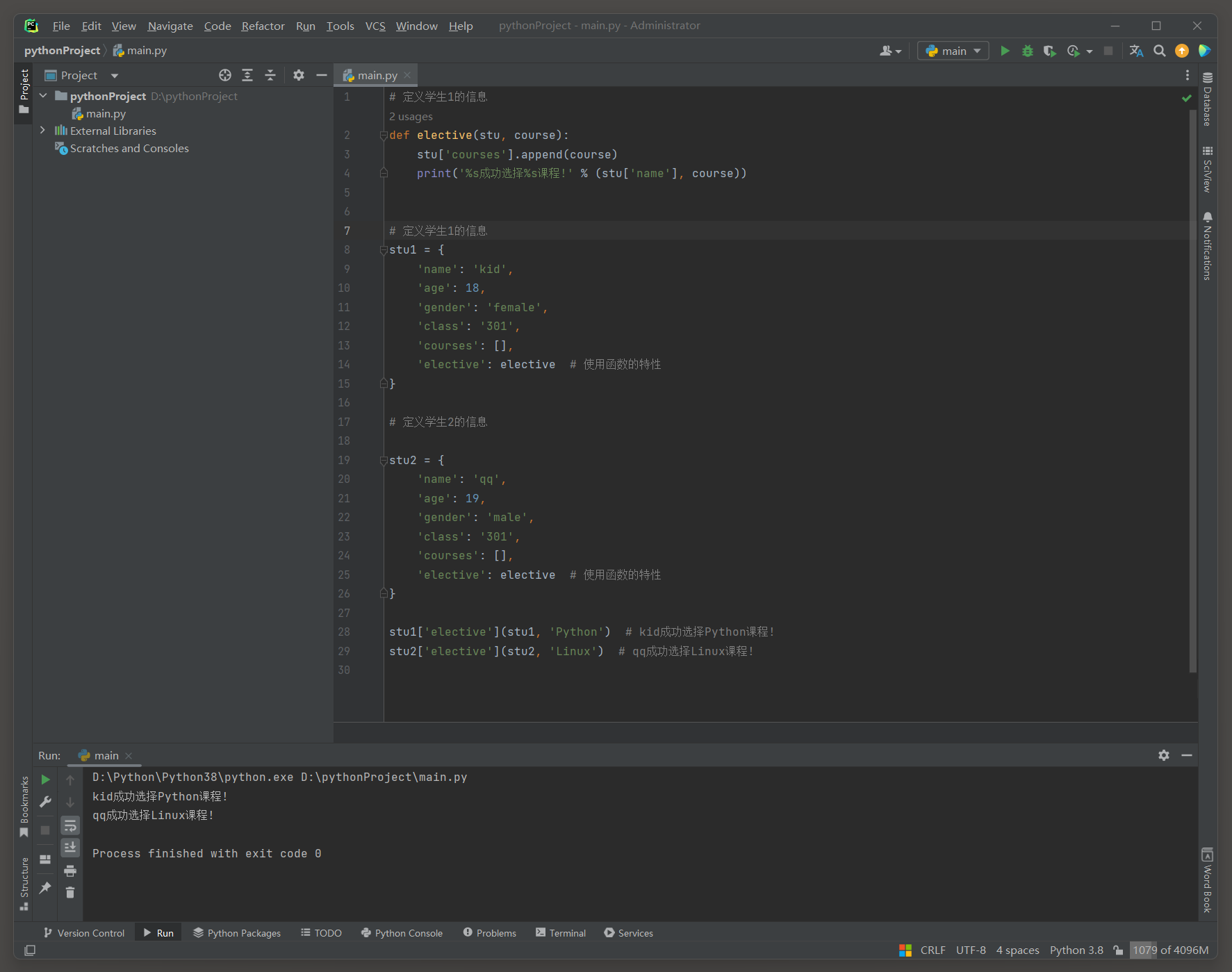
学生选课系统 Version 3 : ( 将选课功能与学生对象紧密绑定 )
将原本可以分离的数据与功能放在一起 , 字典中同时具有学生数据和选课功能 -- > 对象的雏形 .
在Python中 , 函数是一等公民 ( first-class citizens ) , 可以像其他对象一样被赋值给变量 , 作为参数传递 , 甚至作为容器类型的元素 .
def elective ( stu, course) :
stu[ 'courses' ] . append( course)
print ( '%s成功选择%s课程!' % ( stu[ 'name' ] , course) )
stu1 = {
'name' : 'kid' ,
'age' : 18 ,
'gender' : 'female' ,
'class' : '301' ,
'courses' : [ ] ,
'elective' : elective
}
stu2 = {
'name' : 'qq' ,
'age' : 19 ,
'gender' : 'male' ,
'class' : '301' ,
'courses' : [ ] ,
'elective' : elective
}
stu1[ 'elective' ] ( stu1, 'Python' )
stu2[ 'elective' ] ( stu2, 'Linux' )
可以看到每个学生信息字典中都包含一些重复且不变的数据结构 ,
比如 : 'age' : 18 , 'gender' : 'male' , 如果多个学生具有相同的年龄和性别 , 这些数据就会在每个学生的字典中重复 .
学生选课系统 Version 4 ( 减少数据冗余 )
为了减少数据的重复 , 将共同的数据提取出来存放在一个字典容器中 .
可以通过创建一个包含默认学生信息的字典 , 并在创建每个学生信息时从这个默认字典中复制数据 .
def elective ( stu, course) :
stu[ 'courses' ] . append( course)
print ( '%s成功选择%s课程!' % ( stu[ 'name' ] , course) )
student_info = {
'class' : '301' ,
'elective' : elective
}
stu1 = {
'name' : 'kid' ,
'age' : 18 ,
'gender' : 'male' ,
'courses' : [ ] ,
}
stu2 = {
'name' : 'qq' ,
'age' : 19 ,
'gender' : 'male' ,
'courses' : [ ] ,
}
student_info[ 'elective' ] ( stu1, 'Python' )
student_info[ 'elective' ] ( stu2, 'Linux' )
如果我们要创建多个学生对象 , 每个对象都需要一个独立的字典 , 还会导致代码冗余和难以管理 .
况且字典主要用于简单的数据存储和检索 , 而不是用于定义具有复杂行为的对象 .
Python语言提供了类来更好将数据和功能存放 , 而且代码更加清晰 , 易于管理和扩展 .
从上述可知 , 类的基本作用是解决代码冗余 ,
类 ( Class ) 是面向对象编程中的一个核心概念 .
类是一个抽象的概念 , 它描述了一组具有共同属性和方法的对象的蓝图 .
通过定义一个类 , 可以指定该类实例 ( 即对象 ) 应有的行为 ( 方法 = = 函数 ) 和状态 ( 属性 = = 变量 ) .
在Python中 , 可以通过class关键字来定义类 .
class ClassName :
"""类的文档字符串."""
class_name = 301
def func ( ) :
. . .
学生选课系统 Version 4 ( 解决相同数据冗余问题 )
多个学生注册 , 字典中会产生一些重复且不变的数据 ( 数据-- > class班级 , 功能-- > elective选课 ) .
将学生对象中重复的数据提取出来 , 存放在一个共用的容器中 , 这个容器可以是类 .
类可以存放相同的特征和技能 , 将对象的属性和行为包装在一起 , 作为一个独立的单元 , 这个过程称为 '封装' .
在类中定义的变量称为属性 , 在类中定义的函数称为方法 .
class Student :
class_name = '301'
def elective ( stu, course) :
stu[ 'courses' ] . append( course)
print ( '%s成功选择%s课程!' % ( stu[ 'name' ] , course) )
定义类时发生的事情 :
* 1. 立刻执行类体代码 : 定义一个类时 , Python会立即执行类体中的代码 .
这包括任何在类体中的赋值语句 , 函数定义 ( 这些函数在类内成为方法 ) 等 .
会遇到几种不同类型的代码 :
赋值语句 : 这些会立即执行 , 为类变量 ( 也称为静态变量或类属性 ) 分配值 .
函数定义 : 在类体中定义的函数会成为类的方法 .
注意 , 这些函数定义本身只是定义了方法的结构 ( 即它们的名称 , 参数和函数体 ) , 它们并不会被 '执行' 或调用 .
当你定义方法时 , Python会为它们创建函数对象 , 并将这些对象存储在类的命名空间中 .
* 2. 产生一个类的名称空间 , 把类体内产生的名称都归档进名称空间 ( 字典 ) :
当Python定义一个新类时 , 它会为这个类创建一个命名空间 .
这个命名空间是一个字典 , 用于存储类级别的属性 ( 也称为类变量或静态变量 ) 和方法 .
类体中的任何变量或函数定义都会成为这个命名空间的一部分 .
* 3. 把类的名称绑定给 . dict ( 类名 . __dict__可以进行查看 ) :
当定义一个类时 , Python会将类的名称绑定到一个类型对象上 .
这个类型对象有一个__dict__ 属性 , 它是一个字典 , 包含了类的所有属性和方法 .
通过类名 . __dict__来查看这个字典 , 从而了解类定义了哪些属性和方法 .
请注意 , __dict__ 属性主要用于内部实现和调试目的 .
在大多数情况下 , 不需要直接访问它 .
在Python中 , 对象的 . ( 点 ) 操作符通常用于访问对象的属性和方法 .
这是面向对象编程中的一个核心概念 , 允许我们以直观和清晰的方式与对象进行交互 .
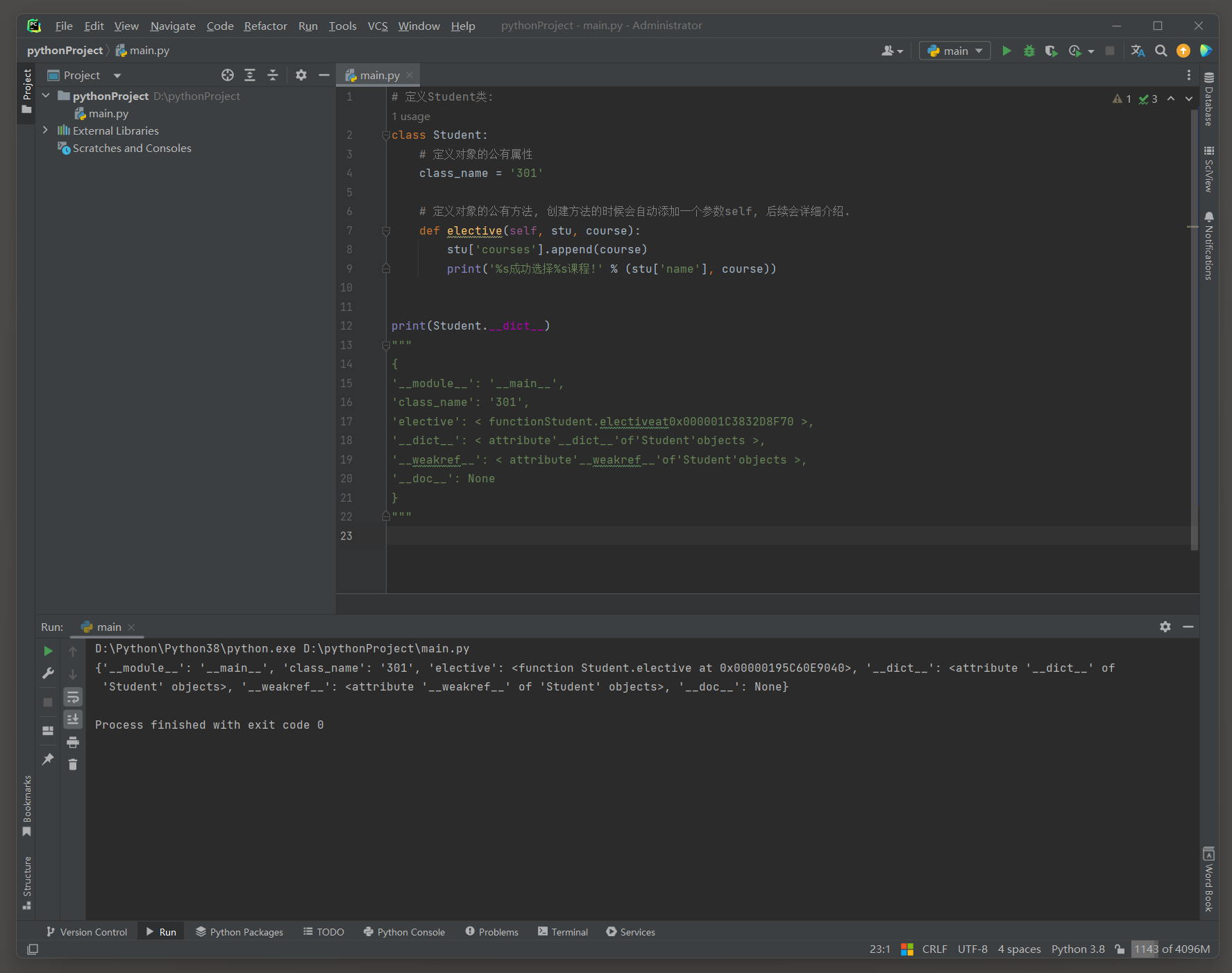
class Student :
class_name = '301'
def elective ( self, stu, course) :
stu[ 'courses' ] . append( course)
print ( '%s成功选择%s课程!' % ( stu[ 'name' ] , course) )
print ( Student. __dict__)
"""
{
'__module__': '__main__',
'class_name': '301',
'elective': < functionStudent.electiveat0x000001C3832D8F70 >,
'__dict__': < attribute'__dict__'of'Student'objects >,
'__weakref__': < attribute'__weakref__'of'Student'objects >,
'__doc__': None
}
"""
查看一个类的__dict__属性时 , 会得到一个字典 , 该字典包含了类的所有公共属性和方法 .
下面是对这些条目的解释 :
__module__ : 这是一个内置属性 , 表示类定义所在的模块名称 .
目前情况下 , 它是 '__main__' , 这通常意味着类是在主程序 ( 即直接运行的脚本 ) 中定义的 , 而不是在导入的模块中 .
class_name : 自己定义的类变量 , 值为 '301' .
elective : 定义的方法 , 值 < function Student . elective at 0x000001C3832D8F70 > 是该方法在内存中的地址 .
__dict__ : 这是一个内置属性描述符 , 用于在类的实例上实现__dict__属性的行为 .
但请注意 , 在类的 __dict__ 中 , __dict__本身并不是一个字典 , 而是一个描述符对象 .
当尝试访问一个实例的__dict__属性时 , Python会使用这个描述符来返回实例的属性字典 .
__weakref__ : 是一个内置属性描述符 , 用于支持对象的弱引用 . 这意味着对象可以被引用 , 但不会增加其引用计数 .
因此 , 即使存在循环引用 , 只要对象的强引用计数变为零 , 垃圾回收器仍然可以回收其内存 .
( 主要是资源回收 , 避免循环引用导致的内存泄漏 . )
__doc__ : 这是一个内置属性 , 用于存储类的文档字符串 ( docstring ) .
文档字符串是类 , 方法 , 模块或函数定义后的第一个未赋值的字符串 .
目前的情况下 , __doc__的值是None , 这意味着没有为Student类定义文档字符串 .
这个字典包含了类的元信息 ( 如 : __module__ 和 __doc__ ) , 自定义的类变量 ( 如 : class_name ) 和方法 ( 如 : elective ) ,
以及用于实现特定功能的内置描述符 ( 如 : __dict__和__weakref__ ) .
在Python中 , 类名加括号用于实例化一个类 , 会返回一个新的对象 , 这个对象是该类的一个实例 .
实例 ( instance ) 是类的具体实现 , 或者说是类的一个具体化的存在 .
( 类可以被看作是一个模板或蓝图 , 它定义了对象应有的属性和方法 .
而实例则是根据这个模板创建出来的具体对象 , 它包含了类中定义的属性和方法的具体值或实现 . )
实例化 : 使用类作为模板创建对象的过程 .
实例化对象 : 根据类创建的具体实例 , 具有类定义的属性和方法 , 并存储在内存中 .
实例化是一个动词 , 描述的是创建对象的过程 .
实例化对象是一个名词 , 指的是创建出来的具体对象 .
但在很多非正式或简化的语境中 , 这两个术语可能会被混用 .
class Student :
class_name = '301'
def elective ( self, stu, course) :
stu[ 'courses' ] . append( course)
print ( '%s成功选择%s课程!' % ( stu[ 'name' ] , course) )
stu1 = {
'name' : 'kid' ,
'age' : 18 ,
'gender' : 'male' ,
'courses' : [ ] ,
}
stu2 = {
'name' : 'qq' ,
'age' : 19 ,
'gender' : 'female' ,
'courses' : [ ] ,
}
stu_obj1 = Student( )
stu_obj2 = Student( )
stu_obj1. elective( stu1, 'Python' )
stu_obj2. elective( stu2, 'Linux' )
现在数据又分离 , 我们需要把数据放到对象中去 .
在Python中 , 每个实例化对象都有一个内建的__dict__属性 , 它是一个字典 , 用于存储该对象的实例属性 ( 也称为成员变量 ) .
通过这个属性 , 我们可以查看或修改对象的状态 , 即它的实例属性 .
( 请注意 , 不是所有的对象都有__dict__ 属性 , 一些内置类型或使用了__slots__属性的类可能不使用__dict__来存储实例属性 . )
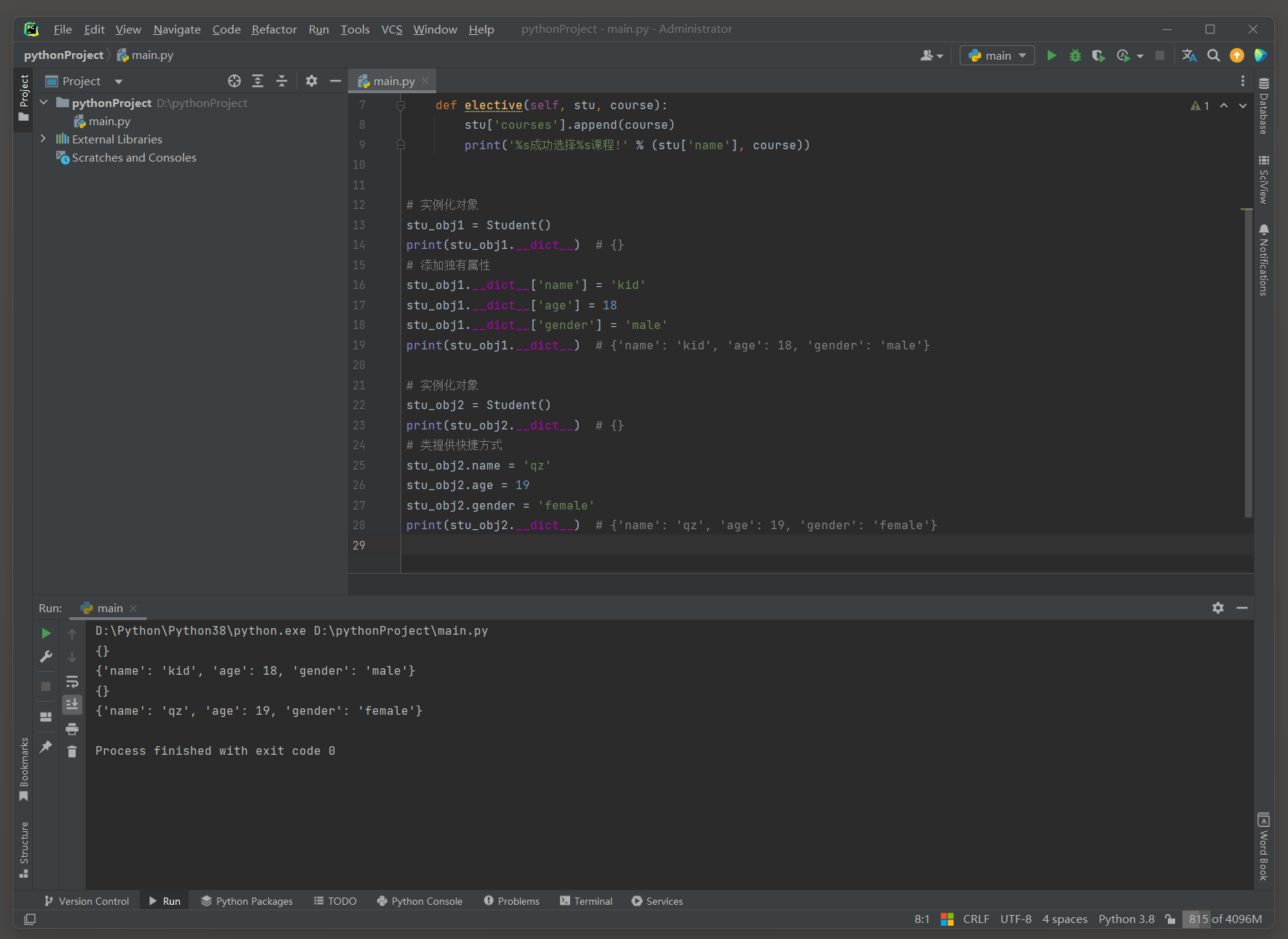
class Student :
class_name = '301'
def elective ( self, stu, course) :
stu[ 'courses' ] . append( course)
print ( '%s成功选择%s课程!' % ( stu[ 'name' ] , course) )
stu1 = {
'name' : 'kid' ,
'age' : 18 ,
'gender' : 'male' ,
'courses' : [ ] ,
}
stu_obj1 = Student( )
print ( stu_obj1. __dict__)
在Python中 , 实例的独有属性可以通过点操作符 ( . ) 来读取 , 设置 , 新增和删除 .
( 可以直接操作__dict__来添加或修改属性 , 但不推荐 . )
Python中 , 实例对象 ( 或称为对象实例 ) 的独有数据 ( 即实例属性 ) 可以通过两种方式访问和修改 :
* 1. 使用点符号 ( . ) 直接访问或修改对象的属性 , 例如 : 对象 . attribute .
* 2. 使用__dict__字典来访问或修改对象的属性 , 例如 : 对象 . __dict__ [ key ] .
但它们在使用方式和背后的机制上有所不同 .
* 1. 对象 . __dict__ [ key ] = value : 直接操作对象的__dict__属性 , 这是一个存储对象属性的字典 .
通过这种方式 , 可以直接设置或修改对象的任何属性 , 无论该属性是否已经在类的定义中声明 .
这种方法绕过了Python的属性访问机制 , 直接对底层数据结构进行操作 .
如果对象没有__slots__属性 , 那么可以通过这种方式添加或修改任意属性 .
* 2. 对象 . attribute = value : 通过标准的点符号 ( . ) 操作符来设置对象的属性 .
例如 , obj . name = 'kid' , Python会首先检查对象的__dict__中是否有name这个键 .
如果有 , 就更新它的值 ; 如果没有 , 就在__dict__中添加这个键和对应的值 .
如果name属性是通过类定义中的方法 ( 如 @ property装饰器 ) 或描述符
( 如实现了__get__ , __set__ , 和__del__方法的对象 ) 来控制的 ,
那么设置这个属性时会调用相应的方法或描述符的__set__方法 .
这种方式更符合Python的面向对象编程惯例 , 并且更易于理解和维护 .
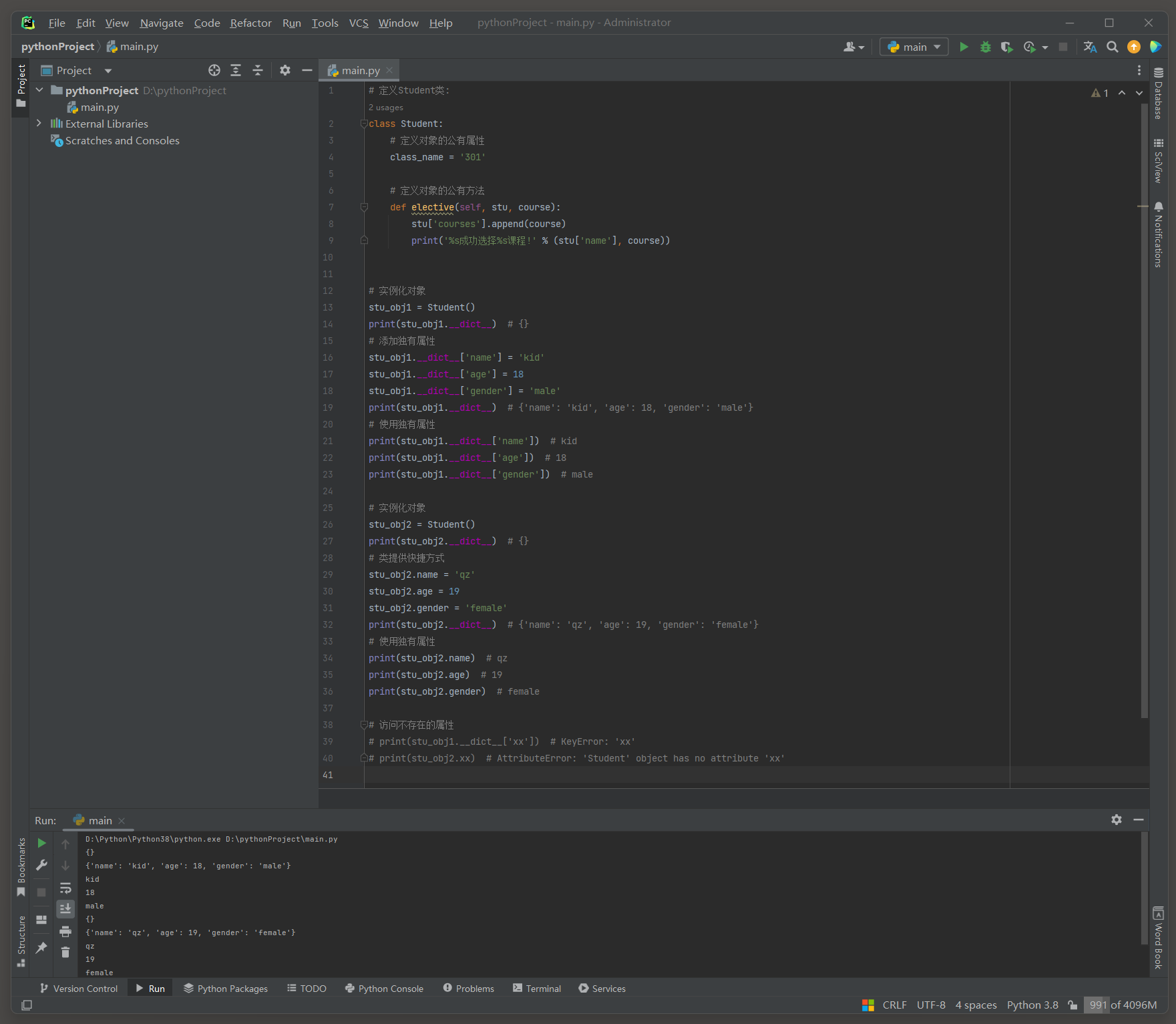
class Student :
class_name = '301'
def elective ( self, stu, course) :
stu[ 'courses' ] . append( course)
print ( '%s成功选择%s课程!' % ( stu[ 'name' ] , course) )
stu_obj1 = Student( )
print ( stu_obj1. __dict__)
stu_obj1. __dict__[ 'name' ] = 'kid'
stu_obj1. __dict__[ 'age' ] = 18
stu_obj1. __dict__[ 'gender' ] = 'male'
print ( stu_obj1. __dict__)
stu_obj2 = Student( )
print ( stu_obj2. __dict__)
stu_obj2. name = 'qz'
stu_obj2. age = 19
stu_obj2. gender = 'female'
print ( stu_obj2. __dict__)
class Student :
class_name = '301'
def elective ( self, stu, course) :
stu[ 'courses' ] . append( course)
print ( '%s成功选择%s课程!' % ( stu[ 'name' ] , course) )
stu_obj1 = Student( )
print ( stu_obj1. __dict__)
stu_obj1. __dict__[ 'name' ] = 'kid'
stu_obj1. __dict__[ 'age' ] = 18
stu_obj1. __dict__[ 'gender' ] = 'male'
print ( stu_obj1. __dict__)
print ( stu_obj1. __dict__[ 'name' ] )
print ( stu_obj1. __dict__[ 'age' ] )
print ( stu_obj1. __dict__[ 'gender' ] )
stu_obj2 = Student( )
print ( stu_obj2. __dict__)
stu_obj2. name = 'qz'
stu_obj2. age = 19
stu_obj2. gender = 'female'
print ( stu_obj2. __dict__)
print ( stu_obj2. name)
print ( stu_obj2. age)
print ( stu_obj2. gender)
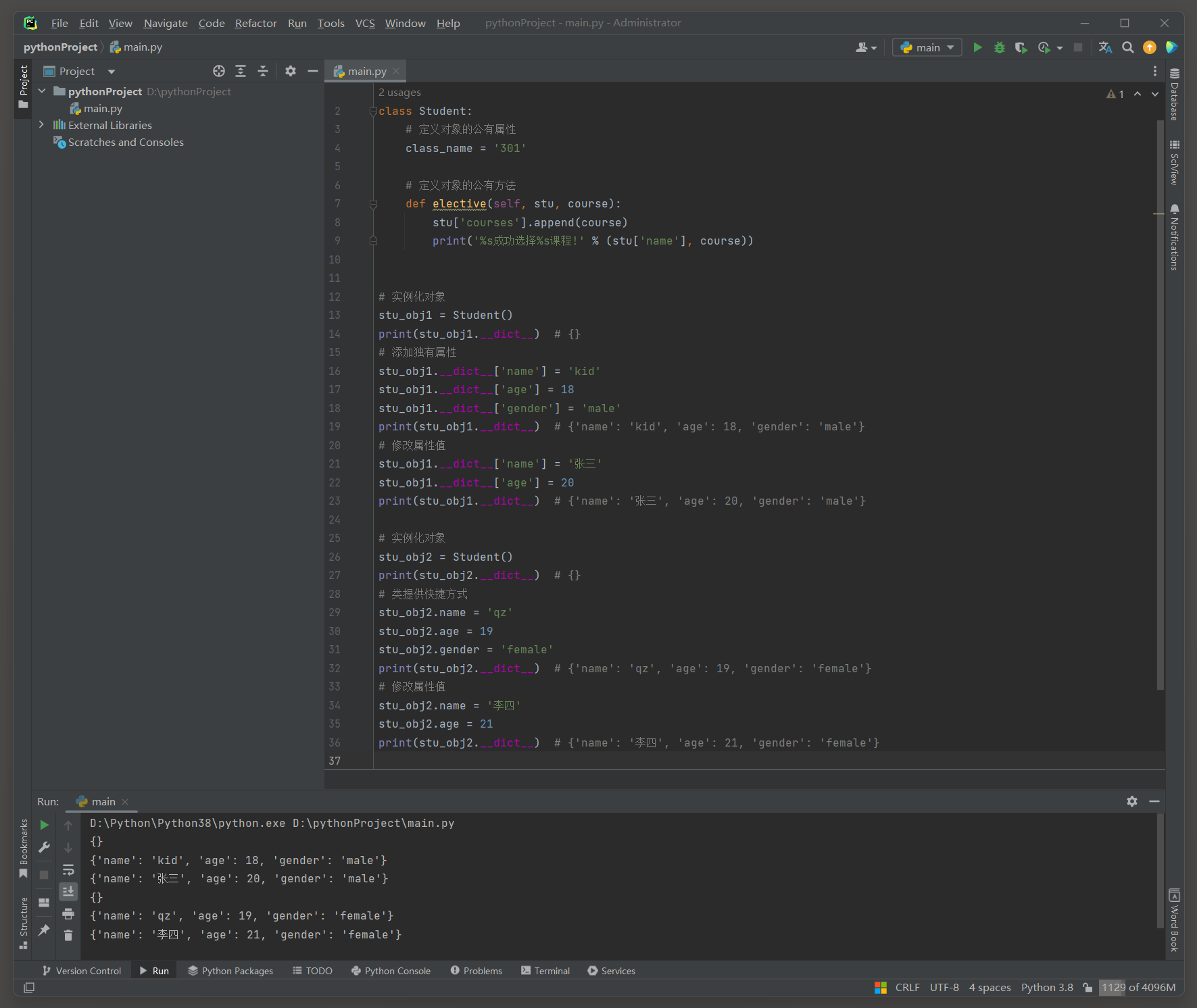
class Student :
class_name = '301'
def elective ( self, stu, course) :
stu[ 'courses' ] . append( course)
print ( '%s成功选择%s课程!' % ( stu[ 'name' ] , course) )
stu_obj1 = Student( )
print ( stu_obj1. __dict__)
stu_obj1. __dict__[ 'name' ] = 'kid'
stu_obj1. __dict__[ 'age' ] = 18
stu_obj1. __dict__[ 'gender' ] = 'male'
print ( stu_obj1. __dict__)
stu_obj1. __dict__[ 'name' ] = '张三'
stu_obj1. __dict__[ 'age' ] = 20
print ( stu_obj1. __dict__)
stu_obj2 = Student( )
print ( stu_obj2. __dict__)
stu_obj2. name = 'qz'
stu_obj2. age = 19
stu_obj2. gender = 'female'
print ( stu_obj2. __dict__)
stu_obj2. name = '李四'
stu_obj2. age = 21
print ( stu_obj2. __dict__)
class Student :
class_name = '301'
def elective ( self, stu, course) :
stu[ 'courses' ] . append( course)
print ( '%s成功选择%s课程!' % ( stu[ 'name' ] , course) )
stu_obj1 = Student( )
print ( stu_obj1. __dict__)
stu_obj1. __dict__[ 'name' ] = 'kid'
stu_obj1. __dict__[ 'age' ] = 18
stu_obj1. __dict__[ 'gender' ] = 'male'
print ( stu_obj1. __dict__)
del stu_obj1. __dict__[ 'name' ]
del stu_obj1. __dict__[ 'age' ]
print ( stu_obj1. __dict__)
stu_obj2 = Student( )
print ( stu_obj2. __dict__)
stu_obj2. name = 'qz'
stu_obj2. age = 19
stu_obj2. gender = 'female'
print ( stu_obj2. __dict__)
del stu_obj2. name
del stu_obj2. age
print ( stu_obj2. __dict__)
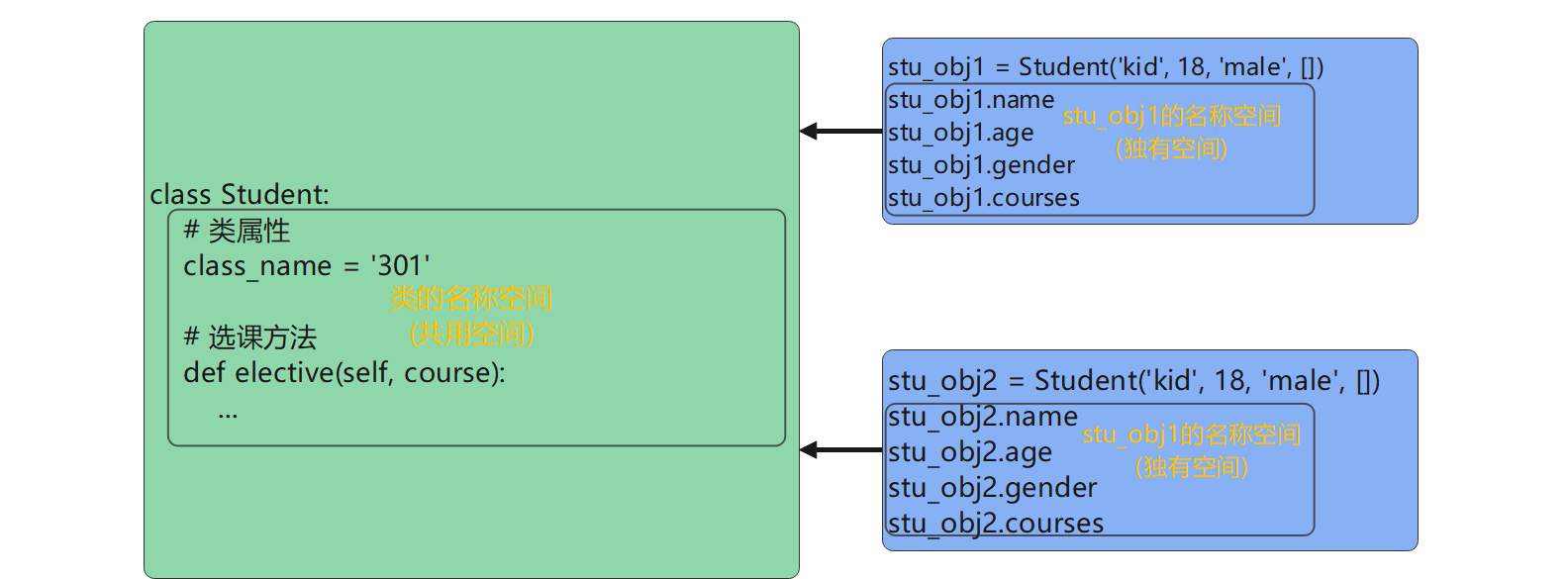
类属性在所有实例间共享 : 类属性是属于类的 , 而不是属于某个特定实例的 .
因此 , 所有通过该类创建的实例都会共享相同的类属性 .
当你修改一个类属性的值时 , 这个改变会反映到类的所有实例上 .
注意 : 类属性通常被设计为只读或几乎不会修改 .
访问类属性的方式 :
通过类名访问类属性 : 可以直接使用类名来访问类属性 , 因为它们是属于类本身的 .
通过对象实例访问类属性 : 虽然类属性是定义在类上的 , 但可以通过类的实例 ( 即对象 ) 来访问它们 .
这是因为在Python中 , 实例会继承类的所有属性 ( 包括类属性 ) .
避免名称冲突 : 为了避免混淆和潜在的错误 , 通常不建议在对象的实例属性中使用与类属性同名的变量 .
如果这样做 , 通过对象实例访问该属性时 , Python会首先查找实例属性 ; 如果实例属性不存在 , 则会查找类属性 .
class Student :
class_name = '301'
def elective ( self, stu, course) :
stu[ 'courses' ] . append( course)
print ( '%s成功选择%s课程!' % ( stu[ 'name' ] , course) )
stu_obj1 = Student( )
stu_obj2 = Student( )
print ( Student. class_name)
print ( Student. class_name)
print ( stu_obj1. class_name)
print ( stu_obj2. class_name)
在Python中 , 当你实例化一个类的对象并调用其方法时 ,
Python会自动将实例对象 ( 即调用方法的那个对象 ) 作为第一个参数传递给该方法 .
这个过程是Python面向对象编程的一个基本特性 , 它使得方法能够访问和修改对象的内部状态 ( 即对象的属性 ) .
self只是一个约定俗成的名称 , 但按照惯例 , 应该始终使用self作为实例方法的第一个参数 .
class Student :
class_name = '301'
def elective ( self, course) :
self. courses. append( course)
print ( '%s成功选择%s课程!' % ( self. name, course) )
stu_obj1 = Student( )
stu_obj1. name = 'kid'
stu_obj1. age = 18
stu_obj1. gender = 'male'
stu_obj1. courses = [ ]
stu_obj1. elective( 'Python' )
stu_obj2 = Student( )
stu_obj2. name = 'qz'
stu_obj2. age = 19
stu_obj2. gender = 'male'
stu_obj2. courses = [ ]
stu_obj2. elective( 'Linux' )
目前代码还存在实例化对象添加属性代码冗余的问题 .
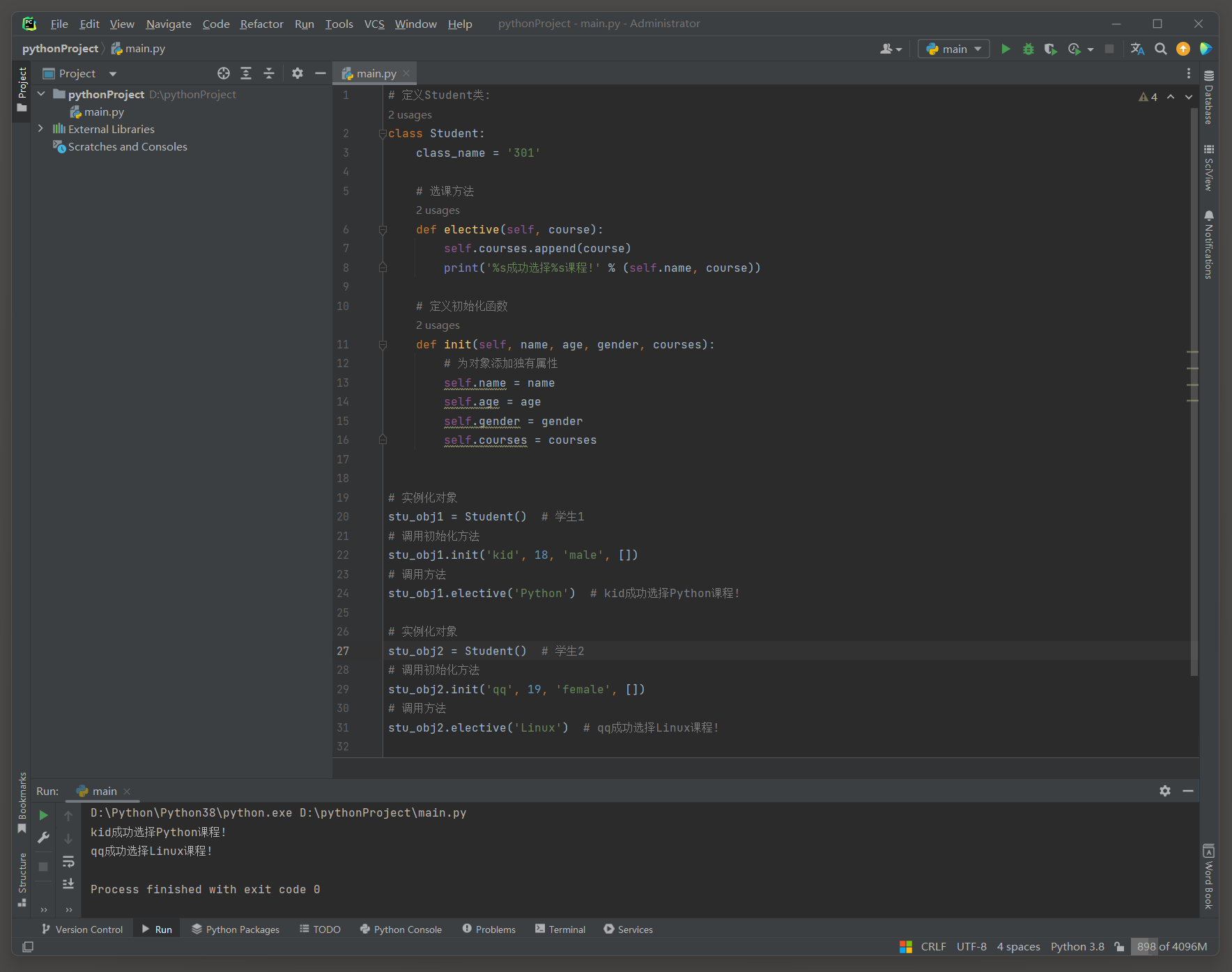
学生选课系统 Version 5 ( 为实例化对象添加属性代码冗余 )
实例化对象添加属性过程重复 , 将重复的代码封装到一个可重用的结构中 ( 函数 ) .
简单来说 , 就是定义一个初始化函数 , 为实例化对象添加独有属性 .
class Student :
class_name = '301'
def elective ( self, course) :
self. courses. append( course)
print ( '%s成功选择%s课程!' % ( self. name, course) )
def init ( stu_obj, name, age, gender, courses) :
stu_obj. name = name
stu_obj. age = age
stu_obj. gender = gender
stu_obj. courses = courses
stu_obj1 = Student( )
init( stu_obj1, 'kid' , 18 , 'male' , [ ] )
stu_obj1. elective( 'Python' )
stu_obj2 = Student( )
init( stu_obj2, 'qq' , 19 , 'female' , [ ] )
stu_obj2. elective( 'Linux' )
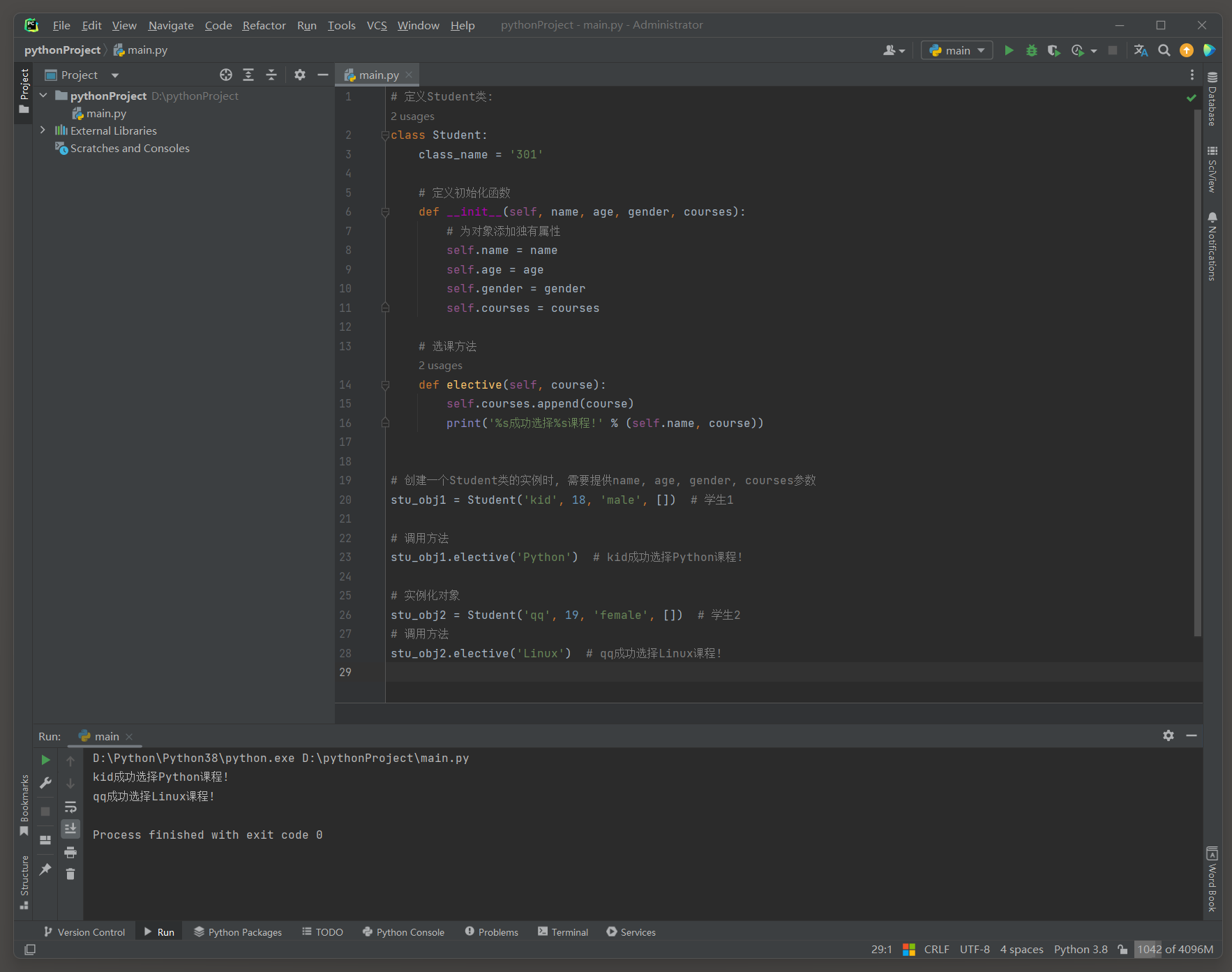
学生选课系统 Version 6 ( 提高可读性 )
在面向对象编程中 , 当有多个对象需要共享相同的初始化和一些共同的行为时 ,
将这些代码封装进一个类中 , 使代码结构更清晰 , 更易于阅读 .
class Student :
class_name = '301'
def elective ( self, course) :
self. courses. append( course)
print ( '%s成功选择%s课程!' % ( self. name, course) )
def init ( self, name, age, gender, courses) :
self. name = name
self. age = age
self. gender = gender
self. courses = courses
stu_obj1 = Student( )
stu_obj1. init( 'kid' , 18 , 'male' , [ ] )
stu_obj1. elective( 'Python' )
stu_obj2 = Student( )
stu_obj2. init( 'qq' , 19 , 'female' , [ ] )
stu_obj2. elective( 'Linux' )
在Python中 , 双下划线开头和结尾的方法被称为 '魔法方法' 或 '特殊方法' 或 '双下划线方法' ( dunder methods ) .
这些方法是Python类定义中的一部分 , 它们为对象提供了一些特殊的行为或特性 .
魔法方法通常由Python解释器在特定情况下自动调用 , 以执行如对象初始化 , 类型转换 , 比较 , 算术操作 , 属性访问等任务 .
这些方法的名称是固定的 , 并且遵循特定的命名约定 , 即以两个下划线开始和结束 .
Python中 , 提供一个特殊的方法__init__ , 用于在创建类的新实例时初始化对象的属性 .
它不是自动为每个类提供的 , 而是需要程序员在定义类时显式地添加 .
__init__方法被称为类的构造函数或初始化方法 .
当创建类的一个新实例时 , __init__方法会自动被调用 , 用于初始化对象的属性或执行其他必要的设置 .
通常 , __init__方法会放在类的开始部分 , 因为它定义了对象创建时需要执行的操作 , 并设置了对象的初始状态 .
这样做有助于读者快速了解如何创建和初始化该类的对象 .
__init__方法的参数是由创建类实例时提供的 .
当调用一个类的构造函数 ( 即实例化一个类 ) 时 , 传递的参数会被用来调用该类的__init__方法 .
__init__方法可以接收任意数量的参数 , 但第一个参数总是一个特殊的引用 , 它指向新创建的对象实例 ,
按照惯例 , 这个参数通常被命名为 self ( 虽然你也可以使用其他名称 , 但self是最常用的 ) .
除了self之外 , __init__方法可以接收任意数量的其他参数 , 这些参数通常对应于实例化对象时传递给构造函数的参数 .
注意 : __init__ 方法不应该有返回值 ( 或者说 , 它应该返回 None ) .
这是因为__init__方法的主要目的是设置对象的状态 , 而不是返回一个新的对象 .
实际上 , 如果尝试从__init__方法返回一个值 ( 除了 None ) , Python解释器会忽略这个返回值 , 并且仍然返回新创建的对象实例 .
学生选课系统 Version 6 ( 自动初始化对象 )
init只是一个普通的成员函数 , 它不会被Python自动调用 , 需要在创建对象后显式地调用它来进行初始化 .
__init__是一个特殊的魔法方法 , 在创建类的新实例时 , Python会自动调用它来进行初始化 .
__init__是Python中类的构造函数的约定 , 所有Python开发者都了解它的作用 .
改进 : 将自定义初始化方法init改为特殊方法__init__ .
class Student :
class_name = '301'
def __init__ ( self, name, age, gender, courses) :
self. name = name
self. age = age
self. gender = gender
self. courses = courses
def elective ( self, course) :
self. courses. append( course)
print ( '%s成功选择%s课程!' % ( self. name, course) )
stu_obj1 = Student( 'kid' , 18 , 'male' , [ ] )
stu_obj1. elective( 'Python' )
stu_obj2 = Student( 'qq' , 19 , 'female' , [ ] )
stu_obj2. elective( 'Linux' )
最终的这个推导而来的就是面向对象编程 , 先定义类 , 后创造对象 .
类可以被视为一个模板或蓝图 , 它定义了对象的属性和方法 .
这个模板描述了具有相似特性和行为的对象应当如何被构建和运作 .
在定义类之后 , 可以通过提供必要的参数来创建类的实例 , 即对象 .
每个对象都是根据其类的定义来创建的 , 并且会拥有类中定义的属性和方法 .
由于每个对象都可以有自己的属性状态 , 因此即使它们都属于同一个类 , 不同的对象之间也可能有不同的属性值 .
对象的独有属性通常是在类的构造函数 ( 在Python中是__init__方法 ) 中定义的 ,
而公有数据 ( 包括公有属性 , 方法和常量 ) 则是直接在类中定义的 .
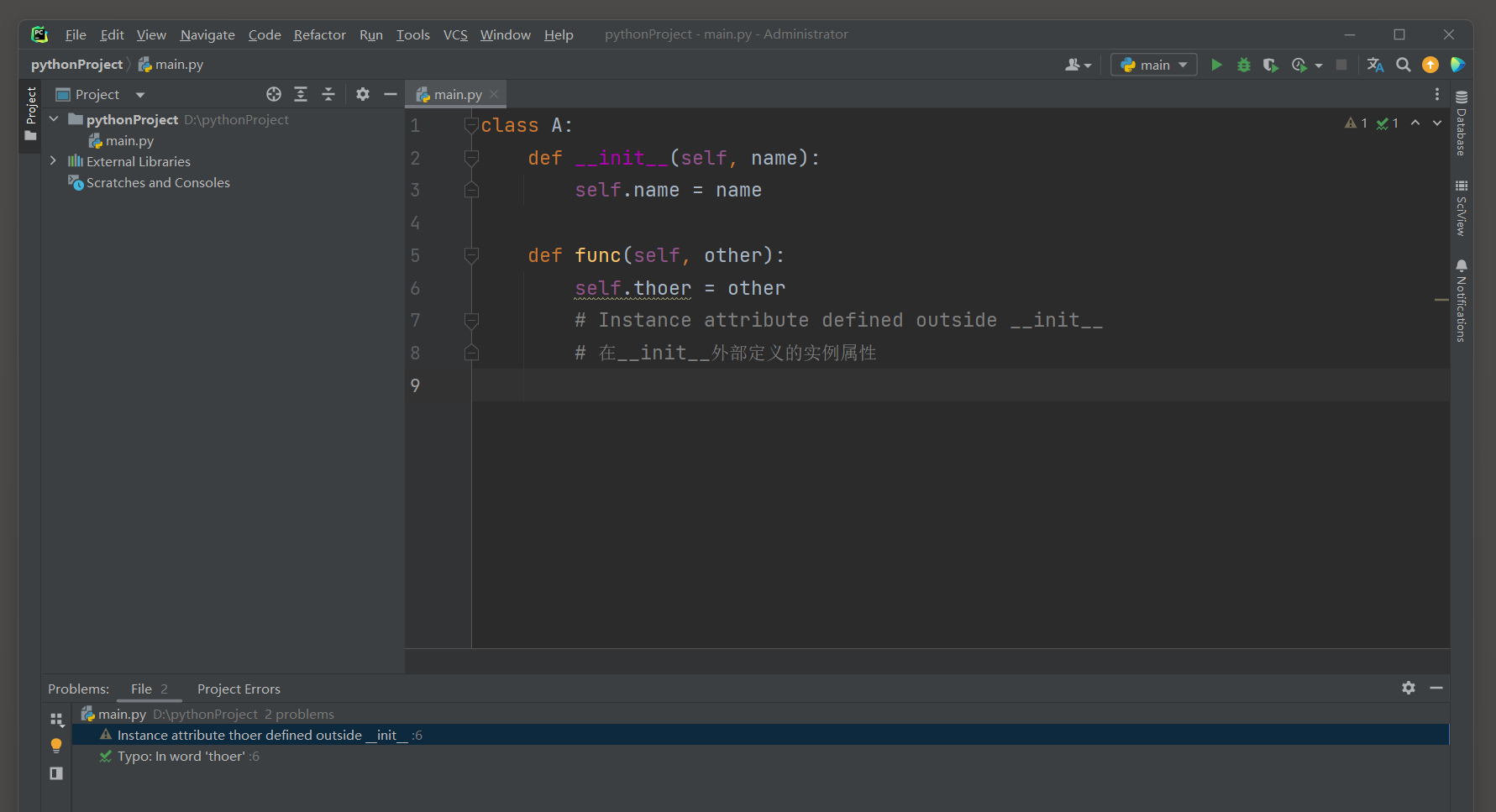
注意 : 避免在__init__方法之外定义实例属性 , 除非你有明确的理由 ( 比如通过某种机制动态地添加属性 ) .
否则 , 其他开发者或未来的你可能不清楚这个属性是在哪里和如何被设置的 , 导致代码更难理解和维护 .
class A :
def __init__ ( self, name) :
self. name = name
def func ( self, other) :
self. thoer = other